Kursus
Pengantar Python
4 Hr
6.9M
Jalankan dan edit kode dari tutorial ini secara online.
Jalankan kodePrincipal component analysis (PCA) adalah teknik reduksi dimensi linear yang dapat digunakan untuk mengekstrak informasi dari ruang berdimensi tinggi dengan memproyeksikannya ke subruang berdimensi lebih rendah. Jika Anda familier dengan bahasa aljabar linear, Anda juga bisa mengatakan bahwa principal component analysis adalah mencari eigenvector dari matriks kovarians untuk mengidentifikasi arah ragam maksimum dalam data.
Satu hal penting tentang PCA adalah bahwa ini merupakan teknik reduksi dimensi tanpa pengawasan (unsupervised), sehingga Anda dapat mengelompokkan titik data yang serupa berdasarkan korelasi di antara mereka tanpa supervisi (atau label).
Catatan: Fitur, Dimensi, dan Variabel semuanya merujuk pada hal yang sama. Anda akan menemukannya digunakan secara bergantian.
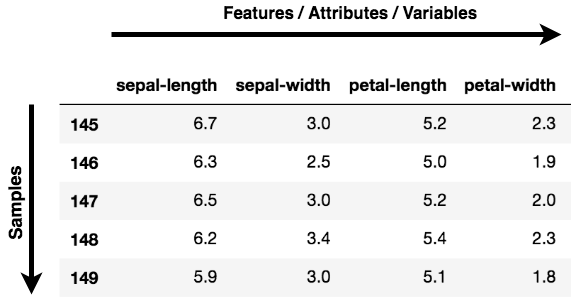
Visualisasi Data: Saat mengerjakan masalah terkait data, tantangan di dunia saat ini adalah besarnya volume data, serta variabel/fitur yang mendefinisikan data tersebut. Untuk memecahkan masalah di mana data adalah kuncinya, Anda memerlukan eksplorasi data ekstensif seperti mencari tahu bagaimana variabel saling berkorelasi atau memahami distribusi beberapa variabel. Mengingat ada banyak variabel atau dimensi tempat data tersebar, visualisasi bisa menjadi tantangan dan hampir mustahil.
Karena itu, PCA dapat melakukannya untuk Anda karena PCA memproyeksikan data ke dimensi yang lebih rendah, sehingga memungkinkan Anda memvisualisasikan data dalam ruang 2D atau 3D dengan mata telanjang.
Mempercepat Algoritma Machine Learning (ML): Karena gagasan utama PCA adalah reduksi dimensi, Anda dapat memanfaatkannya untuk mempercepat waktu pelatihan dan pengujian algoritma machine learning Anda ketika data memiliki banyak fitur dan proses belajar algoritma ML terlalu lambat.
Secara abstrak, Anda mengambil sebuah dataset dengan banyak fitur, lalu Anda menyederhanakannya dengan memilih beberapa Principal Components dari fitur asli.
Komponen utama adalah kunci PCA; komponen ini merepresentasikan apa yang berada di balik kap data Anda. Secara sederhana, ketika data diproyeksikan ke dimensi yang lebih rendah (anggap tiga dimensi) dari ruang yang lebih tinggi, tiga dimensi tersebut tidak lain adalah tiga komponen utama yang menangkap (atau memuat) sebagian besar ragam (informasi) dari data Anda.
Komponen utama memiliki arah dan magnitudo. Arah merepresentasikan sepanjang sumbu utama mana data paling tersebar atau memiliki ragam terbesar dan magnitudo menandakan besarnya ragam yang ditangkap komponen utama dari data saat diproyeksikan ke sumbu tersebut. Komponen utama berbentuk garis lurus, dan komponen utama pertama memuat ragam terbesar dalam data. Setiap komponen utama berikutnya ortogonal terhadap yang terakhir dan memiliki ragam yang lebih kecil. Dengan cara ini, diberikan himpunan variabel x yang berkorelasi pada y sampel, Anda memperoleh himpunan u komponen utama tak berkorelasi pada y sampel yang sama.
Alasan Anda mendapatkan komponen utama yang tak berkorelasi dari fitur asli adalah karena fitur yang berkorelasi berkontribusi pada komponen utama yang sama, sehingga mengurangi fitur data asli menjadi komponen utama yang tak berkorelasi; masing-masing merepresentasikan himpunan fitur berkorelasi yang berbeda dengan tingkat variabilitas yang berbeda. Setiap komponen utama merepresentasikan persentase variabilitas total yang ditangkap dari data.
Dalam tutorial hari ini, kita akan menerapkan PCA untuk mendapatkan wawasan melalui visualisasi data, dan kita juga akan menerapkan PCA untuk mempercepat algoritma machine learning kita. Untuk menyelesaikan kedua tugas tersebut, Anda akan menggunakan dua dataset terkenal: Breast Cancer dan CIFAR - 10. Yang pertama adalah dataset numerik; yang kedua adalah dataset citra.
Sebelum Anda memuat data, ada baiknya memahami dan melihat data yang akan Anda gunakan!
Dataset Breast Cancer adalah data multivariat bernilai riil yang terdiri dari dua kelas, di mana setiap kelas menunjukkan apakah seorang pasien menderita kanker payudara atau tidak. Dua kategorinya adalah: malignant dan benign.
Kelas malignant memiliki 212 sampel, sedangkan kelas benign memiliki 357 sampel.
Dataset ini memiliki 30 fitur yang dibagikan di semua kelas: radius, tekstur, perimeter, area, kelicinan, dimensi fraktal, dll.
Anda dapat mengunduh dataset breast cancer dari sini, atau cara yang lebih mudah adalah memuatnya dengan bantuan pustaka sklearn.
Dataset CIFAR-10 (Canadian Institute For Advanced Research) terdiri dari 60000 gambar berwarna 32x32x3 dengan sepuluh kelas, dengan 6000 gambar per kategori.
Dataset ini terdiri dari 50000 gambar pelatihan dan 10000 gambar pengujian.
Kelas dalam dataset adalah airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck.
Anda dapat mengunduh dataset CIFAR dari sini, atau Anda juga dapat memuatnya langsung dengan bantuan pustaka deep learning seperti Keras.
Sekarang Anda akan memuat dan menganalisis dataset Breast Cancer dan CIFAR-10. Sampai di sini Anda memiliki gambaran mengenai dimensi kedua dataset.
Mari kita cepat eksplor kedua dataset tersebut.
Pertama, mari eksplor dataset Breast Cancer.
Anda akan menggunakan modul datasets milik sklearn dan mengimpor dataset Breast Cancer darinya.
from sklearn.datasets import load_breast_cancer
load_breast_cancer akan memberikan label dan data. Untuk mengambil data, Anda akan memanggil .data dan untuk mengambil label .target.
Data memiliki 569 sampel dengan tiga puluh fitur, dan setiap sampel memiliki label terkait. Ada dua label dalam dataset ini.
breast = load_breast_cancer()
breast_data = breast.data
Mari periksa bentuk (shape) datanya.
breast_data.shape
(569, 30)
Walaupun untuk tutorial ini Anda tidak memerlukan label, namun untuk pemahaman yang lebih baik, mari muat labelnya dan periksa bentuknya.
breast_labels = breast.target
breast_labels.shape
(569,)
Sekarang Anda akan mengimpor numpy karena Anda akan mengubah bentuk breast_labels untuk menggabungkannya dengan breast_data sehingga akhirnya Anda dapat membuat DataFrame yang berisi data dan label.
import numpy as np
labels = np.reshape(breast_labels,(569,1))
Setelah reshaping label, Anda akan concatenate data dan label sepanjang sumbu kedua, yang berarti bentuk akhir array akan menjadi 569 x 31.
final_breast_data = np.concatenate([breast_data,labels],axis=1)
final_breast_data.shape
(569, 31)
Sekarang Anda akan mengimpor pandas untuk membuat DataFrame dari data final agar data direpresentasikan secara tabular.
import pandas as pd
breast_dataset = pd.DataFrame(final_breast_data)
Mari cetak fitur yang ada pada dataset breast cancer!
features = breast.feature_names
features
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
Jika Anda perhatikan pada array features, kolom label tidak ada. Karena itu, Anda harus menambahkannya secara manual ke array features karena Anda akan menyamakan array ini dengan nama kolom dari dataframe breast_dataset Anda.
features_labels = np.append(features,'label')
Bagus! Sekarang Anda akan menyematkan nama kolom ke dataframe breast_dataset.
breast_dataset.columns = features_labels
Mari cetak beberapa baris pertama dari dataframe.
breast_dataset.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0.0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0.0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0.0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0.0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0.0 |
5 baris × 31 kolom
Karena label asli dalam format 0,1, Anda akan mengubah label menjadi benign dan malignant menggunakan fungsi .replace. Anda akan menggunakan inplace=True yang akan memodifikasi dataframe breast_dataset.
breast_dataset['label'].replace(0, 'Benign',inplace=True)
breast_dataset['label'].replace(1, 'Malignant',inplace=True)
Mari cetak beberapa baris terakhir dari breast_dataset.
breast_dataset.tail()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | 0.1726 | 0.05623 | ... | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 | Benign |
| 565 | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | 0.1752 | 0.05533 | ... | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 | Benign |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | Benign |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | Benign |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | Malignant |
5 baris × 31 kolom
Berikutnya, Anda akan mengeksplor dataset gambar CIFAR - 10
Anda dapat memuat dataset CIFAR - 10 menggunakan pustaka deep learning bernama Keras.
from keras.datasets import cifar10
Setelah diimpor, Anda akan menggunakan metode .load_data() untuk mengunduh data; ini akan mengunduh dan menyimpan data di direktori Keras Anda. Waktunya dapat bervariasi tergantung kecepatan internet Anda.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Baris kode di atas mengembalikan gambar pelatihan dan pengujian beserta labelnya.
Mari cepat cetak bentuk gambar pelatihan dan pengujian.
print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)
Traning data shape: (50000, 32, 32, 3)
Testing data shape: (10000, 32, 32, 3)
Mari juga cetak bentuk labelnya.
y_train.shape,y_test.shape
((50000, 1), (10000, 1))
Mari juga cari tahu jumlah total label dan berbagai jenis kelas yang dimiliki data.
# Find the unique numbers from the train labels
classes = np.unique(y_train)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
Total number of outputs : 10
Output classes : [0 1 2 3 4 5 6 7 8 9]
Sekarang untuk memplot gambar CIFAR-10, Anda akan mengimpor matplotlib dan juga menggunakan perintah magic (%) %matplotlib inline untuk memberi tahu jupyter notebook agar menampilkan keluaran langsung di dalam notebook!
import matplotlib.pyplot as plt
%matplotlib inline
Untuk pemahaman yang lebih baik, mari buat kamus yang berisi nama kelas dengan label kelas kategorikal yang sesuai.
label_dict = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck',
}
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
curr_img = np.reshape(x_train[0], (32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_train[0][0]]) + ")"))
# Display the first image in testing data
plt.subplot(122)
curr_img = np.reshape(x_test[0],(32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_test[0][0]]) + ")"))
Text(0.5, 1.0, '(Label: frog)')
Text(0.5, 1.0, '(Label: cat)')

Walaupun kedua gambar di atas buram, Anda masih bisa mengamati bahwa gambar pertama adalah katak dengan label frog, sedangkan gambar kedua adalah kucing dengan label cat.
Sekarang bagian paling menarik dari tutorial ini. Seperti yang Anda pelajari sebelumnya bahwa PCA memproyeksikan data berdimensi tinggi menjadi komponen utama berdimensi rendah, kini saatnya memvisualisasikannya dengan bantuan Python!
Anda mulai dengan Standardizing data karena keluaran PCA dipengaruhi oleh skala fitur dari data.
Merupakan praktik umum untuk menormalkan data sebelum memberikannya ke algoritma machine learning apa pun.
Untuk menerapkan normalisasi, Anda akan mengimpor modul StandardScaler dari pustaka sklearn dan memilih hanya fitur dari breast_dataset yang Anda buat pada langkah Eksplorasi Data. Setelah memiliki fitur, Anda kemudian akan menerapkan penskalaan dengan melakukan fit_transform pada data fitur.
Saat menerapkan StandardScaler, setiap fitur data Anda sebaiknya terdistribusi normal sehingga distribusi akan diskalakan ke mean nol dan deviasi standar satu.
from sklearn.preprocessing import StandardScaler
x = breast_dataset.loc[:, features].values
x = StandardScaler().fit_transform(x) # normalizing the features
x.shape
(569, 30)
Mari periksa apakah data yang dinormalisasi memiliki mean nol dan deviasi standar satu.
np.mean(x),np.std(x)
(-6.826538293184326e-17, 1.0)
Mari konversi fitur yang dinormalisasi ke format tabular dengan bantuan DataFrame.
feat_cols = ['feature'+str(i) for i in range(x.shape[1])]
normalised_breast = pd.DataFrame(x,columns=feat_cols)
normalised_breast.tail()
| feature0 | feature1 | feature2 | feature3 | feature4 | feature5 | feature6 | feature7 | feature8 | feature9 | ... | feature20 | feature21 | feature22 | feature23 | feature24 | feature25 | feature26 | feature27 | feature28 | feature29 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 2.110995 | 0.721473 | 2.060786 | 2.343856 | 1.041842 | 0.219060 | 1.947285 | 2.320965 | -0.312589 | -0.931027 | ... | 1.901185 | 0.117700 | 1.752563 | 2.015301 | 0.378365 | -0.273318 | 0.664512 | 1.629151 | -1.360158 | -0.709091 |
| 565 | 1.704854 | 2.085134 | 1.615931 | 1.723842 | 0.102458 | -0.017833 | 0.693043 | 1.263669 | -0.217664 | -1.058611 | ... | 1.536720 | 2.047399 | 1.421940 | 1.494959 | -0.691230 | -0.394820 | 0.236573 | 0.733827 | -0.531855 | -0.973978 |
| 566 | 0.702284 | 2.045574 | 0.672676 | 0.577953 | -0.840484 | -0.038680 | 0.046588 | 0.105777 | -0.809117 | -0.895587 | ... | 0.561361 | 1.374854 | 0.579001 | 0.427906 | -0.809587 | 0.350735 | 0.326767 | 0.414069 | -1.104549 | -0.318409 |
| 567 | 1.838341 | 2.336457 | 1.982524 | 1.735218 | 1.525767 | 3.272144 | 3.296944 | 2.658866 | 2.137194 | 1.043695 | ... | 1.961239 | 2.237926 | 2.303601 | 1.653171 | 1.430427 | 3.904848 | 3.197605 | 2.289985 | 1.919083 | 2.219635 |
| 568 | -1.808401 | 1.221792 | -1.814389 | -1.347789 | -3.112085 | -1.150752 | -1.114873 | -1.261820 | -0.820070 | -0.561032 | ... | -1.410893 | 0.764190 | -1.432735 | -1.075813 | -1.859019 | -1.207552 | -1.305831 | -1.745063 | -0.048138 | -0.751207 |
5 baris × 30 kolom
Sekarang bagian pentingnya, beberapa baris kode berikut akan memproyeksikan data Breast Cancer berdimensi tiga puluh ke dua komponen utama berdimensi.
Anda akan menggunakan pustaka sklearn untuk mengimpor modul PCA, dan pada metode PCA, Anda akan memasukkan jumlah komponen (n_components=2) dan akhirnya memanggil fit_transform pada data agregat. Di sini, jumlah komponen merepresentasikan dimensi yang lebih rendah tempat Anda memproyeksikan data berdimensi lebih tinggi.
from sklearn.decomposition import PCA
pca_breast = PCA(n_components=2)
principalComponents_breast = pca_breast.fit_transform(x)
Berikutnya, mari buat DataFrame yang akan memiliki nilai komponen utama untuk semua 569 sampel.
principal_breast_Df = pd.DataFrame(data = principalComponents_breast
, columns = ['principal component 1', 'principal component 2'])
principal_breast_Df.tail()
| principal component 1 | principal component 2 | |
|---|---|---|
| 564 | 6.439315 | -3.576817 |
| 565 | 3.793382 | -3.584048 |
| 566 | 1.256179 | -1.902297 |
| 567 | 10.374794 | 1.672010 |
| 568 | -5.475243 | -0.670637 |
explained_variance_ratio. Ini akan memberi Anda jumlah informasi atau ragam yang dipegang setiap komponen utama setelah memproyeksikan data ke subruang berdimensi lebih rendah.print('Explained variability per principal component: {}'.format(pca_breast.explained_variance_ratio_))
Explained variability per principal component: [0.44272026 0.18971182]
Dari keluaran di atas, Anda dapat mengamati bahwa principal component 1 memuat 44,2% informasi sedangkan principal component 2 hanya memuat 19% informasi. Poin lain yang perlu dicatat adalah bahwa saat memproyeksikan data berdimensi tiga puluh ke data dua dimensi, 36,8% informasi hilang.
Mari plot visualisasi 569 sampel sepanjang sumbu principal component - 1 dan principal component - 2. Ini seharusnya memberi Anda wawasan yang baik tentang bagaimana sampel Anda terdistribusi di antara dua kelas.
plt.figure()
plt.figure(figsize=(10,10))
plt.xticks(fontsize=12)
plt.yticks(fontsize=14)
plt.xlabel('Principal Component - 1',fontsize=20)
plt.ylabel('Principal Component - 2',fontsize=20)
plt.title("Principal Component Analysis of Breast Cancer Dataset",fontsize=20)
targets = ['Benign', 'Malignant']
colors = ['r', 'g']
for target, color in zip(targets,colors):
indicesToKeep = breast_dataset['label'] == target
plt.scatter(principal_breast_Df.loc[indicesToKeep, 'principal component 1']
, principal_breast_Df.loc[indicesToKeep, 'principal component 2'], c = color, s = 50)
plt.legend(targets,prop={'size': 15})
<matplotlib.legend.Legend at 0x14552a630>
<Figure size 432x288 with 0 Axes>
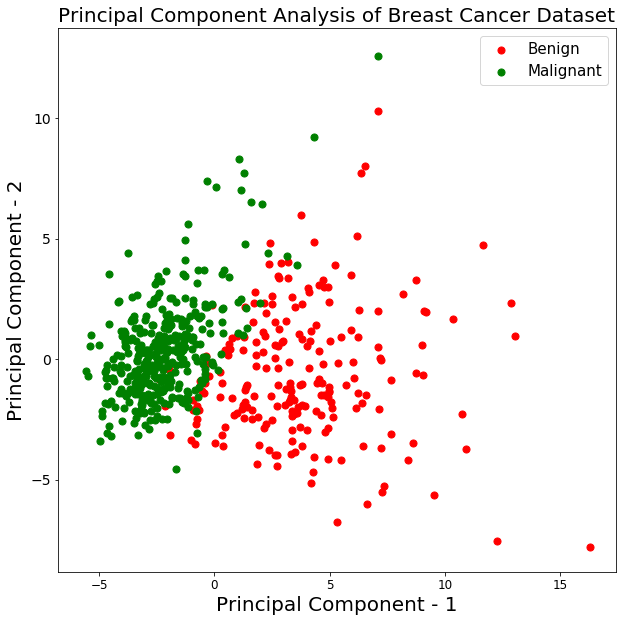
Dari grafik di atas, Anda dapat mengamati bahwa dua kelas benign dan malignant, ketika diproyeksikan ke ruang dua dimensi, dapat dipisahkan secara linear sampai batas tertentu. Pengamatan lain adalah bahwa kelas benign lebih tersebar dibandingkan kelas malignant.
Baris kode berikut untuk memvisualisasikan data CIFAR-10 cukup mirip dengan visualisasi PCA pada data Breast Cancer.
normalisasi piksel antara 0 dan 1 (inklusif).np.min(x_train),np.max(x_train)
(0.0, 1.0)
x_train = x_train/255.0
np.min(x_train),np.max(x_train)
(0.0, 0.00392156862745098)
x_train.shape
(50000, 32, 32, 3)
Berikutnya, Anda akan membuat DataFrame yang akan menyimpan nilai piksel gambar beserta labelnya masing-masing dalam format baris-kolom.
Tetapi sebelum itu, mari ubah bentuk dimensi gambar dari tiga menjadi satu (flatten gambar).
x_train_flat = x_train.reshape(-1,3072)
feat_cols = ['pixel'+str(i) for i in range(x_train_flat.shape[1])]
df_cifar = pd.DataFrame(x_train_flat,columns=feat_cols)
df_cifar['label'] = y_train
print('Size of the dataframe: {}'.format(df_cifar.shape))
Size of the dataframe: (50000, 3073)
Sempurna! Ukuran dataframe sudah benar karena ada 50.000 gambar pelatihan, masing-masing memiliki 3072 piksel dan satu kolom tambahan untuk label jadi total 3073.
PCA akan diterapkan pada semua kolom kecuali yang terakhir, yaitu label untuk setiap gambar.
df_cifar.head()
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel3063 | pixel3064 | pixel3065 | pixel3066 | pixel3067 | pixel3068 | pixel3069 | pixel3070 | pixel3071 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.231373 | 0.243137 | 0.247059 | 0.168627 | 0.180392 | 0.176471 | 0.196078 | 0.188235 | 0.168627 | 0.266667 | ... | 0.847059 | 0.721569 | 0.549020 | 0.592157 | 0.462745 | 0.329412 | 0.482353 | 0.360784 | 0.282353 | 6 |
| 1 | 0.603922 | 0.694118 | 0.733333 | 0.494118 | 0.537255 | 0.533333 | 0.411765 | 0.407843 | 0.372549 | 0.400000 | ... | 0.560784 | 0.521569 | 0.545098 | 0.560784 | 0.525490 | 0.556863 | 0.560784 | 0.521569 | 0.564706 | 9 |
| 2 | 1.000000 | 1.000000 | 1.000000 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | ... | 0.305882 | 0.333333 | 0.325490 | 0.309804 | 0.333333 | 0.325490 | 0.313725 | 0.337255 | 0.329412 | 9 |
| 3 | 0.109804 | 0.098039 | 0.039216 | 0.145098 | 0.133333 | 0.074510 | 0.149020 | 0.137255 | 0.078431 | 0.164706 | ... | 0.211765 | 0.184314 | 0.109804 | 0.247059 | 0.219608 | 0.145098 | 0.282353 | 0.254902 | 0.180392 | 4 |
| 4 | 0.666667 | 0.705882 | 0.776471 | 0.658824 | 0.698039 | 0.768627 | 0.694118 | 0.725490 | 0.796078 | 0.717647 | ... | 0.294118 | 0.309804 | 0.321569 | 0.278431 | 0.294118 | 0.305882 | 0.286275 | 0.301961 | 0.313725 | 1 |
5 baris × 3073 kolom
fit_transform pada data pelatihan, ini bisa memakan beberapa detik karena ada 50.000 sampelpca_cifar = PCA(n_components=2)
principalComponents_cifar = pca_cifar.fit_transform(df_cifar.iloc[:,:-1])
Kemudian Anda akan mengonversi komponen utama untuk masing-masing dari 50.000 gambar dari array numpy ke pandas DataFrame.
principal_cifar_Df = pd.DataFrame(data = principalComponents_cifar
, columns = ['principal component 1', 'principal component 2'])
principal_cifar_Df['y'] = y_train
principal_cifar_Df.head()
| principal component 1 | principal component 2 | y | |
|---|---|---|---|
| 0 | -6.401018 | 2.729039 | 6 |
| 1 | 0.829783 | -0.949943 | 9 |
| 2 | 7.730200 | -11.522102 | 9 |
| 3 | -10.347817 | 0.010738 | 4 |
| 4 | -2.625651 | -4.969240 | 1 |
ragam yang dipegang komponen utama.print('Explained variability per principal component: {}'.format(pca_cifar.explained_variance_ratio_))
Explained variability per principal component: [0.2907663 0.11253144]
Nampaknya jumlah informasi yang layak dipertahankan oleh komponen utama 1 dan 2, mengingat data diproyeksikan dari 3072 dimensi menjadi hanya dua komponen utama.
Sekarang saatnya memvisualisasikan data CIFAR-10 dalam ruang dua dimensi. Ingat bahwa ada sedikit tumpang tindih kelas semantik dalam dataset ini yang berarti seekor katak bisa memiliki bentuk yang sedikit mirip kucing atau rusa dengan anjing; terutama saat diproyeksikan ke ruang dua dimensi. Perbedaannya mungkin tidak tertangkap dengan baik.
import seaborn as sns
plt.figure(figsize=(16,10))
sns.scatterplot(
x="principal component 1", y="principal component 2",
hue="y",
palette=sns.color_palette("hls", 10),
data=principal_cifar_Df,
legend="full",
alpha=0.3
)
<matplotlib.axes._subplots.AxesSubplot at 0x12a5ba8d0>
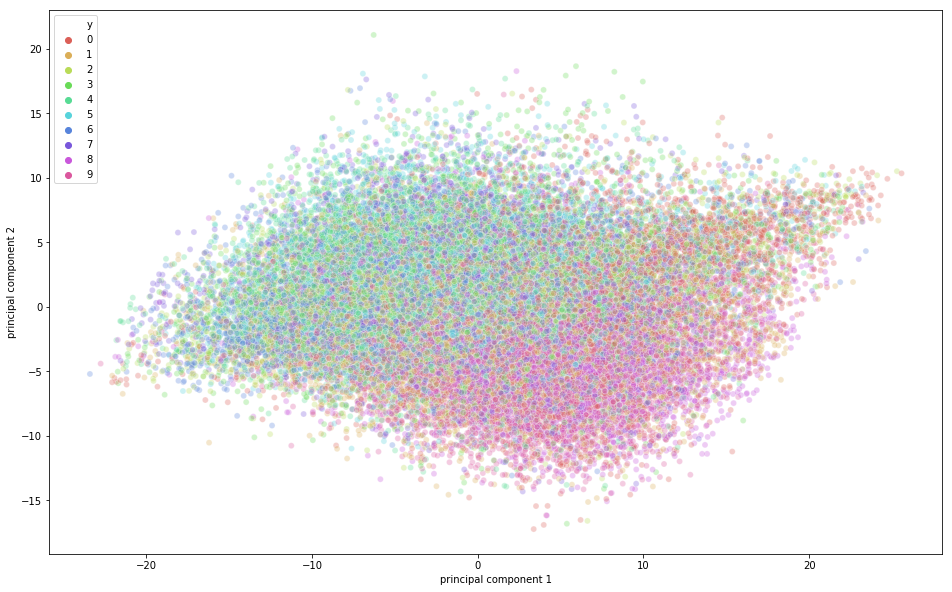
Dari gambar di atas, Anda dapat mengamati bahwa beberapa variasi ditangkap oleh komponen utama karena ada struktur pada titik-titik saat diproyeksikan sepanjang dua sumbu komponen utama. Titik yang berasal dari kelas yang sama saling berdekatan, dan titik atau gambar yang sangat berbeda secara semantik saling berjauhan.
Pada segmen terakhir tutorial ini, Anda akan mempelajari bagaimana Anda dapat mempercepat proses pelatihan Model Deep Learning menggunakan PCA.
Catatan: Untuk mempelajari terminologi dasar yang akan digunakan di bagian ini, silakan lihat tutorial ini.
Pertama, mari normalkan gambar pelatihan dan pengujian. Jika Anda ingat gambar pelatihan telah dinormalisasi pada bagian visualisasi PCA, jadi Anda hanya perlu menormalkan gambar pengujian. Mari cepat lakukan!
x_test = x_test/255.0
x_test = x_test.reshape(-1,32,32,3)
Mari reshape data uji.
x_test_flat = x_test.reshape(-1,3072)
Berikutnya, Anda akan membuat instance model PCA.
Di sini, Anda juga dapat memasukkan berapa banyak ragam yang ingin Anda tangkap dengan PCA. Mari masukkan 0,9 sebagai parameter pada model PCA, yang berarti PCA akan menahan 90% ragam dan jumlah komponen yang diperlukan untuk menangkap 90% ragam akan digunakan.
Perhatikan bahwa sebelumnya Anda memasukkan n_components sebagai parameter dan kemudian Anda dapat mengetahui seberapa besar ragam yang ditangkap oleh dua komponen tersebut. Tetapi di sini kita secara eksplisit menyebutkan seberapa besar ragam yang ingin ditangkap PCA dan karena itu, n_components akan bervariasi berdasarkan parameter ragam.
Jika Anda tidak memasukkan ragam apa pun, maka jumlah komponen akan sama dengan dimensi asli data.
pca = PCA(0.9)
Kemudian Anda akan menyesuaikan (fit) instance PCA pada gambar pelatihan.
pca.fit(x_train_flat)
PCA(copy=True, iterated_power='auto', n_components=0.9, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
Sekarang mari cari tahu berapa banyak n_components yang digunakan PCA untuk menangkap ragam 0,9.
pca.n_components_
99
Dari keluaran di atas, Anda dapat mengamati bahwa untuk mencapai ragam 90%, dimensi dikurangi menjadi 99 komponen utama dari 3072 dimensi sebenarnya.
Terakhir, Anda akan menerapkan transform pada data pelatihan dan uji untuk menghasilkan dataset yang ditransformasikan dari parameter yang dihasilkan dari metode fit.
train_img_pca = pca.transform(x_train_flat)
test_img_pca = pca.transform(x_test_flat)
Berikutnya, mari cepat impor pustaka yang diperlukan untuk menjalankan model deep learning.
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.optimizers import RMSprop
Sekarang, Anda akan mengonversi label pelatihan dan pengujian menjadi vektor one-hot encoding.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
Mari tetapkan jumlah epoch, jumlah kelas, dan ukuran batch untuk model Anda.
batch_size = 128
num_classes = 10
epochs = 20
Berikutnya, Anda akan mendefinisikan model Sequential Anda!
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(99,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
Mari cetak ringkasan model.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1024) 102400
_________________________________________________________________
dense_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_3 (Dense) (None, 512) 524800
_________________________________________________________________
dense_4 (Dense) (None, 256) 131328
_________________________________________________________________
dense_5 (Dense) (None, 10) 2570
=================================================================
Total params: 1,810,698
Trainable params: 1,810,698
Non-trainable params: 0
_________________________________________________________________
Terakhir, saatnya menyusun (compile) dan melatih model!
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(train_img_pca, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(test_img_pca, y_test))
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:2704: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:1257: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 7s - loss: 1.9032 - acc: 0.2962 - val_loss: 1.6925 - val_acc: 0.3875
Epoch 2/20
50000/50000 [==============================] - 7s - loss: 1.6480 - acc: 0.4055 - val_loss: 1.5313 - val_acc: 0.4412
Epoch 3/20
50000/50000 [==============================] - 7s - loss: 1.5205 - acc: 0.4534 - val_loss: 1.4609 - val_acc: 0.4695
Epoch 4/20
50000/50000 [==============================] - 7s - loss: 1.4322 - acc: 0.4849 - val_loss: 1.6164 - val_acc: 0.4503
Epoch 5/20
50000/50000 [==============================] - 7s - loss: 1.3621 - acc: 0.5120 - val_loss: 1.3626 - val_acc: 0.5081
Epoch 6/20
50000/50000 [==============================] - 7s - loss: 1.2995 - acc: 0.5330 - val_loss: 1.4100 - val_acc: 0.4940
Epoch 7/20
50000/50000 [==============================] - 7s - loss: 1.2473 - acc: 0.5529 - val_loss: 1.3589 - val_acc: 0.5251
Epoch 8/20
50000/50000 [==============================] - 7s - loss: 1.2010 - acc: 0.5669 - val_loss: 1.3315 - val_acc: 0.5232
Epoch 9/20
50000/50000 [==============================] - 7s - loss: 1.1524 - acc: 0.5868 - val_loss: 1.3903 - val_acc: 0.5197
Epoch 10/20
50000/50000 [==============================] - 7s - loss: 1.1134 - acc: 0.6013 - val_loss: 1.2722 - val_acc: 0.5499
Epoch 11/20
50000/50000 [==============================] - 7s - loss: 1.0691 - acc: 0.6160 - val_loss: 1.5911 - val_acc: 0.4768
Epoch 12/20
50000/50000 [==============================] - 7s - loss: 1.0325 - acc: 0.6289 - val_loss: 1.2515 - val_acc: 0.5602
Epoch 13/20
50000/50000 [==============================] - 7s - loss: 0.9977 - acc: 0.6420 - val_loss: 1.5678 - val_acc: 0.4914
Epoch 14/20
50000/50000 [==============================] - 8s - loss: 0.9567 - acc: 0.6567 - val_loss: 1.3525 - val_acc: 0.5418
Epoch 15/20
50000/50000 [==============================] - 9s - loss: 0.9158 - acc: 0.6713 - val_loss: 1.3525 - val_acc: 0.5540
Epoch 16/20
50000/50000 [==============================] - 10s - loss: 0.8948 - acc: 0.6816 - val_loss: 1.5633 - val_acc: 0.5156
Epoch 17/20
50000/50000 [==============================] - 9s - loss: 0.8690 - acc: 0.6903 - val_loss: 1.6980 - val_acc: 0.5084
Epoch 18/20
50000/50000 [==============================] - 9s - loss: 0.8586 - acc: 0.7002 - val_loss: 1.6325 - val_acc: 0.5247
Epoch 19/20
50000/50000 [==============================] - 8s - loss: 0.9367 - acc: 0.6853 - val_loss: 1.8253 - val_acc: 0.5165
Epoch 20/20
50000/50000 [==============================] - 8s - loss: 2.3761 - acc: 0.5971 - val_loss: 6.0192 - val_acc: 0.4409
Dari keluaran di atas, Anda dapat mengamati bahwa waktu yang dibutuhkan untuk melatih setiap epoch hanya 7 seconds pada CPU. Model bekerja cukup baik pada data pelatihan, mencapai akurasi 70% sementara hanya mencapai akurasi 56% pada data uji. Ini berarti model mengalami overfitting pada data pelatihan. Namun, ingat bahwa data diproyeksikan ke 99 dimensi dari 3072 dimensi dan meskipun demikian hasilnya cukup baik!
Terakhir, mari lihat berapa banyak waktu yang dibutuhkan model untuk berlatih pada dataset asli dan berapa akurasi yang bisa dicapai menggunakan model deep learning yang sama.
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(3072,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train_flat, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(x_test_flat, y_test))
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 23s - loss: 2.0657 - acc: 0.2200 - val_loss: 2.0277 - val_acc: 0.2485
Epoch 2/20
50000/50000 [==============================] - 22s - loss: 1.8727 - acc: 0.3166 - val_loss: 1.8428 - val_acc: 0.3215
Epoch 3/20
50000/50000 [==============================] - 22s - loss: 1.7801 - acc: 0.3526 - val_loss: 1.7657 - val_acc: 0.3605
Epoch 4/20
50000/50000 [==============================] - 22s - loss: 1.7141 - acc: 0.3796 - val_loss: 1.6345 - val_acc: 0.4132
Epoch 5/20
50000/50000 [==============================] - 22s - loss: 1.6566 - acc: 0.4001 - val_loss: 1.6384 - val_acc: 0.4076
Epoch 6/20
50000/50000 [==============================] - 22s - loss: 1.6083 - acc: 0.4209 - val_loss: 1.7507 - val_acc: 0.3574
Epoch 7/20
50000/50000 [==============================] - 22s - loss: 1.5626 - acc: 0.4374 - val_loss: 1.7125 - val_acc: 0.4010
Epoch 8/20
50000/50000 [==============================] - 22s - loss: 1.5252 - acc: 0.4486 - val_loss: 1.5914 - val_acc: 0.4321
Epoch 9/20
50000/50000 [==============================] - 24s - loss: 1.4924 - acc: 0.4620 - val_loss: 1.5352 - val_acc: 0.4616
Epoch 10/20
50000/50000 [==============================] - 25s - loss: 1.4627 - acc: 0.4728 - val_loss: 1.4561 - val_acc: 0.4798
Epoch 11/20
50000/50000 [==============================] - 24s - loss: 1.4349 - acc: 0.4820 - val_loss: 1.5044 - val_acc: 0.4723
Epoch 12/20
50000/50000 [==============================] - 24s - loss: 1.4120 - acc: 0.4919 - val_loss: 1.4740 - val_acc: 0.4790
Epoch 13/20
50000/50000 [==============================] - 23s - loss: 1.3913 - acc: 0.4981 - val_loss: 1.4430 - val_acc: 0.4891
Epoch 14/20
50000/50000 [==============================] - 27s - loss: 1.3678 - acc: 0.5098 - val_loss: 1.4323 - val_acc: 0.4888
Epoch 15/20
50000/50000 [==============================] - 27s - loss: 1.3508 - acc: 0.5148 - val_loss: 1.6179 - val_acc: 0.4372
Epoch 16/20
50000/50000 [==============================] - 25s - loss: 1.3443 - acc: 0.5167 - val_loss: 1.5868 - val_acc: 0.4656
Epoch 17/20
50000/50000 [==============================] - 25s - loss: 1.3734 - acc: 0.5101 - val_loss: 1.4756 - val_acc: 0.4913
Epoch 18/20
50000/50000 [==============================] - 26s - loss: 5.5126 - acc: 0.3591 - val_loss: 5.7580 - val_acc: 0.3084
Epoch 19/20
50000/50000 [==============================] - 27s - loss: 5.6346 - acc: 0.3395 - val_loss: 3.7362 - val_acc: 0.3402
Epoch 20/20
50000/50000 [==============================] - 26s - loss: 6.4199 - acc: 0.3030 - val_loss: 13.9429 - val_acc: 0.1326
Voila! Dari keluaran di atas, terlihat jelas bahwa waktu yang dibutuhkan untuk melatih setiap epoch sekitar 23 seconds pada CPU yang hampir tiga kali lebih lama dibandingkan model yang dilatih pada keluaran PCA.
Selain itu, akurasi pelatihan dan pengujian keduanya lebih rendah daripada akurasi yang Anda capai dengan 99 komponen utama sebagai masukan ke model.
Jadi, dengan menerapkan PCA pada data pelatihan Anda dapat melatih algoritma deep learning tidak hanya lebih cepat, tetapi juga mencapai akurasi yang lebih baik pada data pengujian dibandingkan dengan algoritma deep learning yang dilatih dengan data pelatihan asli.
Lanjutkan!
Selamat telah menyelesaikan tutorial.
Tutorial ini merupakan pengantar yang sangat baik dan komprehensif untuk PCA di Python, yang mencakup konsep teoretis sekaligus praktis dari PCA.
Jika Anda ingin menggali lebih dalam teknik reduksi dimensi, pertimbangkan untuk membaca tentang t-distributed Stochastic Neighbor Embedding yang biasa dikenal sebagai tSNE, yang merupakan teknik reduksi dimensi probabilistik non-linear.
Jika Anda ingin mempelajari lebih lanjut tentang teknik pembelajaran tanpa pengawasan seperti PCA, ikuti kursus Unsupervised Learning in Python dari DataCamp.
Referensi untuk pembelajaran lebih lanjut:
Pelajari lebih lanjut tentang Python
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
