
Cursus
Introductie tot Python
4 Hr
6.9M
Voer de code uit deze tutorial online uit en pas 'm aan.
Code uitvoerenPrincipal component analysis (PCA) is een lineaire techniek voor dimensiereductie die je kunt gebruiken om informatie uit een hoogdimensionale ruimte te halen door deze te projecteren naar een lager-dimensionale subruimte. Als je vertrouwd bent met de taal van lineaire algebra, kun je ook zeggen dat principal component analysis de eigenvectoren van de covariantiematrix vindt om de richtingen van maximale variantie in de data te identificeren.
Belangrijk om te weten: PCA is een onbewaakte techniek voor dimensiereductie. Je kunt dus vergelijkbare datapunten clusteren op basis van hun onderlinge correlatie, zonder supervisie (of labels).
Let op: Features, dimensies en variabelen verwijzen allemaal naar hetzelfde. Je zult ze door elkaar gebruikt zien.
Datavisualisatie: Bij elk dataprobleem is de uitdaging tegenwoordig de enorme hoeveelheid data en de variabelen/features die die data definiëren. Om een probleem op te lossen waarbij data de sleutel is, heb je uitgebreide data-exploratie nodig, zoals het vinden van correlaties tussen variabelen of het begrijpen van de verdeling van een paar variabelen. Gezien het grote aantal variabelen of dimensies waarlangs de data is verdeeld, kan visualisatie een uitdaging zijn en bijna onmogelijk.
Daarom kan PCA dit voor je doen, omdat het de data projecteert naar een lagere dimensie, zodat je de data met het blote oog in een 2D- of 3D-ruimte kunt visualiseren.
Een machinelearning-algoritme (ML) versnellen: Omdat PCA in de kern draait om dimensiereductie, kun je dat benutten om de trainings- en testtijd van je machinelearning-algoritme te versnellen wanneer je data veel features heeft en het leren van het ML-algoritme te traag is.
Op abstract niveau neem je een dataset met veel features en vereenvoudig je die door een paar Principal Components te selecteren uit de oorspronkelijke features.
Principal components zijn de kern van PCA; ze vertegenwoordigen wat er onder de motorkap van je data gebeurt. Simpel gezegd: wanneer de data uit een hogere ruimte naar een lagere dimensie wordt geprojecteerd (stel drie dimensies), zijn die drie dimensies niets anders dan de drie hoofdcomponenten die het grootste deel van de variantie (informatie) in je data vastleggen.
Principal components hebben zowel richting als grootte. De richting geeft aan langs welke hoofdassen de data het meest verspreid is of de meeste variantie heeft, en de grootte geeft aan hoeveel variantie die hoofdcomponent van de data opvangt wanneer deze op die as wordt geprojecteerd. De principal components zijn rechten lijnen; de eerste hoofdcomponent bevat de meeste variantie in de data. Elke volgende hoofdcomponent staat loodrecht op de vorige en heeft minder variantie. Zo verkrijg je, gegeven een set van x gecorreleerde variabelen over y steekproeven, een set van u ongecorreleerde hoofdcomponenten over dezelfde y steekproeven.
De reden dat je ongecorreleerde hoofdcomponenten krijgt uit de oorspronkelijke features, is dat gecorreleerde features bijdragen aan dezelfde hoofdcomponent. Zo reduceer je de oorspronkelijke datafeatures tot ongecorreleerde hoofdcomponenten; elk vertegenwoordigt een andere set gecorreleerde features met verschillende hoeveelheden variabiliteit. Elke hoofdcomponent vertegenwoordigt een percentage van de totale variabiliteit die uit de data is opgehaald.
In de tutorial van vandaag passen we PCA toe om inzicht te krijgen via datavisualisatie, en we passen PCA ook toe om ons machinelearning-algoritme te versnellen. Om deze twee taken uit te voeren, gebruik je twee bekende datasets: Breast Cancer en CIFAR - 10. De eerste is een numerieke dataset; de tweede is een afbeeldingsdataset.
Voordat je de data gaat laden, is het goed om te begrijpen en te bekijken met welke data je gaat werken!
De Breast Cancer-dataset is een reële multivariate dataset met twee klassen, waarbij elke klasse aangeeft of een patiënt borstkanker heeft of niet. De twee categorieën zijn: kwaadaardig en goedaardig.
De kwaadaardige klasse heeft 212 samples, terwijl de goedaardige klasse 357 samples heeft.
Er zijn 30 features die over alle klassen worden gedeeld: straal, textuur, omtrek, oppervlakte, gladheid, fractale dimensie, enz.
Je kunt de borstkankerdataset hier downloaden, of je kunt hem eenvoudiger laden met behulp van de sklearn-bibliotheek.
De CIFAR-10 (Canadian Institute For Advanced Research) dataset bestaat uit 60000 afbeeldingen van 32x32x3 kleurenafbeeldingen met tien klassen, met 6000 afbeeldingen per categorie.
De dataset bestaat uit 50000 trainingsafbeeldingen en 10000 testafbeeldingen.
De klassen in de dataset zijn airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck.
Je kunt de CIFAR-dataset hier downloaden, of je kunt hem on the fly laden met behulp van een deep learning-bibliotheek zoals Keras.
Nu ga je de datasets Breast Cancer en CIFAR-10 laden en analyseren. Je hebt inmiddels een idee van de dimensionaliteit van beide datasets.
Laten we beide datasets snel verkennen.
Laten we eerst de Breast Cancer-dataset verkennen.
Je gebruikt de module datasets van sklearn en importeert daaruit de Breast Cancer-dataset.
from sklearn.datasets import load_breast_cancer
load_breast_cancer geeft je zowel labels als data. Voor de data roep je .data aan en voor de labels .target.
De data heeft 569 samples met dertig features, en elke sample heeft een bijbehorend label. Er zijn twee labels in deze dataset.
breast = load_breast_cancer()breast_data = breast.dataLaten we de shape van de data controleren.
breast_data.shape(569, 30)Hoewel je de labels voor deze tutorial niet nodig hebt, laden we ze toch voor een beter begrip en controleren we de shape.
breast_labels = breast.targetbreast_labels.shape(569,)Nu importeer je
numpy, omdat jebreast_labelsgaat reshapen om deze te kunnen concateneren metbreast_data, zodat je uiteindelijk eenDataFramekunt maken met zowel de data als de labels.import numpy as nplabels = np.reshape(breast_labels,(569,1))Na het
reshapenvan de labelsconcateneerje de data en de labels langs de tweede as. De uiteindelijke shape van de array is dus569 x 31.final_breast_data = np.concatenate([breast_data,labels],axis=1)final_breast_data.shape(569, 31)Nu importeer je
pandasom hetDataFramevan de einddata te maken en de data in tabelvorm weer te geven.import pandas as pdbreast_dataset = pd.DataFrame(final_breast_data)Laten we snel de features afdrukken die in de borstkankerdataset aanwezig zijn!
features = breast.feature_namesfeaturesarray(['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness', 'mean compactness', 'mean concavity', 'mean concave points', 'mean symmetry', 'mean fractal dimension', 'radius error', 'texture error', 'perimeter error', 'area error', 'smoothness error', 'compactness error', 'concavity error', 'concave points error', 'symmetry error', 'fractal dimension error', 'worst radius', 'worst texture', 'worst perimeter', 'worst area', 'worst smoothness', 'worst compactness', 'worst concavity', 'worst concave points', 'worst symmetry', 'worst fractal dimension'], dtype='<U23')Als je naar de
features-array kijkt, ontbreekt het veldlabel. Daarom moet je dit handmatig toevoegen aan defeatures-array, omdat je deze array gaat gebruiken als kolomnamen van jebreast_dataset-dataframe.features_labels = np.append(features,'label')Top! Nu ken je de kolomnamen toe aan het
breast_dataset-dataframe.breast_dataset.columns = features_labelsLaten we de eerste paar rijen van het dataframe printen.
breast_dataset.head()
mean radius mean texture mean perimeter mean area mean smoothness mean compactness mean concavity mean concave points mean symmetry mean fractal dimension ... worst texture worst perimeter worst area worst smoothness worst compactness worst concavity worst concave points worst symmetry worst fractal dimension label 0 17.99 10.38 122.80 1001.0 0.11840 0.27760 0.3001 0.14710 0.2419 0.07871 ... 17.33 184.60 2019.0 0.1622 0.6656 0.7119 0.2654 0.4601 0.11890 0.0 1 20.57 17.77 132.90 1326.0 0.08474 0.07864 0.0869 0.07017 0.1812 0.05667 ... 23.41 158.80 1956.0 0.1238 0.1866 0.2416 0.1860 0.2750 0.08902 0.0 2 19.69 21.25 130.00 1203.0 0.10960 0.15990 0.1974 0.12790 0.2069 0.05999 ... 25.53 152.50 1709.0 0.1444 0.4245 0.4504 0.2430 0.3613 0.08758 0.0 3 11.42 20.38 77.58 386.1 0.14250 0.28390 0.2414 0.10520 0.2597 0.09744 ... 26.50 98.87 567.7 0.2098 0.8663 0.6869 0.2575 0.6638 0.17300 0.0 4 20.29 14.34 135.10 1297.0 0.10030 0.13280 0.1980 0.10430 0.1809 0.05883 ... 16.67 152.20 1575.0 0.1374 0.2050 0.4000 0.1625 0.2364 0.07678 0.0 5 rijen × 31 kolommen
Aangezien de oorspronkelijke labels in
0,1-formaat zijn, verander je de labels naarbenignenmalignantmet de functie.replace. Je gebruiktinplace=True, waardoor het dataframebreast_datasetwordt aangepast.breast_dataset['label'].replace(0, 'Benign',inplace=True) breast_dataset['label'].replace(1, 'Malignant',inplace=True)Laten we de laatste paar rijen van het
breast_datasetprinten.breast_dataset.tail()
mean radius mean texture mean perimeter mean area mean smoothness mean compactness mean concavity mean concave points mean symmetry mean fractal dimension ... worst texture worst perimeter worst area worst smoothness worst compactness worst concavity worst concave points worst symmetry worst fractal dimension label 564 21.56 22.39 142.00 1479.0 0.11100 0.11590 0.24390 0.13890 0.1726 0.05623 ... 26.40 166.10 2027.0 0.14100 0.21130 0.4107 0.2216 0.2060 0.07115 Benign 565 20.13 28.25 131.20 1261.0 0.09780 0.10340 0.14400 0.09791 0.1752 0.05533 ... 38.25 155.00 1731.0 0.11660 0.19220 0.3215 0.1628 0.2572 0.06637 Benign 566 16.60 28.08 108.30 858.1 0.08455 0.10230 0.09251 0.05302 0.1590 0.05648 ... 34.12 126.70 1124.0 0.11390 0.30940 0.3403 0.1418 0.2218 0.07820 Benign 567 20.60 29.33 140.10 1265.0 0.11780 0.27700 0.35140 0.15200 0.2397 0.07016 ... 39.42 184.60 1821.0 0.16500 0.86810 0.9387 0.2650 0.4087 0.12400 Benign 568 7.76 24.54 47.92 181.0 0.05263 0.04362 0.00000 0.00000 0.1587 0.05884 ... 30.37 59.16 268.6 0.08996 0.06444 0.0000 0.0000 0.2871 0.07039 Malignant 5 rijen × 31 kolommen
CIFAR - 10 data-exploratie
Vervolgens verken je de
CIFAR - 10-afbeeldingsdatasetJe kunt de
CIFAR - 10-dataset laden met een deep learning-bibliotheek genaamdKeras.from keras.datasets import cifar10Nadat je hebt geïmporteerd, gebruik je de methode
.load_data()om de data te downloaden; deze wordt gedownload en opgeslagen in jeKeras-map. Dit kan even duren, afhankelijk van je internetsnelheid.(x_train, y_train), (x_test, y_test) = cifar10.load_data()De bovenstaande code retourneert trainings- en testafbeeldingen samen met de labels.
Laten we snel de shape van de trainings- en testafbeeldingen printen.
print('Traning data shape:', x_train.shape) print('Testing data shape:', x_test.shape)Traning data shape: (50000, 32, 32, 3) Testing data shape: (10000, 32, 32, 3)Laten we ook de shape van de labels printen.
y_train.shape,y_test.shape((50000, 1), (10000, 1))Laten we bovendien het totaal aantal labels en de verschillende soorten klassen in de data bepalen.
# Find the unique numbers from the train labels classes = np.unique(y_train) nClasses = len(classes) print('Total number of outputs : ', nClasses) print('Output classes : ', classes)Total number of outputs : 10 Output classes : [0 1 2 3 4 5 6 7 8 9]Om de
CIFAR-10-afbeeldingen te plotten, importeer jematplotliben gebruik je ook eenmagic (%)-commando%matplotlib inlineom de jupyter-notebook te vertellen dat de output binnen de notebook zelf moet worden getoond!import matplotlib.pyplot as plt %matplotlib inlineVoor een beter begrip maken we een dictionary met klassenamen en hun bijbehorende categorische klasselabels.
label_dict = { 0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog', 6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck', }plt.figure(figsize=[5,5]) # Display the first image in training data plt.subplot(121) curr_img = np.reshape(x_train[0], (32,32,3)) plt.imshow(curr_img) print(plt.title("(Label: " + str(label_dict[y_train[0][0]]) + ")")) # Display the first image in testing data plt.subplot(122) curr_img = np.reshape(x_test[0],(32,32,3)) plt.imshow(curr_img) print(plt.title("(Label: " + str(label_dict[y_test[0][0]]) + ")"))Text(0.5, 1.0, '(Label: frog)') Text(0.5, 1.0, '(Label: cat)')Hoewel de twee bovenstaande afbeeldingen wazig zijn, kun je nog steeds zien dat de eerste afbeelding een kikker is met het label
frog, terwijl de tweede afbeelding een kat is met het labelcat.Datavisualisatie met PCA
Nu komt het spannendste deel van deze tutorial. Zoals je eerder leerde, projecteert PCA hoogdimensionale data naar een laagdimensionale hoofdcomponent. Tijd om dat te visualiseren met behulp van Python!
De borstkankerdata visualiseren
Je begint met het standaardiseren van de data, omdat de output van PCA wordt beïnvloed door de schaal van de features.
Het is gebruikelijk om je data te normaliseren voordat je die aan een machinelearning-algoritme voert.
Om te normaliseren importeer je de module StandardScaler uit de sklearn-bibliotheek en selecteer je alleen de features uit het breast_dataset dat je in de stap Data-exploratie hebt gemaakt. Zodra je de features hebt, pas je schaling toe door fit_transform uit te voeren op de featuredata.
Bij het toepassen van StandardScaler zou elke feature van je data normaal verdeeld moeten zijn, zodat de distributie wordt geschaald naar een gemiddelde van nul en een standaardafwijking van één.
from sklearn.preprocessing import StandardScaler
x = breast_dataset.loc[:, features].values
x = StandardScaler().fit_transform(x) # normalizing the features
x.shape
(569, 30)
Laten we controleren of de genormaliseerde data een gemiddelde van nul en een standaardafwijking van één heeft.
np.mean(x),np.std(x)
(-6.826538293184326e-17, 1.0)
Laten we de genormaliseerde features omzetten naar een tabelvorm met behulp van DataFrame.
feat_cols = ['feature'+str(i) for i in range(x.shape[1])]
normalised_breast = pd.DataFrame(x,columns=feat_cols)
normalised_breast.tail()
| feature0 | feature1 | feature2 | feature3 | feature4 | feature5 | feature6 | feature7 | feature8 | feature9 | ... | feature20 | feature21 | feature22 | feature23 | feature24 | feature25 | feature26 | feature27 | feature28 | feature29 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 2.110995 | 0.721473 | 2.060786 | 2.343856 | 1.041842 | 0.219060 | 1.947285 | 2.320965 | -0.312589 | -0.931027 | ... | 1.901185 | 0.117700 | 1.752563 | 2.015301 | 0.378365 | -0.273318 | 0.664512 | 1.629151 | -1.360158 | -0.709091 |
| 565 | 1.704854 | 2.085134 | 1.615931 | 1.723842 | 0.102458 | -0.017833 | 0.693043 | 1.263669 | -0.217664 | -1.058611 | ... | 1.536720 | 2.047399 | 1.421940 | 1.494959 | -0.691230 | -0.394820 | 0.236573 | 0.733827 | -0.531855 | -0.973978 |
| 566 | 0.702284 | 2.045574 | 0.672676 | 0.577953 | -0.840484 | -0.038680 | 0.046588 | 0.105777 | -0.809117 | -0.895587 | ... | 0.561361 | 1.374854 | 0.579001 | 0.427906 | -0.809587 | 0.350735 | 0.326767 | 0.414069 | -1.104549 | -0.318409 |
| 567 | 1.838341 | 2.336457 | 1.982524 | 1.735218 | 1.525767 | 3.272144 | 3.296944 | 2.658866 | 2.137194 | 1.043695 | ... | 1.961239 | 2.237926 | 2.303601 | 1.653171 | 1.430427 | 3.904848 | 3.197605 | 2.289985 | 1.919083 | 2.219635 |
| 568 | -1.808401 | 1.221792 | -1.814389 | -1.347789 | -3.112085 | -1.150752 | -1.114873 | -1.261820 | -0.820070 | -0.561032 | ... | -1.410893 | 0.764190 | -1.432735 | -1.075813 | -1.859019 | -1.207552 | -1.305831 | -1.745063 | -0.048138 | -0.751207 |
5 rijen × 30 kolommen
Nu komt het kritieke deel: de volgende regels code projecteren de dertigdimensionale Breast Cancer-data naar twee-dimensionale principal components.
Je gebruikt de sklearn-bibliotheek om de module PCA te importeren, en in de PCA-methode geef je het aantal componenten door (n_components=2) en roep je tenslotte fit_transform aan op de verzamelde data. Hier geeft het aantal componenten de lagere dimensie aan waarin je je hoogdimensionale data projecteert.
from sklearn.decomposition import PCA
pca_breast = PCA(n_components=2)
principalComponents_breast = pca_breast.fit_transform(x)
Vervolgens maken we een DataFrame met de waarden van de hoofdcomponenten voor alle 569 samples.
principal_breast_Df = pd.DataFrame(data = principalComponents_breast
, columns = ['principal component 1', 'principal component 2'])
principal_breast_Df.tail()
| principal component 1 | principal component 2 | |
|---|---|---|
| 564 | 6.439315 | -3.576817 |
| 565 | 3.793382 | -3.584048 |
| 566 | 1.256179 | -1.902297 |
| 567 | 10.374794 | 1.672010 |
| 568 | -5.475243 | -0.670637 |
explained_variance_ratio bepalen. Die geeft aan hoeveel informatie of variantie elke hoofdcomponent bevat nadat de data naar een lager-dimensionale subruimte is geprojecteerd.print('Explained variability per principal component: {}'.format(pca_breast.explained_variance_ratio_))
Explained variability per principal component: [0.44272026 0.18971182]
Uit de bovenstaande output blijkt dat principal component 1 44,2% van de informatie bevat, terwijl principal component 2 slechts 19% van de informatie bevat. Een ander punt om op te merken is dat bij het projecteren van dertigdimensionale data naar tweedimensionale data 36,8% informatie verloren ging.
Laten we de 569 samples plotten langs de assen principal component - 1 en principal component - 2. Dit geeft je goed inzicht in hoe je samples over de twee klassen zijn verdeeld.
plt.figure()
plt.figure(figsize=(10,10))
plt.xticks(fontsize=12)
plt.yticks(fontsize=14)
plt.xlabel('Principal Component - 1',fontsize=20)
plt.ylabel('Principal Component - 2',fontsize=20)
plt.title("Principal Component Analysis of Breast Cancer Dataset",fontsize=20)
targets = ['Benign', 'Malignant']
colors = ['r', 'g']
for target, color in zip(targets,colors):
indicesToKeep = breast_dataset['label'] == target
plt.scatter(principal_breast_Df.loc[indicesToKeep, 'principal component 1']
, principal_breast_Df.loc[indicesToKeep, 'principal component 2'], c = color, s = 50)
plt.legend(targets,prop={'size': 15})
<matplotlib.legend.Legend at 0x14552a630>
<Figure size 432x288 with 0 Axes>
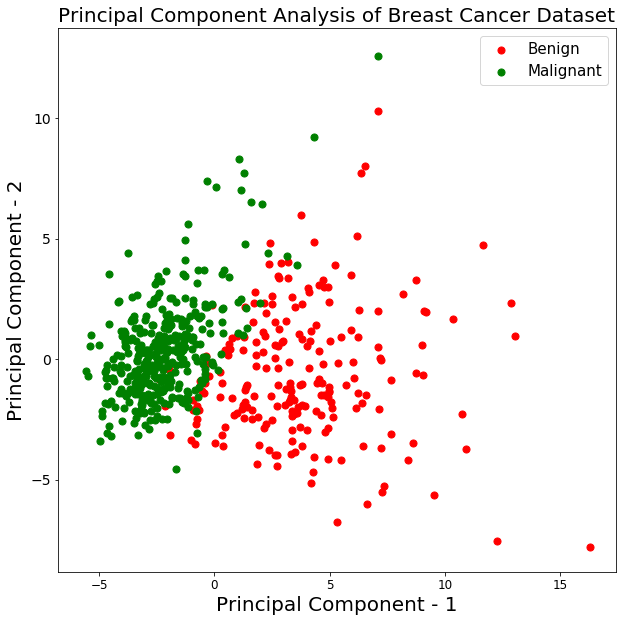
Uit de bovenstaande grafiek kun je afleiden dat de twee klassen benign en malignant, wanneer geprojecteerd naar een tweedimensionale ruimte, tot op zekere hoogte lineair scheidbaar zijn. Je ziet ook dat de klasse benign meer uitgespreid is dan de klasse malignant.
De volgende code voor het visualiseren van de CIFAR-10-data lijkt sterk op de PCA-visualisatie van de Breast Cancer-data.
normaliseren tussen 0 en 1 (inclusief).np.min(x_train),np.max(x_train)
(0.0, 1.0)
x_train = x_train/255.0
np.min(x_train),np.max(x_train)
(0.0, 0.00392156862745098)
x_train.shape
(50000, 32, 32, 3)
Vervolgens maak je een DataFrame dat de pixelwaarden van de afbeeldingen bevat, samen met hun respectieve labels in rij-kolomformaat.
Maar eerst reshapen we de afbeeldingsdimensies van drie naar één (flatten de afbeeldingen).
x_train_flat = x_train.reshape(-1,3072)
feat_cols = ['pixel'+str(i) for i in range(x_train_flat.shape[1])]
df_cifar = pd.DataFrame(x_train_flat,columns=feat_cols)
df_cifar['label'] = y_train
print('Size of the dataframe: {}'.format(df_cifar.shape))
Size of the dataframe: (50000, 3073)
Perfect! De grootte van het dataframe klopt, want er zijn 50.000 trainingsafbeeldingen met elk 3072 pixels en een extra kolom voor labels, dus in totaal 3073.
PCA wordt toegepast op alle kolommen, behalve de laatste, die het label voor elke afbeelding is.
df_cifar.head()
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel3063 | pixel3064 | pixel3065 | pixel3066 | pixel3067 | pixel3068 | pixel3069 | pixel3070 | pixel3071 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.231373 | 0.243137 | 0.247059 | 0.168627 | 0.180392 | 0.176471 | 0.196078 | 0.188235 | 0.168627 | 0.266667 | ... | 0.847059 | 0.721569 | 0.549020 | 0.592157 | 0.462745 | 0.329412 | 0.482353 | 0.360784 | 0.282353 | 6 |
| 1 | 0.603922 | 0.694118 | 0.733333 | 0.494118 | 0.537255 | 0.533333 | 0.411765 | 0.407843 | 0.372549 | 0.400000 | ... | 0.560784 | 0.521569 | 0.545098 | 0.560784 | 0.525490 | 0.556863 | 0.560784 | 0.521569 | 0.564706 | 9 |
| 2 | 1.000000 | 1.000000 | 1.000000 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | ... | 0.305882 | 0.333333 | 0.325490 | 0.309804 | 0.333333 | 0.325490 | 0.313725 | 0.337255 | 0.329412 | 9 |
| 3 | 0.109804 | 0.098039 | 0.039216 | 0.145098 | 0.133333 | 0.074510 | 0.149020 | 0.137255 | 0.078431 | 0.164706 | ... | 0.211765 | 0.184314 | 0.109804 | 0.247059 | 0.219608 | 0.145098 | 0.282353 | 0.254902 | 0.180392 | 4 |
| 4 | 0.666667 | 0.705882 | 0.776471 | 0.658824 | 0.698039 | 0.768627 | 0.694118 | 0.725490 | 0.796078 | 0.717647 | ... | 0.294118 | 0.309804 | 0.321569 | 0.278431 | 0.294118 | 0.305882 | 0.286275 | 0.301961 | 0.313725 | 1 |
5 rijen × 3073 kolommen
fit_transform toe op de trainingsdata. Dit kan een paar seconden duren, want er zijn 50.000 samplespca_cifar = PCA(n_components=2)
principalComponents_cifar = pca_cifar.fit_transform(df_cifar.iloc[:,:-1])
Daarna zet je de hoofdcomponenten voor elk van de 50.000 afbeeldingen om van een numpy-array naar een pandas DataFrame.
principal_cifar_Df = pd.DataFrame(data = principalComponents_cifar
, columns = ['principal component 1', 'principal component 2'])
principal_cifar_Df['y'] = y_train
principal_cifar_Df.head()
| principal component 1 | principal component 2 | y | |
|---|---|---|---|
| 0 | -6.401018 | 2.729039 | 6 |
| 1 | 0.829783 | -0.949943 | 9 |
| 2 | 7.730200 | -11.522102 | 9 |
| 3 | -10.347817 | 0.010738 | 4 |
| 4 | -2.625651 | -4.969240 | 1 |
variantie de hoofdcomponenten bevatten.print('Explained variability per principal component: {}'.format(pca_cifar.explained_variance_ratio_))
Explained variability per principal component: [0.2907663 0.11253144]
Het lijkt erop dat een redelijk deel van de informatie behouden is door principal components 1 en 2, gezien het feit dat de data van 3072 dimensies naar slechts twee hoofdcomponenten is geprojecteerd.
Het is tijd om de CIFAR-10-data in een tweedimensionale ruimte te visualiseren. Onthoud dat er in deze dataset enige semantische overlap tussen klassen is, wat betekent dat een kikker qua vorm enigszins kan lijken op een kat of een hert op een hond; zeker wanneer geprojecteerd in een tweedimensionale ruimte. De verschillen daartussen worden dan mogelijk minder goed vastgelegd.
import seaborn as sns
plt.figure(figsize=(16,10))
sns.scatterplot(
x="principal component 1", y="principal component 2",
hue="y",
palette=sns.color_palette("hls", 10),
data=principal_cifar_Df,
legend="full",
alpha=0.3
)
<matplotlib.axes._subplots.AxesSubplot at 0x12a5ba8d0>
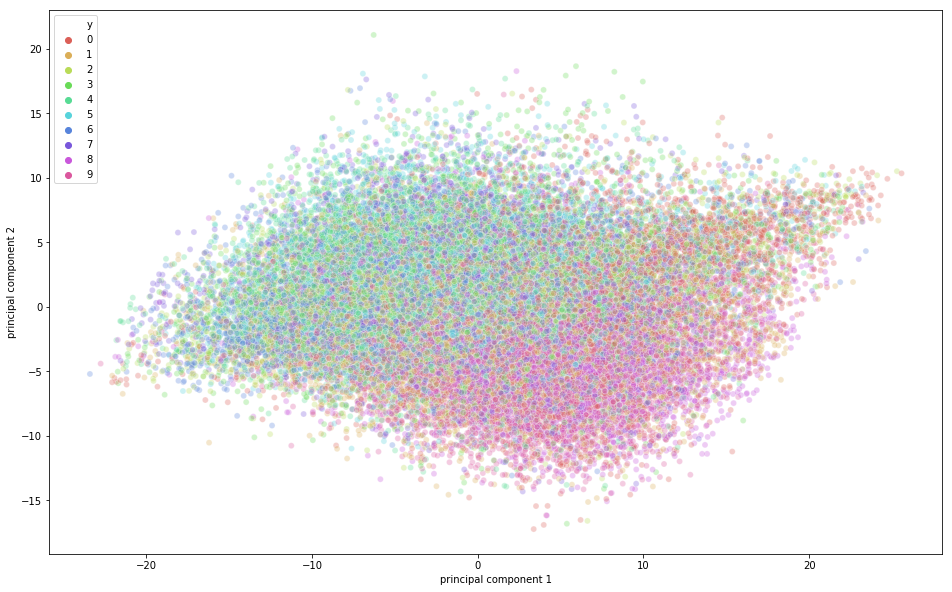
In de bovenstaande figuur zie je dat er variatie is vastgelegd door de hoofdcomponenten, omdat er structuur in de punten zit wanneer ze worden geprojecteerd langs de twee hoofdcomponentassen. De punten die tot dezelfde klasse behoren, liggen dicht bij elkaar, en de punten of afbeeldingen die semantisch sterk verschillen, liggen verder van elkaar.
In dit laatste deel van de tutorial leer je hoe je het trainingsproces van je deep learning-model kunt versnellen met PCA.
Let op: Wil je de basisterminologie leren die in deze sectie wordt gebruikt, bekijk dan gerust deze tutorial.
Laten we eerst de trainings- en testafbeeldingen normaliseren. Als je je herinnert, zijn de trainingsafbeeldingen genormaliseerd in het PCA-visualisatiegedeelte, dus je hoeft alleen de testafbeeldingen te normaliseren. Laten we dat snel doen!
x_test = x_test/255.0
x_test = x_test.reshape(-1,32,32,3)
Laten we de testdata reshapen.
x_test_flat = x_test.reshape(-1,3072)
Vervolgens maak je een instantie van het PCA-model.
Hier kun je ook doorgeven hoeveel variantie je wilt dat PCA vastlegt. Laten we 0,9 als parameter meegeven aan het PCA-model. Dat betekent dat PCA 90% van de variantie zal vasthouden en dat het aantal componenten dat nodig is om 90% variantie te dekken, wordt gebruikt.
Let op: eerder gaf je n_components als parameter mee en kon je vervolgens bepalen hoeveel variantie door die twee componenten werd vastgelegd. Hier geven we expliciet aan hoeveel variantie we willen dat PCA vastlegt en daarom zal n_components variëren op basis van de variantieparameter.
Als je geen variantie doorgeeft, is het aantal componenten gelijk aan de oorspronkelijke dimensie van de data.
pca = PCA(0.9)
Vervolgens fit je de PCA-instantie op de trainingsafbeeldingen.
pca.fit(x_train_flat)
PCA(copy=True, iterated_power='auto', n_components=0.9, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
Nu bepalen we hoeveel n_components PCA gebruikte om 0,9 variantie te dekken.
pca.n_components_
99
Uit de bovenstaande output blijkt dat de dimensie werd teruggebracht tot 99 hoofdcomponenten vanuit de oorspronkelijke 3072 dimensies om 90% variantie te behalen.
Tot slot pas je transform toe op zowel de train- als de testset om een getransformeerde dataset te genereren op basis van de parameters die uit de fit-methode zijn gekomen.
train_img_pca = pca.transform(x_train_flat)
test_img_pca = pca.transform(x_test_flat)
Vervolgens importeren we snel de benodigde libraries om het deep learning-model te draaien.
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.optimizers import RMSprop
Nu zet je je train- en testlabels om naar one-hot-encodering.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
Laten we het aantal epochs, het aantal klassen en de batchgrootte voor je model definiëren.
batch_size = 128
num_classes = 10
epochs = 20
Vervolgens definieer je je Sequential-model!
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(99,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
Laten we de samenvatting van het model printen.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1024) 102400
_________________________________________________________________
dense_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_3 (Dense) (None, 512) 524800
_________________________________________________________________
dense_4 (Dense) (None, 256) 131328
_________________________________________________________________
dense_5 (Dense) (None, 10) 2570
=================================================================
Total params: 1,810,698
Trainable params: 1,810,698
Non-trainable params: 0
_________________________________________________________________
Dan is het tijd om het model te compileren en te trainen!
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(train_img_pca, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(test_img_pca, y_test))
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:2704: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:1257: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 7s - loss: 1.9032 - acc: 0.2962 - val_loss: 1.6925 - val_acc: 0.3875
Epoch 2/20
50000/50000 [==============================] - 7s - loss: 1.6480 - acc: 0.4055 - val_loss: 1.5313 - val_acc: 0.4412
Epoch 3/20
50000/50000 [==============================] - 7s - loss: 1.5205 - acc: 0.4534 - val_loss: 1.4609 - val_acc: 0.4695
Epoch 4/20
50000/50000 [==============================] - 7s - loss: 1.4322 - acc: 0.4849 - val_loss: 1.6164 - val_acc: 0.4503
Epoch 5/20
50000/50000 [==============================] - 7s - loss: 1.3621 - acc: 0.5120 - val_loss: 1.3626 - val_acc: 0.5081
Epoch 6/20
50000/50000 [==============================] - 7s - loss: 1.2995 - acc: 0.5330 - val_loss: 1.4100 - val_acc: 0.4940
Epoch 7/20
50000/50000 [==============================] - 7s - loss: 1.2473 - acc: 0.5529 - val_loss: 1.3589 - val_acc: 0.5251
Epoch 8/20
50000/50000 [==============================] - 7s - loss: 1.2010 - acc: 0.5669 - val_loss: 1.3315 - val_acc: 0.5232
Epoch 9/20
50000/50000 [==============================] - 7s - loss: 1.1524 - acc: 0.5868 - val_loss: 1.3903 - val_acc: 0.5197
Epoch 10/20
50000/50000 [==============================] - 7s - loss: 1.1134 - acc: 0.6013 - val_loss: 1.2722 - val_acc: 0.5499
Epoch 11/20
50000/50000 [==============================] - 7s - loss: 1.0691 - acc: 0.6160 - val_loss: 1.5911 - val_acc: 0.4768
Epoch 12/20
50000/50000 [==============================] - 7s - loss: 1.0325 - acc: 0.6289 - val_loss: 1.2515 - val_acc: 0.5602
Epoch 13/20
50000/50000 [==============================] - 7s - loss: 0.9977 - acc: 0.6420 - val_loss: 1.5678 - val_acc: 0.4914
Epoch 14/20
50000/50000 [==============================] - 8s - loss: 0.9567 - acc: 0.6567 - val_loss: 1.3525 - val_acc: 0.5418
Epoch 15/20
50000/50000 [==============================] - 9s - loss: 0.9158 - acc: 0.6713 - val_loss: 1.3525 - val_acc: 0.5540
Epoch 16/20
50000/50000 [==============================] - 10s - loss: 0.8948 - acc: 0.6816 - val_loss: 1.5633 - val_acc: 0.5156
Epoch 17/20
50000/50000 [==============================] - 9s - loss: 0.8690 - acc: 0.6903 - val_loss: 1.6980 - val_acc: 0.5084
Epoch 18/20
50000/50000 [==============================] - 9s - loss: 0.8586 - acc: 0.7002 - val_loss: 1.6325 - val_acc: 0.5247
Epoch 19/20
50000/50000 [==============================] - 8s - loss: 0.9367 - acc: 0.6853 - val_loss: 1.8253 - val_acc: 0.5165
Epoch 20/20
50000/50000 [==============================] - 8s - loss: 2.3761 - acc: 0.5971 - val_loss: 6.0192 - val_acc: 0.4409
Uit de bovenstaande output blijkt dat de tijd per epoch slechts 7 seconden bedroeg op een CPU. Het model deed het redelijk op de trainingsdata, met 70% nauwkeurigheid, terwijl het slechts 56% nauwkeurigheid behaalde op de testdata. Dit betekent dat het het trainingsmateriaal overfitte. Onthoud echter dat de data werd geprojecteerd naar 99 dimensies vanuit 3072 dimensies en dat het desondanks goed presteerde!
Laten we tot slot bekijken hoeveel tijd het model nodig heeft om te trainen op de oorspronkelijke dataset en welke nauwkeurigheid het kan behalen met hetzelfde deep learning-model.
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(3072,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train_flat, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(x_test_flat, y_test))
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 23s - loss: 2.0657 - acc: 0.2200 - val_loss: 2.0277 - val_acc: 0.2485
Epoch 2/20
50000/50000 [==============================] - 22s - loss: 1.8727 - acc: 0.3166 - val_loss: 1.8428 - val_acc: 0.3215
Epoch 3/20
50000/50000 [==============================] - 22s - loss: 1.7801 - acc: 0.3526 - val_loss: 1.7657 - val_acc: 0.3605
Epoch 4/20
50000/50000 [==============================] - 22s - loss: 1.7141 - acc: 0.3796 - val_loss: 1.6345 - val_acc: 0.4132
Epoch 5/20
50000/50000 [==============================] - 22s - loss: 1.6566 - acc: 0.4001 - val_loss: 1.6384 - val_acc: 0.4076
Epoch 6/20
50000/50000 [==============================] - 22s - loss: 1.6083 - acc: 0.4209 - val_loss: 1.7507 - val_acc: 0.3574
Epoch 7/20
50000/50000 [==============================] - 22s - loss: 1.5626 - acc: 0.4374 - val_loss: 1.7125 - val_acc: 0.4010
Epoch 8/20
50000/50000 [==============================] - 22s - loss: 1.5252 - acc: 0.4486 - val_loss: 1.5914 - val_acc: 0.4321
Epoch 9/20
50000/50000 [==============================] - 24s - loss: 1.4924 - acc: 0.4620 - val_loss: 1.5352 - val_acc: 0.4616
Epoch 10/20
50000/50000 [==============================] - 25s - loss: 1.4627 - acc: 0.4728 - val_loss: 1.4561 - val_acc: 0.4798
Epoch 11/20
50000/50000 [==============================] - 24s - loss: 1.4349 - acc: 0.4820 - val_loss: 1.5044 - val_acc: 0.4723
Epoch 12/20
50000/50000 [==============================] - 24s - loss: 1.4120 - acc: 0.4919 - val_loss: 1.4740 - val_acc: 0.4790
Epoch 13/20
50000/50000 [==============================] - 23s - loss: 1.3913 - acc: 0.4981 - val_loss: 1.4430 - val_acc: 0.4891
Epoch 14/20
50000/50000 [==============================] - 27s - loss: 1.3678 - acc: 0.5098 - val_loss: 1.4323 - val_acc: 0.4888
Epoch 15/20
50000/50000 [==============================] - 27s - loss: 1.3508 - acc: 0.5148 - val_loss: 1.6179 - val_acc: 0.4372
Epoch 16/20
50000/50000 [==============================] - 25s - loss: 1.3443 - acc: 0.5167 - val_loss: 1.5868 - val_acc: 0.4656
Epoch 17/20
50000/50000 [==============================] - 25s - loss: 1.3734 - acc: 0.5101 - val_loss: 1.4756 - val_acc: 0.4913
Epoch 18/20
50000/50000 [==============================] - 26s - loss: 5.5126 - acc: 0.3591 - val_loss: 5.7580 - val_acc: 0.3084
Epoch 19/20
50000/50000 [==============================] - 27s - loss: 5.6346 - acc: 0.3395 - val_loss: 3.7362 - val_acc: 0.3402
Epoch 20/20
50000/50000 [==============================] - 26s - loss: 6.4199 - acc: 0.3030 - val_loss: 13.9429 - val_acc: 0.1326
Voila! Uit de bovenstaande output blijkt duidelijk dat de tijd per epoch ongeveer 23 seconden bedroeg op een CPU, bijna drie keer zoveel als het model dat werd getraind op de PCA-output.
Bovendien zijn zowel de train- als testnauwkeurigheid lager dan de nauwkeurigheid die je behaalde met de 99 hoofdcomponenten als input voor het model.
Door PCA op de trainingsdata toe te passen kon je je deep learning-algoritme dus niet alleen snel trainen, maar behaalde het ook een betere nauwkeurigheid op de testdata vergeleken met het deep learning-algoritme dat op de oorspronkelijke trainingsdata werd getraind.
Ga verder!
Gefeliciteerd met het afronden van de tutorial.
Deze tutorial was een uitstekende en volledige introductie tot PCA in Python, waarin zowel de theoretische als de praktische concepten van PCA aan bod kwamen.
Als je dieper wilt duiken in technieken voor dimensiereductie, lees dan over t-distributed Stochastic Neighbor Embedding, beter bekend als tSNE, een niet-lineaire probabilistische techniek voor dimensiereductie.
Wil je meer leren over onbewaakte leertechnieken zoals PCA, volg dan de cursus Unsupervised Learning in Python van DataCamp.
Referenties voor verdere verdieping:
Leer meer over Python
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
