Corso
Introduzione a Python
4 h
6.9M
Esegui e modifica il codice da questo tutorial online
Esegui codiceL'analisi delle componenti principali (PCA) è una tecnica lineare di riduzione della dimensionalità che può essere usata per estrarre informazioni da uno spazio ad alta dimensionalità proiettandolo in un sotto-spazio a dimensionalità inferiore. Se mastichi l'algebra lineare, potresti anche dire che la PCA consiste nel trovare gli autovettori della matrice di covarianza per identificare le direzioni di massima varianza nei dati.
Una cosa importante da notare sulla PCA è che è una tecnica di riduzione della dimensionalità non supervisionata, quindi puoi raggruppare punti dati simili in base alla correlazione tra loro senza alcuna supervisione (o etichette).
Nota: Feature, dimensioni e variabili si riferiscono tutte alla stessa cosa. Le troverai usate in modo intercambiabile.
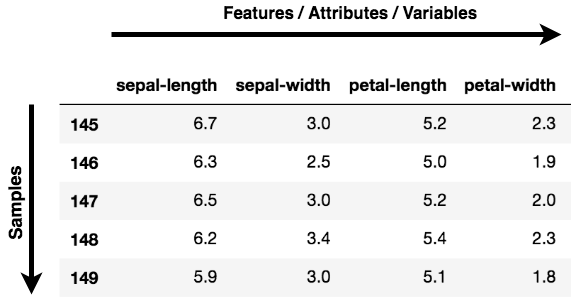
Visualizzazione dei dati: Quando lavori a un problema legato ai dati, la sfida di oggi è la mole di dati e le variabili/feature che la definiscono. Per risolvere un problema in cui i dati sono la chiave, ti serve un'esplorazione approfondita, come capire come le variabili sono correlate o la distribuzione di alcune variabili. Considerando l'elevato numero di variabili o dimensioni lungo le quali i dati sono distribuiti, la visualizzazione può essere impegnativa e quasi impossibile.
Per questo, la PCA può farlo al posto tuo, perché proietta i dati in una dimensione inferiore, permettendoti di visualizzarli in uno spazio 2D o 3D a occhio nudo.
Velocizzare un algoritmo di Machine Learning (ML): Poiché l'idea principale della PCA è la riduzione della dimensionalità, puoi sfruttarla per accelerare i tempi di training e testing del tuo algoritmo di machine learning quando i tuoi dati hanno molte feature e l'apprendimento dell'algoritmo ML è troppo lento.
A un livello astratto, prendi un dataset con molte feature e lo semplifichi selezionando alcune Principal Components dalle feature originali.
Le componenti principali sono la chiave della PCA; rappresentano ciò che c'è sotto il cofano dei tuoi dati. In parole semplici, quando i dati vengono proiettati in una dimensione inferiore (supponiamo tre dimensioni) da uno spazio più alto, le tre dimensioni non sono altro che le tre componenti principali che catturano (o contengono) la maggior parte della varianza (informazione) dei tuoi dati.
Le componenti principali hanno sia direzione che magnitudine. La direzione rappresenta lungo quali assi principali i dati sono maggiormente dispersi o hanno più varianza e la magnitudine indica la quantità di varianza che quella componente principale cattura dei dati quando proiettati su quell'asse. Le componenti principali sono linee rette, e la prima componente principale contiene la maggior varianza nei dati. Ogni componente principale successiva è ortogonale alla precedente e ha una varianza minore. In questo modo, dato un insieme di variabili x correlate su y campioni ottieni un insieme di u componenti principali non correlate sugli stessi y campioni.
Il motivo per cui ottieni componenti principali non correlate dalle feature originali è che le feature correlate contribuiscono alla stessa componente principale, riducendo così le feature originarie in componenti principali non correlate; ognuna rappresenta un diverso insieme di feature correlate con quantità differenti di variabilità. Ogni componente principale rappresenta una percentuale della variabilità totale catturata dai dati.
Nel tutorial di oggi applicheremo la PCA per ottenere insight tramite la visualizzazione dei dati e la useremo anche per velocizzare il nostro algoritmo di machine learning. Per svolgere questi due compiti userai due dataset famosi: Breast Cancer e CIFAR-10. Il primo è un dataset numerico; il secondo è un dataset di immagini.
Prima di caricare i dati, è utile capire e dare un'occhiata al dataset con cui lavorerai!
Il dataset Breast Cancer è un dato multivariato a valori reali che consiste di due classi, dove ciascuna classe indica se una paziente ha il cancro al seno o no. Le due categorie sono: maligno e benigno.
La classe maligna ha 212 campioni, mentre la classe benigna ne ha 357.
Ha 30 feature condivise tra tutte le classi: raggio, texture, perimetro, area, levigatezza, dimensione frattale, ecc.
Puoi scaricare il dataset breast cancer da qui, oppure più semplicemente caricarlo con l'aiuto della libreria sklearn.
Il dataset CIFAR-10 (Canadian Institute For Advanced Research) consiste in 60000 immagini a colori 32x32x3 suddivise in dieci classi, con 6000 immagini per categoria.
Il dataset consiste di 50000 immagini di training e 10000 immagini di test.
Le classi nel dataset sono airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck.
Puoi scaricare il dataset CIFAR da qui, oppure puoi anche caricarlo al volo con l'aiuto di una libreria di deep learning come Keras.
Ora caricherai e analizzerai i dataset Breast Cancer e CIFAR-10. A questo punto hai un'idea della dimensionalità di entrambi i dataset.
Quindi, esploriamoli rapidamente.
Esploriamo prima il dataset Breast Cancer.
Userai il modulo datasets di sklearn e importerai da lì il dataset Breast Cancer.
from sklearn.datasets import load_breast_cancer
load_breast_cancer ti fornirà sia le etichette che i dati. Per ottenere i dati, chiamerai .data e per le etichette .target.
I dati hanno 569 campioni con trenta feature, e ogni campione ha un'etichetta associata. In questo dataset ci sono due etichette.
breast = load_breast_cancer()
breast_data = breast.data
Controlliamo la forma dei dati.
breast_data.shape
(569, 30)
Anche se per questo tutorial non hai bisogno delle etichette, per una migliore comprensione carichiamole e controlliamone la forma.
breast_labels = breast.target
breast_labels.shape
(569,)
Ora importerai numpy perché ridimensionerai (reshape) breast_labels per concatenarlo con breast_data, in modo da poter creare infine un DataFrame che contenga sia dati che etichette.
import numpy as np
labels = np.reshape(breast_labels,(569,1))
Dopo aver reshape le etichette, concatenate i dati e le etichette lungo il secondo asse, il che significa che la forma finale dell'array sarà 569 x 31.
final_breast_data = np.concatenate([breast_data,labels],axis=1)
final_breast_data.shape
(569, 31)
Ora importerai pandas per creare il DataFrame dei dati finali e rappresentarli in forma tabellare.
import pandas as pd
breast_dataset = pd.DataFrame(final_breast_data)
Stampiamo rapidamente le feature presenti nel dataset breast cancer!
features = breast.feature_names
features
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
Se noti, nell'array features manca il campo label. Quindi dovrai aggiungerlo manualmente all'array features dato che assegnerai questo array ai nomi di colonna del dataframe breast_dataset.
features_labels = np.append(features,'label')
Ottimo! Ora assegnerai i nomi di colonna al dataframe breast_dataset.
breast_dataset.columns = features_labels
Stampiamo le prime righe del dataframe.
breast_dataset.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0.0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0.0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0.0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0.0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0.0 |
5 righe × 31 colonne
Poiché le etichette originali sono nel formato 0,1, le cambierai in benign e malignant usando la funzione .replace. Userai inplace=True per modificare il dataframe breast_dataset.
breast_dataset['label'].replace(0, 'Benign',inplace=True)
breast_dataset['label'].replace(1, 'Malignant',inplace=True)
Stampiamo le ultime righe del breast_dataset.
breast_dataset.tail()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | 0.1726 | 0.05623 | ... | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 | Benign |
| 565 | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | 0.1752 | 0.05533 | ... | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 | Benign |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | Benign |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | Benign |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | Malignant |
5 righe × 31 colonne
Successivamente esplorerai il dataset di immagini CIFAR - 10
Puoi caricare il dataset CIFAR - 10 usando una libreria di deep learning chiamata Keras.
from keras.datasets import cifar10
Una volta importato, userai il metodo .load_data() per scaricare i dati; scaricherà e memorizzerà i dati nella tua directory di Keras. Questo può richiedere un po' di tempo in base alla velocità della tua connessione.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
La riga di codice sopra restituisce le immagini di training e test insieme alle etichette.
Stampiamo rapidamente la forma delle immagini di training e di test.
print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)
Traning data shape: (50000, 32, 32, 3)
Testing data shape: (10000, 32, 32, 3)
Stampiamo anche la forma delle etichette.
y_train.shape,y_test.shape
((50000, 1), (10000, 1))
Vediamo anche il numero totale di etichette e le varie classi presenti nei dati.
# Find the unique numbers from the train labels
classes = np.unique(y_train)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
Total number of outputs : 10
Output classes : [0 1 2 3 4 5 6 7 8 9]
Ora, per plottare le immagini CIFAR-10, importerai matplotlib e userai anche un comando magic (%), %matplotlib inline, per dire al notebook Jupyter di mostrare l'output direttamente nel notebook!
import matplotlib.pyplot as plt
%matplotlib inline
Per una migliore comprensione, creiamo un dizionario che conterrà i nomi delle classi con le rispettive etichette categoriali.
label_dict = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck',
}
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
curr_img = np.reshape(x_train[0], (32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_train[0][0]]) + ")"))
# Display the first image in testing data
plt.subplot(122)
curr_img = np.reshape(x_test[0],(32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_test[0][0]]) + ")"))
Text(0.5, 1.0, '(Label: frog)')
Text(0.5, 1.0, '(Label: cat)')

Anche se le due immagini qui sopra sono sfuocate, puoi comunque osservare che la prima immagine è una rana con etichetta frog, mentre la seconda è un gatto con etichetta cat.
Ora arriva la parte più interessante del tutorial. Come hai imparato prima, la PCA proietta i dati ad alta dimensionalità in componenti principali a bassa dimensionalità; è il momento di visualizzarlo con l'aiuto di Python!
Inizi standardizzando i dati perché l'output della PCA è influenzato dalla scala delle feature dei dati.
È prassi comune normalizzare i dati prima di passarli a qualsiasi algoritmo di machine learning.
Per applicare la normalizzazione, importerai il modulo StandardScaler dalla libreria sklearn e selezionerai solo le feature dal breast_dataset creato nel passaggio di esplorazione. Una volta ottenute le feature, applicherai lo scaling usando fit_transform sui dati delle feature.
Applicando StandardScaler, ogni feature dei dati dovrebbe essere normalmente distribuita in modo da scalare la distribuzione a media zero e deviazione standard uno.
from sklearn.preprocessing import StandardScaler
x = breast_dataset.loc[:, features].values
x = StandardScaler().fit_transform(x) # normalizing the features
x.shape
(569, 30)
Verifichiamo che i dati normalizzati abbiano media zero e deviazione standard uno.
np.mean(x),np.std(x)
(-6.826538293184326e-17, 1.0)
Convertiamo le feature normalizzate in formato tabellare con l'aiuto di DataFrame.
feat_cols = ['feature'+str(i) for i in range(x.shape[1])]
normalised_breast = pd.DataFrame(x,columns=feat_cols)
normalised_breast.tail()
| feature0 | feature1 | feature2 | feature3 | feature4 | feature5 | feature6 | feature7 | feature8 | feature9 | ... | feature20 | feature21 | feature22 | feature23 | feature24 | feature25 | feature26 | feature27 | feature28 | feature29 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 2.110995 | 0.721473 | 2.060786 | 2.343856 | 1.041842 | 0.219060 | 1.947285 | 2.320965 | -0.312589 | -0.931027 | ... | 1.901185 | 0.117700 | 1.752563 | 2.015301 | 0.378365 | -0.273318 | 0.664512 | 1.629151 | -1.360158 | -0.709091 |
| 565 | 1.704854 | 2.085134 | 1.615931 | 1.723842 | 0.102458 | -0.017833 | 0.693043 | 1.263669 | -0.217664 | -1.058611 | ... | 1.536720 | 2.047399 | 1.421940 | 1.494959 | -0.691230 | -0.394820 | 0.236573 | 0.733827 | -0.531855 | -0.973978 |
| 566 | 0.702284 | 2.045574 | 0.672676 | 0.577953 | -0.840484 | -0.038680 | 0.046588 | 0.105777 | -0.809117 | -0.895587 | ... | 0.561361 | 1.374854 | 0.579001 | 0.427906 | -0.809587 | 0.350735 | 0.326767 | 0.414069 | -1.104549 | -0.318409 |
| 567 | 1.838341 | 2.336457 | 1.982524 | 1.735218 | 1.525767 | 3.272144 | 3.296944 | 2.658866 | 2.137194 | 1.043695 | ... | 1.961239 | 2.237926 | 2.303601 | 1.653171 | 1.430427 | 3.904848 | 3.197605 | 2.289985 | 1.919083 | 2.219635 |
| 568 | -1.808401 | 1.221792 | -1.814389 | -1.347789 | -3.112085 | -1.150752 | -1.114873 | -1.261820 | -0.820070 | -0.561032 | ... | -1.410893 | 0.764190 | -1.432735 | -1.075813 | -1.859019 | -1.207552 | -1.305831 | -1.745063 | -0.048138 | -0.751207 |
5 righe × 30 colonne
Ora arriva la parte cruciale: le prossime righe di codice proietteranno i dati del Breast Cancer a trenta dimensioni in due componenti principali bidimensionali.
Userai la libreria sklearn per importare il modulo PCA e, nel metodo PCA, passerai il numero di componenti (n_components=2) e infine chiamerai fit_transform sui dati aggregati. Qui il numero di componenti rappresenta la dimensione inferiore in cui proietterai i dati ad alta dimensione.
from sklearn.decomposition import PCA
pca_breast = PCA(n_components=2)
principalComponents_breast = pca_breast.fit_transform(x)
Successivamente, creiamo un DataFrame che conterrà i valori delle componenti principali per tutti i 569 campioni.
principal_breast_Df = pd.DataFrame(data = principalComponents_breast
, columns = ['principal component 1', 'principal component 2'])
principal_breast_Df.tail()
| principal component 1 | principal component 2 | |
|---|---|---|
| 564 | 6.439315 | -3.576817 |
| 565 | 3.793382 | -3.584048 |
| 566 | 1.256179 | -1.902297 |
| 567 | 10.374794 | 1.672010 |
| 568 | -5.475243 | -0.670637 |
explained_variance_ratio. Ti fornirà la quantità di informazione o varianza che ciascuna componente principale detiene dopo la proiezione dei dati in un sotto-spazio a dimensionalità inferiore.print('Explained variability per principal component: {}'.format(pca_breast.explained_variance_ratio_))
Explained variability per principal component: [0.44272026 0.18971182]
Dal risultato sopra puoi osservare che la principal component 1 detiene il 44,2% dell'informazione mentre la principal component 2 ne detiene solo il 19%. Un altro punto da notare è che, proiettando dati a trenta dimensioni in due dimensioni, è andato perso il 36,8% di informazione.
Plottiamo la visualizzazione dei 569 campioni lungo gli assi principal component - 1 e principal component - 2. Dovrebbe darti una buona idea di come i campioni sono distribuiti tra le due classi.
plt.figure()
plt.figure(figsize=(10,10))
plt.xticks(fontsize=12)
plt.yticks(fontsize=14)
plt.xlabel('Principal Component - 1',fontsize=20)
plt.ylabel('Principal Component - 2',fontsize=20)
plt.title("Principal Component Analysis of Breast Cancer Dataset",fontsize=20)
targets = ['Benign', 'Malignant']
colors = ['r', 'g']
for target, color in zip(targets,colors):
indicesToKeep = breast_dataset['label'] == target
plt.scatter(principal_breast_Df.loc[indicesToKeep, 'principal component 1']
, principal_breast_Df.loc[indicesToKeep, 'principal component 2'], c = color, s = 50)
plt.legend(targets,prop={'size': 15})
<matplotlib.legend.Legend at 0x14552a630>
<Figure size 432x288 with 0 Axes>
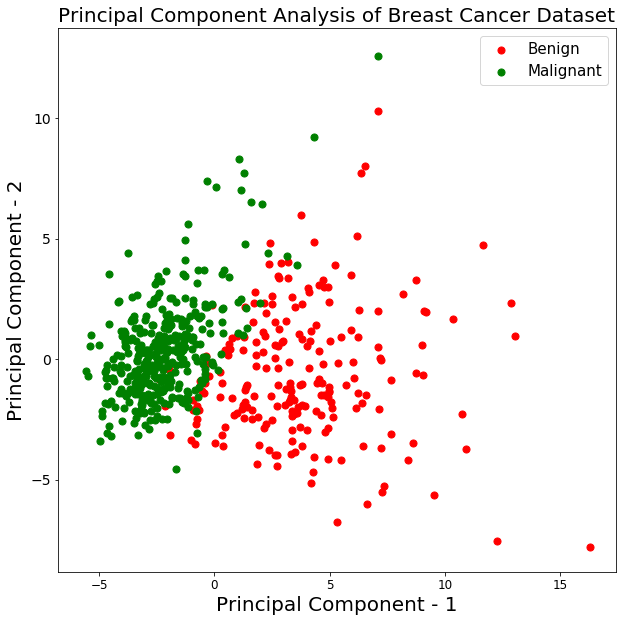
Dal grafico sopra, puoi osservare che le due classi benign e malignant, quando proiettate in uno spazio bidimensionale, possono essere linearmente separabili fino a un certo punto. Un'altra osservazione è che la classe benign è più dispersa rispetto alla classe malignant.
Le righe di codice seguenti per visualizzare i dati CIFAR-10 sono molto simili alla visualizzazione PCA dei dati Breast Cancer.
normalizziamo i pixel tra 0 e 1 inclusi.np.min(x_train),np.max(x_train)
(0.0, 1.0)
x_train = x_train/255.0
np.min(x_train),np.max(x_train)
(0.0, 0.00392156862745098)
x_train.shape
(50000, 32, 32, 3)
Successivamente, creerai un DataFrame che conterrà i valori dei pixel delle immagini insieme alle rispettive etichette in un formato riga-colonna.
Ma prima, ridimensioniamo le immagini da tre dimensioni a una (appiattiamo le immagini).
x_train_flat = x_train.reshape(-1,3072)
feat_cols = ['pixel'+str(i) for i in range(x_train_flat.shape[1])]
df_cifar = pd.DataFrame(x_train_flat,columns=feat_cols)
df_cifar['label'] = y_train
print('Size of the dataframe: {}'.format(df_cifar.shape))
Size of the dataframe: (50000, 3073)
Perfetto! La dimensione del dataframe è corretta, poiché ci sono 50.000 immagini di training, ciascuna con 3072 pixel e una colonna aggiuntiva per le etichette, per un totale di 3073.
La PCA verrà applicata a tutte le colonne tranne l'ultima, che è l'etichetta di ciascuna immagine.
df_cifar.head()
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel3063 | pixel3064 | pixel3065 | pixel3066 | pixel3067 | pixel3068 | pixel3069 | pixel3070 | pixel3071 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.231373 | 0.243137 | 0.247059 | 0.168627 | 0.180392 | 0.176471 | 0.196078 | 0.188235 | 0.168627 | 0.266667 | ... | 0.847059 | 0.721569 | 0.549020 | 0.592157 | 0.462745 | 0.329412 | 0.482353 | 0.360784 | 0.282353 | 6 |
| 1 | 0.603922 | 0.694118 | 0.733333 | 0.494118 | 0.537255 | 0.533333 | 0.411765 | 0.407843 | 0.372549 | 0.400000 | ... | 0.560784 | 0.521569 | 0.545098 | 0.560784 | 0.525490 | 0.556863 | 0.560784 | 0.521569 | 0.564706 | 9 |
| 2 | 1.000000 | 1.000000 | 1.000000 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | ... | 0.305882 | 0.333333 | 0.325490 | 0.309804 | 0.333333 | 0.325490 | 0.313725 | 0.337255 | 0.329412 | 9 |
| 3 | 0.109804 | 0.098039 | 0.039216 | 0.145098 | 0.133333 | 0.074510 | 0.149020 | 0.137255 | 0.078431 | 0.164706 | ... | 0.211765 | 0.184314 | 0.109804 | 0.247059 | 0.219608 | 0.145098 | 0.282353 | 0.254902 | 0.180392 | 4 |
| 4 | 0.666667 | 0.705882 | 0.776471 | 0.658824 | 0.698039 | 0.768627 | 0.694118 | 0.725490 | 0.796078 | 0.717647 | ... | 0.294118 | 0.309804 | 0.321569 | 0.278431 | 0.294118 | 0.305882 | 0.286275 | 0.301961 | 0.313725 | 1 |
5 righe × 3073 colonne
fit_transform ai dati di training; può richiedere qualche secondo poiché ci sono 50.000 campionipca_cifar = PCA(n_components=2)
principalComponents_cifar = pca_cifar.fit_transform(df_cifar.iloc[:,:-1])
Poi convertirai le componenti principali per ciascuna delle 50.000 immagini da array numpy a pandas DataFrame.
principal_cifar_Df = pd.DataFrame(data = principalComponents_cifar
, columns = ['principal component 1', 'principal component 2'])
principal_cifar_Df['y'] = y_train
principal_cifar_Df.head()
| principal component 1 | principal component 2 | y | |
|---|---|---|---|
| 0 | -6.401018 | 2.729039 | 6 |
| 1 | 0.829783 | -0.949943 | 9 |
| 2 | 7.730200 | -11.522102 | 9 |
| 3 | -10.347817 | 0.010738 | 4 |
| 4 | -2.625651 | -4.969240 | 1 |
varianza catturano le componenti principali.print('Explained variability per principal component: {}'.format(pca_cifar.explained_variance_ratio_))
Explained variability per principal component: [0.2907663 0.11253144]
Bene, sembra che una quantità decente di informazione sia stata trattenuta dalle componenti principali 1 e 2, considerando che i dati sono stati proiettati da 3072 dimensioni a sole due componenti principali.
È ora di visualizzare i dati CIFAR-10 in uno spazio bidimensionale. Ricorda che in questo dataset c'è una certa sovrapposizione semantica tra le classi, il che significa che una rana può avere una forma leggermente simile a quella di un gatto o un cervo a quella di un cane; soprattutto quando sono proiettate in due dimensioni. Le differenze tra loro potrebbero non essere catturate così bene.
import seaborn as sns
plt.figure(figsize=(16,10))
sns.scatterplot(
x="principal component 1", y="principal component 2",
hue="y",
palette=sns.color_palette("hls", 10),
data=principal_cifar_Df,
legend="full",
alpha=0.3
)
<matplotlib.axes._subplots.AxesSubplot at 0x12a5ba8d0>
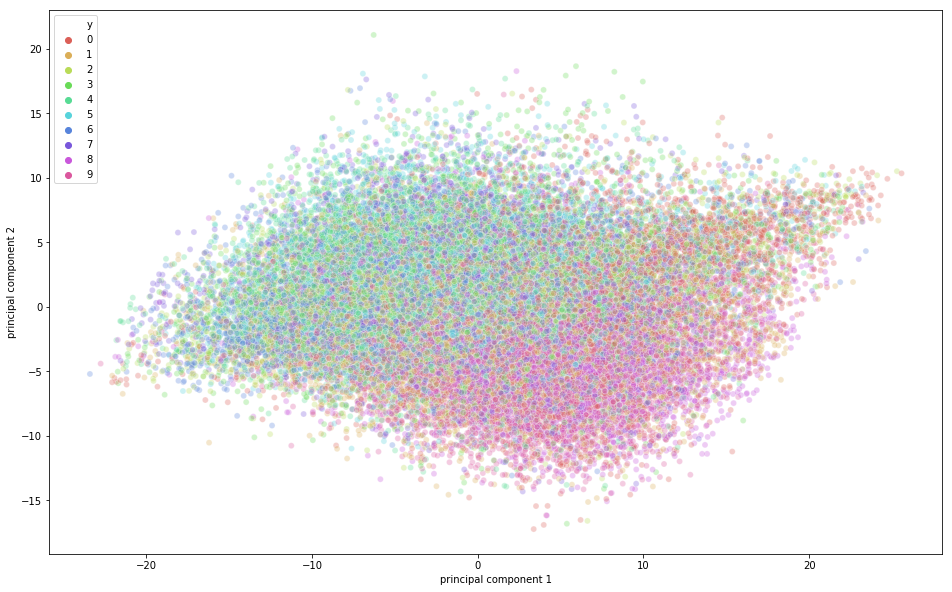
Dalla figura sopra, puoi osservare che una certa variazione è stata catturata dalle componenti principali, poiché c'è una certa struttura nei punti quando proiettati lungo i due assi delle componenti principali. I punti appartenenti alla stessa classe sono vicini tra loro, e i punti o le immagini molto diverse semanticamente sono più lontani tra loro.
In questo segmento finale del tutorial, imparerai come velocizzare il processo di training del tuo modello di Deep Learning usando la PCA.
Nota: Per imparare la terminologia di base usata in questa sezione, dai un'occhiata a questo tutorial.
Per prima cosa, normalizziamo le immagini di training e di test. Se ricordi, le immagini di training sono state normalizzate nella parte di visualizzazione PCA, quindi devi solo normalizzare le immagini di test. Facciamolo rapidamente!
x_test = x_test/255.0
x_test = x_test.reshape(-1,32,32,3)
reshapeiamo i dati di test.
x_test_flat = x_test.reshape(-1,3072)
Successivamente, creerai l'istanza del modello PCA.
Qui puoi anche passare quanta varianza vuoi che la PCA catturi. Passiamo 0,9 come parametro al modello PCA, il che significa che la PCA manterrà il 90% della varianza e utilizzerà il numero di componenti necessario per catturare il 90% della varianza.
Nota che prima hai passato n_components come parametro e potevi poi scoprire quanta varianza era stata catturata da quelle due componenti. Qui, invece, specifichiamo esplicitamente quanta varianza vogliamo che la PCA catturi e, di conseguenza, n_components varierà in base al parametro di varianza.
Se non passi alcuna varianza, allora il numero di componenti sarà uguale alla dimensione originale dei dati.
pca = PCA(0.9)
Poi effettuerai il fit dell'istanza PCA sulle immagini di training.
pca.fit(x_train_flat)
PCA(copy=True, iterated_power='auto', n_components=0.9, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
Ora scopriamo quanti n_components la PCA ha usato per catturare 0,9 di varianza.
pca.n_components_
99
Dal risultato sopra, puoi osservare che per raggiungere il 90% di varianza, la dimensione è stata ridotta a 99 componenti principali dalle 3072 dimensioni originali.
Infine, applicherai transform sia al training set che al test set per generare un dataset trasformato a partire dai parametri generati dal metodo fit.
train_img_pca = pca.transform(x_train_flat)
test_img_pca = pca.transform(x_test_flat)
Ora importiamo rapidamente le librerie necessarie per eseguire il modello di deep learning.
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.optimizers import RMSprop
Ora convertirai le etichette di training e di test in vettori one-hot.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
Definiamo il numero di epoche, il numero di classi e la dimensione del batch per il tuo modello.
batch_size = 128
num_classes = 10
epochs = 20
Successivamente, definirai il tuo modello Sequential!
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(99,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
Stampiamo il sommario del modello.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1024) 102400
_________________________________________________________________
*dense_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_3 (Dense) (None, 512) 524800
_________________________________________________________________
dense_4 (Dense) (None, 256) 131328
_________________________________________________________________
dense_5 (Dense) (None, 10) 2570
=================================================================
Total params: 1,810,698
Trainable params: 1,810,698
Non-trainable params: 0
_________________________________________________________________
Infine, è il momento di compilare e addestrare il modello!
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(train_img_pca, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(test_img_pca, y_test))
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:2704: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:1257: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 7s - loss: 1.9032 - acc: 0.2962 - val_loss: 1.6925 - val_acc: 0.3875
Epoch 2/20
50000/50000 [==============================] - 7s - loss: 1.6480 - acc: 0.4055 - val_loss: 1.5313 - val_acc: 0.4412
Epoch 3/20
50000/50000 [==============================] - 7s - loss: 1.5205 - acc: 0.4534 - val_loss: 1.4609 - val_acc: 0.4695
Epoch 4/20
50000/50000 [==============================] - 7s - loss: 1.4322 - acc: 0.4849 - val_loss: 1.6164 - val_acc: 0.4503
Epoch 5/20
50000/50000 [==============================] - 7s - loss: 1.3621 - acc: 0.5120 - val_loss: 1.3626 - val_acc: 0.5081
Epoch 6/20
50000/50000 [==============================] - 7s - loss: 1.2995 - acc: 0.5330 - val_loss: 1.4100 - val_acc: 0.4940
Epoch 7/20
50000/50000 [==============================] - 7s - loss: 1.2473 - acc: 0.5529 - val_loss: 1.3589 - val_acc: 0.5251
Epoch 8/20
50000/50000 [==============================] - 7s - loss: 1.2010 - acc: 0.5669 - val_loss: 1.3315 - val_acc: 0.5232
Epoch 9/20
50000/50000 [==============================] - 7s - loss: 1.1524 - acc: 0.5868 - val_loss: 1.3903 - val_acc: 0.5197
Epoch 10/20
50000/50000 [==============================] - 7s - loss: 1.1134 - acc: 0.6013 - val_loss: 1.2722 - val_acc: 0.5499
Epoch 11/20
50000/50000 [==============================] - 7s - loss: 1.0691 - acc: 0.6160 - val_loss: 1.5911 - val_acc: 0.4768
Epoch 12/20
50000/50000 [==============================] - 7s - loss: 1.0325 - acc: 0.6289 - val_loss: 1.2515 - val_acc: 0.5602
Epoch 13/20
50000/50000 [==============================] - 7s - loss: 0.9977 - acc: 0.6420 - val_loss: 1.5678 - val_acc: 0.4914
Epoch 14/20
50000/50000 [==============================] - 8s - loss: 0.9567 - acc: 0.6567 - val_loss: 1.3525 - val_acc: 0.5418
Epoch 15/20
50000/50000 [==============================] - 9s - loss: 0.9158 - acc: 0.6713 - val_loss: 1.3525 - val_acc: 0.5540
Epoch 16/20
50000/50000 [==============================] - 10s - loss: 0.8948 - acc: 0.6816 - val_loss: 1.5633 - val_acc: 0.5156
Epoch 17/20
50000/50000 [==============================] - 9s - loss: 0.8690 - acc: 0.6903 - val_loss: 1.6980 - val_acc: 0.5084
Epoch 18/20
50000/50000 [==============================] - 9s - loss: 0.8586 - acc: 0.7002 - val_loss: 1.6325 - val_acc: 0.5247
Epoch 19/20
50000/50000 [==============================] - 8s - loss: 0.9367 - acc: 0.6853 - val_loss: 1.8253 - val_acc: 0.5165
Epoch 20/20
50000/50000 [==============================] - 8s - loss: 2.3761 - acc: 0.5971 - val_loss: 6.0192 - val_acc: 0.4409
Dal risultato sopra, puoi osservare che il tempo impiegato per addestrare ogni epoca è stato di soli 7 secondi su CPU. Il modello ha fatto un discreto lavoro sui dati di training, raggiungendo il 70% di accuratezza, mentre ha raggiunto solo il 56% sui dati di test. Questo significa che ha overfittato i dati di training. Tuttavia, ricorda che i dati sono stati proiettati a 99 dimensioni dalle 3072 dimensioni originali e, nonostante ciò, ha fatto un ottimo lavoro!
Infine, vediamo quanto tempo impiega il modello ad addestrarsi sul dataset originale e quanta accuratezza può ottenere usando lo stesso modello di deep learning.
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(3072,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train_flat, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(x_test_flat, y_test))
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 23s - loss: 2.0657 - acc: 0.2200 - val_loss: 2.0277 - val_acc: 0.2485
Epoch 2/20
50000/50000 [==============================] - 22s - loss: 1.8727 - acc: 0.3166 - val_loss: 1.8428 - val_acc: 0.3215
Epoch 3/20
50000/50000 [==============================] - 22s - loss: 1.7801 - acc: 0.3526 - val_loss: 1.7657 - val_acc: 0.3605
Epoch 4/20
50000/50000 [==============================] - 22s - loss: 1.7141 - acc: 0.3796 - val_loss: 1.6345 - val_acc: 0.4132
Epoch 5/20
50000/50000 [==============================] - 22s - loss: 1.6566 - acc: 0.4001 - val_loss: 1.6384 - val_acc: 0.4076
Epoch 6/20
50000/50000 [==============================] - 22s - loss: 1.6083 - acc: 0.4209 - val_loss: 1.7507 - val_acc: 0.3574
Epoch 7/20
50000/50000 [==============================] - 22s - loss: 1.5626 - acc: 0.4374 - val_loss: 1.7125 - val_acc: 0.4010
Epoch 8/20
50000/50000 [==============================] - 22s - loss: 1.5252 - acc: 0.4486 - val_loss: 1.5914 - val_acc: 0.4321
Epoch 9/20
50000/50000 [==============================] - 24s - loss: 1.4924 - acc: 0.4620 - val_loss: 1.5352 - val_acc: 0.4616
Epoch 10/20
50000/50000 [==============================] - 25s - loss: 1.4627 - acc: 0.4728 - val_loss: 1.4561 - val_acc: 0.4798
Epoch 11/20
50000/50000 [==============================] - 24s - loss: 1.4349 - acc: 0.4820 - val_loss: 1.5044 - val_acc: 0.4723
Epoch 12/20
50000/50000 [==============================] - 24s - loss: 1.4120 - acc: 0.4919 - val_loss: 1.4740 - val_acc: 0.4790
Epoch 13/20
50000/50000 [==============================] - 23s - loss: 1.3913 - acc: 0.4981 - val_loss: 1.4430 - val_acc: 0.4891
Epoch 14/20
50000/50000 [==============================] - 27s - loss: 1.3678 - acc: 0.5098 - val_loss: 1.4323 - val_acc: 0.4888
Epoch 15/20
50000/50000 [==============================] - 27s - loss: 1.3508 - acc: 0.5148 - val_loss: 1.6179 - val_acc: 0.4372
Epoch 16/20
50000/50000 [==============================] - 25s - loss: 1.3443 - acc: 0.5167 - val_loss: 1.5868 - val_acc: 0.4656
Epoch 17/20
50000/50000 [==============================] - 25s - loss: 1.3734 - acc: 0.5101 - val_loss: 1.4756 - val_acc: 0.4913
Epoch 18/20
50000/50000 [==============================] - 26s - loss: 5.5126 - acc: 0.3591 - val_loss: 5.7580 - val_acc: 0.3084
Epoch 19/20
50000/50000 [==============================] - 27s - loss: 5.6346 - acc: 0.3395 - val_loss: 3.7362 - val_acc: 0.3402
Epoch 20/20
50000/50000 [==============================] - 26s - loss: 6.4199 - acc: 0.3030 - val_loss: 13.9429 - val_acc: 0.1326
Voilà! Dal risultato sopra è abbastanza evidente che il tempo impiegato per addestrare ogni epoca è stato di circa 23 secondi su CPU, quasi tre volte rispetto al modello addestrato sull'output della PCA.
Inoltre, sia l'accuratezza di training che quella di test sono inferiori all'accuratezza ottenuta con 99 componenti principali come input al modello.
Quindi, applicando la PCA ai dati di training sei riuscito ad addestrare il tuo algoritmo di deep learning non solo più velocemente, ma ha anche ottenuto una migliore accuratezza sui dati di test rispetto all'algoritmo addestrato con i dati originali.
Vai oltre!
Congratulazioni per aver completato il tutorial.
Questo tutorial è stata un'ottima e completa introduzione alla PCA in Python, che ha coperto sia i concetti teorici sia quelli pratici della PCA.
Se vuoi approfondire le tecniche di riduzione della dimensionalità, considera di leggere del t-distributed Stochastic Neighbor Embedding, comunemente noto come tSNE, una tecnica probabilistica non lineare di riduzione della dimensionalità.
Se vuoi imparare di più sulle tecniche di apprendimento non supervisionato come la PCA, segui il corso di DataCamp Unsupervised Learning in Python.
Riferimenti per approfondire:
Scopri di più su Python
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

