Courses
Nhập môn Python
4 giờ
6.9M
Chạy và chỉnh sửa mã từ hướng dẫn trực tuyến này.
Chạy mãPhân tích thành phần chính (PCA) là một kỹ thuật giảm số chiều tuyến tính dùng để trích xuất thông tin từ không gian có số chiều cao bằng cách chiếu nó xuống một không gian con có số chiều thấp hơn. Nếu bạn quen với ngôn ngữ của đại số tuyến tính, bạn cũng có thể nói rằng PCA là việc tìm vector riêng của ma trận hiệp phương sai để xác định các hướng có phương sai lớn nhất trong dữ liệu.
Một điểm quan trọng về PCA là đây là kỹ thuật giảm số chiều không giám sát, vì vậy bạn có thể gom cụm các điểm dữ liệu tương tự dựa trên tương quan của chúng mà không cần giám sát (hay nhãn).
Lưu ý: Features, Dimensions và Variables đều chỉ cùng một khái niệm. Bạn sẽ thấy chúng được dùng thay thế cho nhau.
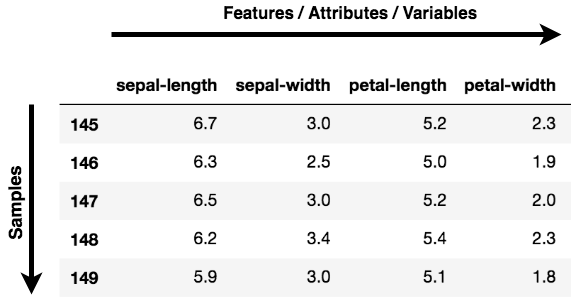
Trực quan hóa dữ liệu: Khi làm việc với bất kỳ bài toán dữ liệu nào, thách thức ngày nay là khối lượng dữ liệu khổng lồ và số biến/đặc trưng mô tả dữ liệu đó. Để giải một bài toán mà dữ liệu là chìa khóa, bạn cần khám phá dữ liệu sâu, như tìm mối tương quan giữa các biến hoặc hiểu phân phối của một vài biến. Xét rằng có rất nhiều biến hay chiều mà dữ liệu được phân bố theo, trực quan hóa có thể là một thách thức và gần như bất khả thi.
Vì vậy, PCA có thể làm điều đó cho bạn vì nó chiếu dữ liệu xuống số chiều thấp hơn, cho phép bạn trực quan hóa dữ liệu trong không gian 2D hoặc 3D bằng mắt thường.
Tăng tốc thuật toán Machine Learning (ML): Vì ý tưởng chính của PCA là giảm số chiều, bạn có thể tận dụng điều này để tăng tốc thời gian huấn luyện và kiểm thử thuật toán ML của mình khi dữ liệu có rất nhiều đặc trưng và quá trình học của thuật toán ML quá chậm.
Ở mức trừu tượng, bạn lấy một tập dữ liệu có nhiều đặc trưng và đơn giản hóa nó bằng cách chọn một vài Thành phần Chính từ các đặc trưng gốc.
Thành phần chính là chìa khóa của PCA; chúng đại diện cho “điều nằm dưới nắp capo” dữ liệu của bạn. Nói đơn giản, khi dữ liệu được chiếu xuống không gian có số chiều thấp hơn (giả sử ba chiều) từ không gian có số chiều cao, thì ba chiều đó chính là ba thành phần chính nắm bắt (hoặc giữ) phần lớn phương sai (thông tin) của dữ liệu.
Các thành phần chính có cả hướng và độ lớn. Hướng biểu thị dọc theo các trục chính nào dữ liệu trải rộng nhất hay có phương sai lớn nhất, và độ lớn biểu thị lượng phương sai mà thành phần chính đó nắm bắt của dữ liệu khi chiếu lên trục đó. Các thành phần chính là các đường thẳng, và thành phần chính thứ nhất giữ nhiều phương sai nhất trong dữ liệu. Mỗi thành phần chính kế tiếp trực giao với thành phần trước và có phương sai nhỏ hơn. Theo cách này, với một tập gồm x biến có tương quan trên y mẫu, bạn thu được một tập gồm u thành phần chính không tương quan trên cùng y mẫu.
Lý do bạn có được các thành phần chính không tương quan từ các đặc trưng gốc là vì các đặc trưng có tương quan cùng đóng góp vào một thành phần chính, từ đó giảm các đặc trưng dữ liệu gốc thành các thành phần chính không tương quan; mỗi thành phần đại diện cho một tập các đặc trưng có tương quan khác nhau với mức độ biến thiên khác nhau. Mỗi thành phần chính đại diện cho một tỷ lệ phần trăm tổng biến thiên được nắm bắt từ dữ liệu.
Trong hướng dẫn hôm nay, chúng ta sẽ áp dụng PCA nhằm mục đích khám phá thông tin thông qua trực quan hóa dữ liệu, và cũng áp dụng PCA để tăng tốc thuật toán machine learning. Để hoàn thành hai nhiệm vụ này, bạn sẽ dùng hai bộ dữ liệu nổi tiếng: Breast Cancer và CIFAR-10. Bộ thứ nhất là dữ liệu số; bộ thứ hai là dữ liệu ảnh.
Trước khi tải dữ liệu, sẽ tốt hơn nếu bạn hiểu và nhìn qua dữ liệu mà bạn sẽ làm việc!
Bộ dữ liệu Breast Cancer là dữ liệu đa biến giá trị thực gồm hai lớp, trong đó mỗi lớp cho biết bệnh nhân có ung thư vú hay không. Hai hạng mục là: ác tính (malignant) và lành tính (benign).
Lớp ác tính có 212 mẫu, trong khi lớp lành tính có 357 mẫu.
Nó có 30 đặc trưng dùng chung cho tất cả các lớp: bán kính, kết cấu, chu vi, diện tích, độ mượt, chiều phân dạng, v.v.
Bạn có thể tải bộ dữ liệu breast cancer từ đây, hoặc cách dễ hơn là tải trực tiếp bằng thư viện sklearn.
Bộ dữ liệu CIFAR-10 (Canadian Institute For Advanced Research) gồm 60000 ảnh màu 32x32x3 thuộc mười lớp, với 6000 ảnh mỗi lớp.
Bộ dữ liệu gồm 50000 ảnh huấn luyện và 10000 ảnh kiểm thử.
Các lớp trong bộ dữ liệu gồm airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck.
Bạn có thể tải bộ dữ liệu CIFAR từ đây, hoặc tải ngay trong quá trình chạy bằng thư viện học sâu như Keras.
Bây giờ bạn sẽ tải và phân tích các bộ dữ liệu Breast Cancer và CIFAR-10. Đến lúc này bạn đã có hình dung về số chiều của cả hai bộ dữ liệu.
Vậy hãy nhanh chóng khám phá cả hai bộ dữ liệu.
Trước hết, hãy khám phá bộ dữ liệu Breast Cancer.
Bạn sẽ dùng mô-đun datasets của sklearn và nhập bộ dữ liệu Breast Cancer từ đó.
from sklearn.datasets import load_breast_cancer
load_breast_cancer sẽ cung cấp cả nhãn và dữ liệu. Để lấy dữ liệu, bạn gọi .data và để lấy nhãn thì gọi .target.
Dữ liệu có 569 mẫu với 30 đặc trưng, và mỗi mẫu có một nhãn đi kèm. Có hai nhãn trong bộ dữ liệu này.
breast = load_breast_cancer()
breast_data = breast.data
Hãy kiểm tra kích thước của dữ liệu.
breast_data.shape
(569, 30)
Dù trong hướng dẫn này bạn không cần nhãn, nhưng để hiểu rõ hơn, hãy tải nhãn và kiểm tra kích thước của chúng.
breast_labels = breast.target
breast_labels.shape
(569,)
Giờ bạn sẽ nhập numpy vì bạn sẽ reshape breast_labels để nối với breast_data nhằm cuối cùng tạo một DataFrame chứa cả dữ liệu và nhãn.
import numpy as np
labels = np.reshape(breast_labels,(569,1))
Sau khi reshape nhãn, bạn sẽ concatenate dữ liệu và nhãn theo trục thứ hai, nghĩa là kích thước mảng cuối cùng sẽ là 569 x 31.
final_breast_data = np.concatenate([breast_data,labels],axis=1)
final_breast_data.shape
(569, 31)
Giờ bạn sẽ nhập pandas để tạo DataFrame từ dữ liệu cuối cùng nhằm biểu diễn dữ liệu dưới dạng bảng.
import pandas as pd
breast_dataset = pd.DataFrame(final_breast_data)
Hãy in nhanh các đặc trưng có trong bộ dữ liệu breast cancer!
features = breast.feature_names
features
array(['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error',
'fractal dimension error', 'worst radius', 'worst texture',
'worst perimeter', 'worst area', 'worst smoothness',
'worst compactness', 'worst concavity', 'worst concave points',
'worst symmetry', 'worst fractal dimension'], dtype='<U23')
Nếu bạn để ý trong mảng features, trường label bị thiếu. Vì vậy bạn sẽ phải thêm thủ công nó vào mảng features vì bạn sẽ dùng mảng này làm tên cột cho dataframe breast_dataset.
features_labels = np.append(features,'label')
Tuyệt! Giờ bạn sẽ gán tên cột cho dataframe breast_dataset.
breast_dataset.columns = features_labels
Hãy in vài hàng đầu tiên của dataframe.
breast_dataset.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0.0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0.0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0.0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0.0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0.0 |
5 hàng × 31 cột
Vì các nhãn gốc ở dạng 0,1, bạn sẽ đổi nhãn thành benign và malignant bằng hàm .replace. Bạn sẽ dùng inplace=True để chỉnh sửa trực tiếp dataframe breast_dataset.
breast_dataset['label'].replace(0, 'Benign',inplace=True)
breast_dataset['label'].replace(1, 'Malignant',inplace=True)
Hãy in vài hàng cuối của breast_dataset.
breast_dataset.tail()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 21.56 | 22.39 | 142.00 | 1479.0 | 0.11100 | 0.11590 | 0.24390 | 0.13890 | 0.1726 | 0.05623 | ... | 26.40 | 166.10 | 2027.0 | 0.14100 | 0.21130 | 0.4107 | 0.2216 | 0.2060 | 0.07115 | Benign |
| 565 | 20.13 | 28.25 | 131.20 | 1261.0 | 0.09780 | 0.10340 | 0.14400 | 0.09791 | 0.1752 | 0.05533 | ... | 38.25 | 155.00 | 1731.0 | 0.11660 | 0.19220 | 0.3215 | 0.1628 | 0.2572 | 0.06637 | Benign |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | Benign |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | Benign |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | Malignant |
5 hàng × 31 cột
Tiếp theo, bạn sẽ khám phá bộ dữ liệu ảnh CIFAR - 10
Bạn có thể tải bộ dữ liệu CIFAR - 10 bằng thư viện học sâu có tên Keras.
from keras.datasets import cifar10
Sau khi nhập, bạn sẽ dùng phương thức .load_data() để tải dữ liệu, phương thức này sẽ tải và lưu dữ liệu vào thư mục Keras của bạn. Thời gian có thể lâu hay nhanh tùy tốc độ Internet.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
Dòng code trên trả về ảnh huấn luyện và kiểm thử cùng với nhãn của chúng.
Hãy in nhanh kích thước ảnh huấn luyện và kiểm thử.
print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)
Traning data shape: (50000, 32, 32, 3)
Testing data shape: (10000, 32, 32, 3)
Hãy in cả kích thước của nhãn.
y_train.shape,y_test.shape
((50000, 1), (10000, 1))
Hãy xem tổng số nhãn và các loại lớp mà dữ liệu có.
# Find the unique numbers from the train labels
classes = np.unique(y_train)
nClasses = len(classes)
print('Total number of outputs : ', nClasses)
print('Output classes : ', classes)
Total number of outputs : 10
Output classes : [0 1 2 3 4 5 6 7 8 9]
Giờ để vẽ ảnh CIFAR-10, bạn sẽ nhập matplotlib và dùng lệnh magic (%) %matplotlib inline để yêu cầu jupyter notebook hiển thị kết quả ngay trong notebook!
import matplotlib.pyplot as plt
%matplotlib inline
Để hiểu rõ hơn, hãy tạo một từ điển chứa tên lớp với nhãn phân loại tương ứng.
label_dict = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck',
}
plt.figure(figsize=[5,5])
# Display the first image in training data
plt.subplot(121)
curr_img = np.reshape(x_train[0], (32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_train[0][0]]) + ")"))
# Display the first image in testing data
plt.subplot(122)
curr_img = np.reshape(x_test[0],(32,32,3))
plt.imshow(curr_img)
print(plt.title("(Label: " + str(label_dict[y_test[0][0]]) + ")"))
Text(0.5, 1.0, '(Label: frog)')
Text(0.5, 1.0, '(Label: cat)')

Dù hai ảnh trên bị mờ, bạn vẫn có thể phần nào nhận ra ảnh đầu tiên là một con ếch với nhãn frog, còn ảnh thứ hai là một con mèo với nhãn cat.
Bây giờ đến phần thú vị nhất của hướng dẫn. Như bạn đã học trước đó rằng PCA chiếu dữ liệu có số chiều cao xuống các thành phần chính có số chiều thấp, giờ là lúc trực quan hóa điều đó bằng Python!
Bạn bắt đầu bằng cách Chuẩn hóa dữ liệu vì đầu ra của PCA bị ảnh hưởng bởi thang đo của các đặc trưng dữ liệu.
Chuẩn hóa dữ liệu trước khi đưa vào bất kỳ thuật toán machine learning nào là thực hành phổ biến.
Để chuẩn hóa, bạn sẽ nhập mô-đun StandardScaler từ thư viện sklearn và chỉ chọn các đặc trưng từ breast_dataset mà bạn đã tạo ở bước Khám phá dữ liệu. Khi có đặc trưng, bạn sẽ áp dụng scale bằng cách gọi fit_transform trên dữ liệu đặc trưng.
Khi áp dụng StandardScaler, mỗi đặc trưng của dữ liệu nên phân phối xấp xỉ chuẩn để nó scale phân phối về trung bình 0 và độ lệch chuẩn 1.
from sklearn.preprocessing import StandardScaler
x = breast_dataset.loc[:, features].values
x = StandardScaler().fit_transform(x) # normalizing the features
x.shape
(569, 30)
Hãy kiểm tra xem dữ liệu đã chuẩn hóa có trung bình bằng 0 và độ lệch chuẩn bằng 1 hay không.
np.mean(x),np.std(x)
(-6.826538293184326e-17, 1.0)
Hãy chuyển các đặc trưng đã chuẩn hóa sang dạng bảng với DataFrame.
feat_cols = ['feature'+str(i) for i in range(x.shape[1])]
normalised_breast = pd.DataFrame(x,columns=feat_cols)
normalised_breast.tail()
| feature0 | feature1 | feature2 | feature3 | feature4 | feature5 | feature6 | feature7 | feature8 | feature9 | ... | feature20 | feature21 | feature22 | feature23 | feature24 | feature25 | feature26 | feature27 | feature28 | feature29 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 564 | 2.110995 | 0.721473 | 2.060786 | 2.343856 | 1.041842 | 0.219060 | 1.947285 | 2.320965 | -0.312589 | -0.931027 | ... | 1.901185 | 0.117700 | 1.752563 | 2.015301 | 0.378365 | -0.273318 | 0.664512 | 1.629151 | -1.360158 | -0.709091 |
| 565 | 1.704854 | 2.085134 | 1.615931 | 1.723842 | 0.102458 | -0.017833 | 0.693043 | 1.263669 | -0.217664 | -1.058611 | ... | 1.536720 | 2.047399 | 1.421940 | 1.494959 | -0.691230 | -0.394820 | 0.236573 | 0.733827 | -0.531855 | -0.973978 |
| 566 | 0.702284 | 2.045574 | 0.672676 | 0.577953 | -0.840484 | -0.038680 | 0.046588 | 0.105777 | -0.809117 | -0.895587 | ... | 0.561361 | 1.374854 | 0.579001 | 0.427906 | -0.809587 | 0.350735 | 0.326767 | 0.414069 | -1.104549 | -0.318409 |
| 567 | 1.838341 | 2.336457 | 1.982524 | 1.735218 | 1.525767 | 3.272144 | 3.296944 | 2.658866 | 2.137194 | 1.043695 | ... | 1.961239 | 2.237926 | 2.303601 | 1.653171 | 1.430427 | 3.904848 | 3.197605 | 2.289985 | 1.919083 | 2.219635 |
| 568 | -1.808401 | 1.221792 | -1.814389 | -1.347789 | -3.112085 | -1.150752 | -1.114873 | -1.261820 | -0.820070 | -0.561032 | ... | -1.410893 | 0.764190 | -1.432735 | -1.075813 | -1.859019 | -1.207552 | -1.305831 | -1.745063 | -0.048138 | -0.751207 |
5 hàng × 30 cột
Giờ đến phần then chốt, vài dòng code tiếp theo sẽ chiếu dữ liệu Breast Cancer 30 chiều xuống hai thành phần chính hai chiều.
Bạn sẽ dùng thư viện sklearn để nhập mô-đun PCA, và trong phương thức PCA, bạn truyền số thành phần (n_components=2) và cuối cùng gọi fit_transform trên dữ liệu tổng hợp. Ở đây, số thành phần biểu diễn số chiều thấp mà bạn sẽ chiếu dữ liệu có số chiều cao xuống.
from sklearn.decomposition import PCA
pca_breast = PCA(n_components=2)
principalComponents_breast = pca_breast.fit_transform(x)
Tiếp theo, hãy tạo một DataFrame chứa giá trị các thành phần chính cho toàn bộ 569 mẫu.
principal_breast_Df = pd.DataFrame(data = principalComponents_breast
, columns = ['principal component 1', 'principal component 2'])
principal_breast_Df.tail()
| principal component 1 | principal component 2 | |
|---|---|---|
| 564 | 6.439315 | -3.576817 |
| 565 | 3.793382 | -3.584048 |
| 566 | 1.256179 | -1.902297 |
| 567 | 10.374794 | 1.672010 |
| 568 | -5.475243 | -0.670637 |
explained_variance_ratio. Nó sẽ cho bạn biết lượng thông tin hay phương sai mà mỗi thành phần chính giữ lại sau khi chiếu dữ liệu xuống không gian con có số chiều thấp.print('Explained variability per principal component: {}'.format(pca_breast.explained_variance_ratio_))
Explained variability per principal component: [0.44272026 0.18971182]
Từ kết quả trên, bạn có thể thấy principal component 1 giữ 44,2% thông tin trong khi principal component 2 chỉ giữ 19% thông tin. Cũng cần lưu ý rằng khi chiếu dữ liệu 30 chiều xuống 2 chiều, đã mất 36,8% thông tin.
Hãy vẽ trực quan 569 mẫu dọc theo trục principal component - 1 và principal component - 2. Điều này sẽ cho bạn cái nhìn tốt về cách các mẫu được phân bố giữa hai lớp.
plt.figure()
plt.figure(figsize=(10,10))
plt.xticks(fontsize=12)
plt.yticks(fontsize=14)
plt.xlabel('Principal Component - 1',fontsize=20)
plt.ylabel('Principal Component - 2',fontsize=20)
plt.title("Principal Component Analysis of Breast Cancer Dataset",fontsize=20)
targets = ['Benign', 'Malignant']
colors = ['r', 'g']
for target, color in zip(targets,colors):
indicesToKeep = breast_dataset['label'] == target
plt.scatter(principal_breast_Df.loc[indicesToKeep, 'principal component 1']
, principal_breast_Df.loc[indicesToKeep, 'principal component 2'], c = color, s = 50)
plt.legend(targets,prop={'size': 15})
<matplotlib.legend.Legend at 0x14552a630>
<Figure size 432x288 with 0 Axes>
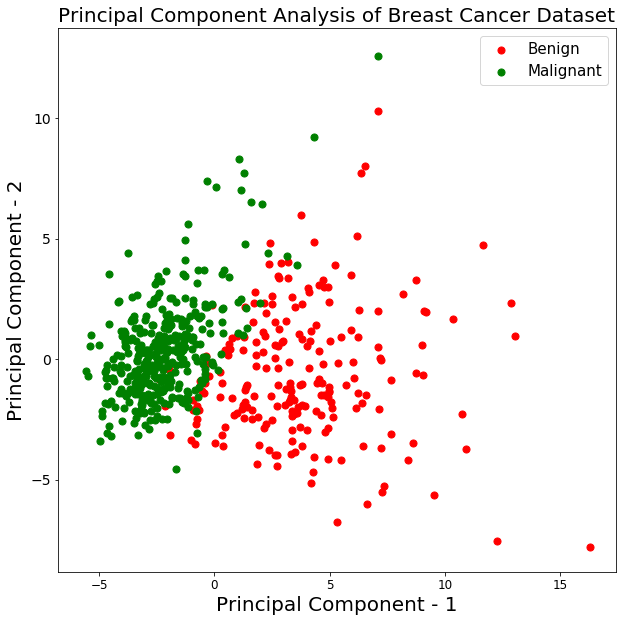
Từ biểu đồ trên, bạn có thể thấy hai lớp benign và malignant, khi được chiếu xuống không gian hai chiều, có thể tách tuyến tính ở một mức độ nhất định. Một quan sát khác là lớp benign phân tán rộng hơn so với lớp malignant.
Các dòng code sau để trực quan hóa dữ liệu CIFAR-10 khá giống với phần trực quan hóa PCA cho dữ liệu Breast Cancer.
chuẩn hóa các điểm ảnh về trong khoảng từ 0 đến 1 bao gồm.np.min(x_train),np.max(x_train)
(0.0, 1.0)
x_train = x_train/255.0
np.min(x_train),np.max(x_train)
(0.0, 0.00392156862745098)
x_train.shape
(50000, 32, 32, 3)
Tiếp theo, bạn sẽ tạo một DataFrame chứa giá trị điểm ảnh của ảnh cùng với nhãn tương ứng theo định dạng hàng-cột.
Nhưng trước đó, hãy reshape kích thước ảnh từ ba chiều xuống một chiều (làm phẳng ảnh).
x_train_flat = x_train.reshape(-1,3072)
feat_cols = ['pixel'+str(i) for i in range(x_train_flat.shape[1])]
df_cifar = pd.DataFrame(x_train_flat,columns=feat_cols)
df_cifar['label'] = y_train
print('Size of the dataframe: {}'.format(df_cifar.shape))
Size of the dataframe: (50000, 3073)
Hoàn hảo! Kích thước dataframe là chính xác vì có 50.000 ảnh huấn luyện, mỗi ảnh có 3072 điểm ảnh và một cột bổ sung cho nhãn, tổng cộng là 3073.
PCA sẽ được áp dụng cho tất cả các cột trừ cột cuối cùng, là nhãn của mỗi ảnh.
df_cifar.head()
| pixel0 | pixel1 | pixel2 | pixel3 | pixel4 | pixel5 | pixel6 | pixel7 | pixel8 | pixel9 | ... | pixel3063 | pixel3064 | pixel3065 | pixel3066 | pixel3067 | pixel3068 | pixel3069 | pixel3070 | pixel3071 | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.231373 | 0.243137 | 0.247059 | 0.168627 | 0.180392 | 0.176471 | 0.196078 | 0.188235 | 0.168627 | 0.266667 | ... | 0.847059 | 0.721569 | 0.549020 | 0.592157 | 0.462745 | 0.329412 | 0.482353 | 0.360784 | 0.282353 | 6 |
| 1 | 0.603922 | 0.694118 | 0.733333 | 0.494118 | 0.537255 | 0.533333 | 0.411765 | 0.407843 | 0.372549 | 0.400000 | ... | 0.560784 | 0.521569 | 0.545098 | 0.560784 | 0.525490 | 0.556863 | 0.560784 | 0.521569 | 0.564706 | 9 |
| 2 | 1.000000 | 1.000000 | 1.000000 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | 0.992157 | ... | 0.305882 | 0.333333 | 0.325490 | 0.309804 | 0.333333 | 0.325490 | 0.313725 | 0.337255 | 0.329412 | 9 |
| 3 | 0.109804 | 0.098039 | 0.039216 | 0.145098 | 0.133333 | 0.074510 | 0.149020 | 0.137255 | 0.078431 | 0.164706 | ... | 0.211765 | 0.184314 | 0.109804 | 0.247059 | 0.219608 | 0.145098 | 0.282353 | 0.254902 | 0.180392 | 4 |
| 4 | 0.666667 | 0.705882 | 0.776471 | 0.658824 | 0.698039 | 0.768627 | 0.694118 | 0.725490 | 0.796078 | 0.717647 | ... | 0.294118 | 0.309804 | 0.321569 | 0.278431 | 0.294118 | 0.305882 | 0.286275 | 0.301961 | 0.313725 | 1 |
5 hàng × 3073 cột
fit_transform lên dữ liệu huấn luyện, việc này có thể mất vài giây vì có 50.000 mẫupca_cifar = PCA(n_components=2)
principalComponents_cifar = pca_cifar.fit_transform(df_cifar.iloc[:,:-1])
Sau đó bạn sẽ chuyển các thành phần chính cho từng ảnh trong 50.000 ảnh từ mảng numpy sang pandas DataFrame.
principal_cifar_Df = pd.DataFrame(data = principalComponents_cifar
, columns = ['principal component 1', 'principal component 2'])
principal_cifar_Df['y'] = y_train
principal_cifar_Df.head()
| principal component 1 | principal component 2 | y | |
|---|---|---|---|
| 0 | -6.401018 | 2.729039 | 6 |
| 1 | 0.829783 | -0.949943 | 9 |
| 2 | 7.730200 | -11.522102 | 9 |
| 3 | -10.347817 | 0.010738 | 4 |
| 4 | -2.625651 | -4.969240 | 1 |
phương sai mà các thành phần chính giữ lại.print('Explained variability per principal component: {}'.format(pca_cifar.explained_variance_ratio_))
Explained variability per principal component: [0.2907663 0.11253144]
Có vẻ như lượng thông tin giữ lại bởi hai thành phần chính 1 và 2 là khá ổn, xét rằng dữ liệu đã được chiếu từ 3072 chiều xuống chỉ còn hai thành phần chính.
Đến lúc trực quan hóa dữ liệu CIFAR-10 trong không gian hai chiều. Hãy nhớ rằng có sự chồng lấn ngữ nghĩa giữa các lớp trong bộ dữ liệu này, nghĩa là một con ếch có thể có hình dáng hơi giống một con mèo hoặc một con hươu với một con chó; đặc biệt khi chiếu xuống không gian hai chiều. Những khác biệt giữa chúng có thể không được nắm bắt tốt.
import seaborn as sns
plt.figure(figsize=(16,10))
sns.scatterplot(
x="principal component 1", y="principal component 2",
hue="y",
palette=sns.color_palette("hls", 10),
data=principal_cifar_Df,
legend="full",
alpha=0.3
)
<matplotlib.axes._subplots.AxesSubplot at 0x12a5ba8d0>
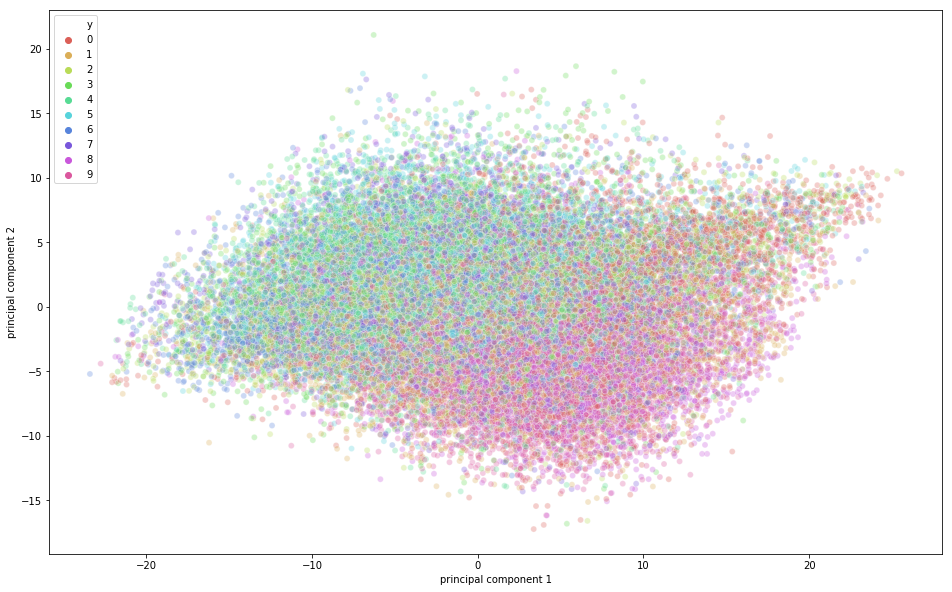
Từ hình trên, bạn có thể thấy một phần biến thiên được các thành phần chính nắm bắt vì có cấu trúc nhất định trong các điểm khi chiếu theo hai trục thành phần chính. Các điểm thuộc cùng một lớp thì gần nhau, còn các điểm hay ảnh khác nhau rõ rệt về mặt ngữ nghĩa thì xa nhau hơn.
Ở phần cuối cùng của hướng dẫn, bạn sẽ học cách tăng tốc quá trình huấn luyện mô hình học sâu bằng PCA.
Lưu ý: Để tìm hiểu các thuật ngữ cơ bản sẽ dùng trong phần này, bạn có thể xem hướng dẫn này.
Đầu tiên, hãy chuẩn hóa ảnh huấn luyện và kiểm thử. Nếu bạn nhớ thì ảnh huấn luyện đã được chuẩn hóa ở phần trực quan hóa PCA, nên bạn chỉ cần chuẩn hóa ảnh kiểm thử. Hãy làm nhanh nào!
x_test = x_test/255.0
x_test = x_test.reshape(-1,32,32,3)
Hãy reshape dữ liệu kiểm thử.
x_test_flat = x_test.reshape(-1,3072)
Tiếp theo, bạn sẽ tạo thể hiện của mô hình PCA.
Tại đây, bạn cũng có thể truyền vào PCA lượng phương sai bạn muốn giữ lại. Hãy truyền 0.9 làm tham số cho mô hình PCA, nghĩa là PCA sẽ giữ 90% phương sai và sẽ dùng số thành phần cần thiết để nắm bắt 90% phương sai.
Lưu ý rằng trước đó bạn truyền n_components làm tham số và sau đó có thể tìm được lượng phương sai được hai thành phần đó giữ lại. Nhưng ở đây chúng ta chỉ rõ lượng phương sai muốn PCA giữ, do đó n_components sẽ thay đổi dựa trên tham số phương sai.
Nếu bạn không truyền phương sai, thì số thành phần sẽ bằng với số chiều gốc của dữ liệu.
pca = PCA(0.9)
Sau đó bạn sẽ fit thể hiện PCA trên ảnh huấn luyện.
pca.fit(x_train_flat)
PCA(copy=True, iterated_power='auto', n_components=0.9, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
Bây giờ hãy xem PCA đã dùng bao nhiêu n_components để giữ 0.9 phương sai.
pca.n_components_
99
Từ kết quả trên, bạn có thể thấy để đạt 90% phương sai, số chiều đã được giảm xuống còn 99 thành phần chính từ 3072 chiều ban đầu.
Cuối cùng, bạn sẽ áp dụng transform lên cả tập huấn luyện và kiểm thử để tạo tập dữ liệu đã biến đổi từ các tham số sinh ra từ phương thức fit.
train_img_pca = pca.transform(x_train_flat)
test_img_pca = pca.transform(x_test_flat)
Tiếp theo, hãy nhanh chóng nhập các thư viện cần thiết để chạy mô hình học sâu.
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.optimizers import RMSprop
Bây giờ, bạn sẽ chuyển nhãn huấn luyện và kiểm thử sang vector one-hot.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
Hãy định nghĩa số epoch, số lớp và kích thước batch cho mô hình.
batch_size = 128
num_classes = 10
epochs = 20
Tiếp theo, bạn sẽ định nghĩa mô hình Sequential!
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(99,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
Hãy in tóm tắt mô hình.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1024) 102400
_________________________________________________________________
dense_2 (Dense) (None, 1024) 1049600
_________________________________________________________________
dense_3 (Dense) (None, 512) 524800
_________________________________________________________________
dense_4 (Dense) (None, 256) 131328
_________________________________________________________________
dense_5 (Dense) (None, 10) 2570
=================================================================
Total params: 1,810,698
Trainable params: 1,810,698
Non-trainable params: 0
_________________________________________________________________
Cuối cùng, đến lúc biên dịch và huấn luyện mô hình!
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(train_img_pca, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(test_img_pca, y_test))
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:2704: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:From /Users/adityasharma/blog/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:1257: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 7s - loss: 1.9032 - acc: 0.2962 - val_loss: 1.6925 - val_acc: 0.3875
Epoch 2/20
50000/50000 [==============================] - 7s - loss: 1.6480 - acc: 0.4055 - val_loss: 1.5313 - val_acc: 0.4412
Epoch 3/20
50000/50000 [==============================] - 7s - loss: 1.5205 - acc: 0.4534 - val_loss: 1.4609 - val_acc: 0.4695
Epoch 4/20
50000/50000 [==============================] - 7s - loss: 1.4322 - acc: 0.4849 - val_loss: 1.6164 - val_acc: 0.4503
Epoch 5/20
50000/50000 [==============================] - 7s - loss: 1.3621 - acc: 0.5120 - val_loss: 1.3626 - val_acc: 0.5081
Epoch 6/20
50000/50000 [==============================] - 7s - loss: 1.2995 - acc: 0.5330 - val_loss: 1.4100 - val_acc: 0.4940
Epoch 7/20
50000/50000 [==============================] - 7s - loss: 1.2473 - acc: 0.5529 - val_loss: 1.3589 - val_acc: 0.5251
Epoch 8/20
50000/50000 [==============================] - 7s - loss: 1.2010 - acc: 0.5669 - val_loss: 1.3315 - val_acc: 0.5232
Epoch 9/20
50000/50000 [==============================] - 7s - loss: 1.1524 - acc: 0.5868 - val_loss: 1.3903 - val_acc: 0.5197
Epoch 10/20
50000/50000 [==============================] - 7s - loss: 1.1134 - acc: 0.6013 - val_loss: 1.2722 - val_acc: 0.5499
Epoch 11/20
50000/50000 [==============================] - 7s - loss: 1.0691 - acc: 0.6160 - val_loss: 1.5911 - val_acc: 0.4768
Epoch 12/20
50000/50000 [==============================] - 7s - loss: 1.0325 - acc: 0.6289 - val_loss: 1.2515 - val_acc: 0.5602
Epoch 13/20
50000/50000 [==============================] - 7s - loss: 0.9977 - acc: 0.6420 - val_loss: 1.5678 - val_acc: 0.4914
Epoch 14/20
50000/50000 [==============================] - 8s - loss: 0.9567 - acc: 0.6567 - val_loss: 1.3525 - val_acc: 0.5418
Epoch 15/20
50000/50000 [==============================] - 9s - loss: 0.9158 - acc: 0.6713 - val_loss: 1.3525 - val_acc: 0.5540
Epoch 16/20
50000/50000 [==============================] - 10s - loss: 0.8948 - acc: 0.6816 - val_loss: 1.5633 - val_acc: 0.5156
Epoch 17/20
50000/50000 [==============================] - 9s - loss: 0.8690 - acc: 0.6903 - val_loss: 1.6980 - val_acc: 0.5084
Epoch 18/20
50000/50000 [==============================] - 9s - loss: 0.8586 - acc: 0.7002 - val_loss: 1.6325 - val_acc: 0.5247
Epoch 19/20
50000/50000 [==============================] - 8s - loss: 0.9367 - acc: 0.6853 - val_loss: 1.8253 - val_acc: 0.5165
Epoch 20/20
50000/50000 [==============================] - 8s - loss: 2.3761 - acc: 0.5971 - val_loss: 6.0192 - val_acc: 0.4409
Từ kết quả trên, bạn có thể thấy thời gian huấn luyện mỗi epoch chỉ 7 giây trên CPU. Mô hình làm tốt trên dữ liệu huấn luyện, đạt 70% độ chính xác trong khi chỉ đạt 56% trên dữ liệu kiểm thử. Điều này có nghĩa là nó đã overfit dữ liệu huấn luyện. Tuy nhiên, hãy nhớ rằng dữ liệu đã được chiếu xuống 99 chiều từ 3072 chiều và dù vậy mô hình vẫn hoạt động khá tốt!
Cuối cùng, hãy xem mô hình mất bao lâu để huấn luyện trên tập dữ liệu gốc và có thể đạt độ chính xác bao nhiêu khi dùng cùng một mô hình học sâu.
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(3072,)))
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
history = model.fit(x_train_flat, y_train,batch_size=batch_size,epochs=epochs,verbose=1,
validation_data=(x_test_flat, y_test))
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 23s - loss: 2.0657 - acc: 0.2200 - val_loss: 2.0277 - val_acc: 0.2485
Epoch 2/20
50000/50000 [==============================] - 22s - loss: 1.8727 - acc: 0.3166 - val_loss: 1.8428 - val_acc: 0.3215
Epoch 3/20
50000/50000 [==============================] - 22s - loss: 1.7801 - acc: 0.3526 - val_loss: 1.7657 - val_acc: 0.3605
Epoch 4/20
50000/50000 [==============================] - 22s - loss: 1.7141 - acc: 0.3796 - val_loss: 1.6345 - val_acc: 0.4132
Epoch 5/20
50000/50000 [==============================] - 22s - loss: 1.6566 - acc: 0.4001 - val_loss: 1.6384 - val_acc: 0.4076
Epoch 6/20
50000/50000 [==============================] - 22s - loss: 1.6083 - acc: 0.4209 - val_loss: 1.7507 - val_acc: 0.3574
Epoch 7/20
50000/50000 [==============================] - 22s - loss: 1.5626 - acc: 0.4374 - val_loss: 1.7125 - val_acc: 0.4010
Epoch 8/20
50000/50000 [==============================] - 22s - loss: 1.5252 - acc: 0.4486 - val_loss: 1.5914 - val_acc: 0.4321
Epoch 9/20
50000/50000 [==============================] - 24s - loss: 1.4924 - acc: 0.4620 - val_loss: 1.5352 - val_acc: 0.4616
Epoch 10/20
50000/50000 [==============================] - 25s - loss: 1.4627 - acc: 0.4728 - val_loss: 1.4561 - val_acc: 0.4798
Epoch 11/20
50000/50000 [==============================] - 24s - loss: 1.4349 - acc: 0.4820 - val_loss: 1.5044 - val_acc: 0.4723
Epoch 12/20
50000/50000 [==============================] - 24s - loss: 1.4120 - acc: 0.4919 - val_loss: 1.4740 - val_acc: 0.4790
Epoch 13/20
50000/50000 [==============================] - 23s - loss: 1.3913 - acc: 0.4981 - val_loss: 1.4430 - val_acc: 0.4891
Epoch 14/20
50000/50000 [==============================] - 27s - loss: 1.3678 - acc: 0.5098 - val_loss: 1.4323 - val_acc: 0.4888
Epoch 15/20
50000/50000 [==============================] - 27s - loss: 1.3508 - acc: 0.5148 - val_loss: 1.6179 - val_acc: 0.4372
Epoch 16/20
50000/50000 [==============================] - 25s - loss: 1.3443 - acc: 0.5167 - val_loss: 1.5868 - val_acc: 0.4656
Epoch 17/20
50000/50000 [==============================] - 25s - loss: 1.3734 - acc: 0.5101 - val_loss: 1.4756 - val_acc: 0.4913
Epoch 18/20
50000/50000 [==============================] - 26s - loss: 5.5126 - acc: 0.3591 - val_loss: 5.7580 - val_acc: 0.3084
Epoch 19/20
50000/50000 [==============================] - 27s - loss: 5.6346 - acc: 0.3395 - val_loss: 3.7362 - val_acc: 0.3402
Epoch 20/20
50000/50000 [==============================] - 26s - loss: 6.4199 - acc: 0.3030 - val_loss: 13.9429 - val_acc: 0.1326
Voila! Từ kết quả trên, có thể thấy rõ ràng thời gian huấn luyện mỗi epoch khoảng 23 giây trên CPU, gần gấp ba lần so với mô hình huấn luyện trên đầu ra PCA.
Hơn nữa, cả độ chính xác huấn luyện và kiểm thử đều thấp hơn so với độ chính xác đạt được khi dùng 99 thành phần chính làm đầu vào cho mô hình.
Vì vậy, bằng cách áp dụng PCA lên dữ liệu huấn luyện, bạn có thể huấn luyện thuật toán học sâu không chỉ nhanh hơn, mà còn đạt độ chính xác tốt hơn trên dữ liệu kiểm thử so với thuật toán học sâu được huấn luyện trên dữ liệu gốc.
Tiến xa hơn!
Chúc mừng bạn đã hoàn thành hướng dẫn.
Hướng dẫn này là một phần giới thiệu tuyệt vời và toàn diện về PCA trong Python, bao quát cả khái niệm lý thuyết lẫn thực hành.
Nếu bạn muốn đào sâu hơn vào các kỹ thuật giảm số chiều thì hãy cân nhắc đọc về t-distributed Stochastic Neighbor Embedding, thường được biết đến là tSNE, một kỹ thuật giảm số chiều phi tuyến xác suất.
Nếu bạn muốn tìm hiểu thêm về các kỹ thuật học không giám sát như PCA, hãy học khóa Unsupervised Learning in Python của DataCamp.
Tài liệu tham khảo để học thêm:
Tìm hiểu thêm về Python
Courses
Courses
Courses