
Program
Pengembangan Aplikasi Kecerdasan Buatan
21 Hr
Qwen3 adalah generasi terbaru model bahasa berbobot terbuka dari Alibaba. Dengan dukungan untuk 100+ bahasa dan performa kuat pada tugas penalaran, pemrograman, serta penerjemahan, Qwen3 menyaingi banyak model kelas atas saat ini, termasuk DeepSeek-R1, o3-mini, dan Gemini 2.5.
Dalam tutorial ini, saya akan menjelaskan langkah demi langkah cara menjalankan Qwen3 secara lokal menggunakan Ollama.
Kita juga akan membangun aplikasi ringan lokal dengan Qwen 3. Aplikasi ini memungkinkan Anda beralih antara mode penalaran Qwen3 dan menerjemahkan antar berbagai bahasa.
Kami menjaga pembaca tetap mengetahui kabar terbaru AI melalui The Median, buletin gratis setiap Jumat yang merangkum berita kunci pekan ini. Berlangganan dan tetap tajam hanya dalam beberapa menit setiap minggu:
Menjalankan Qwen3 secara lokal memberikan beberapa manfaat utama:
Qwen3 dioptimalkan untuk penalaran mendalam (mode berpikir) dan respons cepat (mode non-berpikir), serta mendukung 100+ bahasa. Mari kita siapkan secara lokal.
Ollama adalah alat yang memungkinkan Anda menjalankan model bahasa seperti Llama atau Qwen secara lokal di komputer Anda dengan antarmuka baris perintah yang sederhana.
Unduh Ollama untuk macOS, Windows, atau Linux dari: https://ollama.com/download.
Ikuti petunjuk penginstal, dan setelah instalasi, verifikasi dengan menjalankan perintah ini di terminal:
ollama --versionOllama menawarkan beragam model Qwen3 yang terus bertambah, dirancang untuk berbagai konfigurasi perangkat keras, mulai dari laptop ringan hingga server kelas atas.
ollama run qwen3Menjalankan perintah di atas akan meluncurkan model Qwen3 default di Ollama, yang saat ini mengarah ke qwen3:8b. Jika Anda bekerja dengan sumber daya terbatas atau menginginkan waktu mulai yang lebih cepat, Anda dapat secara eksplisit menjalankan varian yang lebih kecil seperti model 4B:
ollama run qwen3:4bQwen3 saat ini tersedia dalam beberapa varian, mulai dari yang terkecil 0,6b (523MB) hingga yang terbesar 235b (142GB) parameter. Varian yang lebih kecil ini menawarkan performa yang mengesankan untuk penalaran, penerjemahan, dan pembuatan kode, terutama saat digunakan dalam mode berpikir.
Model MoE (30b-a3b, 235b-a22b) sangat menarik karena hanya mengaktifkan sebagian subset pakar pada setiap langkah inferensi, memungkinkan jumlah parameter total yang sangat besar sambil menjaga biaya runtime tetap efisien.
Secara umum, gunakan model terbesar yang mampu ditangani perangkat keras Anda, dan kembali ke model 8B atau 4B untuk eksperimen lokal yang responsif pada mesin konsumen.
Berikut rekap singkat semua model Qwen3 yang dapat Anda jalankan:
|
Model |
Perintah Ollama |
Terbaik Untuk |
|
Qwen3-0.6B |
|
Tugas ringan, aplikasi seluler, dan perangkat edge |
|
Qwen3-1.7B |
|
Chatbot, asisten, dan aplikasi berlatensi rendah |
|
Qwen3-4B |
|
Tugas serbaguna dengan kinerja dan penggunaan sumber daya yang seimbang |
|
Qwen3-8B |
|
Dukungan multibahasa dan kemampuan penalaran sedang |
|
Qwen3-14B |
|
Penalaran tingkat lanjut, pembuatan konten, dan pemecahan masalah kompleks |
|
Qwen3-32B |
|
Tugas kelas atas yang memerlukan penalaran kuat dan penanganan konteks luas |
|
Qwen3-30B-A3B (MoE) |
|
Performa efisien dengan 3B parameter aktif, cocok untuk tugas pemrograman |
|
Qwen3-235B-A22B (MoE) |
|
Aplikasi skala masif, penalaran mendalam, dan solusi tingkat enterprise |
Untuk menyajikan model melalui API, jalankan perintah ini di terminal:
ollama serveIni akan membuat model tersedia untuk integrasi dengan aplikasi lain di http://localhost:11434.
Di bagian ini, saya akan memandu Anda melalui beberapa cara menggunakan Qwen3 secara lokal, dari interaksi CLI dasar hingga mengintegrasikan model dengan Python.
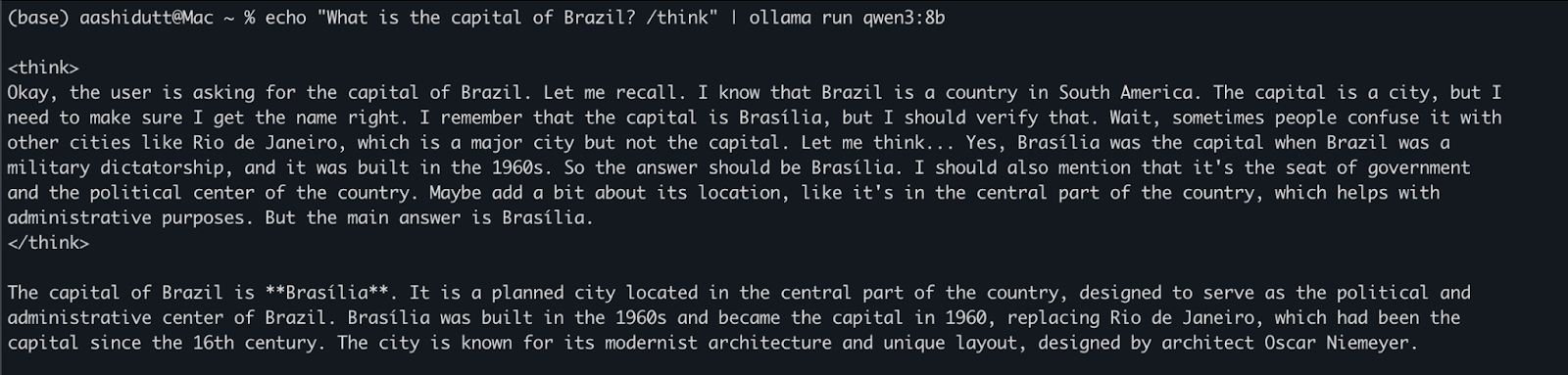
Setelah model diunduh, Anda dapat berinteraksi langsung dengan Qwen3 di terminal. Jalankan perintah berikut di terminal Anda:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bIni berguna untuk uji cepat atau interaksi ringan tanpa menulis kode. Tag /think di akhir prompt menginstruksikan model untuk melakukan penalaran lebih dalam, langkah demi langkah. Anda dapat menggantinya dengan /no_think untuk respons yang lebih cepat dan dangkal atau menghapusnya sama sekali untuk menggunakan mode penalaran default model.
Setelah ollama serve berjalan di latar belakang, Anda dapat berinteraksi dengan Qwen3 secara terprogram menggunakan HTTP API, yang sangat cocok untuk integrasi backend, otomasi, atau pengujian klien REST.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Begini cara kerjanya:
curl membuat permintaan POST (cara kita memanggil API) ke server Ollama lokal yang berjalan di localhost:11434."model": Menentukan model yang digunakan (di sini: qwen3:8b)."messages": Daftar pesan obrolan yang berisi role dan content."stream": false: Memastikan respons dikembalikan sekaligus, bukan token per token.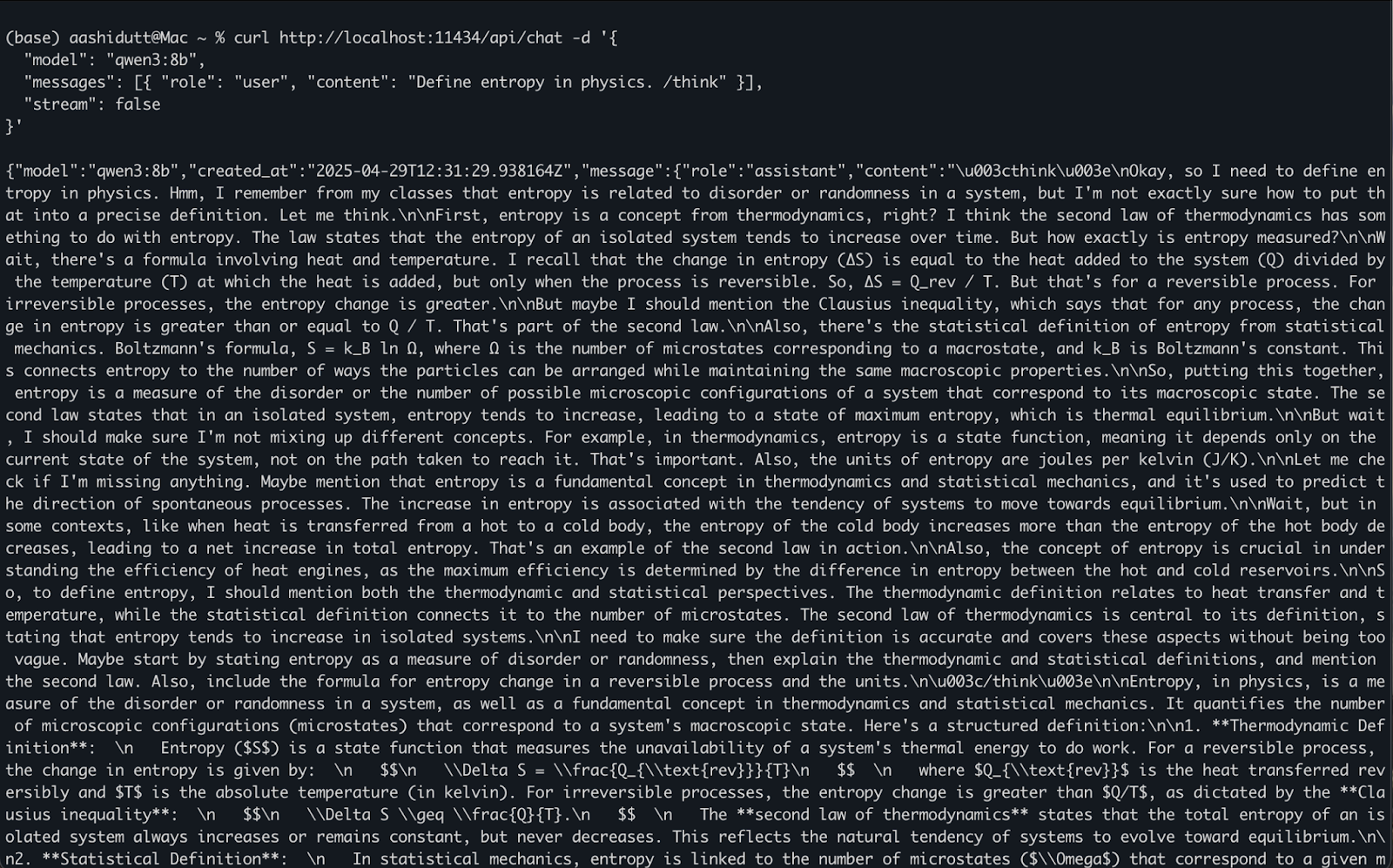
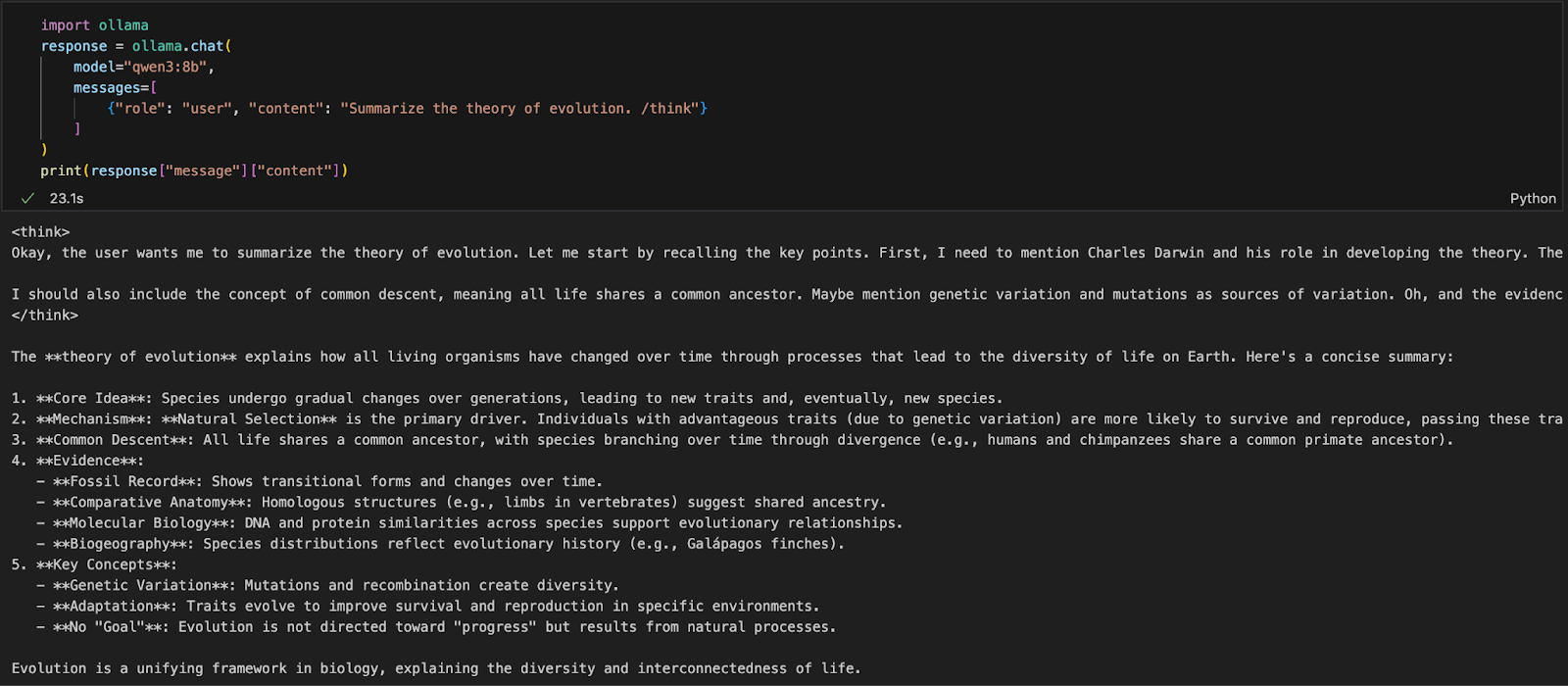
Jika Anda bekerja di lingkungan Python (seperti Jupyter, VSCode, atau skrip), cara termudah berinteraksi dengan Qwen3 adalah melalui Ollama Python SDK. Mulailah dengan memasang ollama:
pip install ollamaLalu, jalankan model Qwen3 Anda dengan skrip ini (kita menggunakan qwen3:8b di bawah):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Pada kode di atas:
ollama.chat(...) mengirim permintaan bergaya chat ke server Ollama lokal.qwen3:8b) dan daftar pesan dalam format yang mirip dengan API OpenAI./think memberi tahu model untuk bernalar langkah demi langkah.["message"]["content"].Pendekatan ini ideal untuk eksperimen lokal, pembuatan prototipe, atau membangun aplikasi berbasis LLM tanpa bergantung pada API cloud.
Qwen3 mendukung perilaku inferensi hibrida menggunakan tag /think (penalaran mendalam) dan /no_think (respons cepat). Di bagian ini, kita akan menggunakan Gradio untuk membuat aplikasi web lokal interaktif dengan dua tab terpisah:
Pada langkah ini, kita membangun tab penalaran hibrida dengan tag /think dan /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Pada kode di atas:
reasoning_qwen3() menerima prompt pengguna dan mode penalaran ("think" atau "no_think").subprocess.run() menjalankan perintah ollama run qwen3:8b, dengan memasukkan prompt sebagai input standar.Setelah fungsi pembangkit keluaran didefinisikan, fungsi gr.Interface() membungkusnya menjadi UI web interaktif dengan menentukan komponen input—sebuah Textbox untuk prompt dan tombol Radio untuk memilih mode penalaran—serta memetakkannya ke input fungsi.
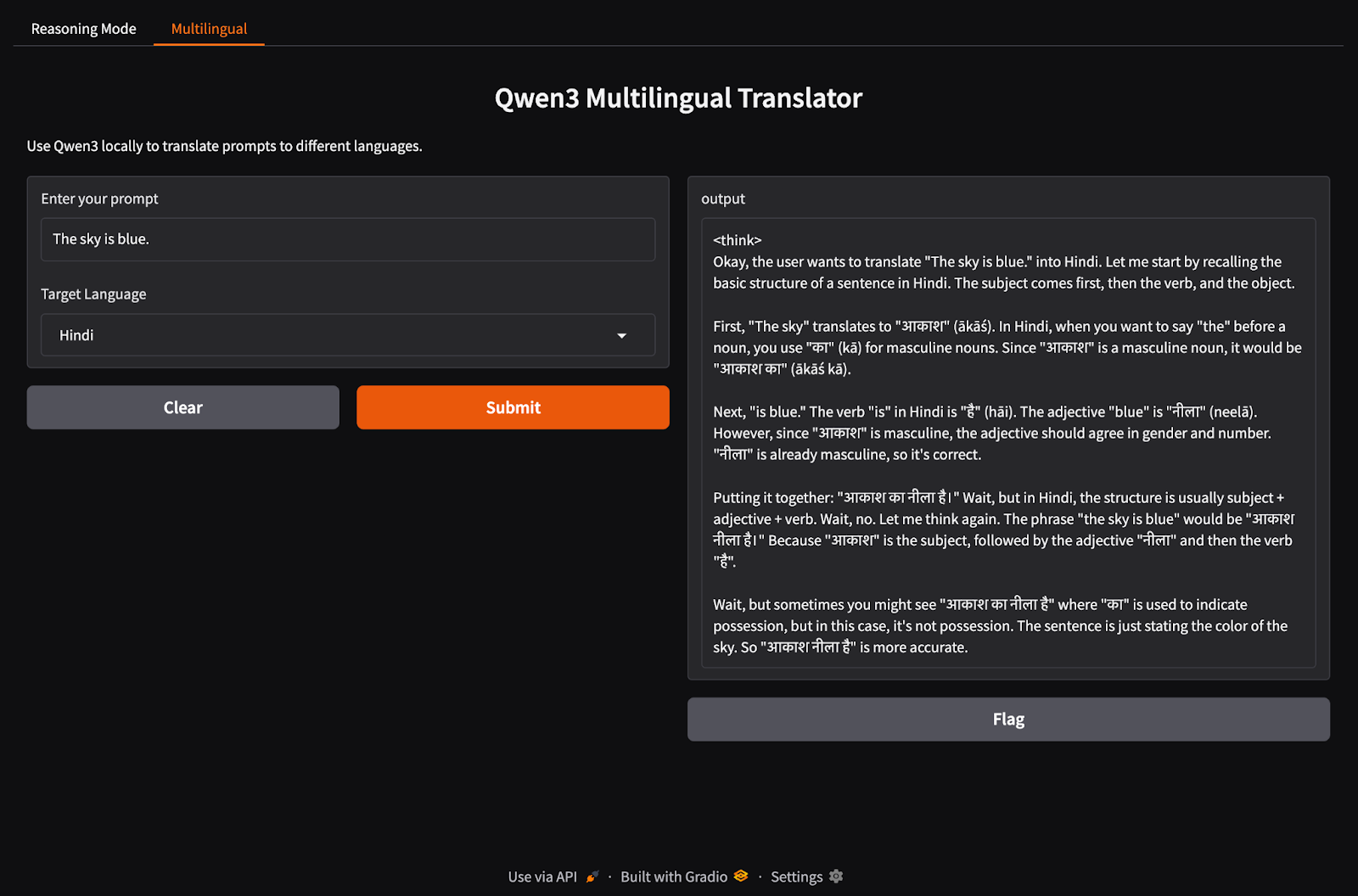
Sekarang, mari kita siapkan tab aplikasi multibahasa.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Serupa dengan langkah sebelumnya, kode ini bekerja sebagai berikut:
multilingual_qwen3() menerima prompt dan bahasa target.Mari gabungkan kedua tab dalam satu aplikasi Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Berikut yang kita lakukan pada kode di atas:
gr.TabbedInterface() membuat UI dengan dua tab:demo.launch(debug=True) menjalankan aplikasi secara lokal dan membukanya di browser dengan debugging diaktifkan.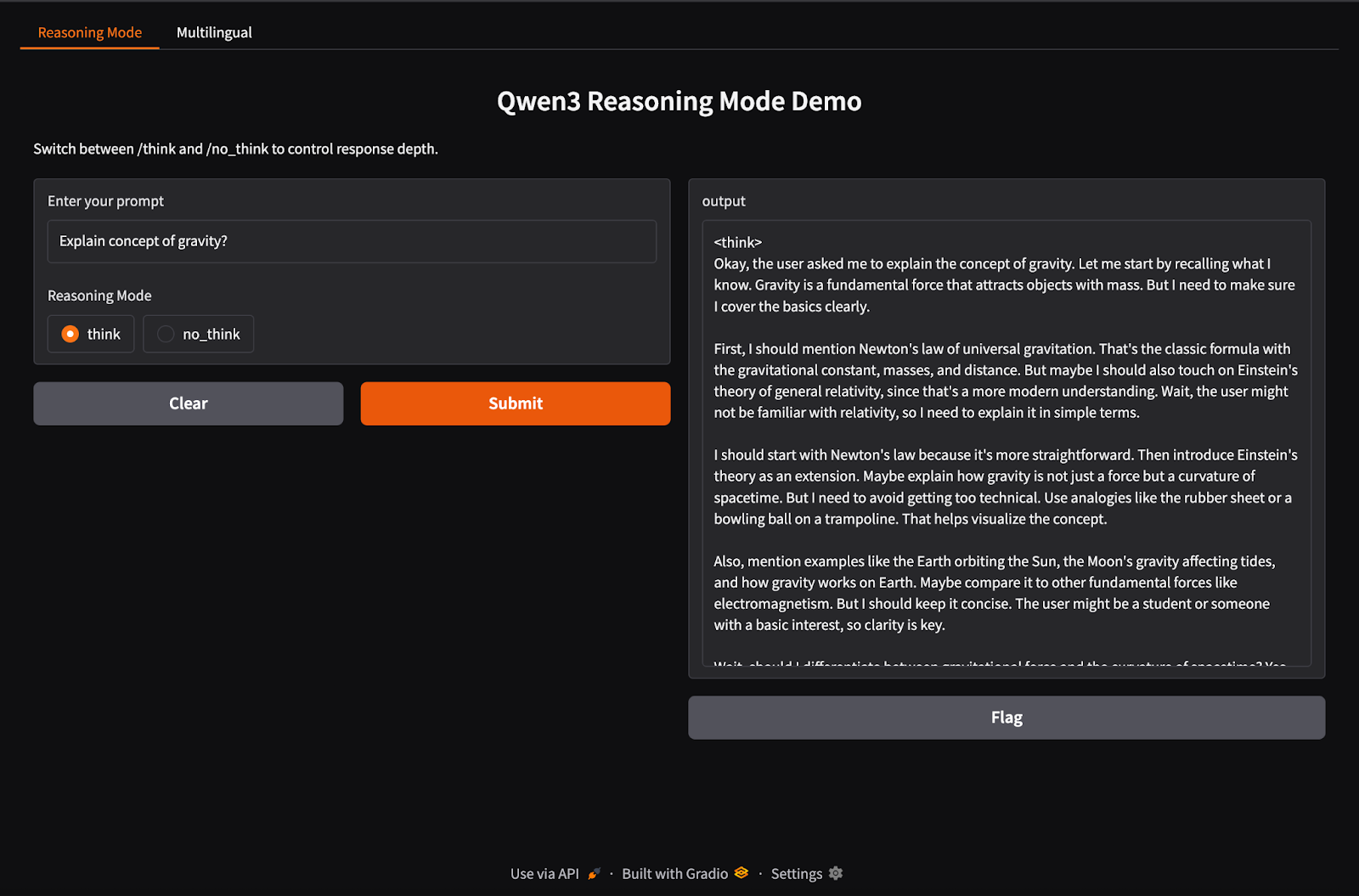
 Kesimpulan
KesimpulanQwen3 menghadirkan penalaran tingkat lanjut, decoding cepat, dan dukungan multibahasa ke mesin lokal Anda menggunakan Ollama.
Dengan penyiapan minimal, Anda dapat:
Untuk mempelajari lebih lanjut tentang Qwen3, saya merekomendasikan:
Belajar AI dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
