
Cursus
Développer des applications d'IA
21 h
Qwen3 est la dernière génération de modèles linguistiques à poids ouvert d'Alibaba. Avec la prise en charge de plus de 100 langues et d'excellentes performances dans les tâches de raisonnement, de codage et de traduction, Qwen3 rivalise avec de nombreux modèles de premier plan disponibles aujourd'hui, notamment DeepSeek-R1, o3-mini et Gemini 2.5.
Dans ce tutoriel, je vais vous expliquer étape par étape comment exécuter Qwen3 localement en utilisant Ollama.
Nous construirons également une application locale légère avec Qwen 3. L'application vous permettra de passer d'un mode de raisonnement à l'autre de Qwen3 et de traduire entre différentes langues.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
L'exécution locale de Qwen3 présente plusieurs avantages importants :
Qwen3 est optimisé pour un raisonnement approfondi (mode réflexion) et des réponses rapides (mode non-réflexion), et prend en charge plus de 100 langues. Mettons-le en place localement.
Ollama est un outil qui vous permet d'exécuter des modèles de langage comme Llama ou Qwen localement sur votre ordinateur à l'aide d'une simple interface de ligne de commande.
Téléchargez Ollama pour macOS, Windows ou Linux à partir de : https://ollama.com/download.
Suivez les instructions de l'installateur, et après l'installation, vérifiez en lançant ceci dans le terminal :
ollama --versionOllama propose une gamme croissante de modèles Qwen3 conçus pour s'adapter à une variété de configurations matérielles, des ordinateurs portables légers aux serveurs haut de gamme.
ollama run qwen3L'exécution de la commande ci-dessus lancera le modèle Qwen3 par défaut dans Ollama, dont la valeur par défaut est actuellement qwen3:8b. Si vous travaillez avec des ressources limitées ou si vous souhaitez des temps de démarrage plus rapides, vous pouvez explicitement utiliser des variantes plus petites comme le modèle 4B :
ollama run qwen3:4bQwen3 est actuellement disponible en plusieurs variantes, du plus petit modèle de 0.6b(523MB) au plus grand modèle de 235b(142GB). Ces variantes plus petites offrent des performances impressionnantes en matière de raisonnement, de traduction et de génération de code, en particulier lorsqu'elles sont utilisées en mode réflexion.
Les modèles MoE (30b-a3b, 235b-a22b) sont particulièrement intéressants car ils n'activent qu'un sous-ensemble d'experts par étape d'inférence, ce qui permet d'obtenir un nombre total de paramètres important tout en maintenant des coûts d'exécution raisonnables.
En général, utilisez le modèle le plus grand que votre matériel peut supporter, et revenez aux modèles 8B ou 4B pour des expériences locales réactives sur des machines grand public.
Voici un récapitulatif rapide de tous les modèles Qwen3 que vous pouvez utiliser :
|
Modèle |
Commandement d'Ollama |
Meilleur pour |
|
Qwen3-0.6B |
|
Tâches légères, applications mobiles et appareils périphériques |
|
Qwen3-1.7B |
|
Chatbots, assistants et applications à faible latence |
|
Qwen3-4B |
|
Tâches générales avec un équilibre entre performance et utilisation des ressources |
|
Qwen3-8B |
|
Support multilingue et capacités de raisonnement modérées |
|
Qwen3-14B |
|
Raisonnement avancé, création de contenu et résolution de problèmes complexes |
|
Qwen3-32B |
|
Tâches de haut niveau nécessitant un raisonnement rigoureux et une gestion étendue du contexte |
|
Qwen3-30B-A3B (MoE) |
|
Performance efficace avec 3B paramètres actifs, adaptée aux tâches de codage |
|
Qwen3-235B-A22B (MoE) |
|
Applications à grande échelle, raisonnement approfondi et solutions d'entreprise |
Pour servir le modèle via l'API, exécutez la commande suivante dans le terminal :
ollama serveLe modèle pourra ainsi être intégré à d'autres applications. à l'adresse http://localhost:11434.
Dans cette section, je vais vous présenter plusieurs façons d'utiliser Qwen3 localement, de l'interaction CLI de base à l'intégration du modèle avec Python.
Une fois le modèle téléchargé, vous pouvez interagir avec Qwen3 directement dans le terminal. Exécutez la commande suivante dans votre terminal :
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bCeci est utile pour des tests rapides ou une interaction légère sans écrire de code. La balise /think à la fin de l'invite demande au modèle de s'engager dans un raisonnement plus approfondi, étape par étape. Vous pouvez le remplacer par /no_think pour une réponse plus rapide et moins profonde ou l'omettre complètement pour utiliser le mode de raisonnement par défaut du modèle.
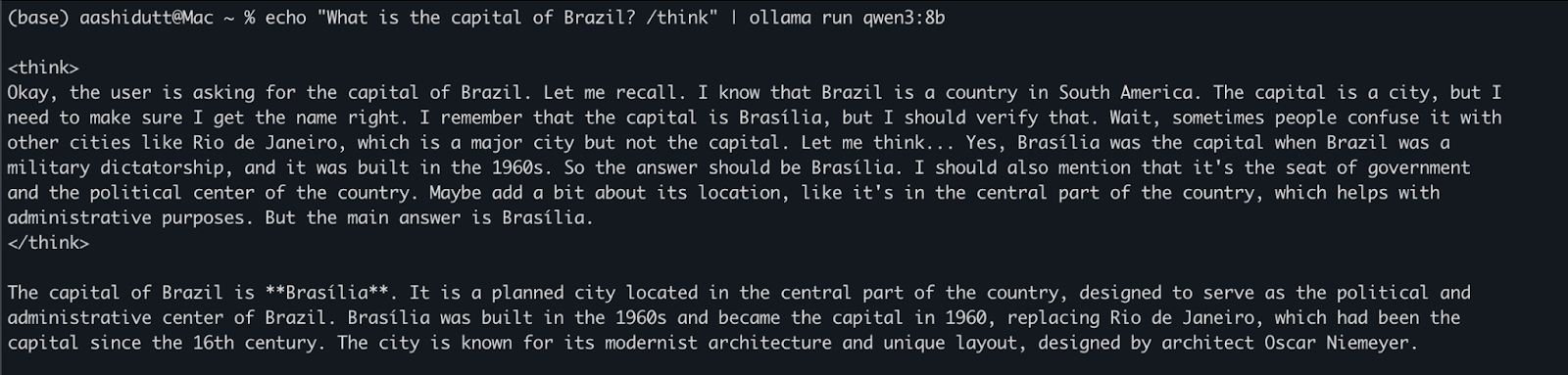
Une fois que ollama serve est exécuté en arrière-plan, vous pouvez interagir avec Qwen3 de manière programmatique à l'aide d'une API HTTP, ce qui est parfait pour l'intégration de backend, l'automatisation ou le test de clients REST.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Voici comment cela fonctionne :
curl fait une demande POST (la façon dont nous appelons l'API) au serveur local d'Ollama fonctionnant à l'adresse localhost:11434."model": Spécifie le modèle à utiliser (ici : qwen3:8b)."messages": Une liste des messages de chat contenant role et content."stream": false: Assure que la réponse est renvoyée en une seule fois, et non pas jeton par jeton.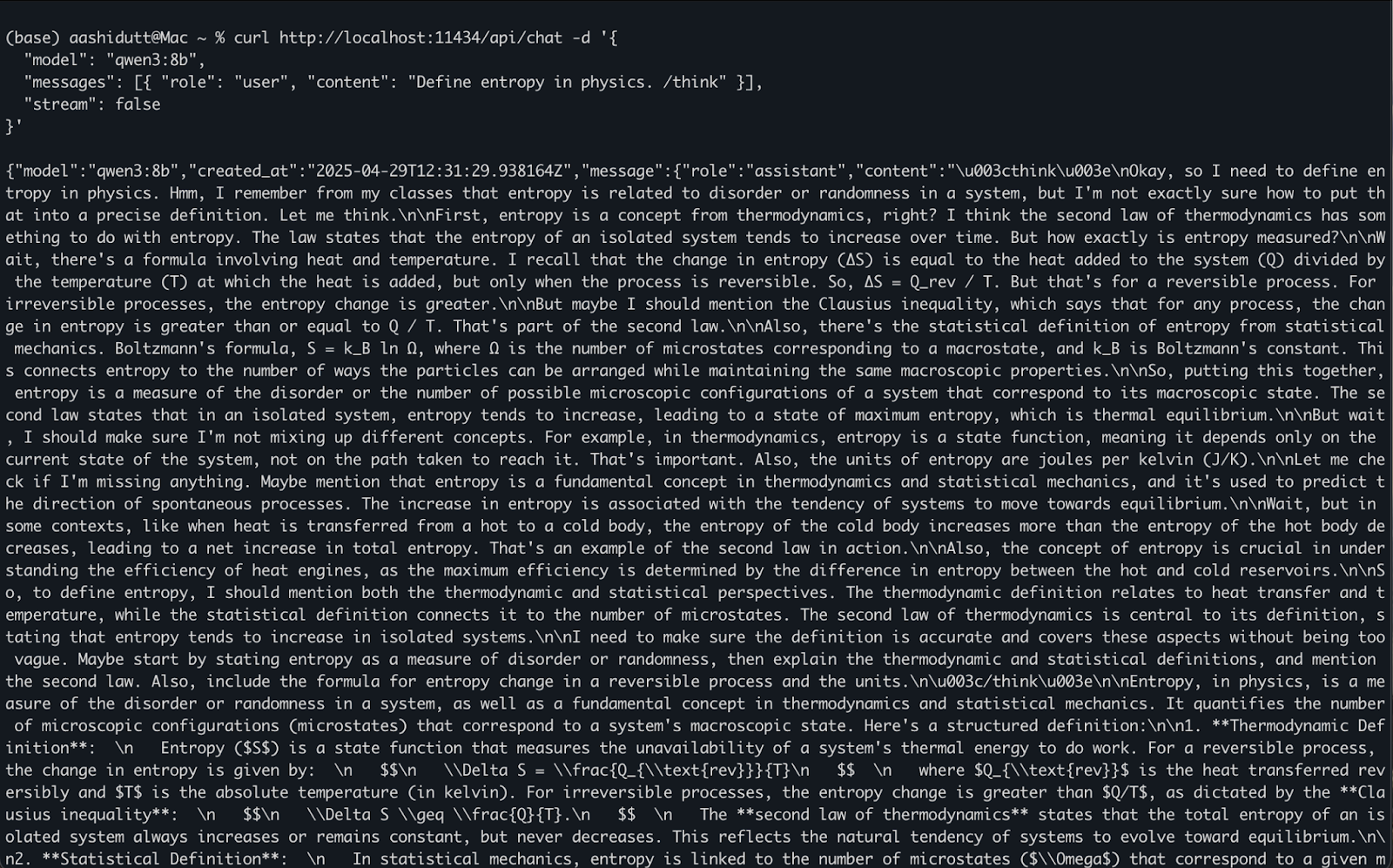
Si vous travaillez dans un environnement Python (comme Jupyter, VSCode ou un script), la manière la plus simple d'interagir avec Qwen3 est de passer par le Ollama Python SDK. Commencez par installer ollama :
pip install ollamaEnsuite, exécutez votre modèle Qwen3 avec ce script (nous utilisons qwen3:8b ci-dessous) :
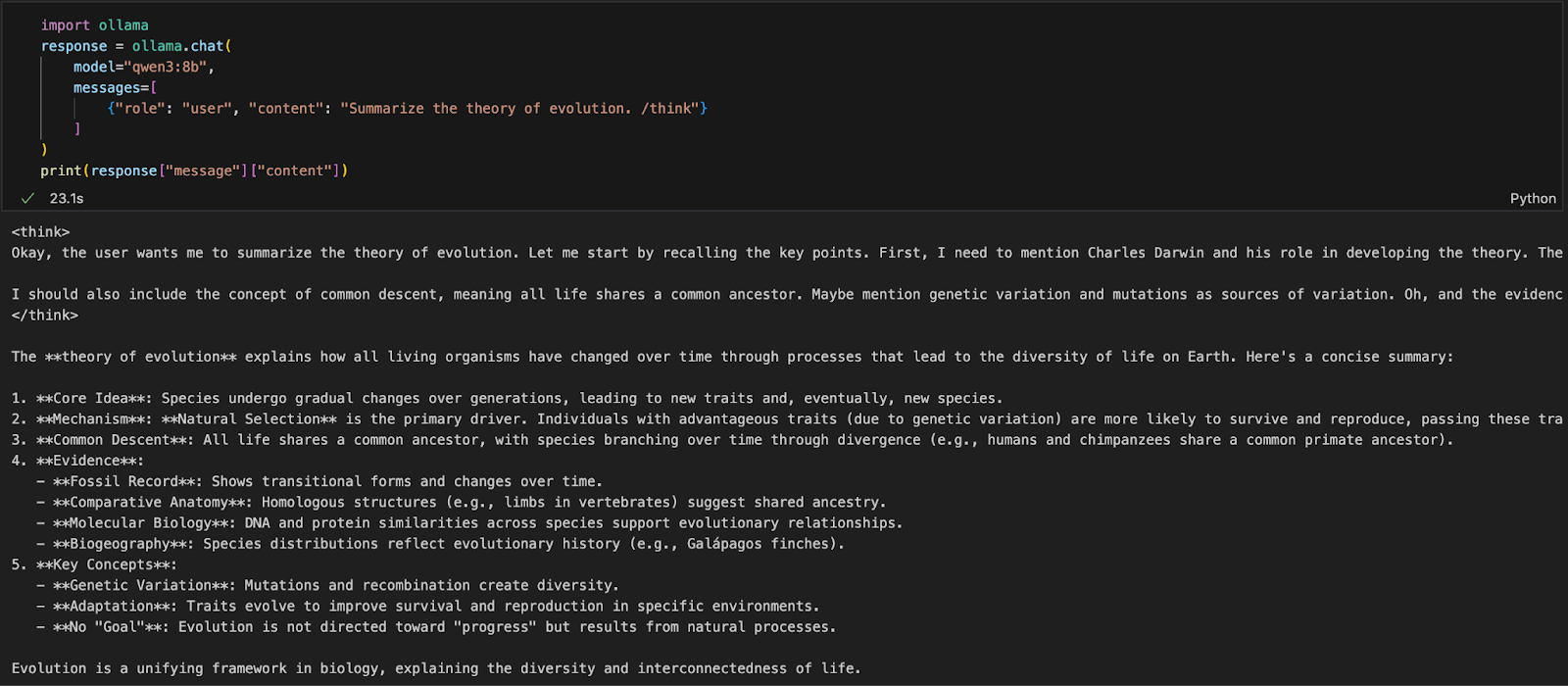
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Dans le code ci-dessus :
ollama.chat(...) envoie une requête de type "chat" au serveur Ollama local.qwen3:8b) et une liste de messages dans un format similaire à l'API d'OpenAI./think indique au modèle de raisonner étape par étape.["message"]["content"].Cette approche est idéale pour l'expérimentation locale, le prototypage ou la création d'applications soutenues par LLM sans dépendre des API du cloud.
Qwen3 prend en charge un comportement d'inférence hybride en utilisant les balises /think (raisonnement approfondi) et /no_think (réponse rapide). Dans cette section, nous utiliserons Gradio pour créer une application web locale interactive avec deux onglets distincts :
Dans cette étape, nous construisons notre onglet de raisonnement hybride avec les balises /think et /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Dans le code ci-dessus :
reasoning_qwen3() prend une invite de l'utilisateur et un mode de raisonnement ("think" ou "no_think").subprocess.run() exécute la commande ollama run qwen3:8b, en utilisant l'invite comme entrée standard.Une fois la fonction génératrice de sortie définie, la fonction gr.Interface() l'intègre dans une interface web interactive en spécifiant les composants d'entrée - un Textbox pour l'invite et un bouton Radio pour sélectionner le mode de raisonnement - et en les associant aux entrées de la fonction.
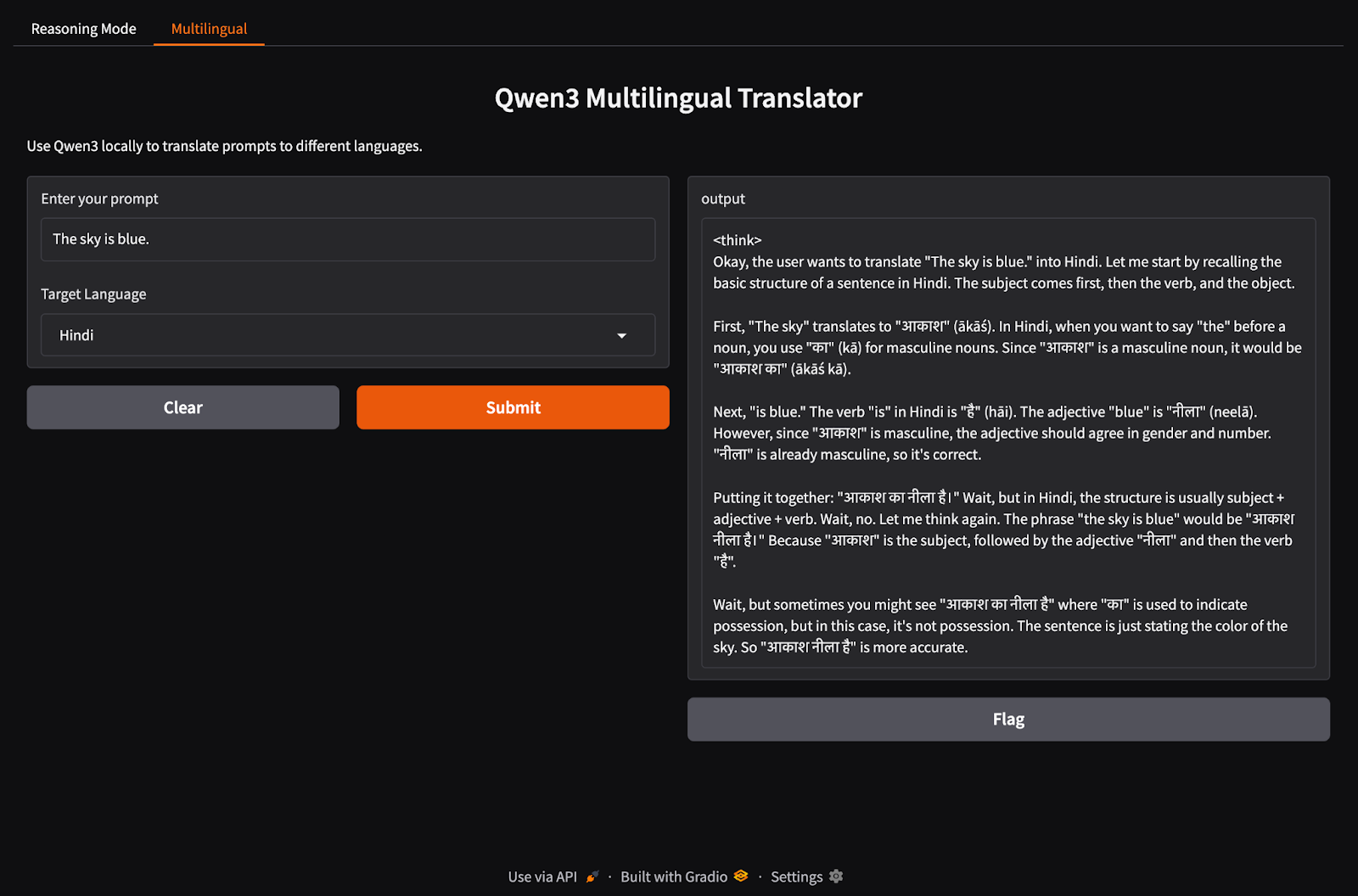
Maintenant, configurons notre onglet d'application multilingue.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Comme à l'étape précédente, ce code fonctionne comme suit :
multilingual_qwen3() prend une invite et une langue cible.Rassemblons ces deux onglets dans une application Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Voici ce que nous faisons dans le code ci-dessus :
gr.TabbedInterface() crée une interface utilisateur avec deux onglets :demo.launch(debug=True) exécute l'application localement et l'ouvre dans le navigateur avec le débogage activé.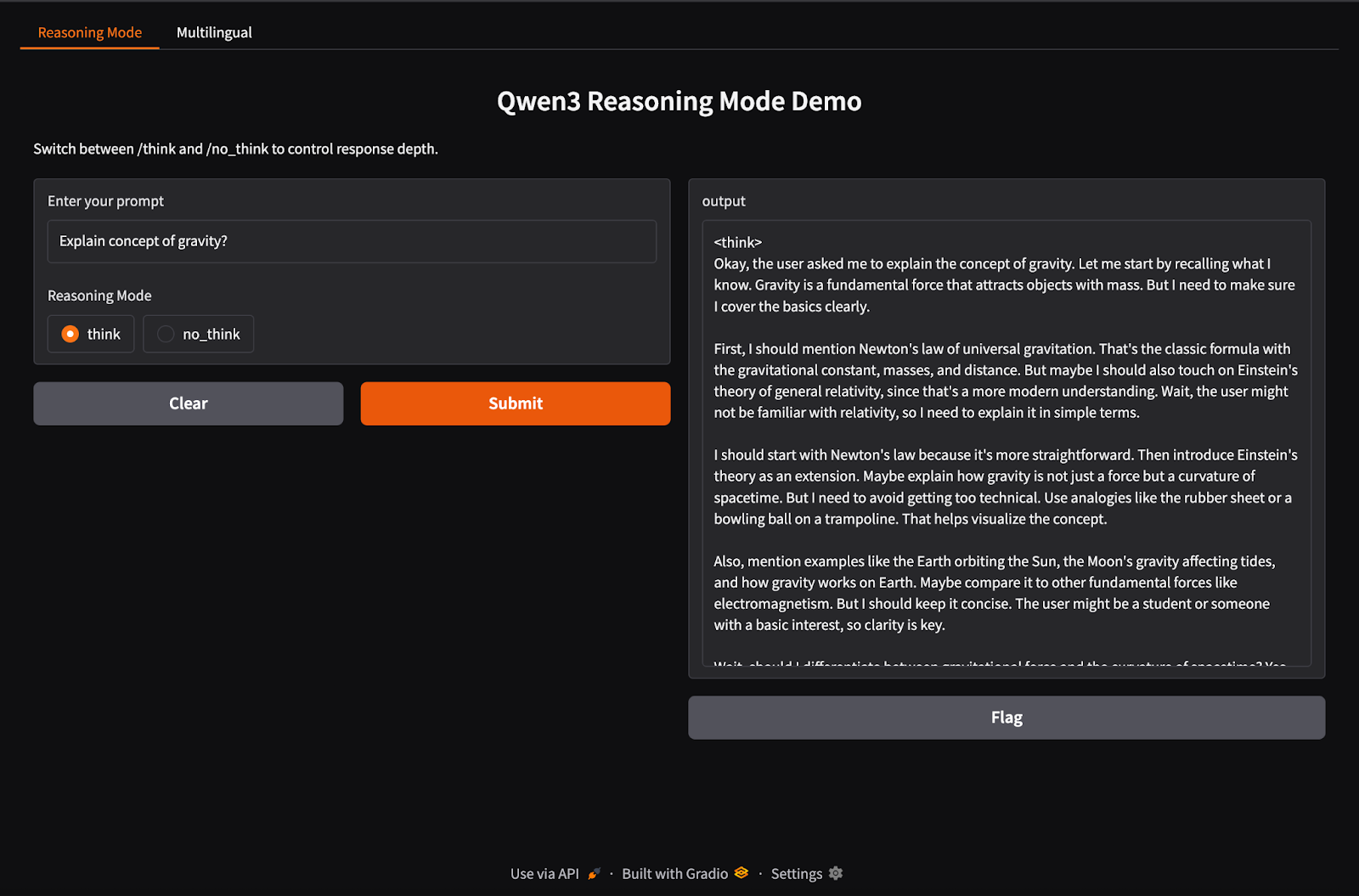
 Conclusion
ConclusionQwen3 apporte un raisonnement avancé, un décodage rapide et une prise en charge multilingue à votre machine locale à l'aide d'Ollama.
Avec un minimum d'installation, vous pouvez :
Si vous souhaitez avoir une vue d'ensemble des capacités de Qwen3, je vous recommande de lire ce blog d'introduction à Qwen3.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Kurtis Pykes
Tutoriel
Moez Ali
Tutoriel
Adel Nehme
