
Programma
Sviluppare applicazioni AI
21 h
Qwen3 è l’ultima generazione di modelli linguistici open-weight di Alibaba. Con il supporto per oltre 100 lingue e ottime prestazioni in compiti di ragionamento, coding e traduzione, Qwen3 rivaleggia con molti modelli di fascia alta disponibili oggi, tra cui DeepSeek-R1, o3-mini e Gemini 2.5.
In questo tutorial ti spiegherò passo dopo passo come eseguire Qwen3 in locale usando Ollama.
Costruiremo anche una piccola applicazione locale con Qwen3. L’app ti permetterà di passare tra le modalità di ragionamento di Qwen3 e di tradurre tra lingue diverse.
Teniamo aggiornatɜ lɜ nostrɜ lettorɜ sulle ultime novità dell’AI inviando The Median, la nostra newsletter gratuita del venerdì che riassume le notizie chiave della settimana. Iscriviti e resta sul pezzo in pochi minuti a settimana:
Eseguire Qwen3 in locale offre diversi vantaggi chiave:
Qwen3 è ottimizzato sia per il ragionamento profondo (modalità thinking) sia per risposte rapide (modalità non-thinking), e supporta oltre 100 lingue. Vediamo come configurarlo in locale.
Ollama è uno strumento che ti permette di eseguire in locale sul tuo computer modelli linguistici come Llama o Qwen tramite una semplice interfaccia a riga di comando.
Scarica Ollama per macOS, Windows o Linux da: https://ollama.com/download.
Segui le istruzioni dell’installer e, dopo l’installazione, verifica eseguendo questo comando nel terminale:
ollama --versionOllama offre una gamma crescente di modelli Qwen3 progettati per adattarsi a varie configurazioni hardware, dai laptop leggeri ai server di fascia alta.
ollama run qwen3Eseguire il comando sopra avvierà il modello Qwen3 predefinito in Ollama, che al momento è qwen3:8b. Se stai lavorando con risorse limitate o vuoi tempi di avvio più rapidi, puoi eseguire esplicitamente varianti più piccole come il modello 4B:
ollama run qwen3:4bQwen3 è attualmente disponibile in diverse varianti, dalla più piccola 0.6b (523 MB) alla più grande 235b (142 GB). Queste varianti più piccole offrono prestazioni notevoli in ragionamento, traduzione e generazione di codice, soprattutto se usate in modalità thinking.
I modelli MoE (30b-a3b, 235b-a22b) sono particolarmente interessanti perché attivano solo un sottoinsieme di “esperti” per ogni step di inferenza, consentendo un numero totale di parametri enorme mantenendo efficienti i costi di runtime.
In generale, usa il modello più grande che il tuo hardware può gestire e ripiega sui modelli 8B o 4B per esperimenti locali reattivi su macchine consumer.
Ecco un rapido riepilogo di tutti i modelli Qwen3 che puoi eseguire:
|
Modello |
Comando Ollama |
Ideale per |
|
Qwen3-0.6B |
|
Attività leggere, app mobile e dispositivi edge |
|
Qwen3-1.7B |
|
Chatbot, assistenti e applicazioni a bassa latenza |
|
Qwen3-4B |
|
Compiti generici con buon equilibrio tra prestazioni e risorse |
|
Qwen3-8B |
|
Supporto multilingue e capacità di ragionamento moderate |
|
Qwen3-14B |
|
Ragionamento avanzato, creazione di contenuti e problem solving complesso |
|
Qwen3-32B |
|
Compiti di alto livello che richiedono forte ragionamento e ampio contesto |
|
Qwen3-30B-A3B (MoE) |
|
Prestazioni efficienti con 3B parametri attivi, adatto a compiti di coding |
|
Qwen3-235B-A22B (MoE) |
|
Applicazioni su larga scala, ragionamento profondo e soluzioni enterprise |
Per esporre il modello via API, esegui questo comando nel terminale:
ollama serveQuesto renderà il modello disponibile per l’integrazione con altre applicazioni su http://localhost:11434.
In questa sezione ti mostro alcuni modi per usare Qwen3 in locale, dall’interazione di base via CLI all’integrazione del modello con Python.
Una volta scaricato il modello, puoi interagire con Qwen3 direttamente dal terminale. Esegui il seguente comando nel terminale:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bUtile per test rapidi o interazioni leggere senza scrivere codice. Il tag /think alla fine del prompt indica al modello di attivare un ragionamento più profondo, passo dopo passo. Puoi sostituirlo con /no_think per una risposta più veloce e superficiale oppure ometterlo del tutto per usare la modalità di ragionamento predefinita del modello.
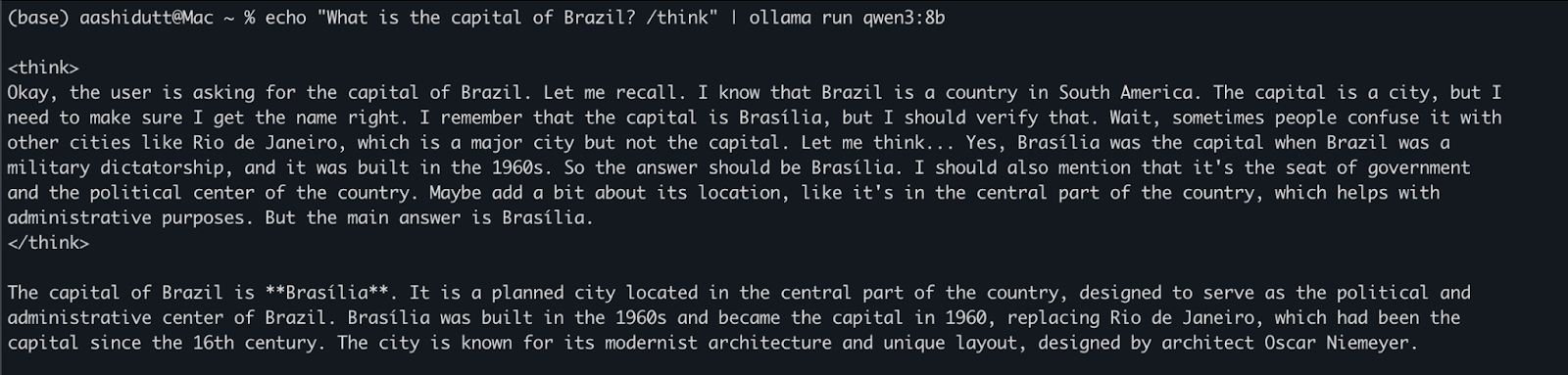
Quando ollama serve è in esecuzione in background, puoi interagire con Qwen3 in modo programmatico tramite un’API HTTP, ideale per integrazioni backend, automazione o test di client REST.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Ecco come funziona:
curl effettua una richiesta POST (come chiamiamo l’API) al server Ollama locale in esecuzione su localhost:11434."model": specifica il modello da usare (qui: qwen3:8b)."messages": una lista di messaggi di chat con role e content."stream": false: fa sì che la risposta venga restituita in un’unica soluzione, non token per token.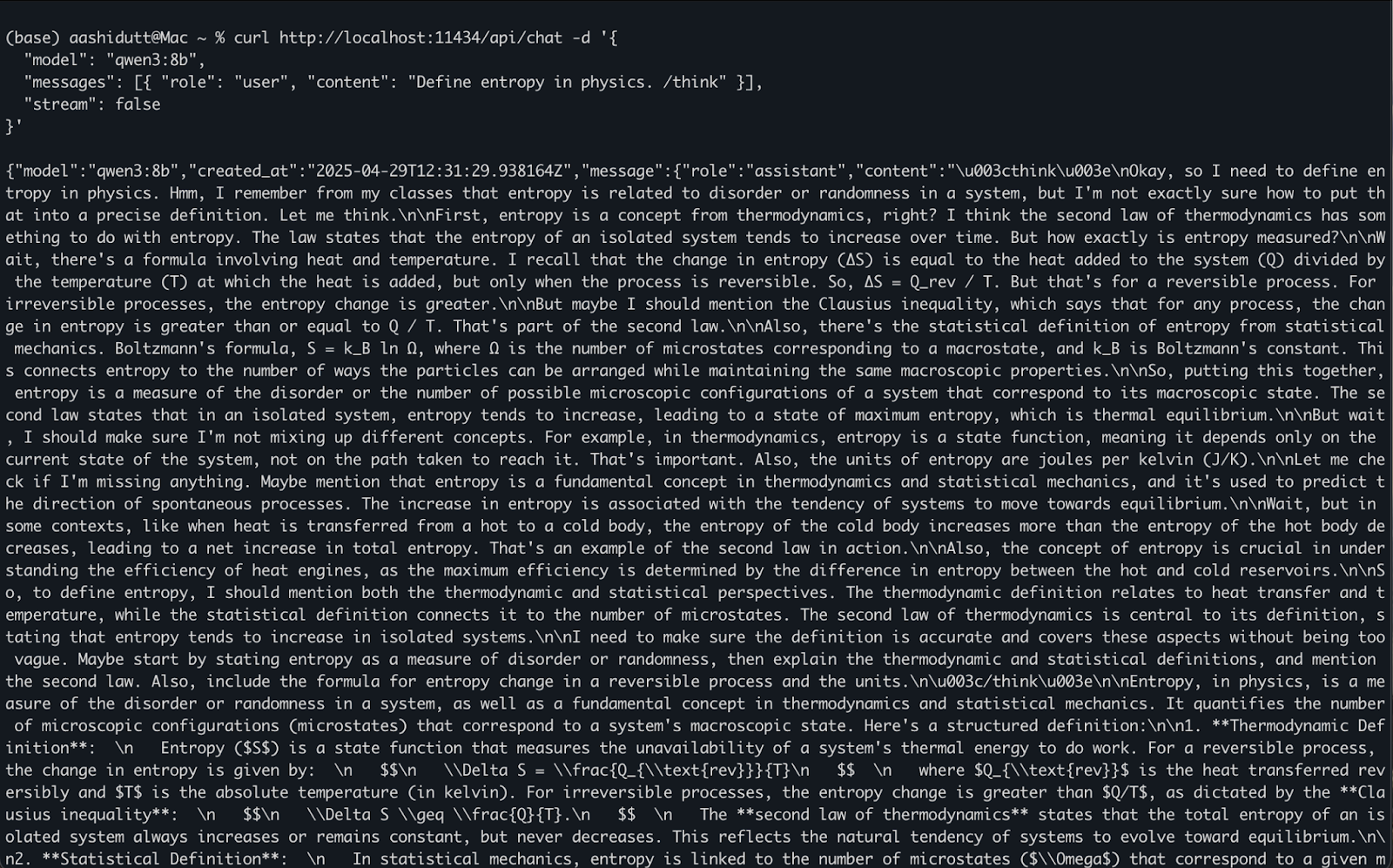
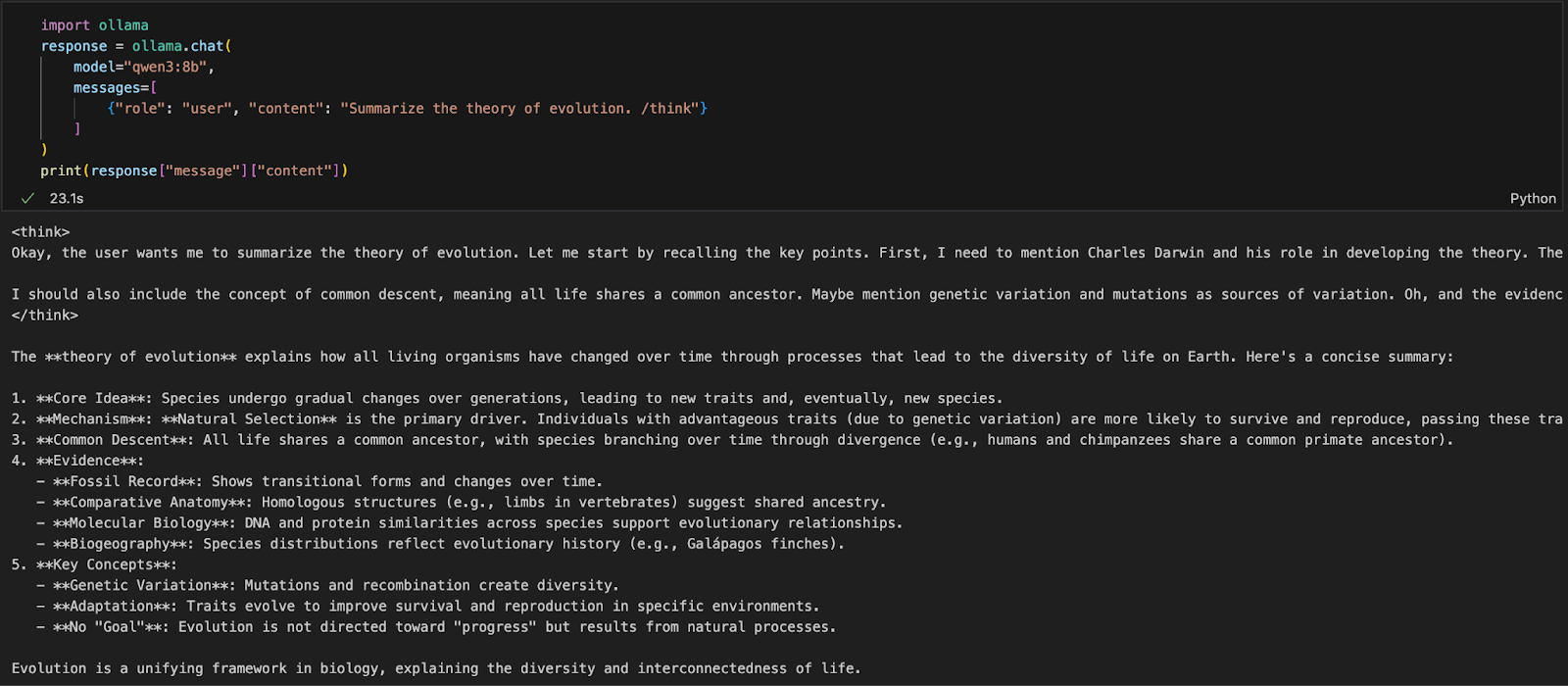
Se lavori in un ambiente Python (come Jupyter, VSCode o uno script), il modo più semplice per interagire con Qwen3 è tramite l’ Ollama Python SDK. Inizia installando ollama:
pip install ollamaPoi esegui il tuo modello Qwen3 con questo script (sotto usiamo qwen3:8b):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Nel codice sopra:
ollama.chat(...) invia una richiesta in stile chat al server Ollama locale.qwen3:8b) e una lista di messaggi in un formato simile all’API di OpenAI./think indica al modello di ragionare passo dopo passo.["message"]["content"].Questo approccio è ideale per esperimenti locali, prototipazione o per costruire app basate su LLM senza dipendere da API cloud.
Qwen3 supporta un comportamento di inferenza ibrido usando i tag /think (ragionamento profondo) e /no_think (risposta veloce). In questa sezione useremo Gradio per creare un’app web locale interattiva con due schede separate:
In questo passaggio, costruiamo la scheda di ragionamento ibrido con i tag /think e /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Nel codice sopra:
reasoning_qwen3() accetta un prompt dell’utente e una modalità di ragionamento ("think" o "no_think").subprocess.run() esegue il comando ollama run qwen3:8b, passando il prompt come input standard.Definita la funzione che genera l’output, la funzione gr.Interface() la incapsula in una UI web interattiva specificando i componenti di input — una Textbox per il prompt e un pulsante Radio per selezionare la modalità di ragionamento — e mappandoli agli input della funzione.
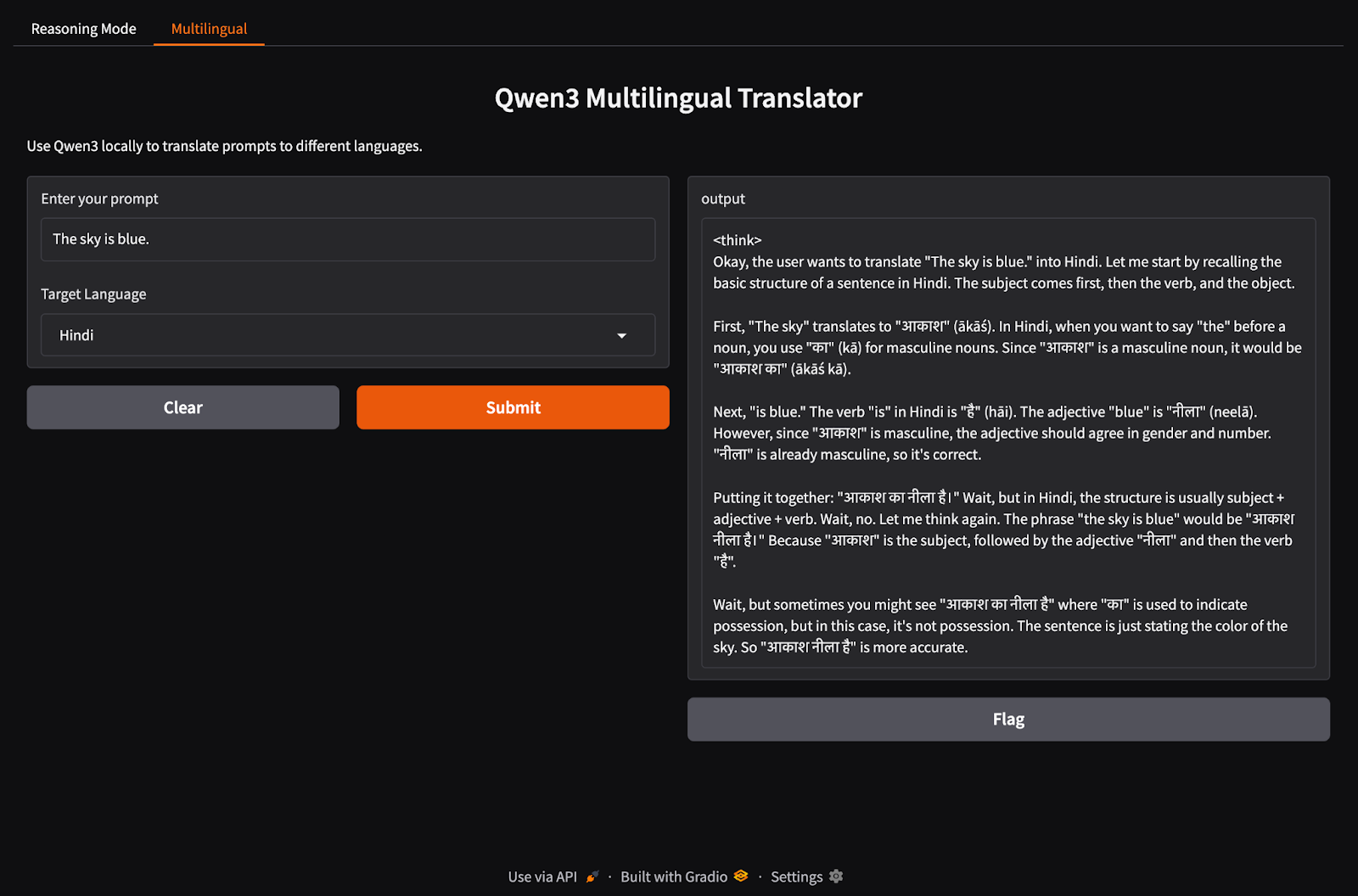
Ora configuriamo la scheda della nostra applicazione multilingue.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Similmente al passaggio precedente, questo codice funziona così:
multilingual_qwen3() accetta un prompt e una lingua di destinazione.Mettiamo insieme entrambe le schede in un’applicazione Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Ecco cosa facciamo nel codice sopra:
gr.TabbedInterface() crea una UI con due schede:demo.launch(debug=True) esegue l’app in locale e la apre nel browser con il debug abilitato.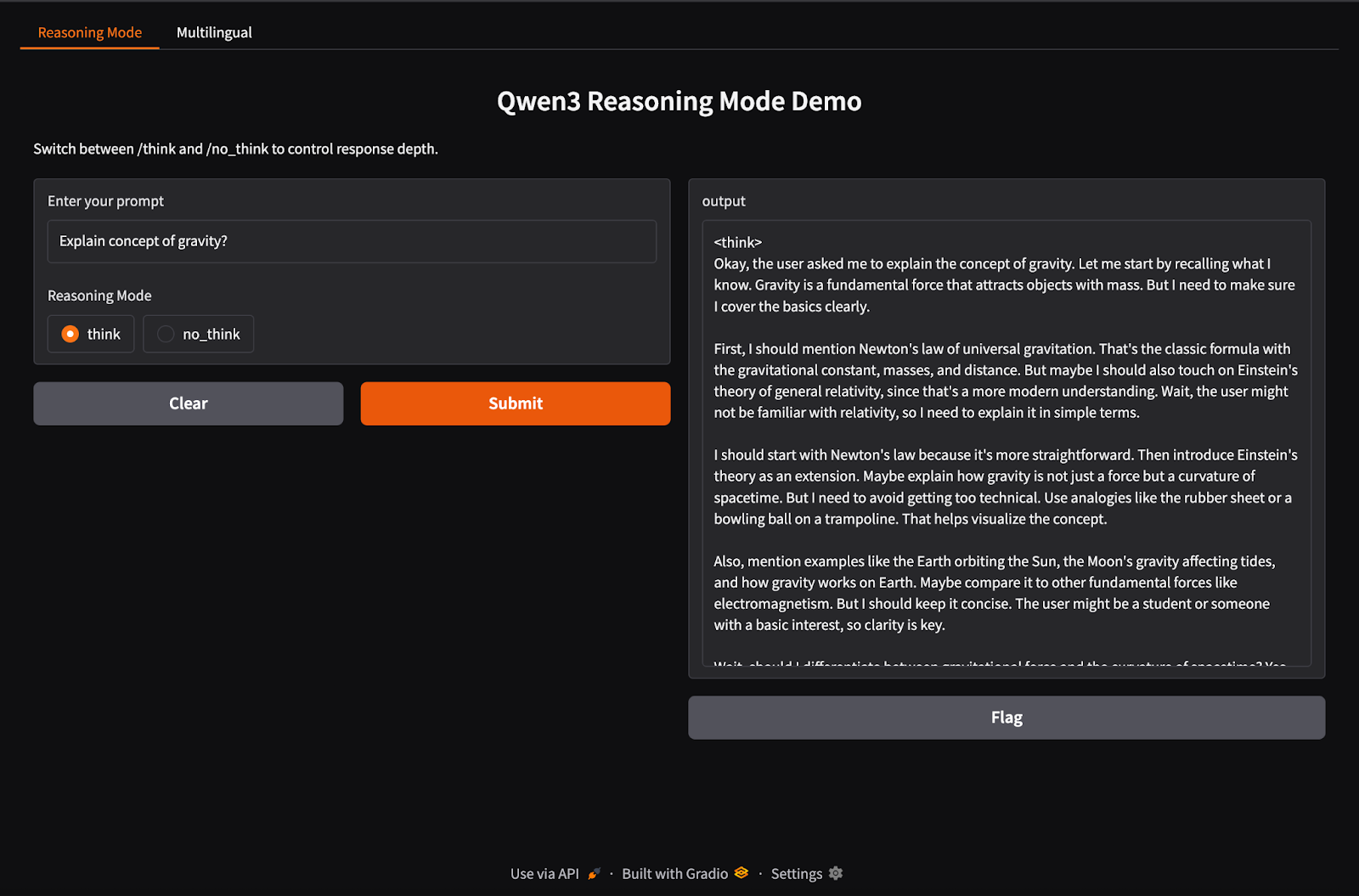
 Conclusione
ConclusioneQwen3 porta ragionamento avanzato, decodifica rapida e supporto multilingue sul tuo computer locale attraverso Ollama.
Con una configurazione minima, puoi:
Per saperne di più su Qwen3, ti consiglio di:
Impara l’AI con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

