
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Qwen3 ist die neueste Generation von Alibabas großen Sprachmodellen mit offenem Gewicht. Mit der Unterstützung von mehr als 100 Sprachen und einer starken Leistung bei Argumentations-, Kodierungs- und Übersetzungsaufgaben konkurriert Qwen3 mit vielen heute verfügbaren Spitzenmodellen, darunter DeepSeek-R1, o3-mini und Gemini 2.5.
In diesem Tutorial erkläre ich Schritt für Schritt wie man Qwen3 lokal ausführt mit Ollama ausführt.
Wir werden auch eine lokale, leichtgewichtige Anwendung mit Qwen 3 erstellen. Mit der App kannst du zwischen den Argumentationsmodi von Qwen3 wechseln und zwischen verschiedenen Sprachen übersetzen.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Der lokale Betrieb von Qwen3 bietet mehrere wichtige Vorteile:
Qwen3 ist sowohl für tiefes Denken (Denkmodus) als auch für schnelle Antworten (Nicht-Denkmodus) optimiert und unterstützt über 100 Sprachen. Lass uns das lokal einrichten.
Ollama ist ein Tool, mit dem du Sprachmodelle wie Llama oder Qwen lokal auf deinem Computer über eine einfache Befehlszeilenschnittstelle ausführen kannst.
Lade Ollama für macOS, Windows oder Linux herunter unter: https://ollama.com/download.
Befolge die Anweisungen des Installationsprogramms und überprüfe nach der Installation, indem du dies im Terminal ausführst:
ollama --versionOllama bietet eine wachsende Auswahl an Qwen3-Modellen an, die für eine Vielzahl von Hardwarekonfigurationen geeignet sind, von leichten Laptops bis hin zu High-End-Servern.
ollama run qwen3Wenn du den obigen Befehl ausführst, wird das Standardmodell von Qwen3 in Ollama gestartet, das derzeit auf qwen3:8b voreingestellt ist. Wenn du mit begrenzten Ressourcen arbeitest oder schnellere Startzeiten haben willst, kannst du explizit kleinere Varianten wie das 4B-Modell einsetzen:
ollama run qwen3:4bQwen3 ist derzeit in mehreren Varianten erhältlich, angefangen von der kleinsten 0,6b(523MB) bis hin zur größten 235b(142GB) Parametervariante. Diese kleineren Varianten bieten eine beeindruckende Leistung beim Reasoning, der Übersetzung und der Codegenerierung, vor allem wenn sie im Denkmodus verwendet werden.
Die MoE-Modelle (30b-a3b, 235b-a22b) sind besonders interessant, da sie nur eine Teilmenge von Experten pro Inferenzschritt aktivieren, was eine große Anzahl von Parametern ermöglicht und gleichzeitig die Laufzeitkosten niedrig hält.
Generell solltest du das größte Modell verwenden, das deine Hardware verarbeiten kann, und für reaktionsschnelle lokale Experimente auf Consumer-Rechnern auf das 8B- oder 4B-Modell zurückgreifen.
Hier ist eine kurze Übersicht über alle Qwen3-Modelle, die du einsetzen kannst :
|
Modell |
Ollama Kommando |
Am besten für |
|
Qwen3-0.6B |
|
Leichte Aufgaben, mobile Anwendungen und Endgeräte |
|
Qwen3-1.7B |
|
Chatbots, Assistenten und Anwendungen mit niedriger Latenzzeit |
|
Qwen3-4B |
|
Allzweckaufgaben mit ausgewogener Leistung und Ressourcennutzung |
|
Qwen3-8B |
|
Mehrsprachige Unterstützung und moderate Argumentationsfähigkeiten |
|
Qwen3-14B |
|
Fortgeschrittenes logisches Denken, Erstellen von Inhalten und Lösen von komplexen Problemen |
|
Qwen3-32B |
|
Anspruchsvolle Aufgaben, die ein starkes logisches Denken und eine umfangreiche Kontextverarbeitung erfordern |
|
Qwen3-30B-A3B (MoE) |
|
Effiziente Leistung mit 3B aktiven Parametern, geeignet für Codieraufgaben |
|
Qwen3-235B-A22B (MoE) |
|
Massive Anwendungen, tiefgreifende Schlussfolgerungen und Lösungen auf Unternehmensebene |
Um das Modell über die API zu bedienen, führe diesen Befehl im Terminal aus:
ollama serveDadurch wird das Modell für die Integration in andere Anwendungen verfügbar unter http://localhost:11434.
In diesem Abschnitt zeige ich dir verschiedene Möglichkeiten, wie du Qwen3 lokal nutzen kannst, von der einfachen CLI-Interaktion bis zur Integration des Modells in Python.
Sobald das Modell heruntergeladen ist, kannst du direkt im Terminal mit Qwen3 interagieren. Führe den folgenden Befehl in deinem Terminal aus:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bDies ist nützlich für schnelle Tests oder leichte Interaktionen, ohne dass du Code schreiben musst. Der /think Tag am Ende der Aufforderung weist das Modell an, Schritt für Schritt tiefer zu argumentieren. Du kannst dies durch /no_think ersetzen, um eine schnellere, flachere Reaktion zu erhalten, oder es ganz weglassen, um den Standard-Denkmodus des Modells zu verwenden.
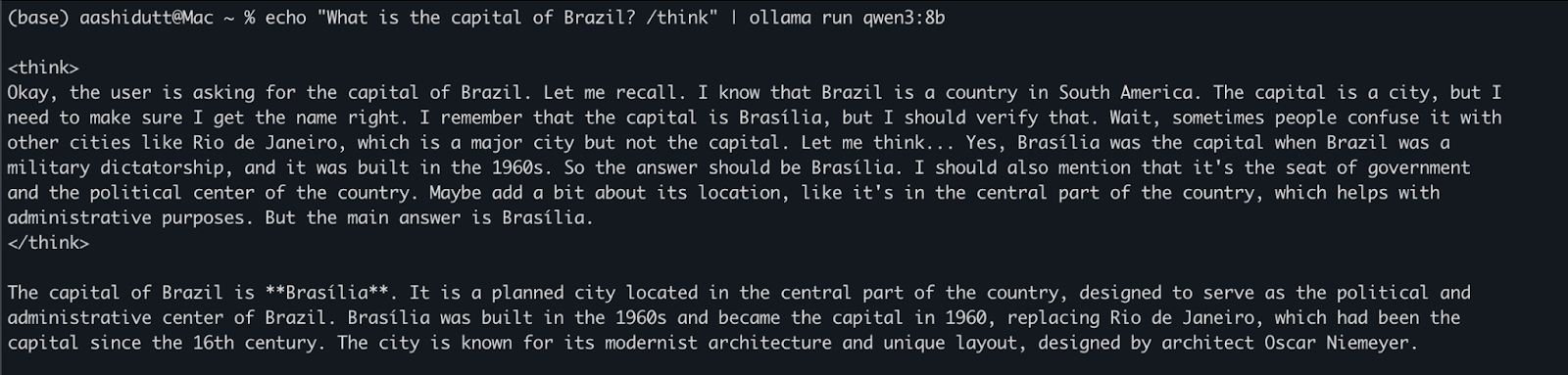
Sobald ollama serve im Hintergrund läuft, kannst du über eine HTTP-API programmatisch mit Qwen3 interagieren, was sich perfekt für Backend-Integration, Automatisierung oder das Testen von REST-Clients eignet.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'So funktioniert es:
curl stellt eine POST Anfrage (wie wir die API aufrufen) an den lokalen Ollama-Server, der unter localhost:11434 läuft."model": Gibt das zu verwendende Modell an (hier ist es: qwen3:8b)."messages": Eine Liste von Chat-Nachrichten, die role und content enthält."stream": false: Stellt sicher, dass die Antwort auf einmal zurückgegeben wird, nicht Token für Token.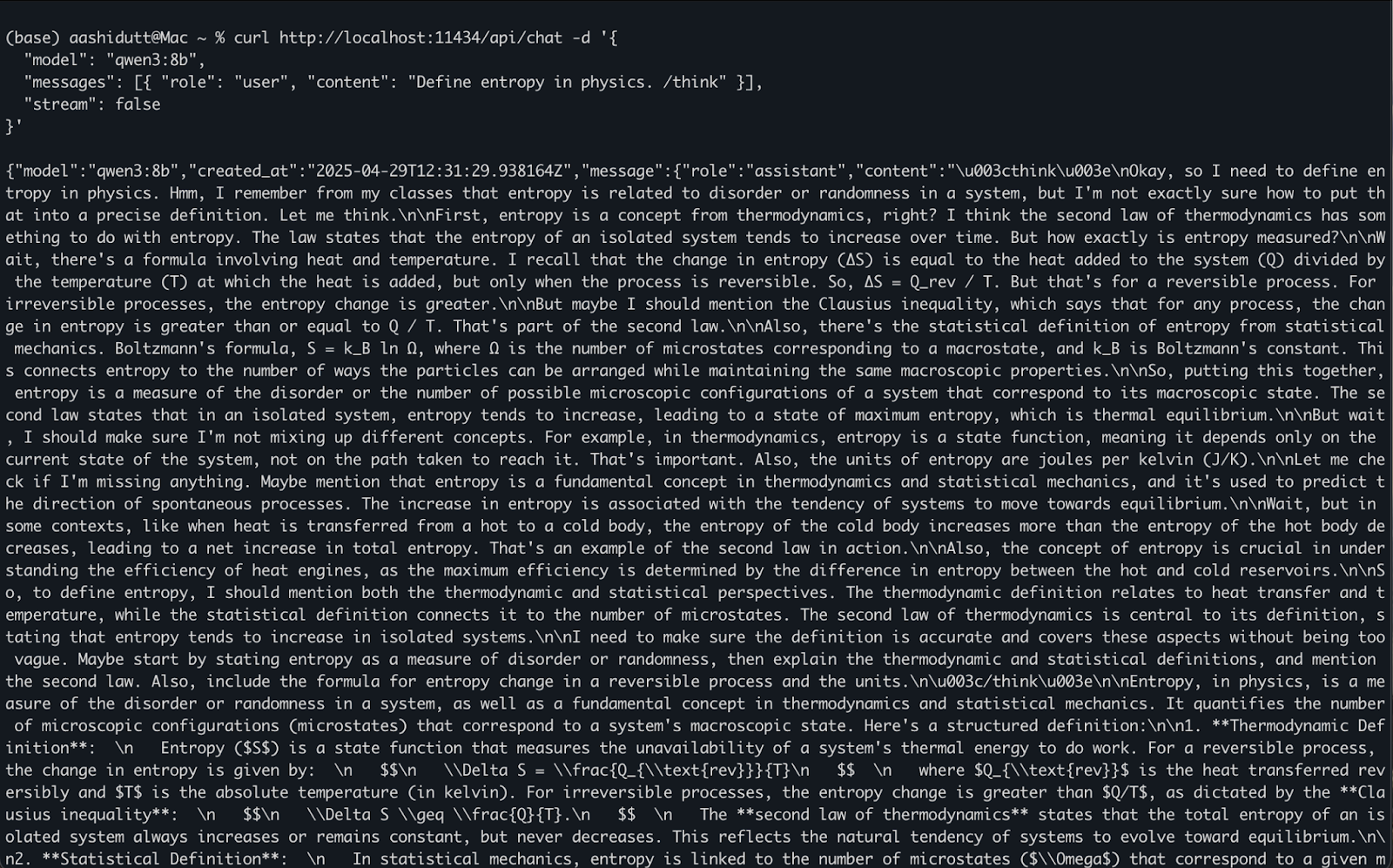
Wenn du in einer Python-Umgebung (wie Jupyter, VSCode oder einem Skript) arbeitest, ist der einfachste Weg, mit Qwen3 zu interagieren, über das Ollama Python SDK. Beginne mit der Installation von ollama:
pip install ollamaDann führst du dein Qwen3-Modell mit diesem Skript aus (wir verwenden qwen3:8b ):
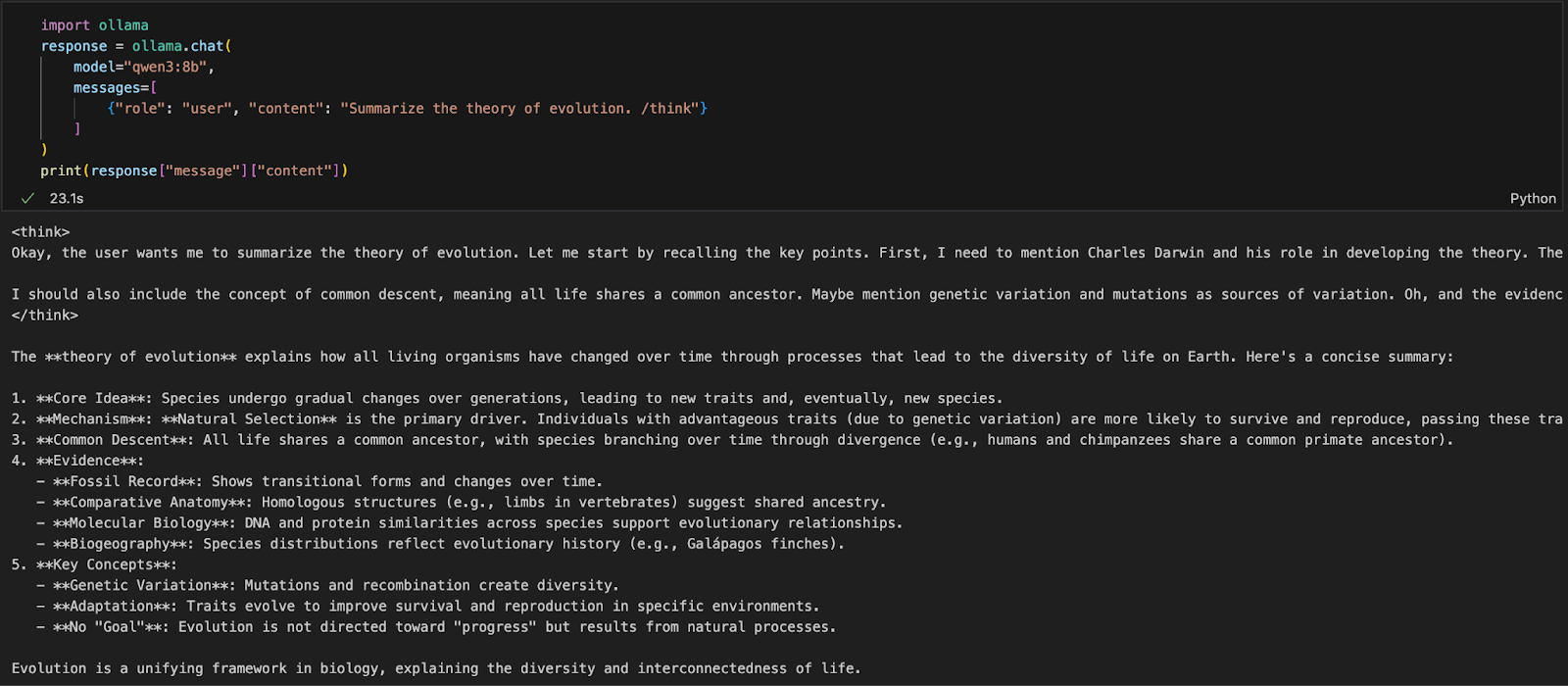
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Im obigen Code:
ollama.chat(...) sendet eine Anfrage im Chat-Stil an den lokalen Ollama-Server.qwen3:8b) und eine Liste von Nachrichten in einem Format an, das der API von OpenAI ähnelt./think Tag sagt dem Modell, dass es Schritt für Schritt denken soll.["message"]["content"] auf die Antwort des Modells zugreifen.Dieser Ansatz ist ideal für lokale Experimente, Prototyping oder den Aufbau von LLM-gestützten Apps, ohne auf Cloud-APIs angewiesen zu sein.
Qwen3 unterstützt hybrides Inferenzverhalten mit /think (Deep Reasoning) und /no_think (Fast Response) Tags. In diesem Abschnitt werden wir Gradio verwenden, um eine interaktive lokale Web-App mit zwei separaten Registerkarten zu erstellen:
In diesem Schritt bauen wir unsere hybride Argumentationskarte mit den Tags /think und /no_think auf.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Im obigen Code:
reasoning_qwen3() benötigt eine Eingabeaufforderung und einen Argumentationsmodus ("think" oder "no_think").subprocess.run() den Befehl ollama run qwen3:8b aus und gibt die Eingabeaufforderung als Standardeingabe ein.Sobald die ausgabeerzeugende Funktion definiert ist, wird sie mit der Funktion gr.Interface() in eine interaktive Web-UI verpackt, indem Eingabekomponenten festgelegt werden - Textbox für die Eingabeaufforderung und eine Schaltfläche Radio für die Auswahl des Argumentationsmodus - und diese den Eingaben der Funktion zugeordnet werden.
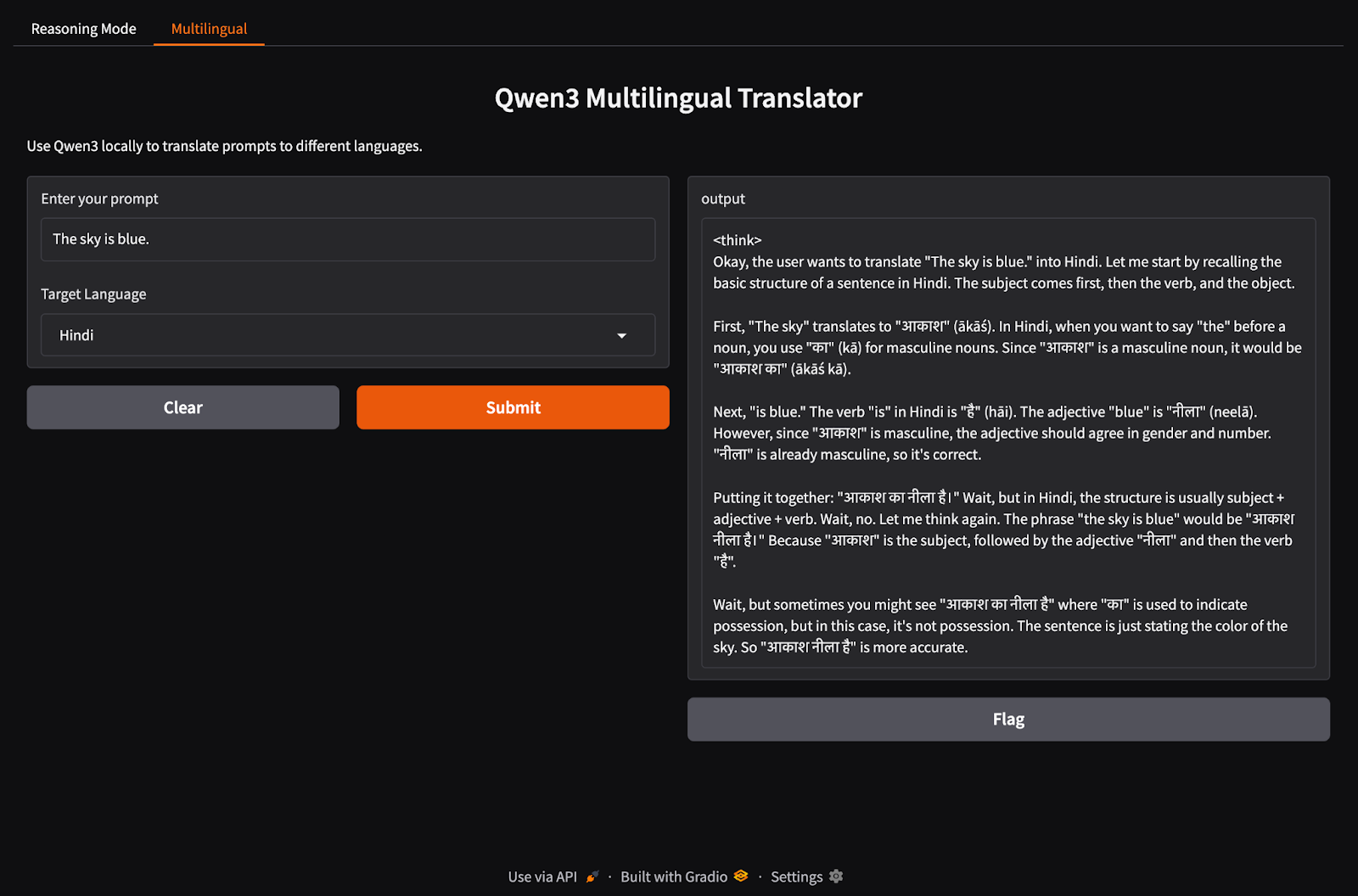
Richten wir nun die Registerkarte für unsere mehrsprachige Anwendung ein.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Ähnlich wie im vorherigen Schritt funktioniert dieser Code wie folgt:
multilingual_qwen3() benötigt eine Eingabeaufforderung und eine Zielsprache.Lass uns die beiden Tabs in einer Gradio-Anwendung zusammenführen.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Das machen wir im obigen Code:
gr.TabbedInterface() erstellt eine Benutzeroberfläche mit zwei Registerkarten:demo.launch(debug=True) führt die App lokal aus und öffnet sie im Browser mit aktiviertem Debugging.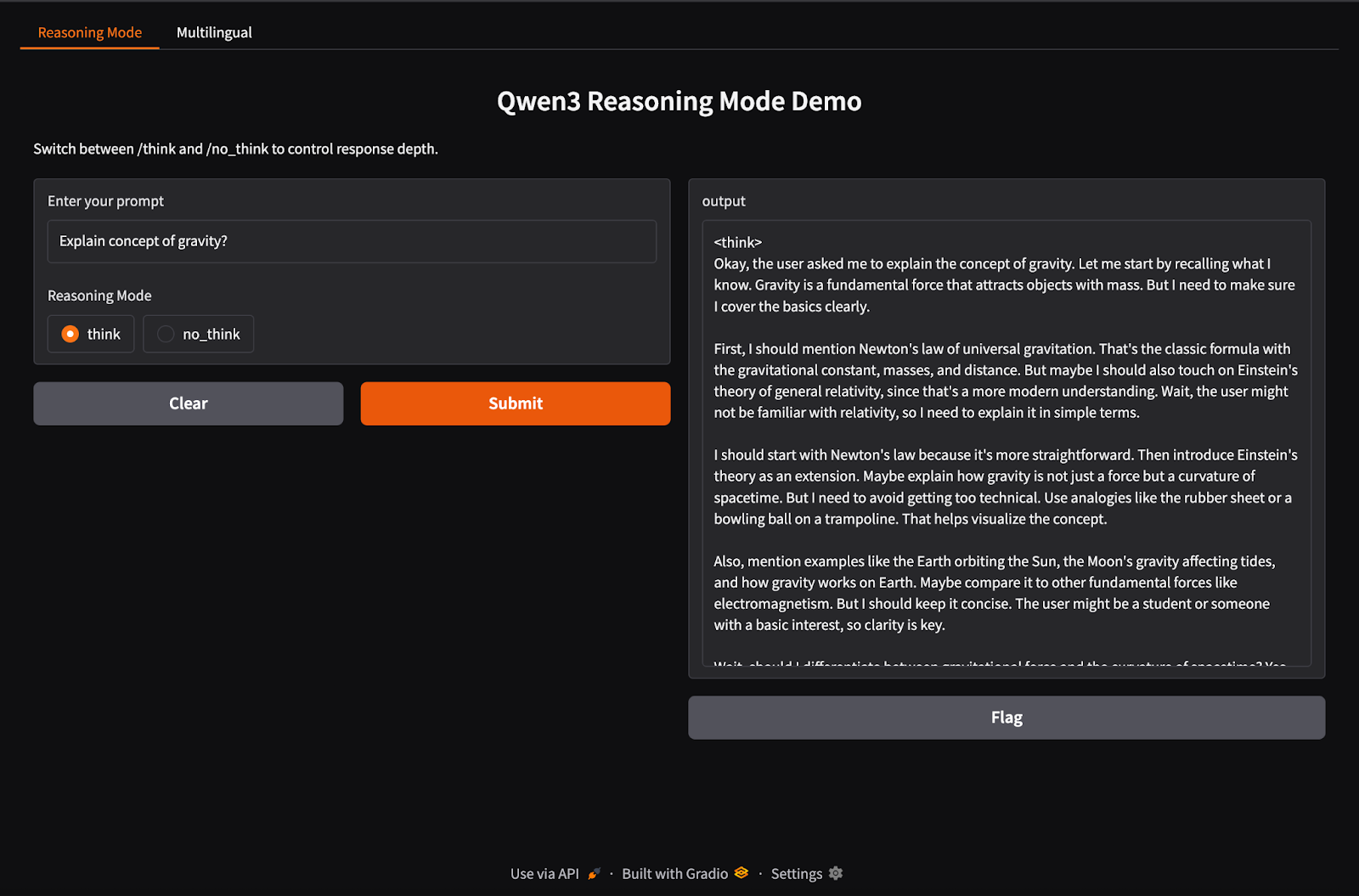
 Fazit
FazitQwen3 bringt mit Ollama fortschrittliches Reasoning, schnelle Dekodierung und mehrsprachige Unterstützung auf deinen lokalen Rechner.
Mit minimaler Einrichtung kannst du:
Wenn du dir einen Überblick über die Möglichkeiten von Qwen3 verschaffen willst, empfehle ich dir, diesen Einführungsblog zu lesen Qwen3.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Allan Ouko
Tutorial
Adel Nehme
Tutorial
Moez Ali

