
Track
Developing AI Applications
21 hr
Qwen3 is Alibaba's latest generation of open-weight large language models. With support for 100+ languages and strong performance across reasoning, coding, and translation tasks, Qwen3 rivals many top-tier models available today, including DeepSeek-R1, o3-mini, and Gemini 2.5.
In this tutorial, I’ll explain step-by-step how to run Qwen3 locally using Ollama.
We’ll also build a local lightweight application with Qwen 3. The app will enable you to switch between Qwen3’s reasoning modes and translate between different languages.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
Running Qwen3 locally provides several key benefits:
Qwen3 is optimized for both deep reasoning (thinking mode) and fast responses (non-thinking mode), and supports 100+ languages. Let's set it up locally.
Ollama is a tool that lets you run language models like Llama or Qwen locally on your computer with a simple command-line interface.
Download Ollama for macOS, Windows, or Linux from: https://ollama.com/download.
Follow the installer instructions, and after installation, verify by running this in the terminal:
ollama --versionOllama offers a growing range of Qwen3 models designed to suit a variety of hardware configurations, from lightweight laptops to high-end servers.
ollama run qwen3Running the command above will launch the default Qwen3 model in Ollama, which currently defaults to qwen3:8b. If you're working with limited resources or want faster startup times, you can explicitly run smaller variants like the 4B model:
ollama run qwen3:4bQwen3 is currently available in several variants, starting from the smallest 0.6b(523MB) to the largest 235b(142GB) parameter models. These smaller variants offer impressive performance for reasoning, translation, and code generation, especially when used in thinking mode.
The MoE models (30b-a3b, 235b-a22b) are particularly interesting as they activate only a subset of experts per inference step, allowing for massive total parameter counts while keeping runtime costs efficient.
In general, use the largest model your hardware can handle, and fall back to the 8B or 4B models for responsive local experiments on consumer machines.
Here’s a quick recap of all the Qwen3 models you can run:
|
Model |
Ollama Command |
Best For |
|
Qwen3-0.6B |
|
Lightweight tasks, mobile applications, and edge devices |
|
Qwen3-1.7B |
|
Chatbots, assistants, and low-latency applications |
|
Qwen3-4B |
|
General-purpose tasks with balanced performance and resource usage |
|
Qwen3-8B |
|
Multilingual support and moderate reasoning capabilities |
|
Qwen3-14B |
|
Advanced reasoning, content creation, and complex problem-solving |
|
Qwen3-32B |
|
High-end tasks requiring strong reasoning and extensive context handling |
|
Qwen3-30B-A3B (MoE) |
|
Efficient performance with 3B active parameters, suitable for coding tasks |
|
Qwen3-235B-A22B (MoE) |
|
Massive-scale applications, deep reasoning, and enterprise-level solutions |
To serve the model via API, run this command in the terminal:
ollama serveThis will make the model available for integration with other applications at http://localhost:11434.
In this section, I’ll walk you through several ways you can use Qwen3 locally, from basic CLI interaction to integrating the model with Python.
Once the model is downloaded, you can interact with Qwen3 directly in the terminal. Run the following command in your terminal:
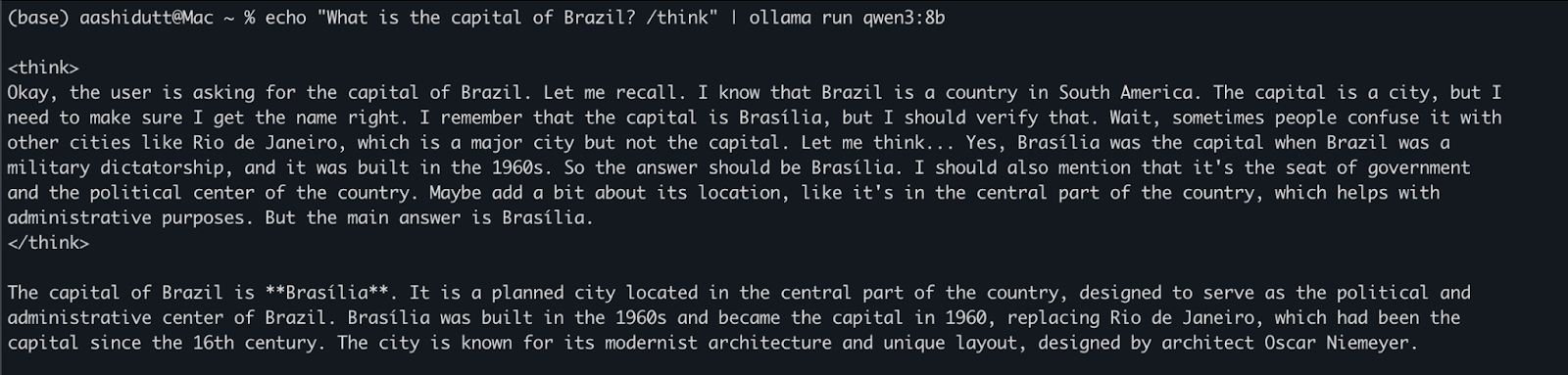
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bThis is useful for quick tests or lightweight interaction without writing any code. The /think tag at the end of the prompt instructs the model to engage in deeper, step-by-step reasoning. You can replace this with /no_think for a faster, shallower response or omit it entirely to use the model’s default reasoning mode.
Once ollama serve is running in the background, you can interact with Qwen3 programmatically using an HTTP API, which is perfect for backend integration, automation, or testing REST clients.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Here is how it works:
curl makes a POST request (how we call the API) to the local Ollama server running at localhost:11434."model": Specifies the model to use (here it is: qwen3:8b)."messages": A list of chat messages containing role and content."stream": false: Ensures the response is returned all at once, not token-by-token.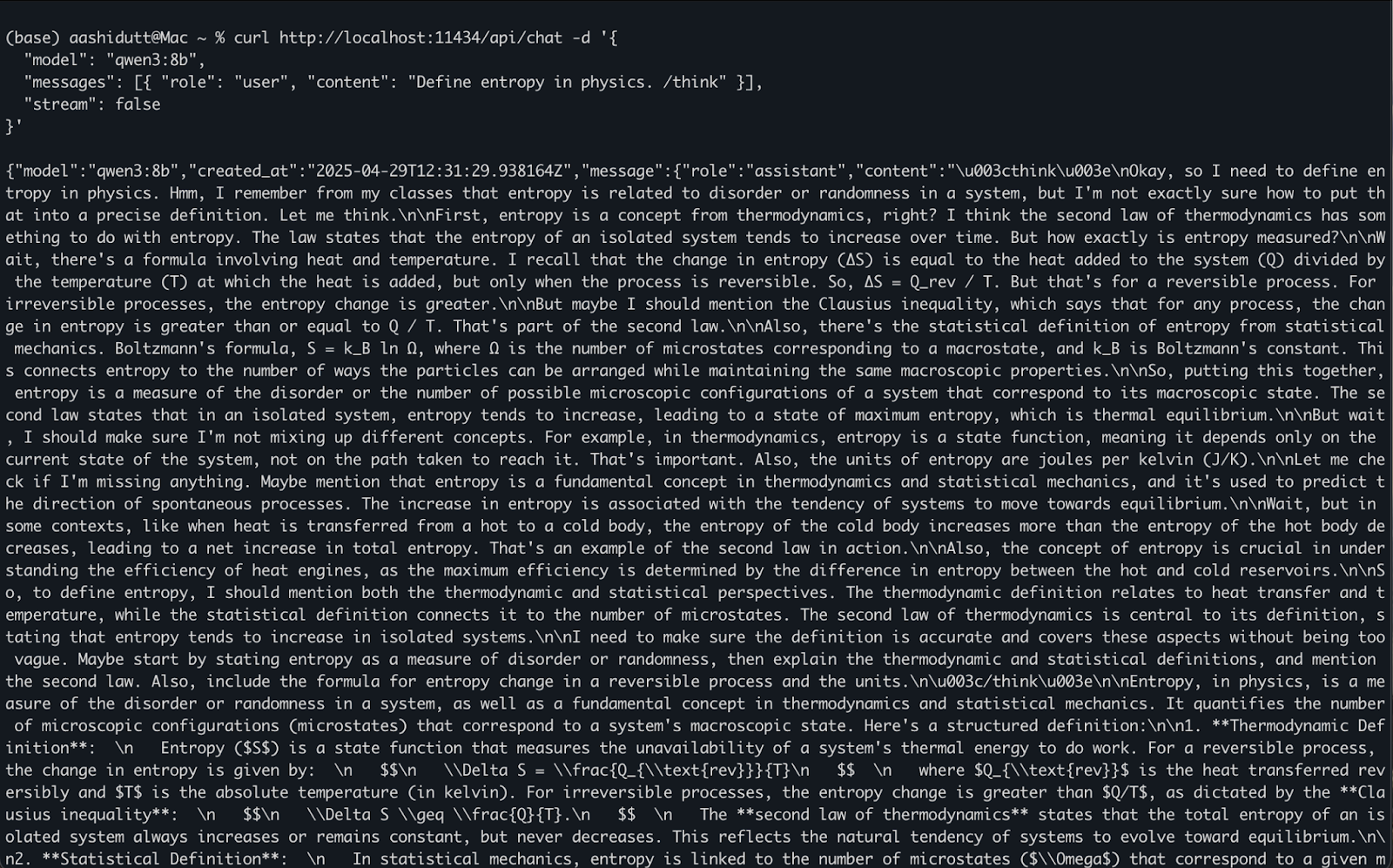
If you’re working in a Python environment (like Jupyter, VSCode, or a script), the easiest way to interact with Qwen3 is via the Ollama Python SDK. Start by installing ollama:
pip install ollamaThen, run your Qwen3 model with this script (we’re using qwen3:8b below):
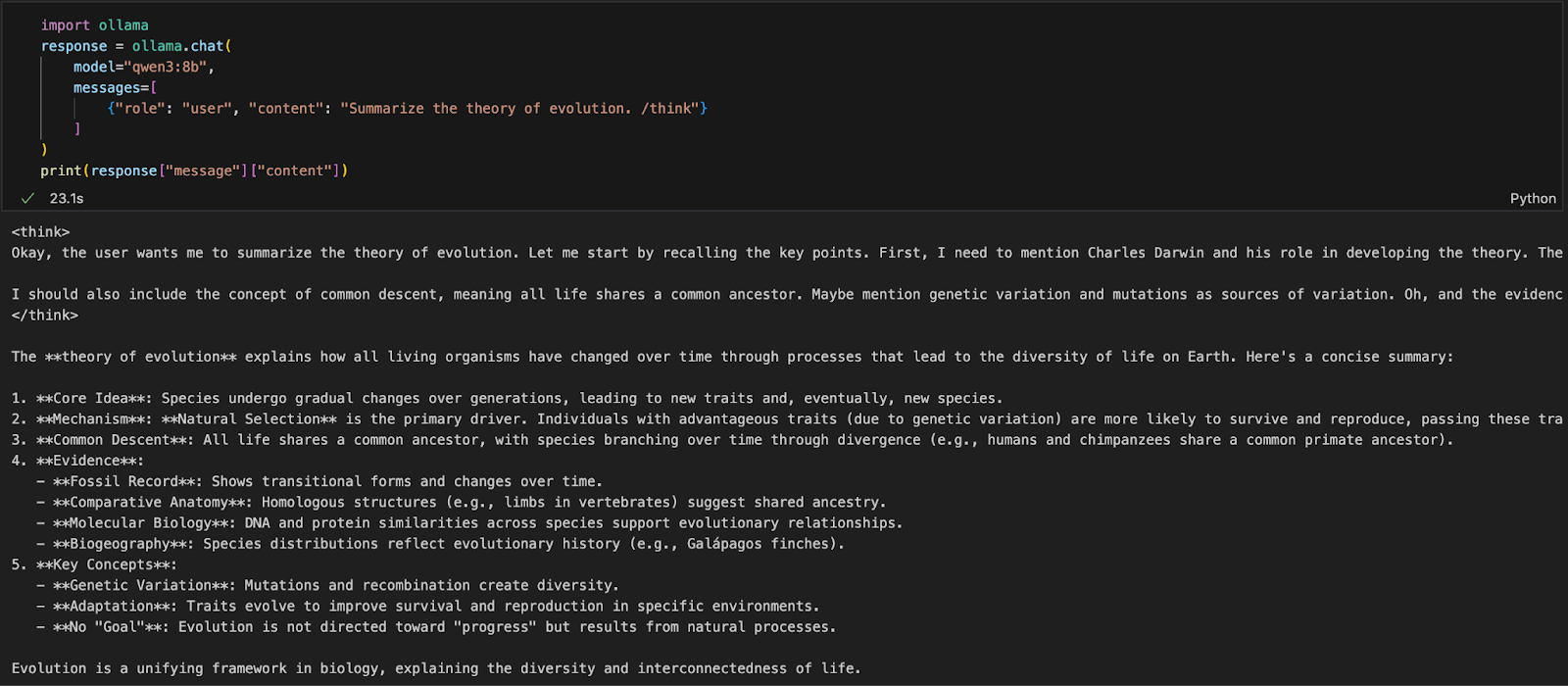
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])In the above code:
ollama.chat(...) sends a chat-style request to the local Ollama server.qwen3:8b) and a list of messages in a format similar to OpenAI’s API./think tag tells the model to reason step by step.["message"]["content"].This approach is ideal for local experimentation, prototyping, or building LLM-backed apps without relying on cloud APIs.
Qwen3 supports hybrid inference behavior using /think (deep reasoning) and /no_think (fast response) tags. In this section, we’ll use Gradio to create an interactive local web app with two separate tabs:
In this step, we build our hybrid reasoning tab with /think and /no_think tags.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)In the above code:
reasoning_qwen3() takes a user prompt and a reasoning mode ("think" or "no_think").subprocess.run() method runs the command ollama run qwen3:8b, feeding the prompt as standard input.Once the output-generating function is defined, the gr.Interface() function wraps it into an interactive web UI by specifying input components—a Textbox for the prompt and a Radio button for selecting the reasoning mode—and mapping them to the function's inputs.
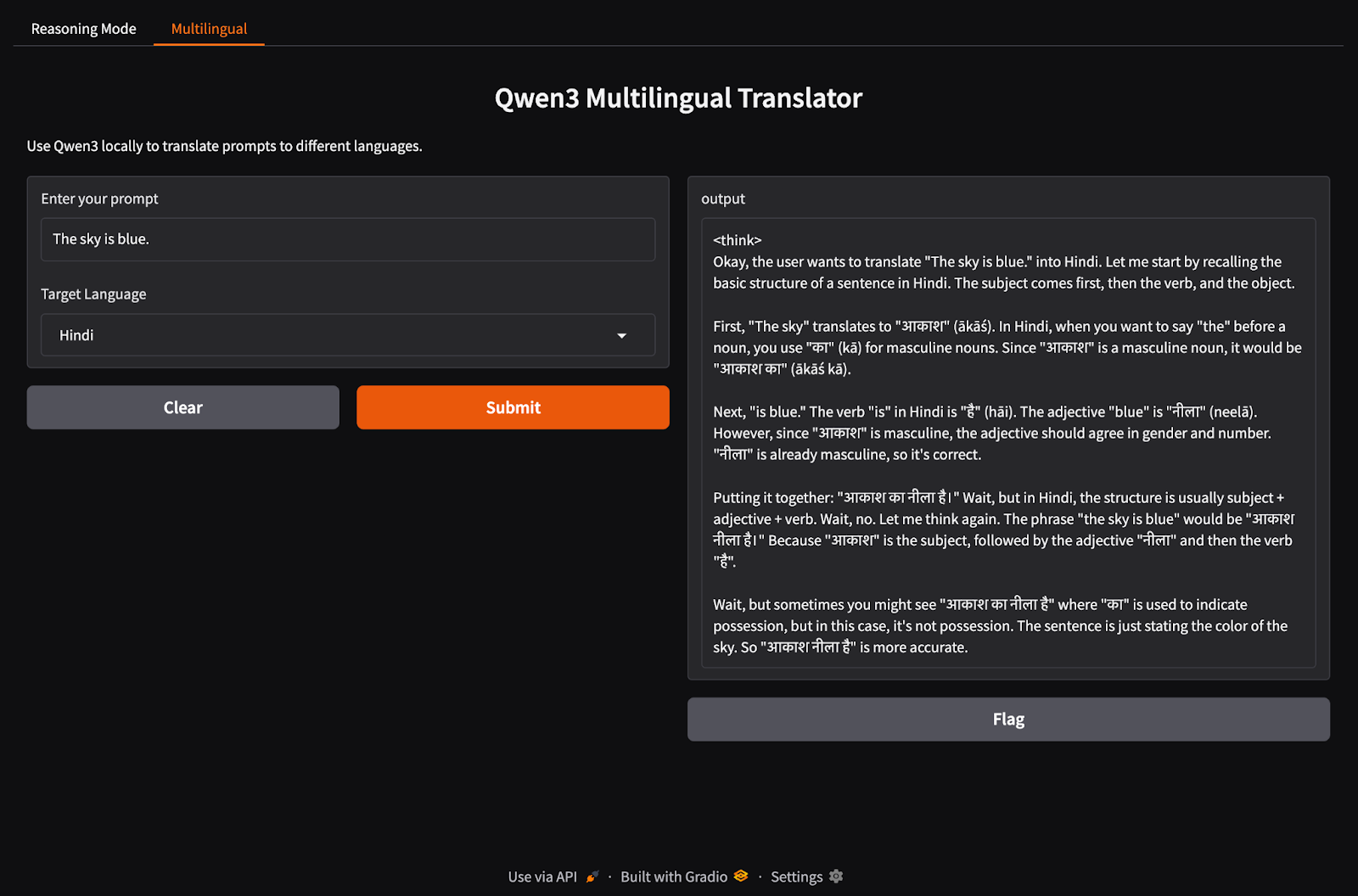
Now, let’s set up our multilingual application tab.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Similar to the previous step, this code works as follows:
multilingual_qwen3() function takes a prompt and a target language.Let’s bring both the tabs together in a Gradio application.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Here is what we are doing in the above code:
gr.TabbedInterface() function creates a UI with two tabs:demo.launch(debug=True) function runs the app locally and opens it in the browser with debugging enabled.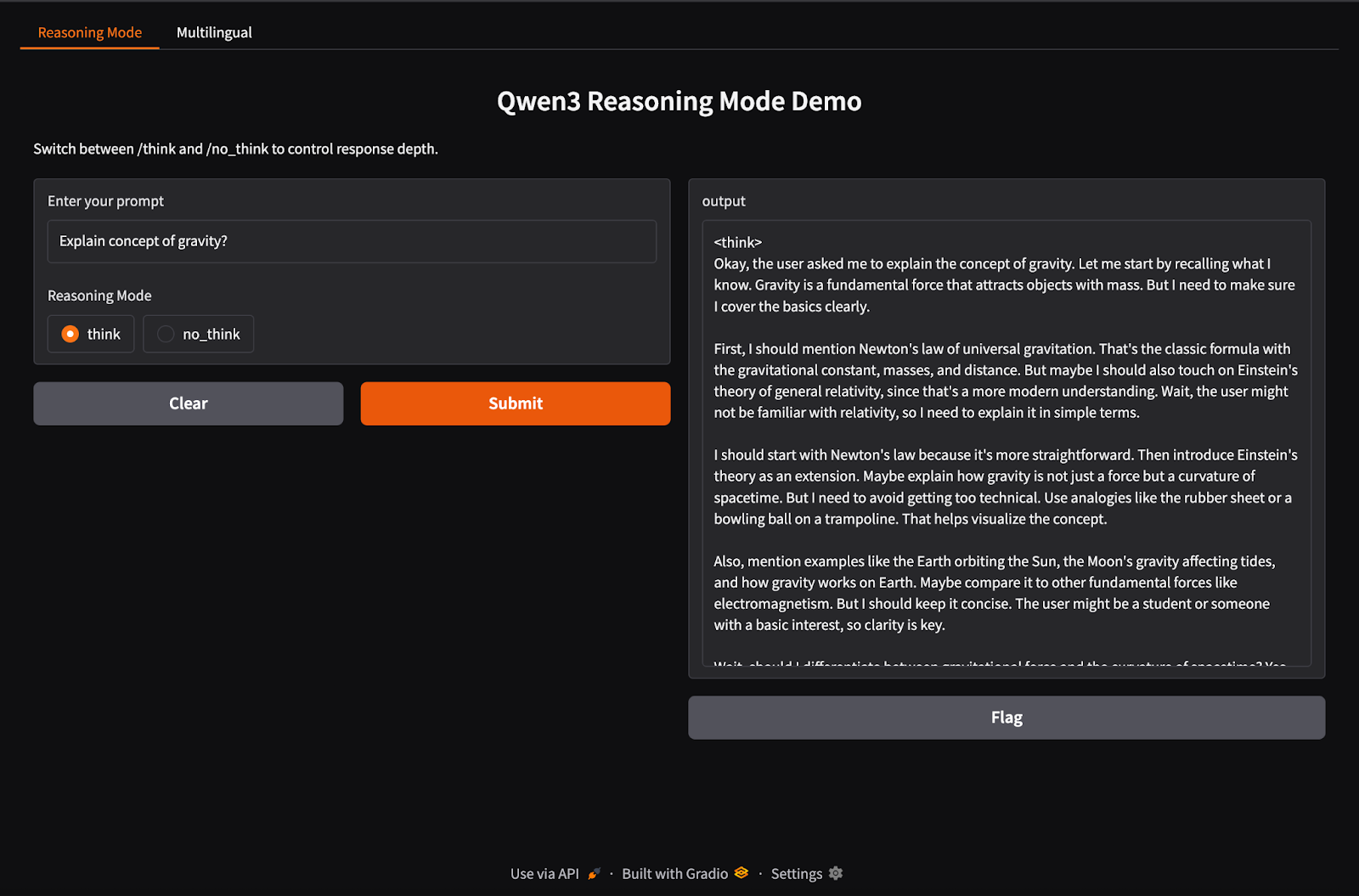
 Conclusion
ConclusionQwen3 brings advanced reasoning, fast decoding, and multilingual support to your local machine using Ollama.
With minimal setup, you can:
To learn more about Qwen3, I recommend:
Learn AI with these courses!
Track
Track
Course
Tutorial
Aashi Dutt
Tutorial
François Aubry
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan