
Leerpad
AI-toepassingen ontwikkelen
21 Hr
Qwen3 is Alibaba’s nieuwste generatie open-weight large language models. Met ondersteuning voor 100+ talen en sterke prestaties op het gebied van redeneren, coderen en vertalen, kan Qwen3 zich meten met veel toonaangevende modellen van dit moment, waaronder DeepSeek-R1, o3-mini en Gemini 2.5.
In deze tutorial leg ik stap voor stap uit hoe je Qwen3 lokaal draait met Ollama.
We bouwen ook een lokale, lichte toepassing met Qwen 3. De app laat je schakelen tussen de redeneermodi van Qwen3 en vertalen tussen verschillende talen.
We houden onze lezers op de hoogte van het laatste AI-nieuws via The Median, onze gratis vrijdagse nieuwsbrief die de belangrijkste verhalen van de week samenvat. Abonneer je en blijf scherp in slechts een paar minuten per week:
Qwen3 lokaal draaien biedt meerdere belangrijke voordelen:
Qwen3 is geoptimaliseerd voor zowel diep redeneren (thinking-modus) als snelle reacties (non-thinking-modus) en ondersteunt 100+ talen. Laten we het lokaal instellen.
Ollama is een tool waarmee je taalmodellen zoals Llama of Qwen lokaal op je computer kunt draaien via een eenvoudige command-line interface.
Download Ollama voor macOS, Windows of Linux via: https://ollama.com/download.
Volg de instructies van de installer en controleer na de installatie door dit in de terminal uit te voeren:
ollama --versionOllama biedt een groeiend aanbod aan Qwen3-modellen, geschikt voor uiteenlopende hardwareconfiguraties, van lichte laptops tot high-end servers.
ollama run qwen3Met het bovenstaande commando start je het standaard Qwen3-model in Ollama, dat momenteel standaard qwen3:8b is. Werk je met beperkte resources of wil je snellere opstarttijden, dan kun je expliciet kleinere varianten draaien, zoals het 4B-model:
ollama run qwen3:4bQwen3 is momenteel beschikbaar in meerdere varianten, van het kleinste 0.6b (523 MB) tot het grootste 235b (142 GB) parametrische model. Deze kleinere varianten leveren indrukwekkende prestaties voor redeneren, vertalen en codegeneratie, vooral in thinking-modus.
De MoE-modellen (30b-a3b, 235b-a22b) zijn extra interessant omdat ze per inferentiestap slechts een subset van experts activeren. Zo krijg je enorme totale parameter-aantallen terwijl de runtime-kosten efficiënt blijven.
Gebruik in het algemeen het grootste model dat je hardware aankan, en val terug op de 8B- of 4B-modellen voor responsieve lokale experimenten op consumentenhardware.
Hier is een korte samenvatting van alle Qwen3-modellen die je kunt runnen:
|
Model |
Ollama-commando |
Beste voor |
|
Qwen3-0.6B |
|
Lichte taken, mobiele apps en edge-apparaten |
|
Qwen3-1.7B |
|
Chatbots, assistenten en low-latency toepassingen |
|
Qwen3-4B |
|
Algemene taken met een goede balans tussen performance en resources |
|
Qwen3-8B |
|
Meertalige ondersteuning en gemiddelde redeneercapaciteiten |
|
Qwen3-14B |
|
Geavanceerd redeneren, contentcreatie en complexe probleemoplossing |
|
Qwen3-32B |
|
High-end taken die sterk redeneren en veel context vereisen |
|
Qwen3-30B-A3B (MoE) |
|
Efficiënte prestaties met 3B actieve parameters, geschikt voor codetaken |
|
Qwen3-235B-A22B (MoE) |
|
Toepassingen op grote schaal, diep redeneren en enterprise-oplossingen |
Om het model via een API aan te bieden, voer je dit commando uit in de terminal:
ollama serveHiermee wordt het model beschikbaar voor integratie met andere toepassingen op http://localhost:11434.
In deze sectie laat ik je verschillende manieren zien om Qwen3 lokaal te gebruiken, van basis-CLI-interactie tot integratie met Python.
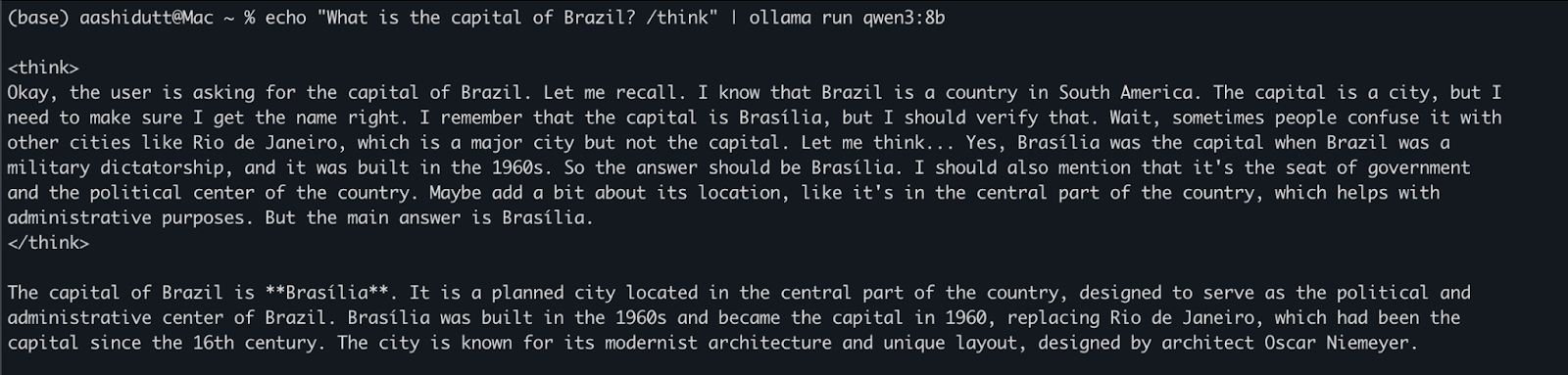
Zodra het model is gedownload, kun je rechtstreeks in de terminal met Qwen3 communiceren. Voer het volgende commando uit in je terminal:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bDit is handig voor snelle tests of lichte interactie zonder code te schrijven. De tag /think aan het einde van de prompt instrueert het model om dieper, stap-voor-stap te redeneren. Je kunt dit vervangen door /no_think voor een snellere, oppervlakkigere reactie, of het helemaal weglaten om de standaard redeneermodus van het model te gebruiken.
Zodra ollama serve op de achtergrond draait, kun je programmatisch met Qwen3 communiceren via een HTTP API — ideaal voor backend-integratie, automatisering of het testen van REST-clients.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Zo werkt het:
curl doet een POST-request (zo roepen we de API aan) naar de lokale Ollama-server op localhost:11434."model": specificeert het te gebruiken model (hier: qwen3:8b)."messages": een lijst met chatberichten met role en content."stream": false: zorgt dat het antwoord in één keer terugkomt, niet token-voor-token.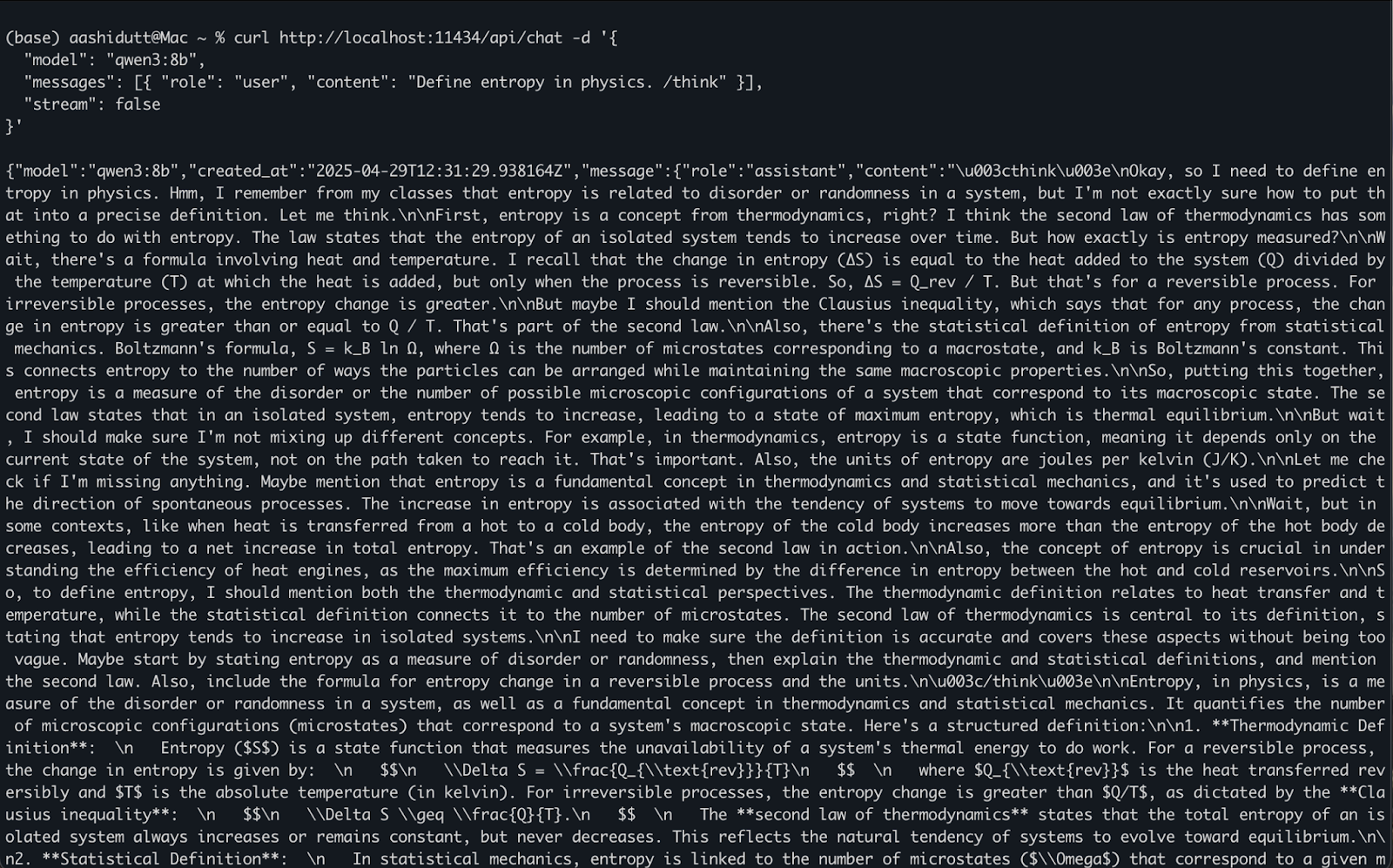
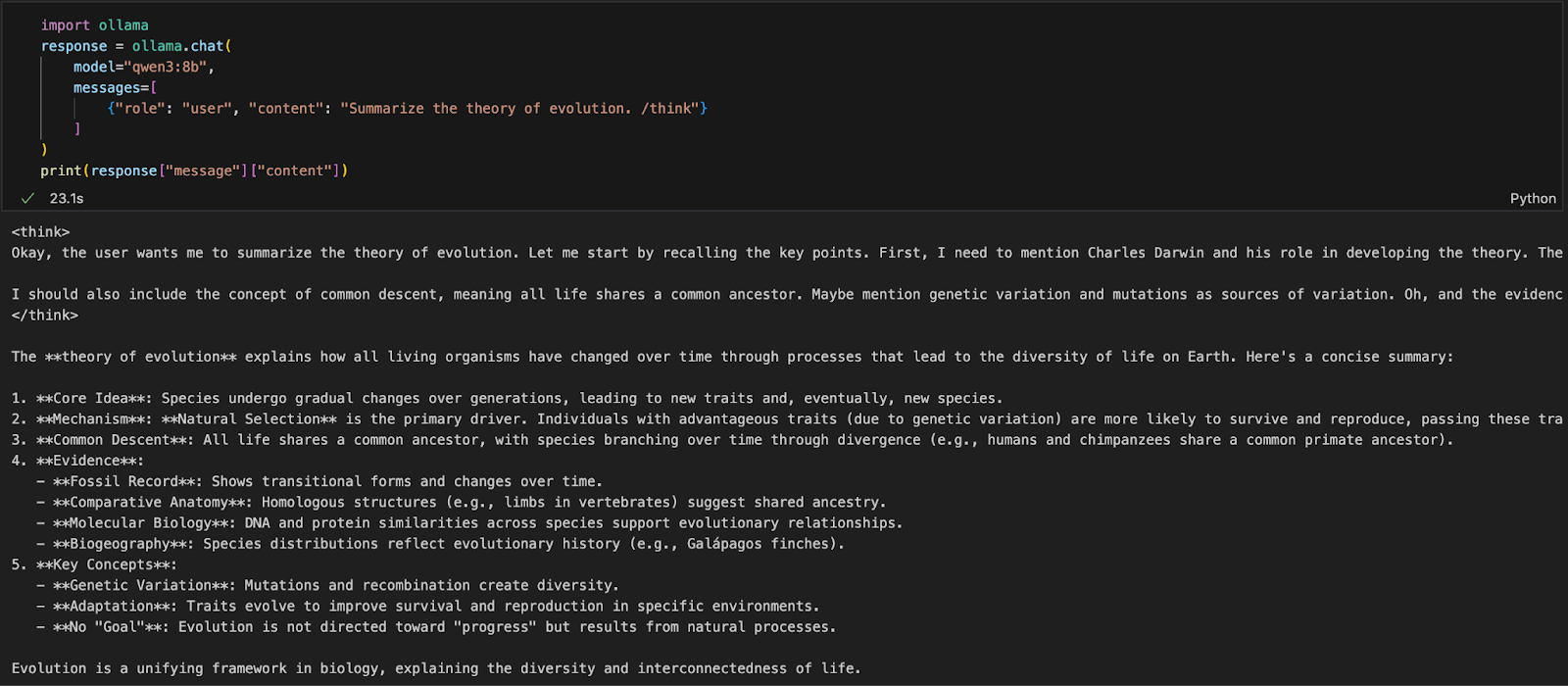
Werk je in een Python-omgeving (zoals Jupyter, VSCode of een script), dan is de makkelijkste manier om met Qwen3 te werken via de Ollama Python SDK. Installeer eerst ollama:
pip install ollamaDraai daarna je Qwen3-model met dit script (we gebruiken hieronder qwen3:8b):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])In de bovenstaande code:
ollama.chat(...) stuurt een chatverzoek naar de lokale Ollama-server.qwen3:8b) en een lijst met berichten in een formaat dat lijkt op de API van OpenAI./think vertelt het model om stap voor stap te redeneren.["message"]["content"].Deze aanpak is ideaal voor lokale experimenten, prototyping of het bouwen van LLM-apps zonder afhankelijk te zijn van cloud-API’s.
Qwen3 ondersteunt hybride inferentiegedrag met de tags /think (diep redeneren) en /no_think (snelle respons). In deze sectie gebruiken we Gradio om een interactieve lokale webapp te maken met twee tabbladen:
In deze stap bouwen we ons hybride reasoning-tabblad met de tags /think en /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)In de bovenstaande code:
reasoning_qwen3() neemt een gebruikersprompt en een redeneermodus ("think" of "no_think").subprocess.run() het commando ollama run qwen3:8b en voert de prompt aan via standard input.Zodra de functie die output genereert is gedefinieerd, verpakt gr.Interface() die in een interactieve web-UI door invoercomponenten te specificeren — een Textbox voor de prompt en een Radio-knop voor de redeneermodus — en die te koppelen aan de functie-invoer.
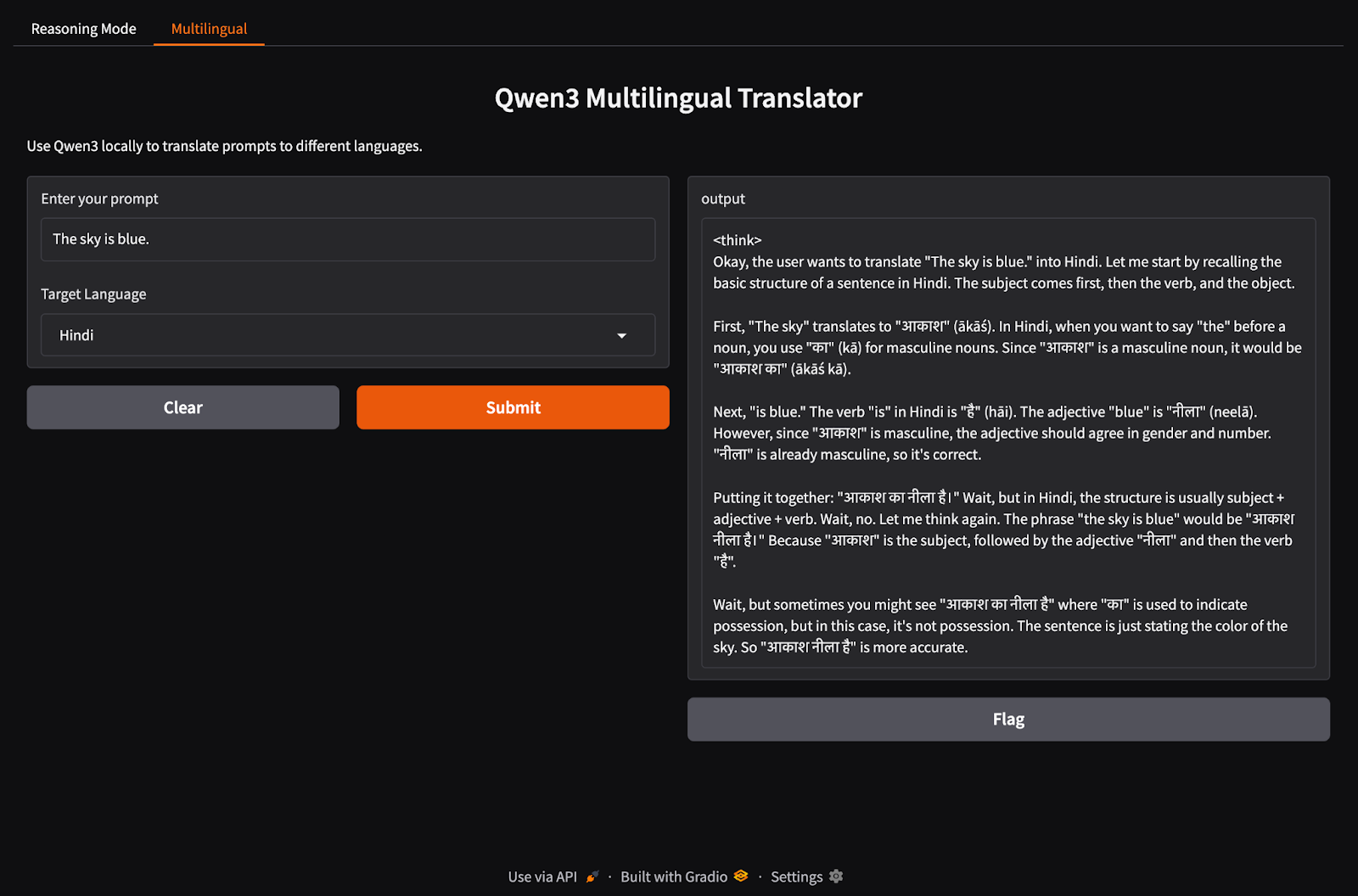
Laten we nu het meertalige tabblad van onze applicatie opzetten.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Net als in de vorige stap werkt deze code als volgt:
multilingual_qwen3() neemt een prompt en een doeltaal.Laten we beide tabbladen samenbrengen in een Gradio-applicatie.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Dit is wat we in de bovenstaande code doen:
gr.TabbedInterface() maakt een UI met twee tabbladen:demo.launch(debug=True) draait de app lokaal en opent deze in de browser met debugging ingeschakeld.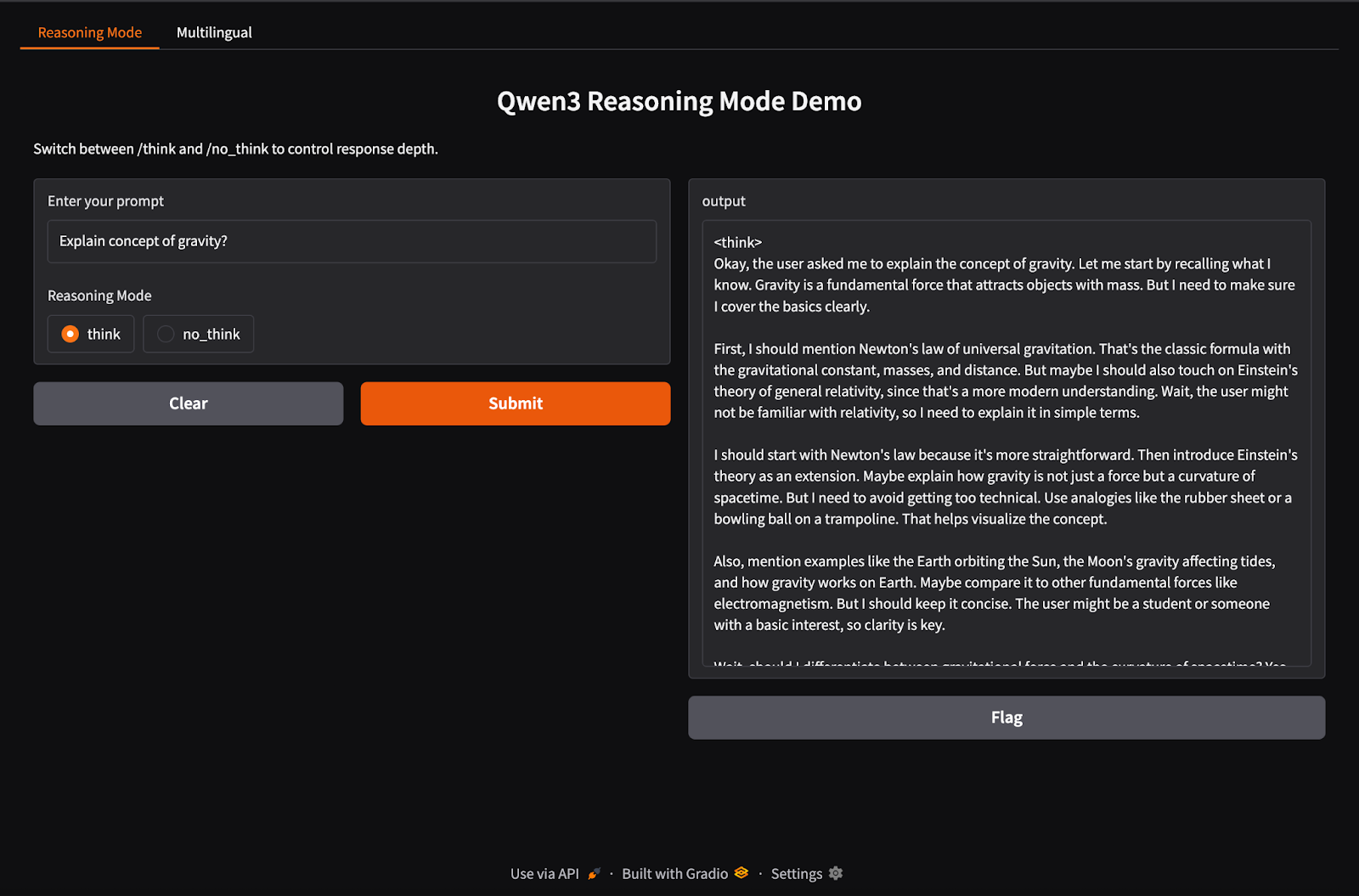
 Conclusie
ConclusieQwen3 brengt geavanceerd redeneren, snelle decodering en meertalige ondersteuning naar je lokale machine met Ollama.
Met minimale setup kun je:
Wil je meer weten over Qwen3, dan raad ik aan:
Leer AI met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
