
Program
Yapay Zeka Uygulamaları Geliştirme
21 sa
Qwen3, Alibaba’nın açık ağırlıklı büyük dil modellerinin en yeni neslidir. 100+ dil desteği ve akıl yürütme, kodlama ve çeviri görevlerinde güçlü performansıyla Qwen3, DeepSeek-R1, o3-mini ve Gemini 2.5 gibi günümüzdeki üst düzey pek çok modele rakip oluyor.
Bu eğitimde, adım adım Qwen3’ün yerelde nasıl çalıştırılacağını Ollama kullanarak anlatacağım.
Ayrıca Qwen3 ile yerel ve hafif bir uygulama da geliştireceğiz. Uygulama, Qwen3’ün akıl yürütme modları arasında geçiş yapmanıza ve farklı diller arasında çeviri yapmanıza olanak tanıyacak.
Okurlarımızı yapay zekâdaki en güncel gelişmelerden, haftanın önemli haberlerini özetleyen ücretsiz Cuma bültenimiz The Median ile haberdar ediyoruz. Abone olun, haftada sadece birkaç dakikada güncel kalın:
Qwen3’ü yerelde çalıştırmanın birkaç önemli avantajı vardır:
Qwen3, hem derin akıl yürütme (düşünme modu) hem de hızlı yanıtlar (düşünme dışı modu) için optimize edilmiştir ve 100+ dili destekler. Hadi yerelde kuralım.
Ollama, Llama veya Qwen gibi dil modellerini basit bir komut satırı arayüzüyle bilgisayarınızda yerelde çalıştırmanızı sağlayan bir araçtır.
macOS, Windows veya Linux için Ollama’yı şu adresten indirin: https://ollama.com/download.
Yükleyici yönergelerini izleyin ve kurulumdan sonra terminalde şunu çalıştırarak doğrulayın:
ollama --versionOllama, hafif dizüstülerden üst düzey sunuculara kadar çeşitli donanım yapılandırmalarına uygun, giderek artan sayıda Qwen3 modelini sunar.
ollama run qwen3Yukarıdaki komutu çalıştırmak, Ollama’da varsayılan Qwen3 modelini başlatır; bu da şu anda qwen3:8b’dir. Kısıtlı kaynaklarla çalışıyorsanız veya daha hızlı başlangıç istiyorsanız, 4B model gibi daha küçük varyantları açıkça çalıştırabilirsiniz:
ollama run qwen3:4bQwen3 hâlihazırda, en küçüğü 0.6b (523MB) ve en büyüğü 235b (142GB) parametreli modellerden başlayan çeşitli varyantlarda mevcuttur. Bu daha küçük varyantlar, özellikle düşünme modunda kullanıldığında, akıl yürütme, çeviri ve kod üretiminde etkileyici performans sunar.
MoE modelleri (30b-a3b, 235b-a22b) özellikle ilgi çekicidir; çünkü her çıkarım adımında yalnızca bir uzman alt kümesini etkinleştirirler; bu da toplam parametre sayısını çok yüksek tutarken çalışma zamanını verimli kılar.
Genel olarak, donanımınızın kaldırabildiği en büyük modeli kullanın; tüketici makinelerinde hızlı ve tepkisel yerel deneyler için 8B veya 4B modellere geri dönün.
İşte çalıştırabileceğiniz tüm Qwen3 modellerinin hızlı bir özeti:
|
Model |
Ollama Komutu |
En Uygun Olduğu Alan |
|
Qwen3-0.6B |
|
Hafif görevler, mobil uygulamalar ve uç cihazlar |
|
Qwen3-1.7B |
|
Sohbet botları, asistanlar ve düşük gecikmeli uygulamalar |
|
Qwen3-4B |
|
Dengeli performans ve kaynak kullanımıyla genel amaçlı görevler |
|
Qwen3-8B |
|
Çok dilli destek ve orta düzey akıl yürütme yetenekleri |
|
Qwen3-14B |
|
Gelişmiş akıl yürütme, içerik üretimi ve karmaşık problem çözme |
|
Qwen3-32B |
|
Güçlü akıl yürütme ve kapsamlı bağlam işleme gerektiren üst düzey görevler |
|
Qwen3-30B-A3B (MoE) |
|
3B etkin parametreyle verimli performans; kodlama görevlerine uygun |
|
Qwen3-235B-A22B (MoE) |
|
Çok büyük ölçekli uygulamalar, derin akıl yürütme ve kurumsal çözümler |
Modeli API üzerinden sunmak için terminalde şu komutu çalıştırın:
ollama serveBu, modeli diğer uygulamalarla entegrasyon için şu adreste kullanılabilir hâle getirir: http://localhost:11434.
Bu bölümde, Qwen3’ü yerelde kullanmanın birkaç yolunu; temel CLI etkileşiminden Python ile entegrasyona kadar anlatacağım.
Model indirildikten sonra Qwen3 ile doğrudan terminalde etkileşime girebilirsiniz. Terminalinizde şu komutu çalıştırın:
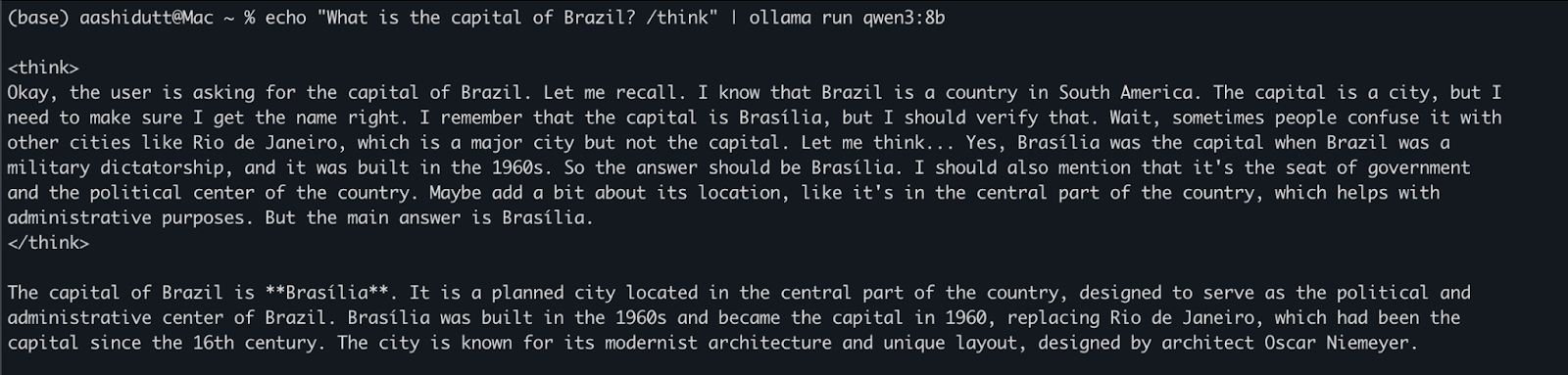
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bBu yöntem, herhangi bir kod yazmadan hızlı testler veya hafif etkileşimler için kullanışlıdır. İstem sonundaki /think etiketi, modelin daha derin, adım adım akıl yürütme yapmasını ister. Daha hızlı ve yüzeysel bir yanıt için bunu /no_think ile değiştirebilir veya modelin varsayılan akıl yürütme modunu kullanmak için tamamen kaldırabilirsiniz.
ollama serve arka planda çalışırken, Qwen3 ile bir HTTP API üzerinden programatik olarak etkileşime girebilirsiniz; bu da arka uç entegrasyonu, otomasyon veya REST istemcilerini test etmek için idealdir.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Nasıl çalıştığı şöyle:
curl, yerel olarak localhost:11434’te çalışan Ollama sunucusuna bir POST isteği yapar (API’yi böyle çağırıyoruz)."model": Kullanılacak modeli belirtir (burada: qwen3:8b)."messages": role ve content içeren sohbet mesajlarının listesi."stream": false: Yanıtın token token değil, tek seferde döndürülmesini sağlar.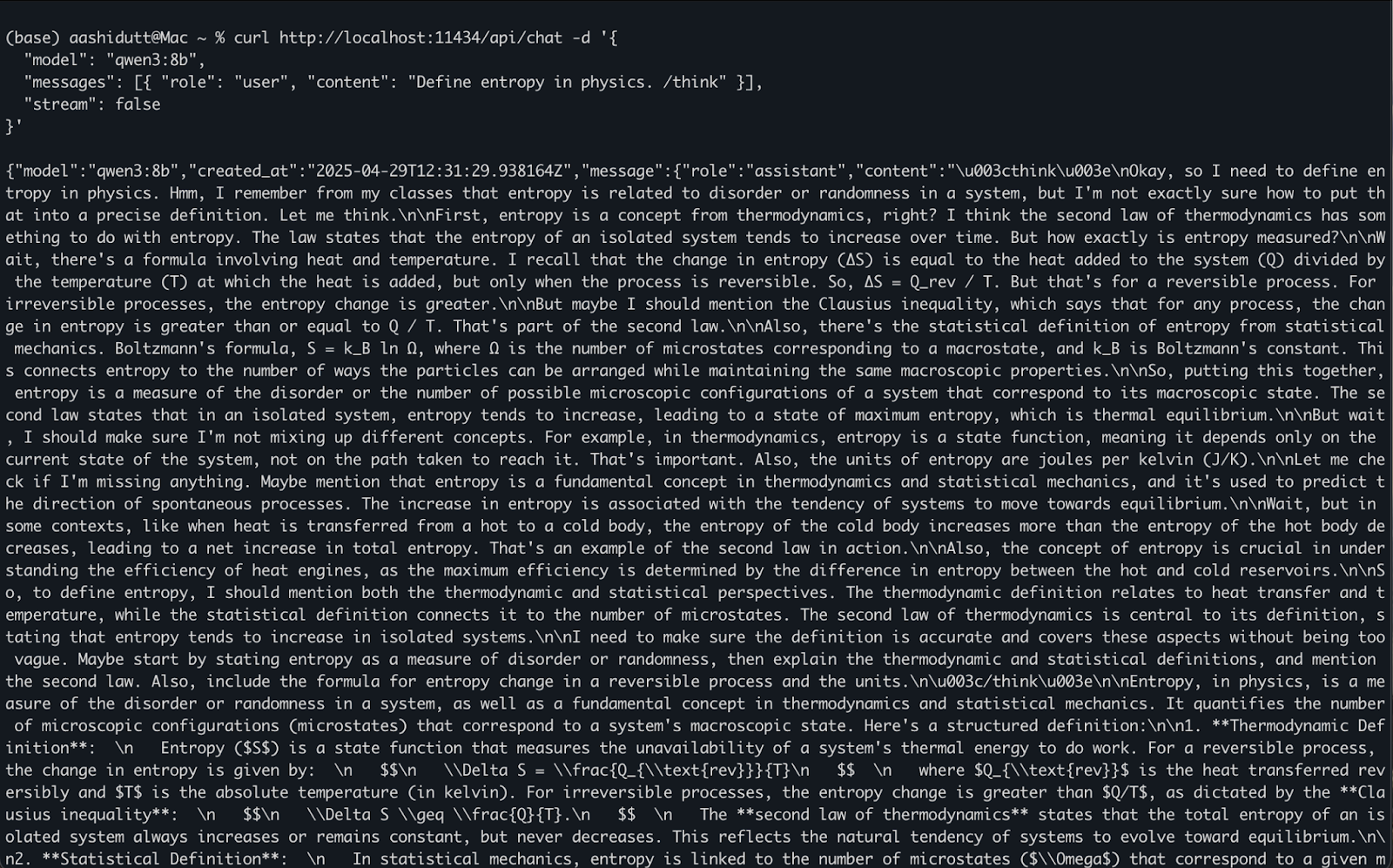
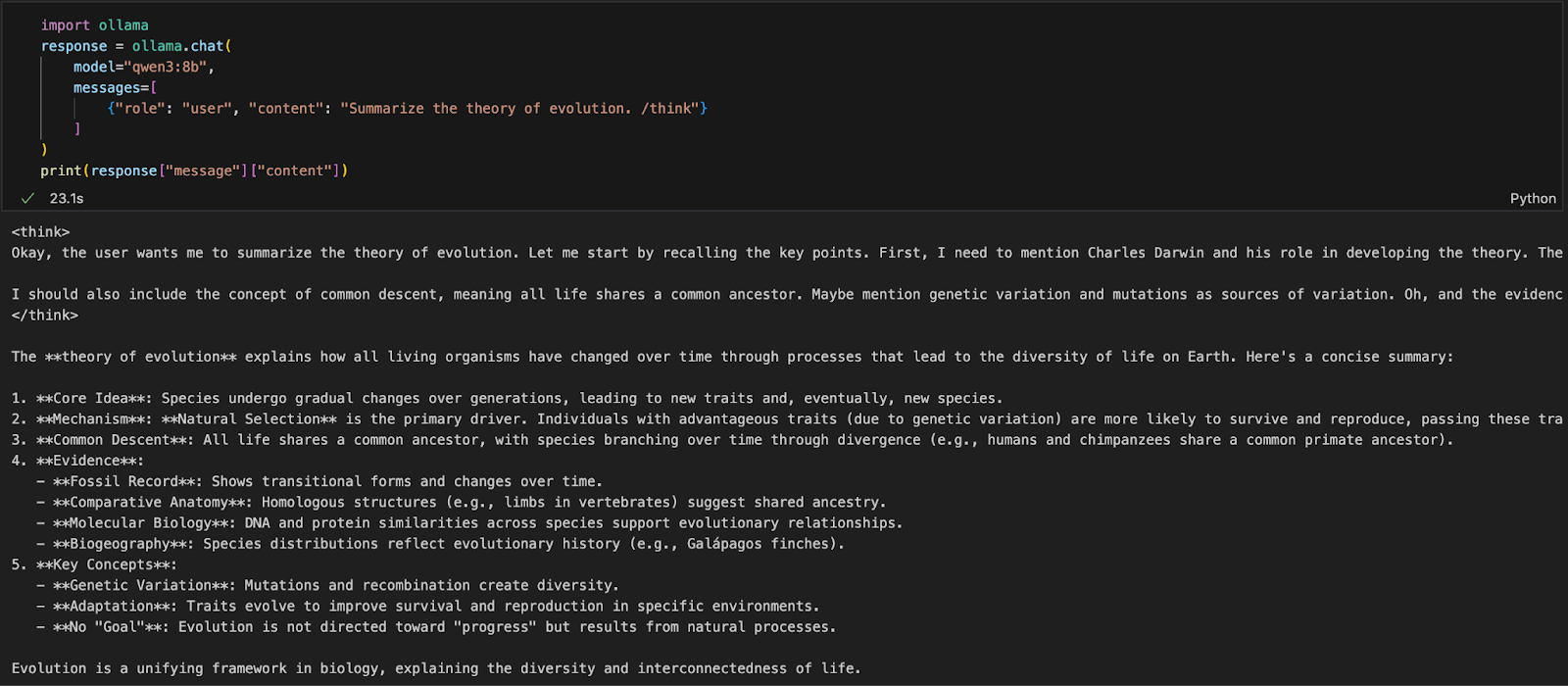
Python ortamında (Jupyter, VSCode veya bir betik) çalışıyorsanız, Qwen3 ile etkileşime geçmenin en kolay yolu Ollama Python SDK’dır. Önce ollama’yı yükleyin:
pip install ollamaArdından, Qwen3 modelinizi şu betikle çalıştırın (aşağıda qwen3:8b kullanıyoruz):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Yukarıdaki kodda:
ollama.chat(...), yerel Ollama sunucusuna sohbet tarzı bir istek gönderir.qwen3:8b) ve OpenAI’nin API’sine benzer bir biçimde mesaj listesini belirtirsiniz./think etiketi, modelin adım adım akıl yürütmesini ister.["message"]["content"] ile erişebilirsiniz.Bu yaklaşım, bulut API’lerine bağlı kalmadan yerel deneyler, prototipleme veya LLM destekli uygulamalar geliştirmek için idealdir.
Qwen3, /think (derin akıl yürütme) ve /no_think (hızlı yanıt) etiketlerini kullanarak hibrit çıkarım davranışını destekler. Bu bölümde, iki ayrı sekmeye sahip etkileşimli bir yerel web uygulamasını Gradio ile oluşturacağız:
Bu adımda, /think ve /no_think etiketleriyle hibrit akıl yürütme sekmemizi oluşturuyoruz.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Yukarıdaki kodda:
reasoning_qwen3() işlevi bir kullanıcı istemi ve bir akıl yürütme modu ("think" veya "no_think") alır.subprocess.run() yöntemi ollama run qwen3:8b komutunu çalıştırır ve istemi standart girdi olarak besler.Çıktı üreten işlev tanımlandıktan sonra, gr.Interface() işlevi bunu etkileşimli bir web arayüzüne sarar; bir Textbox (istem için) ve akıl yürütme modunu seçmek için bir Radio düğmesi gibi giriş bileşenleri belirterek bunları işlevin girdilerine eşler.
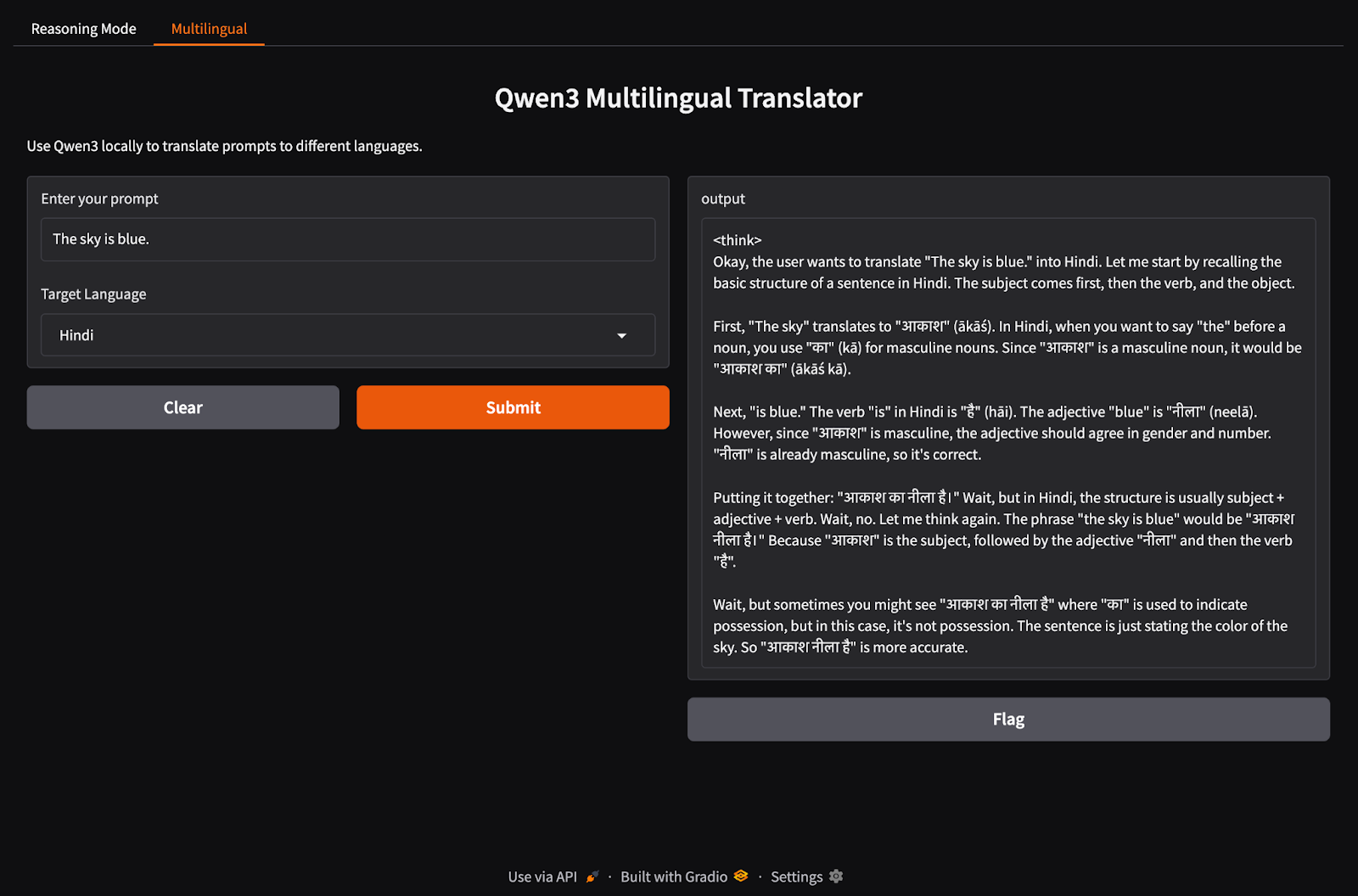
Şimdi çok dilli uygulama sekmemizi kuralım.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Önceki adıma benzer şekilde, bu kod şu şekilde çalışır:
multilingual_qwen3() işlevi bir istem ve hedef dil alır.Her iki sekmeyi de bir Gradio uygulamasında bir araya getirelim.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Yukarıdaki kodda yaptıklarımız:
gr.TabbedInterface() iki sekmeli bir arayüz oluşturur:demo.launch(debug=True) işlevi uygulamayı yerelde çalıştırır ve hata ayıklama etkinleştirilmiş olarak tarayıcıda açar.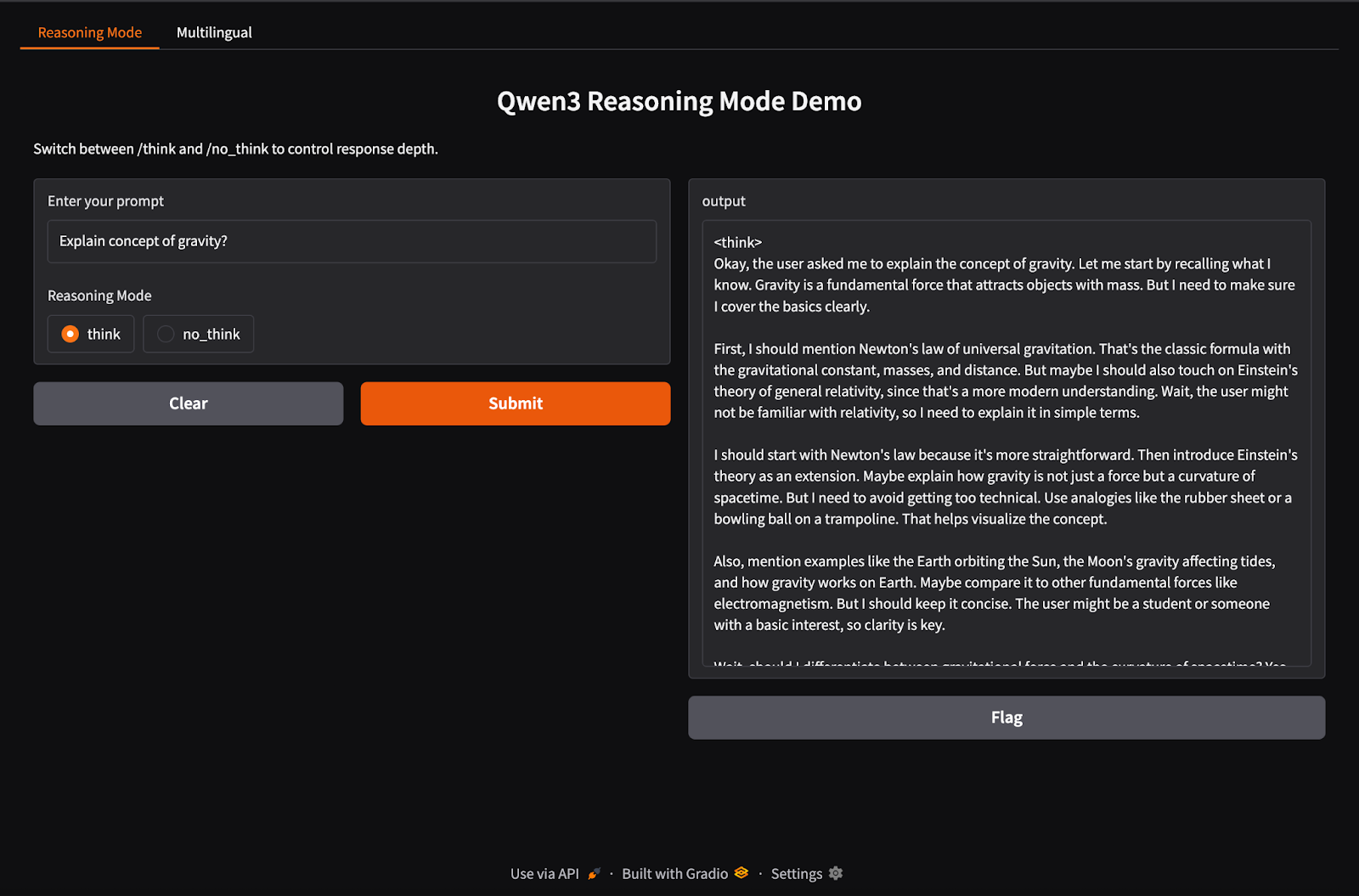
 Sonuç
SonuçQwen3, Ollama kullanarak gelişmiş akıl yürütmeyi, hızlı kod çözmeyi ve çok dilli desteği yerel makinenize getirir.
Minimum kurulumla şunları yapabilirsiniz:
Qwen3 hakkında daha fazla bilgi edinmek için şunları öneririm:
Bu kurslarla yapay zekâ öğrenin!
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
