
programa
Desarrollo de aplicaciones de IA
21 h
Qwen3 es la última generación de Alibaba de grandes modelos lingüísticos de peso abierto. Con soporte para más de 100 idiomas y un gran rendimiento en tareas de razonamiento, codificación y traducción, Qwen3 rivaliza con muchos modelos de primer nivel disponibles en la actualidad, como DeepSeek-R1, o3-mini y Gemini 2.5.
En este tutorial, te explicaré paso a paso cómo ejecutar Qwen3 localmente utilizando Ollama.
También construiremos una aplicación local ligera con Qwen 3. La aplicación te permitirá cambiar entre los modos de razonamiento de Qwen3 y traducir entre diferentes idiomas.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Ejecutar Qwen3 localmente proporciona varias ventajas clave:
Qwen3 está optimizado tanto para el razonamiento profundo (modo pensante) como para las respuestas rápidas (modo no pensante), y es compatible con más de 100 idiomas. Vamos a configurarlo localmente.
Ollama es una herramienta que te permite ejecutar modelos lingüísticos como Llama o Qwen localmente en tu ordenador con una sencilla interfaz de línea de comandos.
Descarga Ollama para macOS, Windows o Linux desde: https://ollama.com/download.
Sigue las instrucciones del instalador y, tras la instalación, compruébalo ejecutando esto en el terminal:
ollama --versionOllama ofrece una gama creciente de modelos Qwen3 diseñados para adaptarse a diversas configuraciones de hardware, desde portátiles ligeros hasta servidores de gama alta.
ollama run qwen3Al ejecutar el comando anterior se iniciará el modelo Qwen3 por defecto en Ollama, que actualmente es qwen3:8b. Si trabajas con recursos limitados o quieres tiempos de arranque más rápidos, puedes ejecutar explícitamente variantes más pequeñas como el modelo 4B:
ollama run qwen3:4bQwen3 está disponible actualmente en varias variantes, empezando por el modelo más pequeño de 0,6b(523MB) hasta el más grande de 235b(142GB) de parámetros. Estas variantes más pequeñas ofrecen un rendimiento impresionante para el razonamiento, la traducción y la generación de código, especialmente cuando se utilizan en modo de pensamiento.
Los modelos MoE (30b-a3b, 235b-a22b) son especialmente interesantes, ya que sólo activan un subconjunto de expertos por paso de inferencia, lo que permite un recuento total masivo de parámetros, manteniendo unos costes de ejecución eficientes.
En general, utiliza el modelo más grande que pueda soportar tu hardware, y recurre a los modelos de 8B o 4B para experimentos locales de respuesta en máquinas de consumo.
Aquí tienes un resumen rápido de todos los modelos de Qwen3 que puedes ejecutar:
|
Modelo |
Ollama Command |
Lo mejor para |
|
Qwen3-0,6B |
|
Tareas ligeras, aplicaciones móviles y dispositivos de borde |
|
Qwen3-1.7B |
|
Chatbots, asistentes y aplicaciones de baja latencia |
|
Qwen3-4B |
|
Tareas de uso general con rendimiento y uso de recursos equilibrados |
|
Qwen3-8B |
|
Soporte multilingüe y capacidad de razonamiento moderado |
|
Qwen3-14B |
|
Razonamiento avanzado, creación de contenidos y resolución de problemas complejos |
|
Qwen3-32B |
|
Tareas de alto nivel que requieren un razonamiento sólido y un amplio manejo del contexto |
|
Qwen3-30B-A3B (MoE) |
|
Rendimiento eficiente con 3B parámetros activos, adecuado para tareas de codificación |
|
Qwen3-235B-A22B (MoE) |
|
Aplicaciones a gran escala, razonamiento profundo y soluciones a nivel empresarial |
Para servir el modelo a través de la API, ejecuta este comando en el terminal:
ollama serveEsto hará que el modelo esté disponible para su integración con otras aplicaciones en http://localhost:11434.
En esta sección, te guiaré a través de varias formas de utilizar Qwen3 localmente, desde la interacción básica con la CLI hasta la integración del modelo con Python.
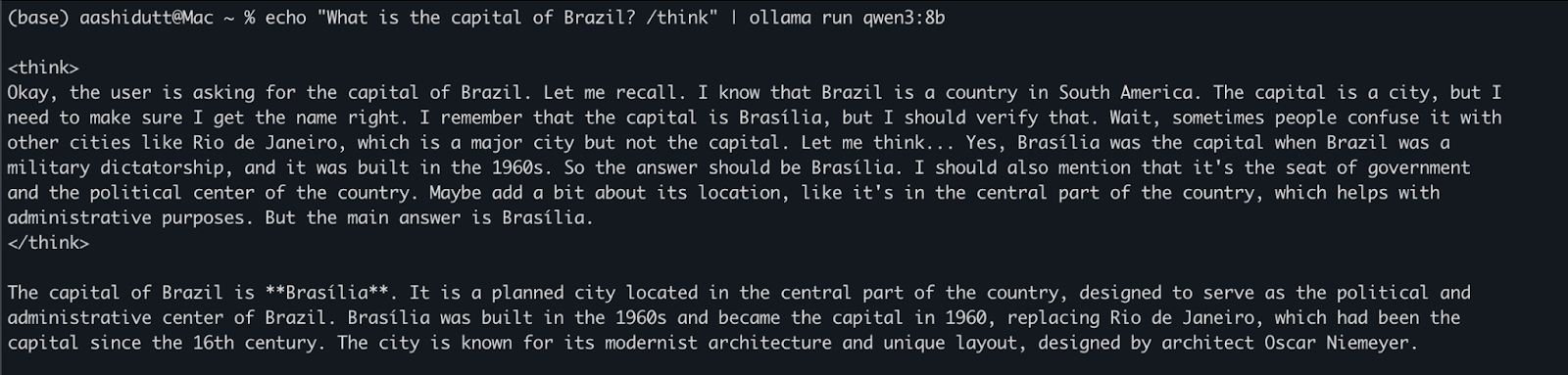
Una vez descargado el modelo, puedes interactuar con Qwen3 directamente en el terminal. Ejecuta el siguiente comando en tu terminal:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bEsto es útil para realizar pruebas rápidas o interacciones ligeras sin escribir código. La etiqueta /think al final de la indicación indica al modelo que realice un razonamiento más profundo, paso a paso. Puedes sustituirlo por /no_think para obtener una respuesta más rápida y superficial u omitirlo por completo para utilizar el modo de razonamiento por defecto del modelo.
Una vez que ollama serve se está ejecutando en segundo plano, puedes interactuar con Qwen3 mediante programación utilizando una API HTTP, que es perfecta para la integración backend, la automatización o la prueba de clientes REST.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Así es como funciona:
curl realiza una petición POST (como llamamos a la API) al servidor local de Ollama que se ejecuta en localhost:11434."model": Especifica el modelo a utilizar (aquí es: qwen3:8b)."messages": Una lista de mensajes de chat que contienen role y content."stream": false: Garantiza que la respuesta se devuelva toda a la vez, no ficha a ficha.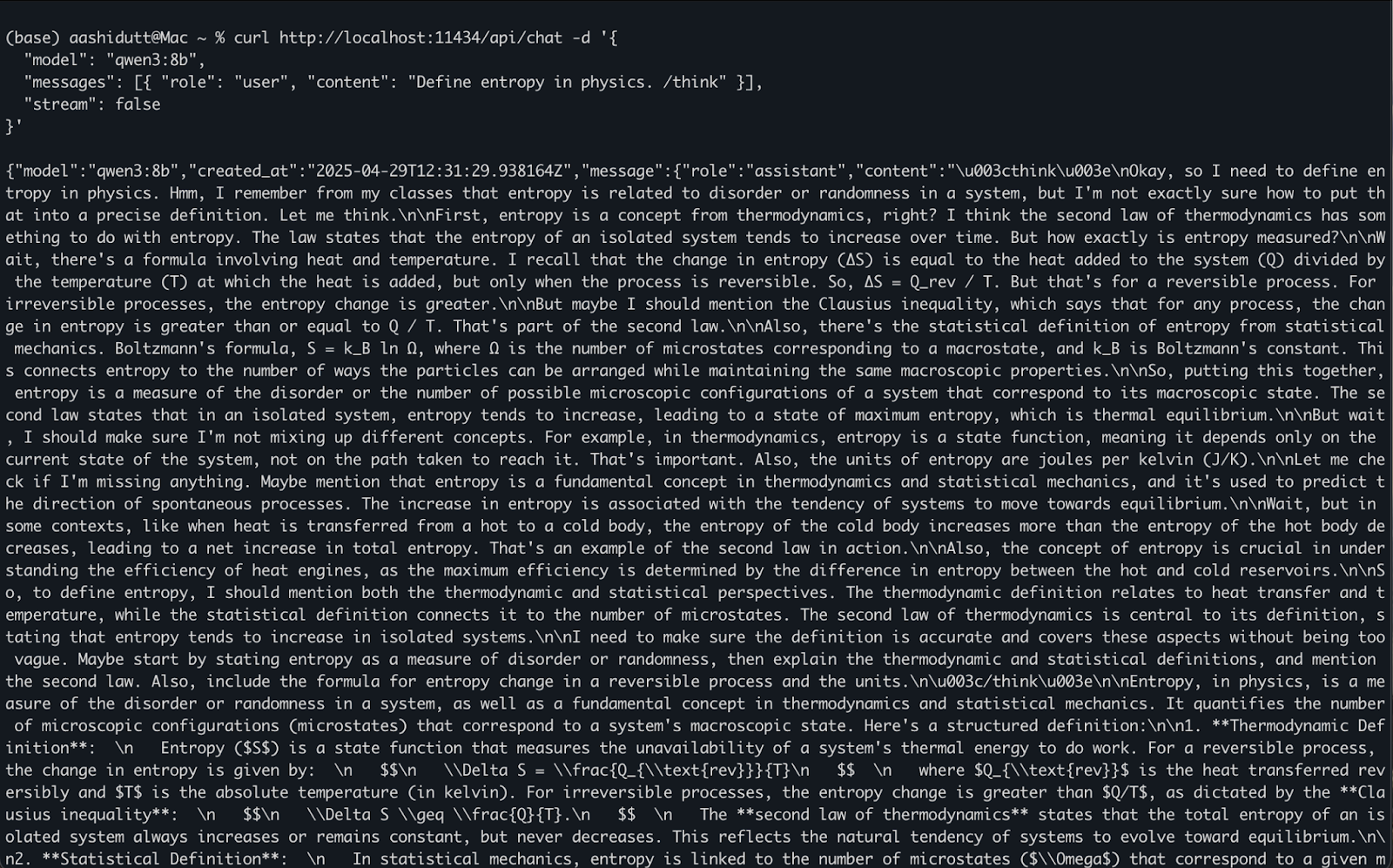
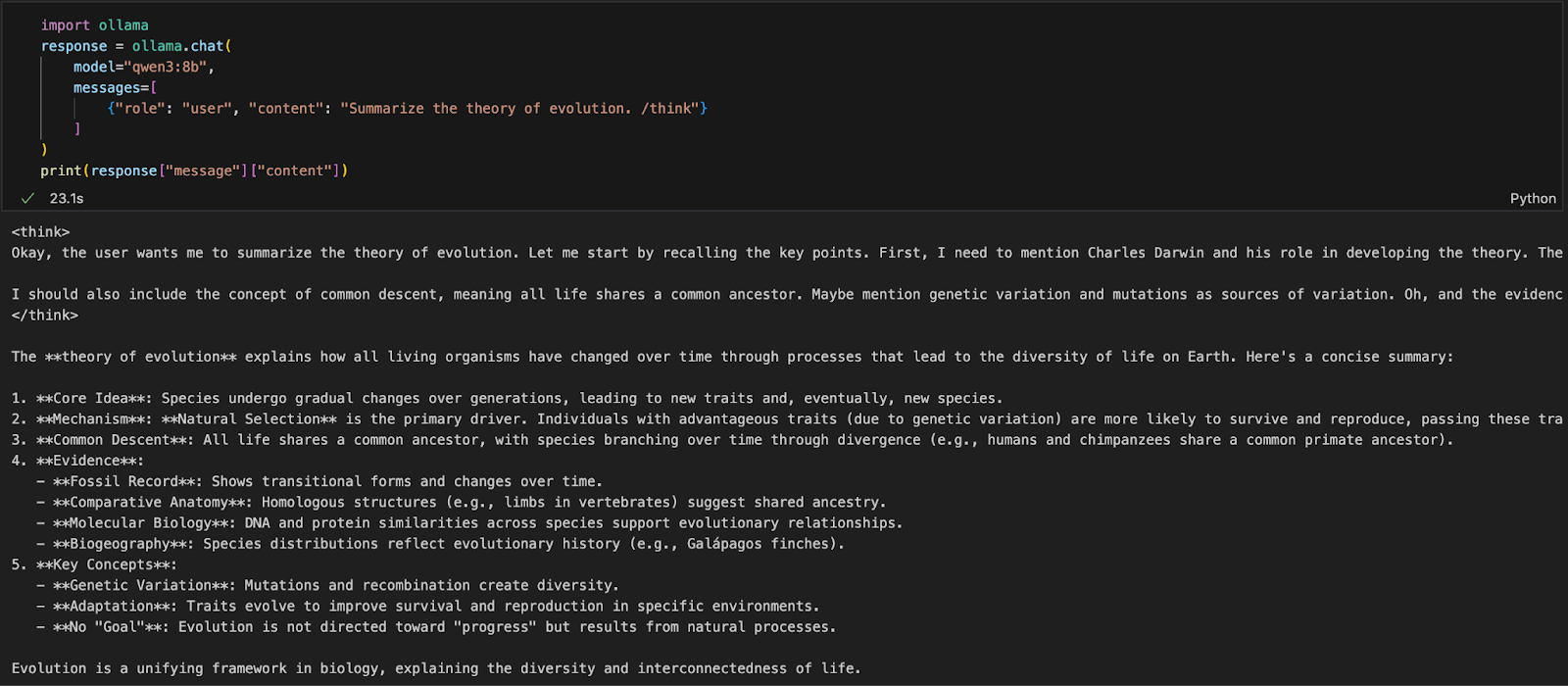
Si estás trabajando en un entorno Python (como Jupyter, VSCode o un script), la forma más sencilla de interactuar con Qwen3 es a través del SDK Python de Ollama. Empieza instalando ollama:
pip install ollamaA continuación, ejecuta tu modelo Qwen3 con este script (a continuación utilizaremos qwen3:8b ):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])En el código anterior:
ollama.chat(...) envía una petición tipo chat al servidor local de Ollama.qwen3:8b) y una lista de mensajes en un formato similar a la API de OpenAI./think indica al modelo que razone paso a paso.["message"]["content"].Este enfoque es ideal para la experimentación local, la creación de prototipos o la construcción de aplicaciones respaldadas por LLM sin depender de las API de la nube.
Qwen3 admite un comportamiento de inferencia híbrido que utiliza las etiquetas /think (razonamiento profundo) y /no_think (respuesta rápida). En esta sección, utilizaremos Gradio para crear una aplicación web local interactiva con dos pestañas separadas:
En este paso, construimos nuestra ficha de razonamiento híbrido con las etiquetas /think y /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)En el código anterior:
reasoning_qwen3() toma un indicador de usuario y un modo de razonamiento ("think" o "no_think").subprocess.run() ejecuta el comando ollama run qwen3:8b, alimentando el prompt como entrada estándar.Una vez definida la función generadora de resultados, la función gr.Interface() la envuelve en una interfaz de usuario web interactiva especificando los componentes de entrada -un Textbox para el aviso y un botón Radio para seleccionar el modo de razonamiento- y asignándolos a las entradas de la función.
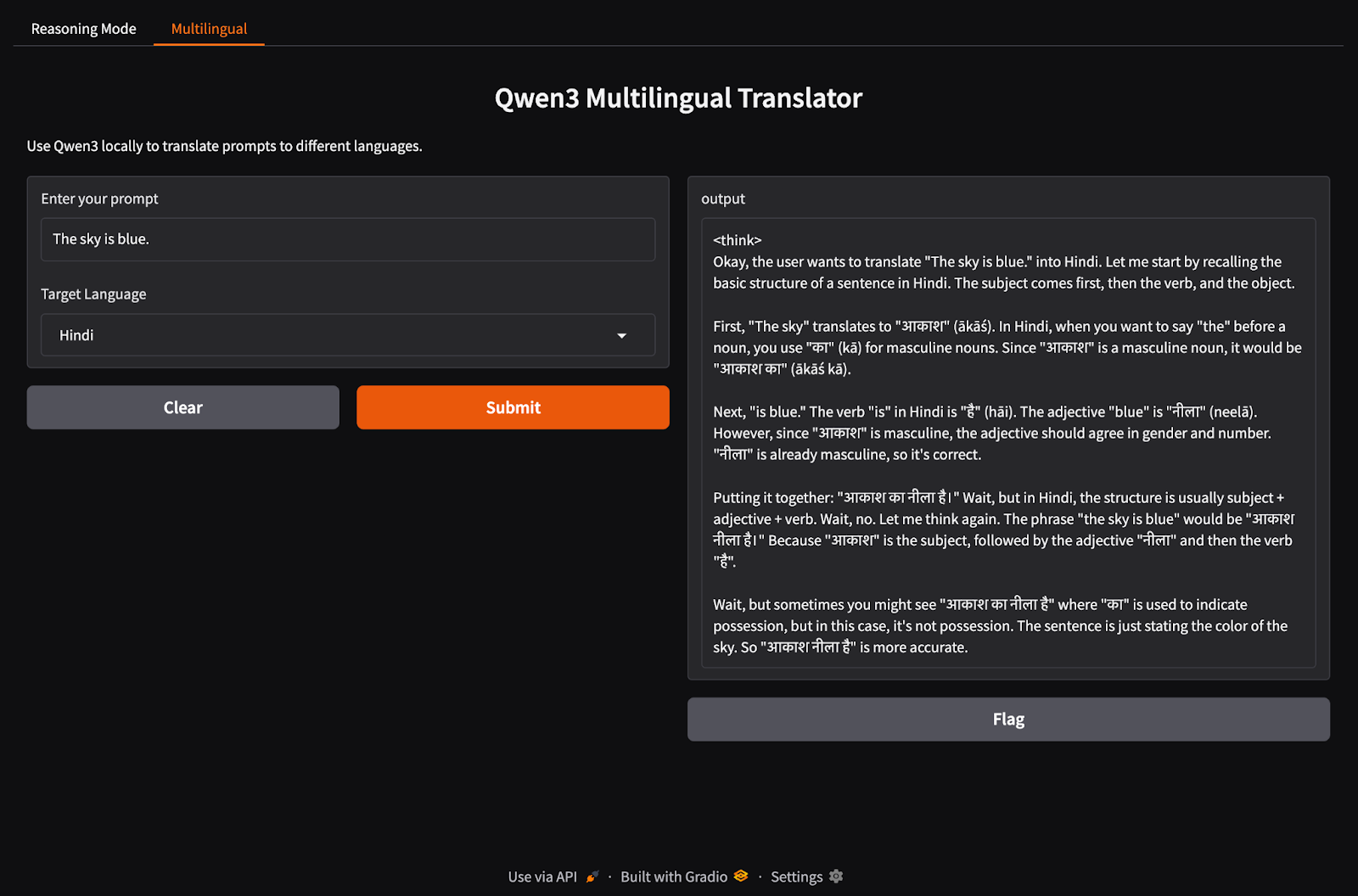
Ahora, vamos a configurar nuestra pestaña de aplicación multilingüe.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)De forma similar al paso anterior, este código funciona como sigue:
multilingual_qwen3() toma una indicación y una lengua de llegada.Unamos ambas pestañas en una aplicación Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Esto es lo que hacemos en el código anterior:
gr.TabbedInterface() crea una interfaz de usuario con dos pestañas:demo.launch(debug=True) ejecuta la aplicación localmente y la abre en el navegador con la depuración activada.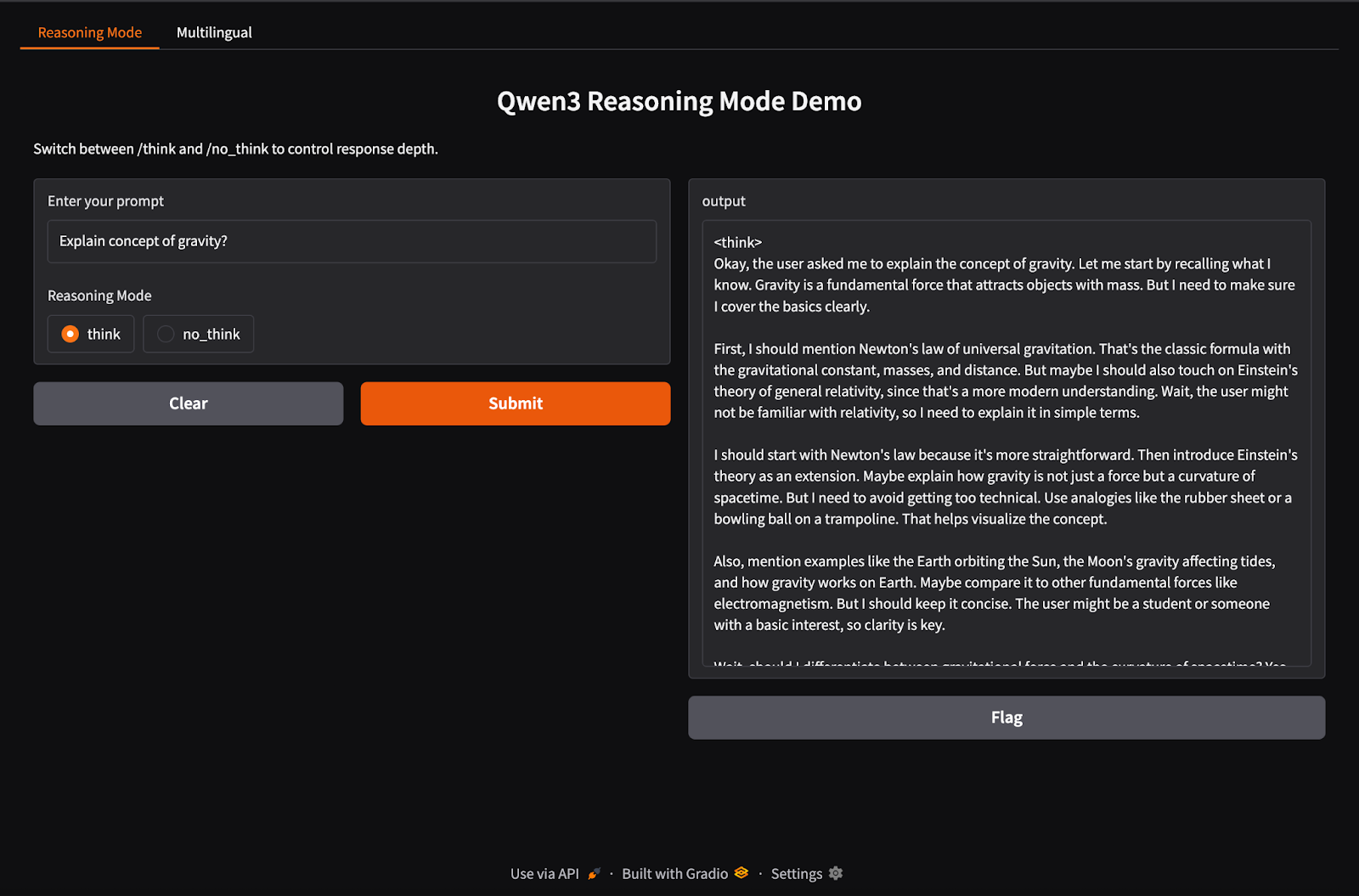
 Conclusión
ConclusiónQwen3 aporta razonamiento avanzado, descodificación rápida y soporte multilingüe a tu máquina local utilizando Ollama.
Con una configuración mínima, puedes
Si quieres una visión general de las capacidades de Qwen3, te recomiendo que leas este blog introductorio sobre Qwen3.
Aprende IA con estos cursos
programa
programa
Curso
Tutorial
Ryan Ong
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Moez Ali


