
Programa
Desenvolvimento de aplicativos de IA
21 h
O Qwen3 é a última geração de modelos de linguagem de grande porte de peso aberto da Alibaba. Com suporte para mais de 100 idiomas e excelente desempenho em tarefas de raciocínio, codificação e tradução, o Qwen3 rivaliza com muitos modelos de primeira linha disponíveis atualmente, incluindo DeepSeek-R1, o3-mini e Gemini 2.5.
Neste tutorial, explicarei passo a passo como executar o Qwen3 localmente usando o Ollama.
Também criaremos um aplicativo local leve com o Qwen 3. O aplicativo permitirá que você alterne entre os modos de raciocínio do Qwen3 e traduza entre diferentes idiomas.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
A execução do Qwen3 localmente oferece vários benefícios importantes:
O Qwen3 é otimizado para raciocínio profundo (modo de raciocínio) e respostas rápidas (modo de não raciocínio), e suporta mais de 100 idiomas. Vamos configurá-lo localmente.
O Ollama é uma ferramenta que permite que você execute modelos de linguagem como o Llama ou o Qwen localmente em seu computador com uma interface de linha de comando simples.
Faça o download do Ollama para macOS, Windows ou Linux em: https://ollama.com/download.
Siga as instruções do instalador e, após a instalação, verifique executando isso no terminal:
ollama --versionA Ollama oferece uma gama crescente de modelos Qwen3 projetados para atender a uma variedade de configurações de hardware, desde laptops leves até servidores de ponta.
ollama run qwen3A execução do comando acima iniciará o modelo padrão do Qwen3 no Ollama, que atualmente tem como padrão o endereço qwen3:8b. Se você estiver trabalhando com recursos limitados ou quiser tempos de inicialização mais rápidos, poderá executar explicitamente variantes menores, como o modelo 4B:
ollama run qwen3:4bAtualmente, o Qwen3 está disponível em diversas variantes, desde o menor modelo de parâmetros de 0,6 b (523 MB) até o maior de 235 b (142 GB). Essas variantes menores oferecem um desempenho impressionante para raciocínio, tradução e geração de código, especialmente quando usadas no modo de raciocínio.
Os modelos MoE (30b-a3b, 235b-a22b) são particularmente interessantes, pois ativam apenas um subconjunto de especialistas por etapa de inferência, o que permite uma contagem maciça de parâmetros totais e, ao mesmo tempo, mantém os custos de tempo de execução eficientes.
Em geral, use o maior modelo que seu hardware puder suportar e volte para os modelos 8B ou 4B para experimentos locais responsivos em máquinas de consumo.
Aqui está uma rápida recapitulação de todos os modelos Qwen3 que você pode executar:
|
Modelo |
Comando Ollama |
Melhor para |
|
Qwen3-0.6B |
|
Tarefas leves, aplicativos móveis e dispositivos de borda |
|
Qwen3-1.7B |
|
Chatbots, assistentes e aplicativos de baixa latência |
|
Qwen3-4B |
|
Tarefas de uso geral com desempenho e uso de recursos equilibrados |
|
Qwen3-8B |
|
Suporte multilíngue e recursos de raciocínio moderados |
|
Qwen3-14B |
|
Raciocínio avançado, criação de conteúdo e solução de problemas complexos |
|
Qwen3-32B |
|
Tarefas de alto nível que requerem raciocínio sólido e manipulação extensiva do contexto |
|
Qwen3-30B-A3B (MoE) |
|
Desempenho eficiente com parâmetros ativos 3B, adequado para tarefas de codificação |
|
Qwen3-235B-A22B (MoE) |
|
Aplicativos em grande escala, raciocínio profundo e soluções de nível empresarial |
Para servir o modelo via API, execute este comando no terminal:
ollama serveIsso tornará o modelo disponível para integração com outros aplicativos em http://localhost:11434.
Nesta seção, mostrarei várias maneiras de usar o Qwen3 localmente, desde a interação básica com a CLI até a integração do modelo com o Python.
Depois que o modelo for baixado, você poderá interagir com o Qwen3 diretamente no terminal. Execute o seguinte comando em seu terminal:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bIsso é útil para testes rápidos ou interação leve sem que você precise escrever nenhum código. A tag /think no final do prompt instrui o modelo a se envolver em um raciocínio mais profundo, passo a passo. Você pode substituí-lo por /no_think para obter uma resposta mais rápida e superficial ou omiti-lo totalmente para usar o modo de raciocínio padrão do modelo.
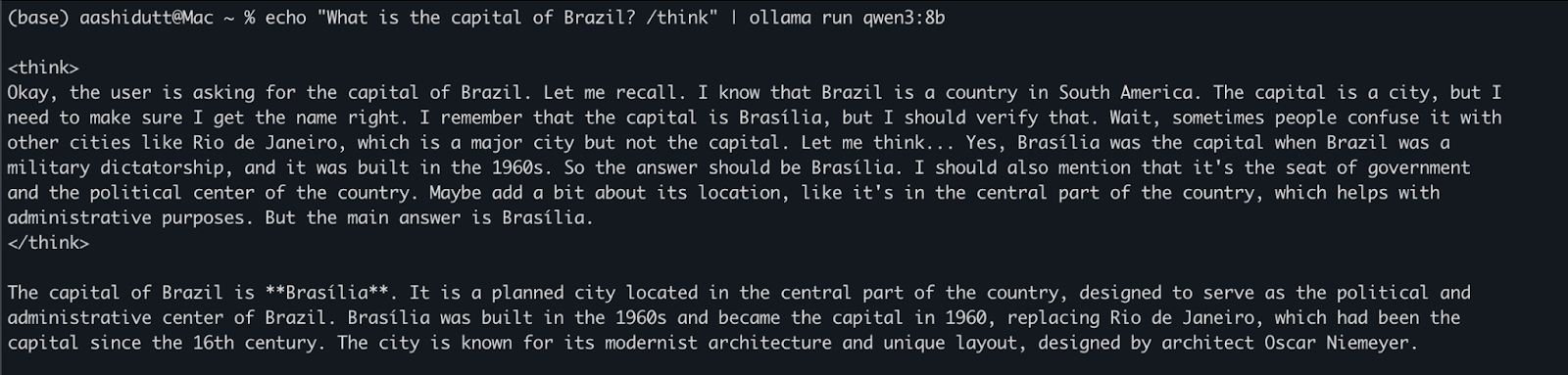
Quando o ollama serve estiver em execução em segundo plano, você poderá interagir com o Qwen3 programaticamente usando uma API HTTP, o que é perfeito para integração de back-end, automação ou teste de clientes REST.
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Veja como isso funciona:
curl Você faz uma solicitação POST (como chamamos a API) para o servidor Ollama local em execução em localhost:11434."model": Especifica o modelo a ser usado (aqui é: qwen3:8b)."messages": Uma lista de mensagens de bate-papo contendo role e content."stream": false: Garante que a resposta seja retornada de uma só vez, e não token por token.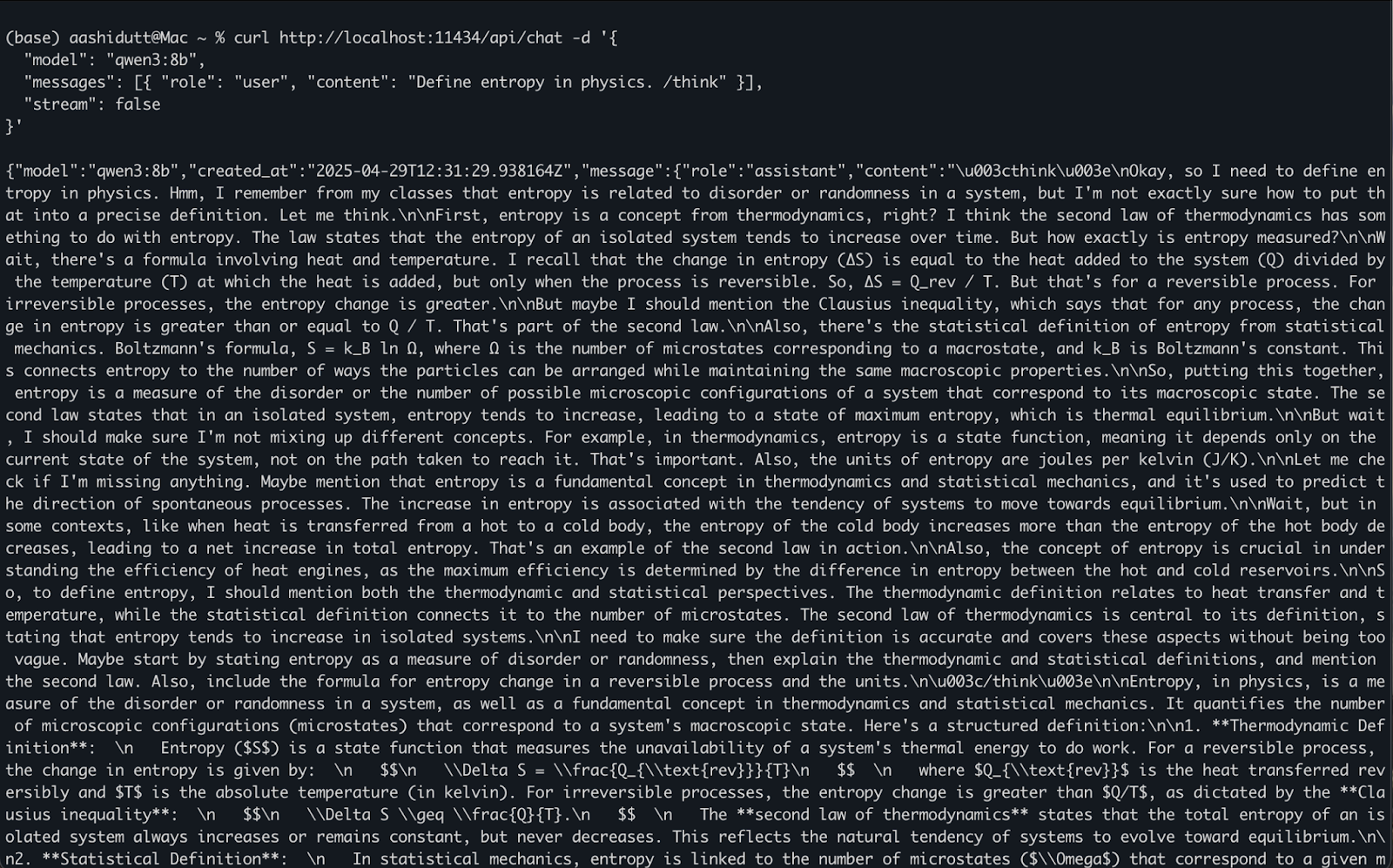
Se você estiver trabalhando em um ambiente Python (como Jupyter, VSCode ou um script), a maneira mais fácil de interagir com o Qwen3 é por meio do Ollama Python SDK. Comece instalando o ollama:
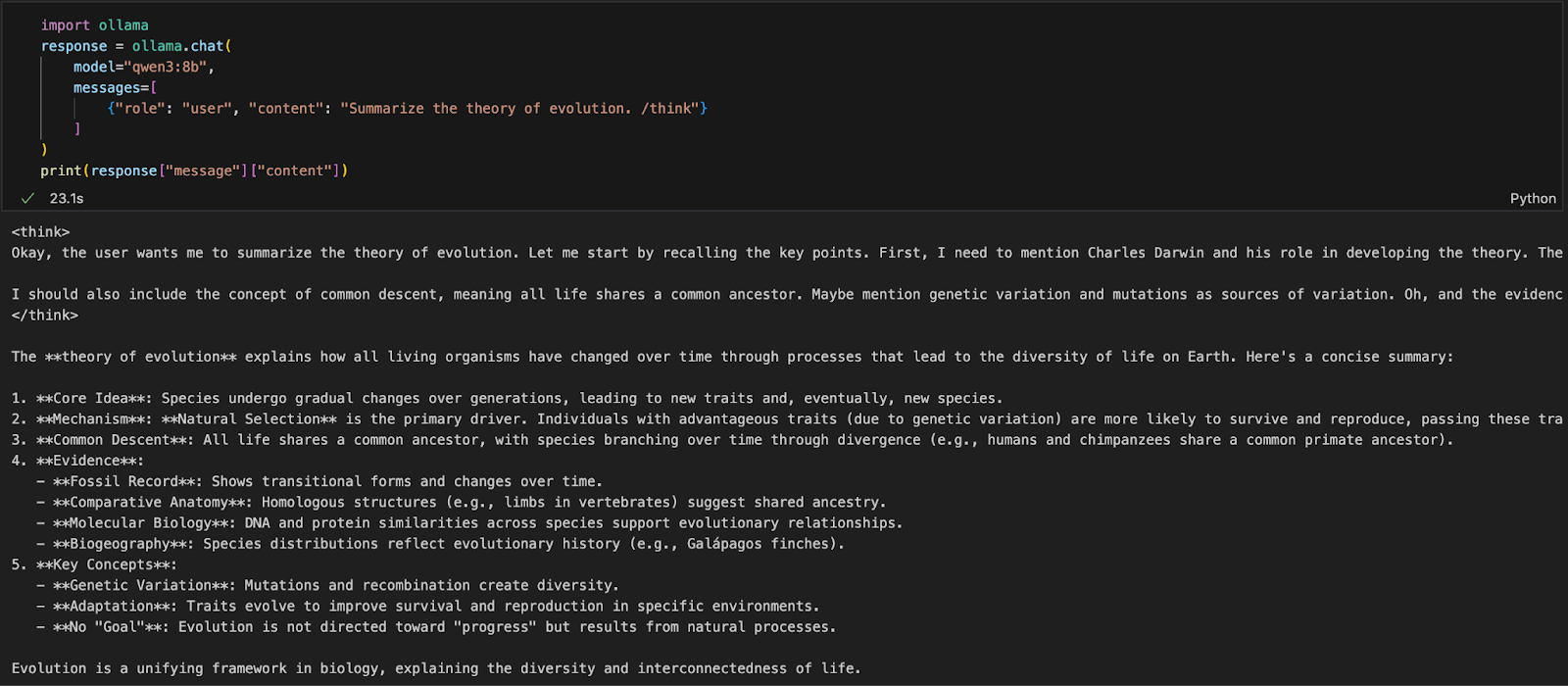
pip install ollamaEm seguida, execute seu modelo Qwen3 com este script (estamos usando qwen3:8b abaixo):
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])No código acima:
ollama.chat(...) envia uma solicitação no estilo de bate-papo para o servidor Ollama local.qwen3:8b) e uma lista de mensagens em um formato semelhante à API da OpenAI./think informa ao modelo que você deve raciocinar passo a passo.["message"]["content"].Essa abordagem é ideal para experimentação local, prototipagem ou criação de aplicativos apoiados pelo LLM sem depender de APIs de nuvem.
O Qwen3 oferece suporte ao comportamento de inferência híbrida usando as tags /think (raciocínio profundo) e /no_think (resposta rápida). Nesta seção, usaremos o Gradio para criar um aplicativo da Web local interativo com duas guias separadas:
Nesta etapa, criamos nossa guia de raciocínio híbrido com as tags /think e /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)No código acima:
reasoning_qwen3() recebe um prompt de usuário e um modo de raciocínio ("think" ou "no_think").subprocess.run() executa o comando ollama run qwen3:8b, alimentando o prompt como entrada padrão.Depois que a função geradora de saída é definida, a função gr.Interface() a transforma em uma interface de usuário interativa da Web, especificando os componentes de entrada - um Textbox para o prompt e um botão Radio para selecionar o modo de raciocínio - e mapeando-os para as entradas da função.
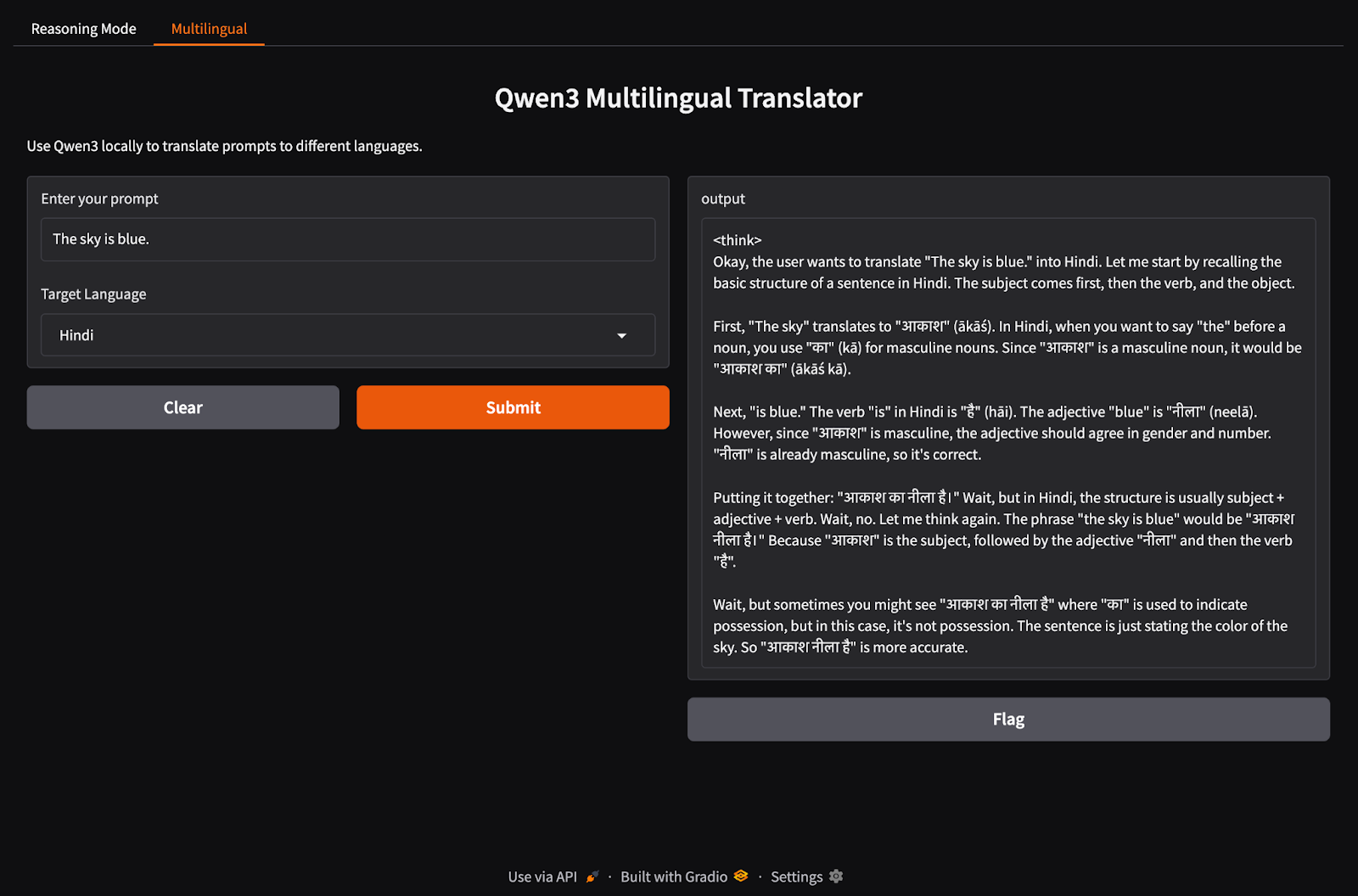
Agora, vamos configurar nossa guia de aplicativo multilíngue.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Semelhante à etapa anterior, esse código funciona da seguinte forma:
multilingual_qwen3() recebe um prompt e um idioma de destino.Vamos reunir as duas guias em um aplicativo Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Aqui está o que estamos fazendo no código acima:
gr.TabbedInterface() cria uma interface do usuário com duas guias:demo.launch(debug=True) executa o aplicativo localmente e o abre no navegador com a depuração ativada.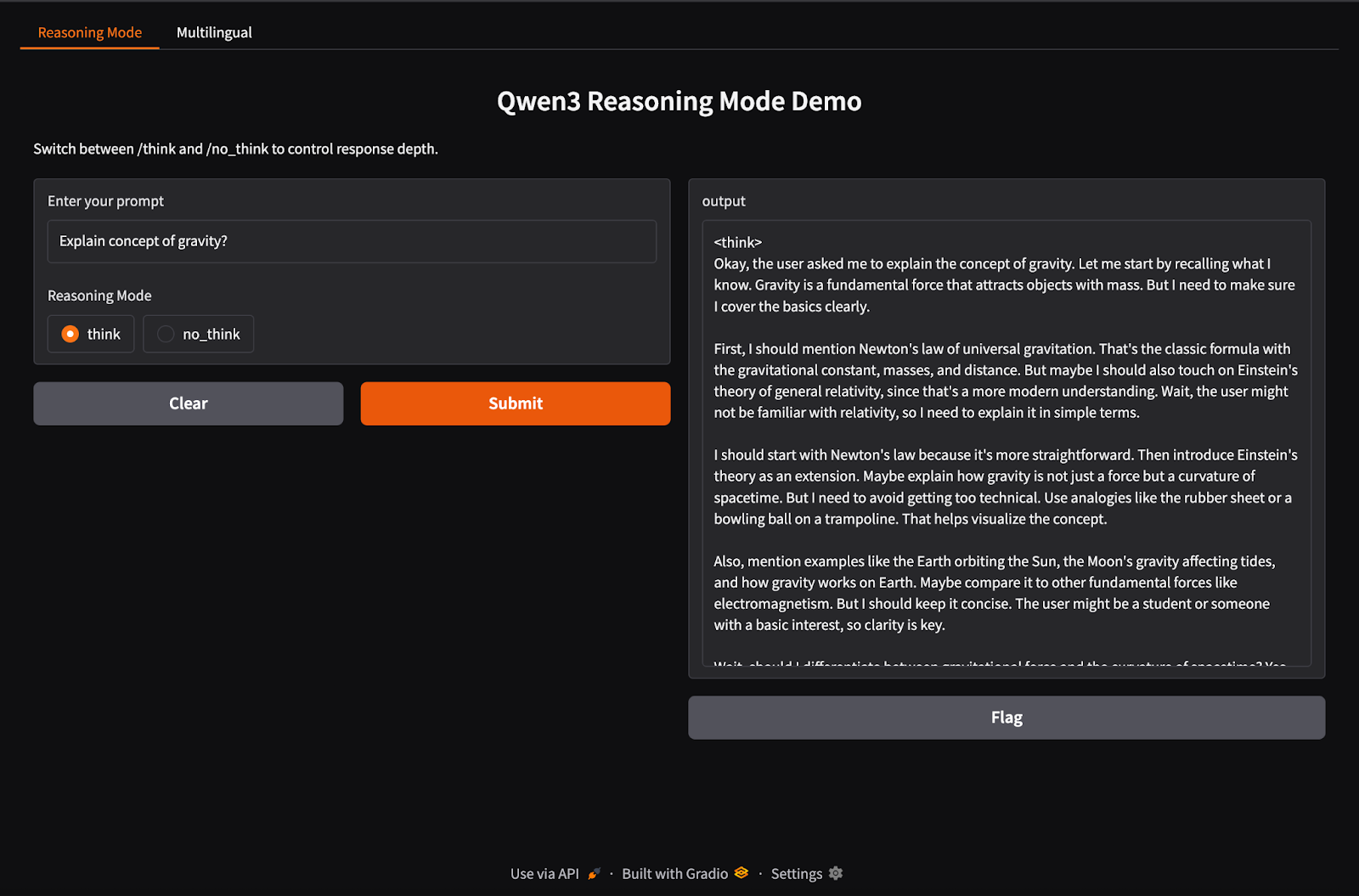
 Conclusão
ConclusãoO Qwen3 traz raciocínio avançado, decodificação rápida e suporte multilíngue para sua máquina local usando Ollama.
Com uma configuração mínima, você pode:
Se você quiser ter uma visão geral dos recursos do Qwen3, recomendo a leitura deste blog introdutório sobre Qwen3.
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Ryan Ong
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze


