

Program
Insinyur AI Asisten untuk Ilmuwan Data
40 Hr
GLM-5 adalah model open-reasoning terbaru dari Z.ai, dan dengan cepat menarik perhatian berkat performanya yang kuat dalam coding, alur kerja agen, dan percakapan ber-konteks panjang.
Banyak pengembang sudah menggunakannya untuk membuat situs web one-shot, membangun aplikasi kecil, dan bereksperimen dengan agen AI lokal.
Tantangannya adalah GLM-5 merupakan model yang sangat besar, dan menjalankannya secara lokal tidak realistis pada perangkat konsumen. Bahkan versi yang sudah dikuantisasi tetap memerlukan ratusan gigabita memori dan setup GPU yang mumpuni.
Dalam tutorial ini, kami membahas cara praktis untuk menjalankan GLM-5 secara lokal menggunakan GGUF 2-bit pada pod NVIDIA H200, menyajikannya melalui llama.cpp, dan menghubungkannya ke Aider agar Anda dapat menggunakan GLM-5 sebagai agen coding yang sesungguhnya di dalam proyek Anda sendiri.
Saya juga merekomendasikan untuk melihat panduan kami tentang menjalankan GLM 4.7 Flash secara Lokal.
Sebelum menjalankan GLM-5 secara lokal, Anda memerlukan varian model yang tepat, memori yang cukup untuk memuatnya, dan tumpukan perangkat lunak GPU yang berfungsi.
Persyaratan perangkat keras bergantung pada ukuran kuantisasi:
Untuk performa terbaik, jumlah VRAM + RAM sistem Anda sebaiknya mendekati ukuran kuantisasi. Jika tidak, llama.cpp dapat melakukan offload ke SSD, tetapi inferensi akan lebih lambat. Gunakan --fit di llama.cpp untuk memaksimalkan penggunaan GPU.
Dalam setup kami, kami menjalankan GLM-5-UD-Q2_K_XL pada NVIDIA H200, dengan VRAM dan RAM sistem yang cukup untuk memuat model dengan efisien.
Prasyarat perangkat lunak:
Di bawah ini, Anda dapat menemukan langkah-langkah menjalankan GLM-5 secara lokal:
Bahkan versi 1-bit dari GLM-5 terlalu besar untuk dijalankan pada sebagian besar laptop konsumen, jadi untuk tutorial ini, saya akan menggunakan Runpod dengan GPU NVIDIA H200.
Mulailah dengan membuat pod baru dan memilih template PyTorch terbaru.
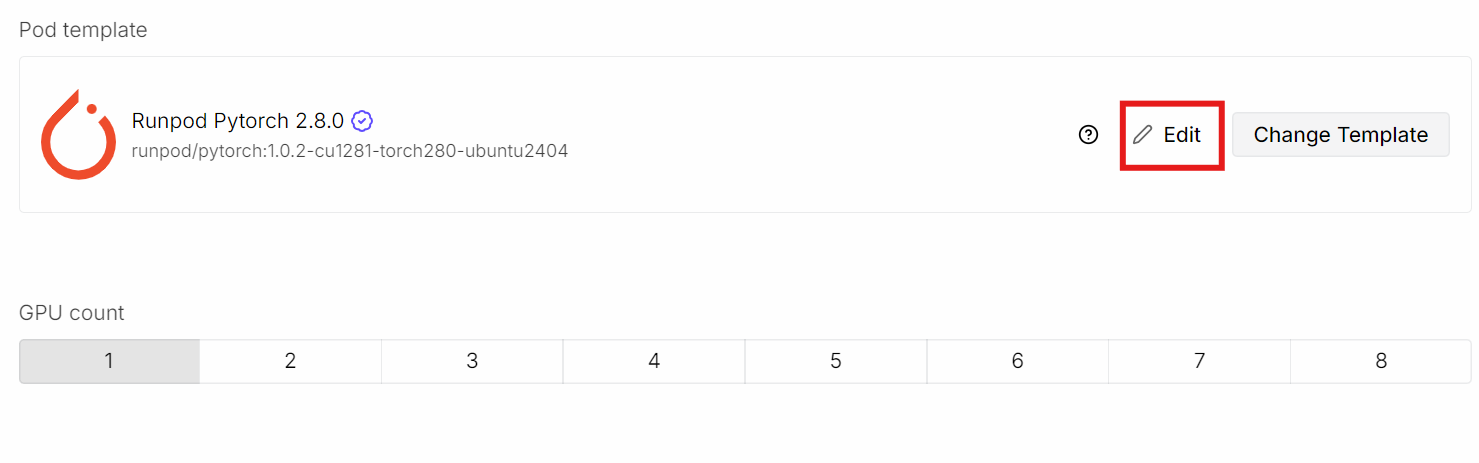
Lalu klik Edit untuk menyesuaikan pengaturan pod:
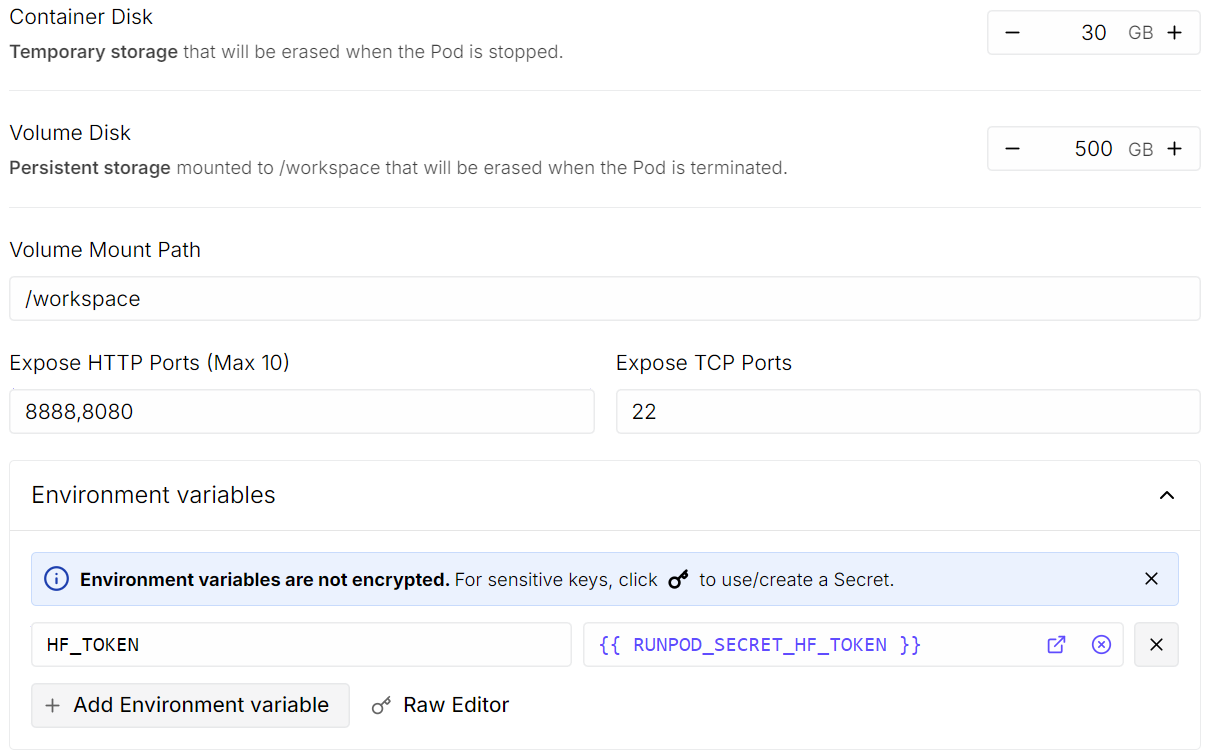
Setelah semuanya tampak benar, tinjau ringkasan pod dan klik Deploy On-Demand.
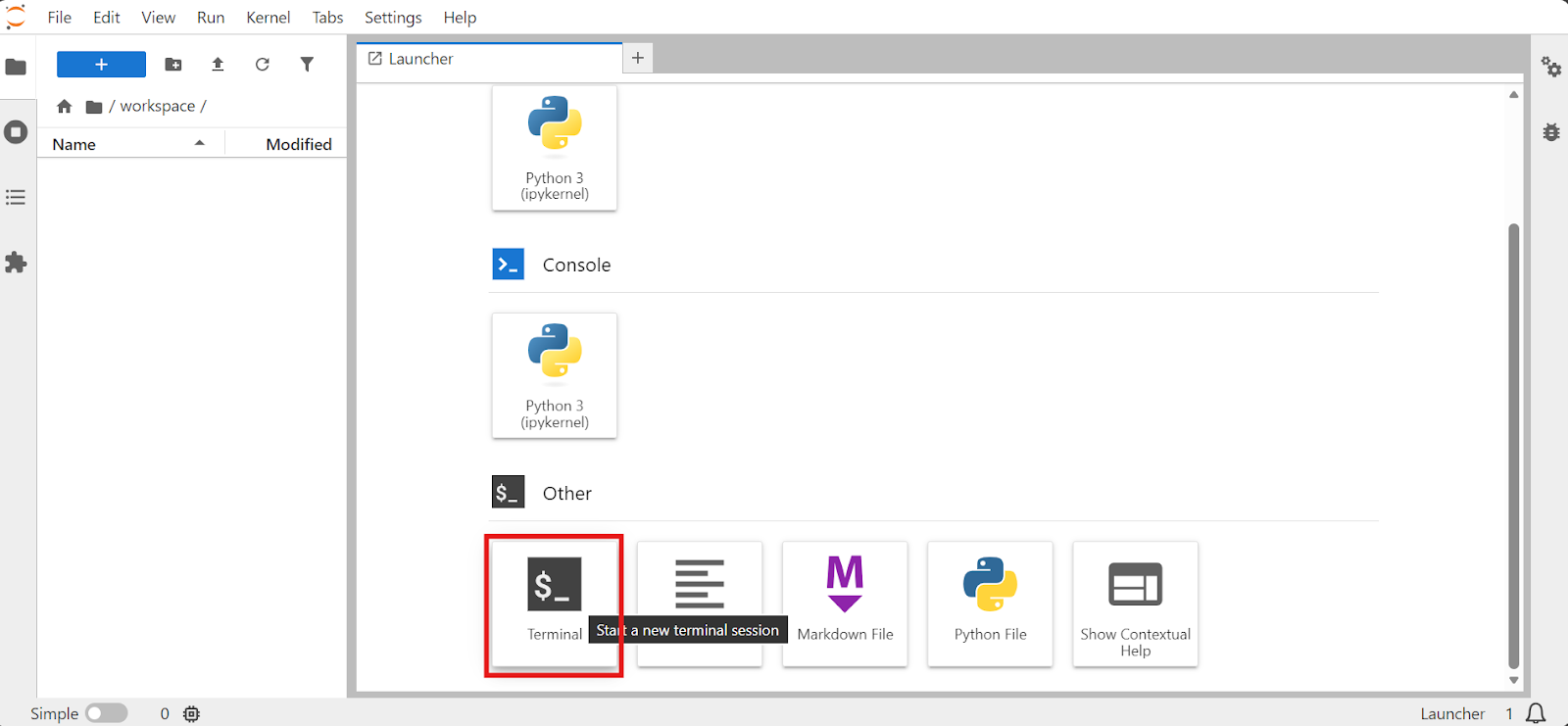
Saat pod siap, buka JupyterLab, luncurkan Terminal, dan bekerja dari sana. Menggunakan terminal Jupyter nyaman karena Anda dapat menjalankan beberapa sesi dengan mulus tanpa bergantung pada SSH.
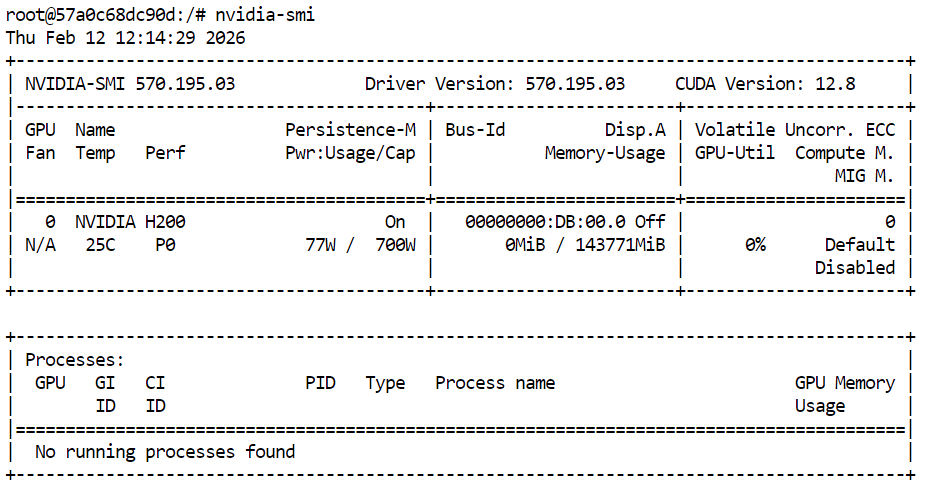
Pertama, konfirmasikan GPU tersedia:
nvidia-smi Anda seharusnya melihat H200 tercantum pada output.
Selanjutnya, pasang paket Linux yang diperlukan untuk mengkloning dan membangun llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqSekarang lingkungan Runpod Anda sudah siap dan GPU berfungsi, langkah berikutnya adalah memasang dan mengompilasi llama.cpp dengan akselerasi CUDA agar GLM-5 dapat berjalan efisien di H200.
Pertama, pindah ke direktori workspace dan klon repositori resmi llama.cpp:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppPada titik ini, penting untuk dicatat bahwa rilis stabil terbaru llama.cpp belum sepenuhnya mendukung GLM-5 secara langsung. Anda perlu menarik pull request upstream tertentu yang berisi perubahan terbaru yang diperlukan untuk kompatibilitas yang tepat.
Ambil dan checkout branch yang diperbarui:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Berikutnya, kita konfigurasi sistem build agar llama.cpp dikompilasi dengan CUDA diaktifkan, memungkinkan model menggunakan akselerasi GPU alih-alih berjalan sepenuhnya di CPU.
Jalankan CMake dengan flag CUDA dinyalakan:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Ini akan membuat direktori build/ khusus dan memastikan binary server llama.cpp mendukung eksekusi GPU NVIDIA.
Setelah konfigurasi selesai, bangun target llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Langkah ini mungkin memakan waktu beberapa menit tergantung pod, tetapi setelah selesai Anda memiliki binary server berkemampuan CUDA siap untuk menjalankan GLM-5.
Terakhir, salin executable yang dikompilasi ke folder utama agar lebih mudah diakses:
cp llama.cpp/build/bin/llama-* llama.cppDengan llama.cpp yang sudah dikompilasi dan siap, langkah selanjutnya adalah mengunduh berkas model GLM-5 GGUF dari Hugging Face.
Karena checkpoint model ini sangat besar, penting untuk mengaktifkan metode unduhan tercepat yang tersedia.
Hugging Face menyediakan alat opsional seperti hf_xet dan hf_transfer, yang secara signifikan meningkatkan kecepatan unduhan, terutama pada mesin cloud seperti Runpod.
Mulailah dengan memasang utilitas unduhan Hugging Face yang diperlukan:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferPaket-paket ini memungkinkan unduhan paralel yang lebih cepat dan kinerja lebih baik saat menarik ratusan gigabita potongan model.
Sekarang unduh varian model terkuantisasi spesifik yang digunakan dalam tutorial ini. Kita hanya menginginkan berkas UD-Q2_K_XL, bukan seluruh unggahan:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Ini akan menyimpan model langsung ke direktori models/GLM-5-GGUF.
Dalam setup kami, kecepatan unduhan mencapai sekitar 1,2 GB/detik, karena kami mengaktifkan hf_xet dan memberikan token Hugging Face sebelumnya. Unduhan anonim biasanya jauh lebih lambat, jadi menyiapkan autentikasi dan percepatan transfer sangat berpengaruh saat bekerja dengan model sebesar ini.
Sekarang model sudah diunduh dan llama.cpp dikompilasi dengan dukungan CUDA, kita dapat memulai GLM-5 menggunakan llama-server bawaan.
Jalankan perintah berikut untuk meluncurkan server:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Beberapa argumen penting untuk dipahami di sini:
--host 0.0.0.0 mengekspos server agar dapat diakses dari browser Anda--port 8080 sesuai dengan port yang kita buka sebelumnya di Runpod--fit on memastikan pemanfaatan GPU maksimal sebelum meluber ke RAM--ctx-size 16384 mengatur jendela konteks untuk inferensi--flash-attn auto mengaktifkan kernel attention yang lebih cepat saat didukungSaat Anda memulai server, Anda akan melihat bahwa llama.cpp menggunakan hampir seluruh memori GPU yang tersedia, dengan sisa lapisan model dialihkan ke RAM sistem. Ini diharapkan dan bekerja baik pada setup H200.
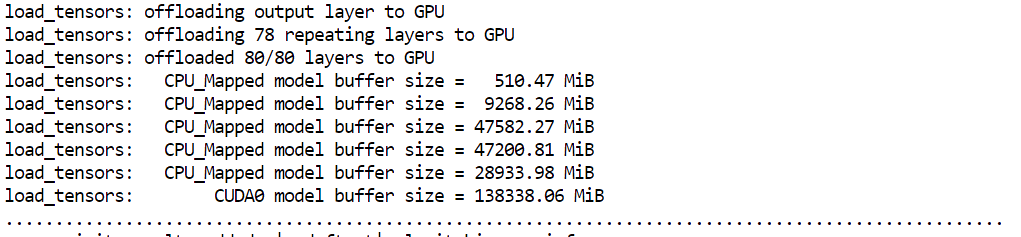
Model seharusnya memuat dan mulai melayani dalam waktu kurang dari satu menit. Jika pod Anda membutuhkan waktu jauh lebih lama, mungkin ada masalah pada instance. Dalam kasus tersebut, biasanya lebih cepat untuk menghentikan pod dan meluncurkan yang baru.

Setelah server berjalan, verifikasi bahwa GLM-5 tersedia dengan melakukan kueri ke endpoint yang kompatibel dengan OpenAI:
curl -s http://127.0.0.1:8080/v1/models | jqAnda seharusnya melihat "GLM-5" tercantum dalam respons, mengonfirmasi model dimuat dan siap digunakan.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Setelah server berjalan, Anda dapat menguji GLM-5 langsung melalui Chat UI bawaan llama.cpp.
Biasanya, WebUI tersedia secara lokal di: http://127.0.0.1:8080
Namun, karena kita menjalankannya di Runpod di cloud, tautan localhost ini tidak akan berfungsi dari mesin Anda.
Sebagai gantinya, buka dasbor Runpod Anda dan klik tautan HTTP Service untuk port 8080. Ini adalah URL publik yang meneruskan trafik ke llama-server Anda yang berjalan.
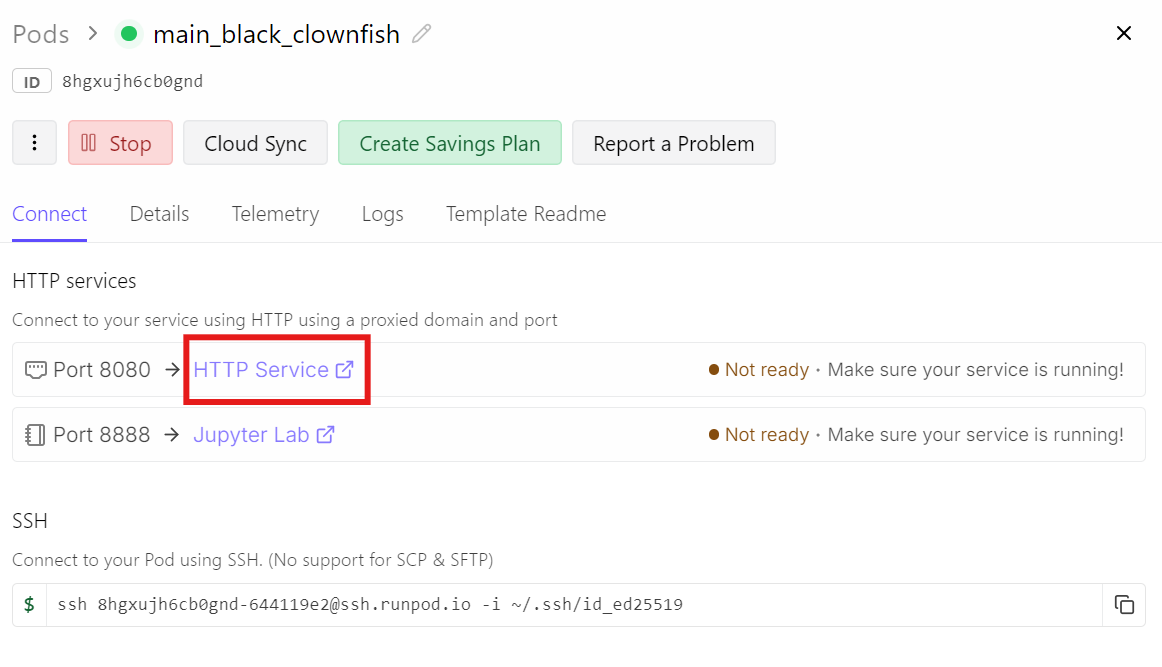 Membuka tautan itu akan membawa Anda ke Chat UI, dengan model GLM-5 sudah dimuat dan siap.
Membuka tautan itu akan membawa Anda ke Chat UI, dengan model GLM-5 sudah dimuat dan siap.
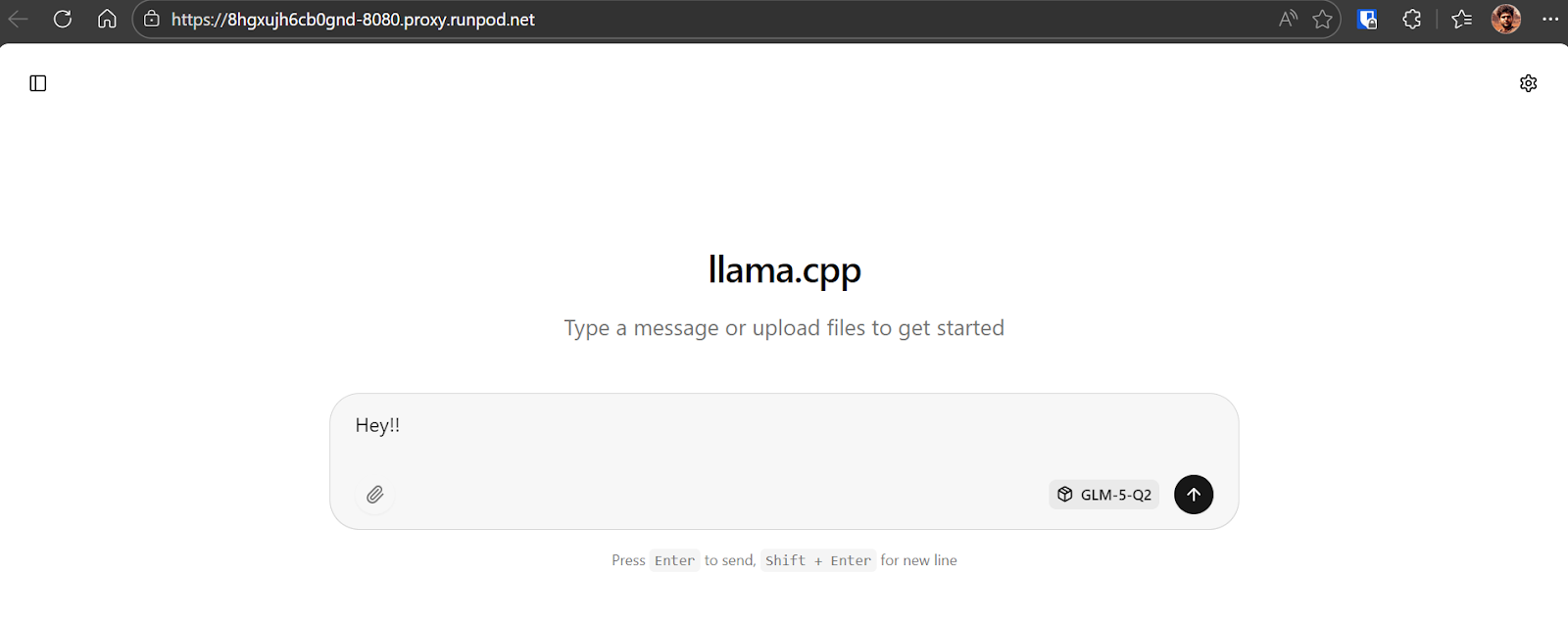
Untuk mengonfirmasi semuanya berfungsi, kirim pesan sederhana seperti “Hey!!”. Anda akan melihat model merespons segera.
Dalam kasus kami, inferensi berjalan sekitar 8,7 token per detik, yang merupakan performa sangat baik mengingat ukuran GLM-5 dan checkpoint 281GB yang dikuantisasi.
Aider adalah alat pair programming AI berbasis terminal yang bekerja langsung di dalam folder proyek Anda.
Anda mengobrol dengannya seperti rekan coding, dan ia dapat membuat, mengedit, dan merombak berkas di seluruh repo Anda sambil tetap berpijak pada basis kode dan alur kerja git Anda yang sebenarnya.
Aider juga mendukung koneksi ke endpoint API yang kompatibel dengan OpenAI, sehingga sangat cocok untuk dijalankan melawan server llama.cpp lokal kita.
Pertama, instal Aider:
pip install -U aider-chatSelanjutnya, arahkan Aider ke server lokal llama.cpp yang kompatibel dengan OpenAI. Kami menetapkan key dummy karena llama.cpp tidak memerlukan kunci OpenAI asli:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASESekarang buat folder proyek demo baru (agar Aider memiliki repo bersih untuk bekerja):
mkdir -p glm5-demo-app
cd glm5-demo-appTerakhir, jalankan Aider dan hubungkan ke GLM-5 menggunakan alias model yang kita ekspos sebelumnya:
aider --model openai/GLM-5 --no-show-model-warningsPada titik ini, apa pun yang Anda minta di dalam Aider akan dirutekan melalui server GLM-5 lokal Anda, dan Aider akan menerapkan perubahan langsung ke berkas di glm5-demo-app.
 Gunakan GLM-5 sebagai Agen Coding Anda
Gunakan GLM-5 sebagai Agen Coding AndaSetelah Aider terhubung ke GLM-5, Anda dapat menggunakannya seperti agen coding di dalam repo Anda. Mulailah dengan sapaan sederhana untuk memastikan responsnya cepat.

Lalu, berikan prompt tugas yang jelas seperti ini:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider akan terlebih dahulu mengusulkan rencana, lalu meminta izin untuk menerapkan edit.
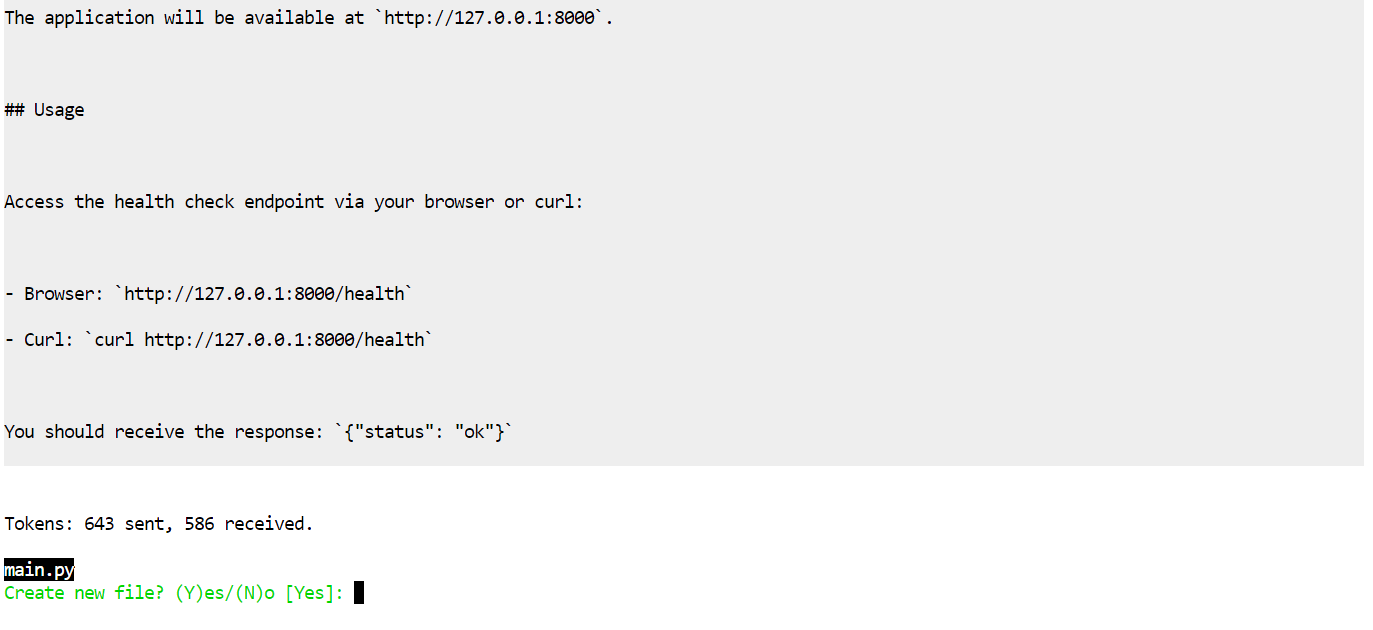
Terima editnya, dan ia akan menghasilkan berkas-berkas secara otomatis.
Pada kuantisasi 2-bit seperti GLM-5-UD-Q2_K_XL, Anda mungkin melihat kesalahan kecil, misalnya membuat berkas seperti pip install -r requirements.txt, yang merupakan kesalahan. Model penuh lebih kecil kemungkinannya membuat kesalahan ini, tetapi model 2-bit tetap sangat dapat digunakan dengan tinjauan manusia cepat.
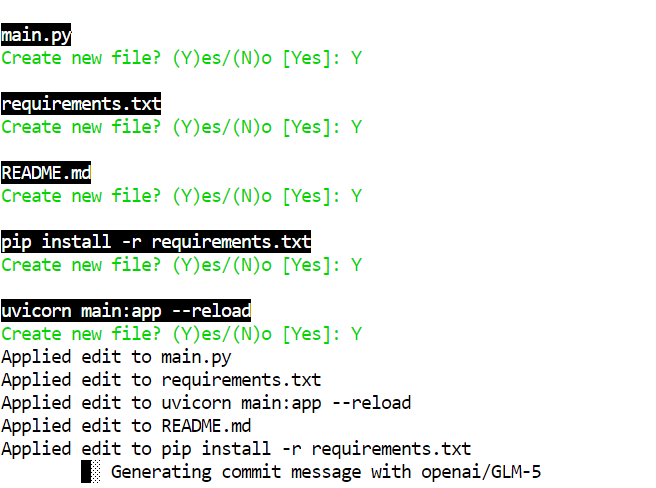
Setelah Aider selesai menulis proyek, masuk ke folder, pasang dependensi, dan jalankan server:
cd glm5-demo-app/pip install -r requirements.txtMulai aplikasi FastAPI dengan Uvicorn:
uvicorn main:app --reloadServer akan berjalan pada port 8000.
Uji endpoint health:
curl -s http://127.0.0.1:8000/healthAnda akan mendapatkan:
{"status":"ok"}GLM-5 dengan cepat menjadi salah satu model open-weight yang paling banyak dibicarakan di komunitas AI, terutama karena mendorong performa open source mendekati model proprietari sekaligus dirancang untuk penalaran mendalam, alur kerja agen, dan tugas coding.
Terlepas dari semua hype, menjalankan model skala penuh secara lokal masih menjadi tantangan bagi pengguna biasa.
Bahkan dengan kuantisasi, model seperti GLM-5 memerlukan ratusan gigabita memori dan GPU cepat, sesuatu yang tidak dimiliki banyak individu pada mesin rumahan.
Ini berarti sebagian besar orang bergantung pada pod GPU cloud (seperti setup H200 dalam tutorial ini) atau menggunakan layanan API terkelola.
Sifat open-weight dari GLM-5 kuat karena memungkinkan Anda meng-host dan mengontrol instance Anda sendiri tanpa bergantung pada penyedia API proprietari, tetapi ini juga menyoroti mengapa open source dalam AI tidak serta-merta berarti “berjalan di laptop” untuk semua orang.
Dalam tutorial ini, kita melihat bagaimana mengatasi hambatan perangkat keras tersebut menggunakan versi GLM-5 2-bit yang dikuantisasi pada GPU Runpod H200. Kita menelusuri penyiapan lingkungan, kompilasi llama.cpp dengan dukungan CUDA, pengunduhan model secara efisien, peluncuran server inferensi, pengujian melalui UI browser, dan akhirnya menghubungkan alat coding seperti Aider untuk menggunakan GLM-5 sebagai agen untuk tugas pengembangan nyata.
Kursus AI Teratas
Program
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
