

programa
Ingeniero Asociado de IA para Científicos de Datos
40 h
GLM-5 es el nuevo modelo de razonamiento abierto de Z.ai y ha ganado atención rápidamente por su gran rendimiento en código, flujos de trabajo con agentes y chats con contextos muy largos.
Muchos desarrolladores ya lo usan para crear sitios web en un solo intento, construir apps pequeñas y experimentar con agentes de IA locales.
El reto es que GLM-5 es un modelo muy grande, y ejecutarlo en local no es realista con hardware de consumo. Incluso las versiones cuantizadas requieren cientos de gigabytes de memoria y una GPU potente.
En este tutorial, veremos una forma práctica de ejecutar GLM-5 en local con una cuantización GGUF de 2 bits en un pod NVIDIA H200, servirlo con llama.cpp y conectarlo a Aider para que puedas usar GLM-5 como un agente real de programación dentro de tus propios proyectos.
También te recomiendo ver nuestra guía sobre ejecutar GLM 4.7 Flash en local.
Antes de ejecutar GLM-5 en local, necesitas la variante correcta del modelo, suficiente memoria para cargarlo y una pila de software de GPU funcional.
Los requisitos de hardware dependen del tamaño de la cuantización:
Para obtener el mejor rendimiento, la VRAM + la RAM del sistema combinadas deberían acercarse al tamaño de la cuantización. Si no, llama.cpp puede descargar a SSD, pero la inferencia será más lenta. Usa --fit en llama.cpp para maximizar el uso de GPU.
En nuestra configuración, ejecutamos GLM-5-UD-Q2_K_XL en una NVIDIA H200, con suficiente VRAM y RAM del sistema para alojar el modelo de forma eficiente.
Requisitos de software:
A continuación, encontrarás las instrucciones paso a paso para ejecutar GLM-5 en local:
Incluso la versión de 1 bit de GLM-5 es demasiado grande para la mayoría de portátiles de consumo, así que para este tutorial usaré Runpod con una GPU NVIDIA H200.
Empieza creando un pod nuevo y seleccionando la plantilla más reciente de PyTorch.
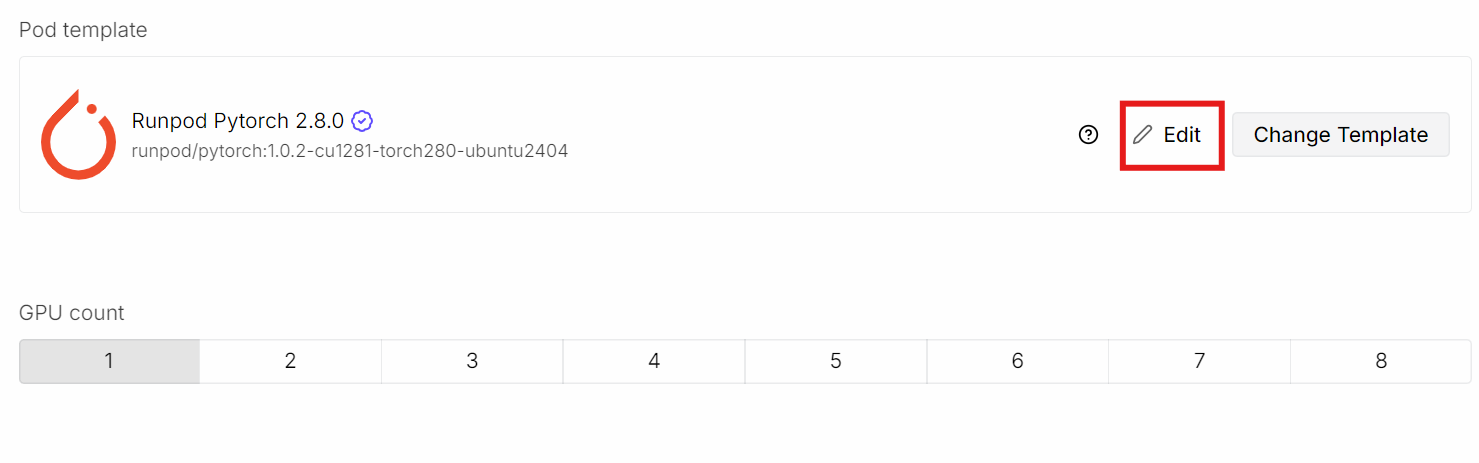
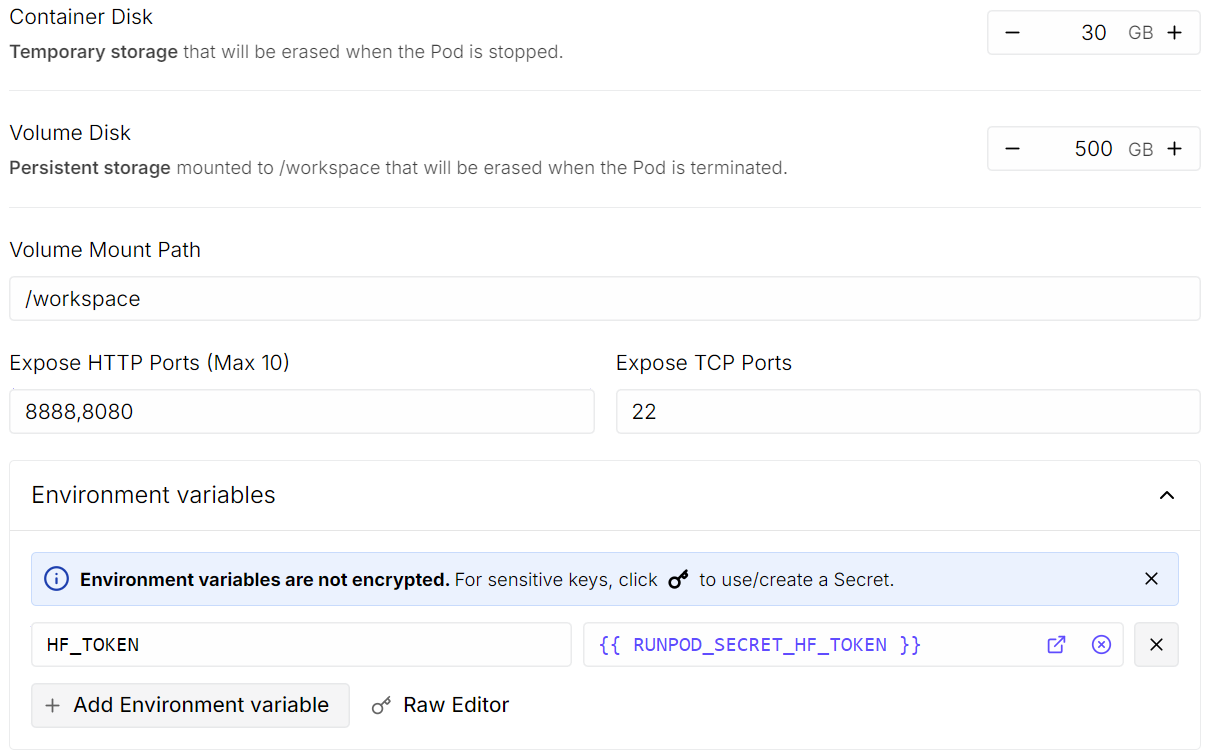
Luego haz clic en Edit para ajustar la configuración del pod:
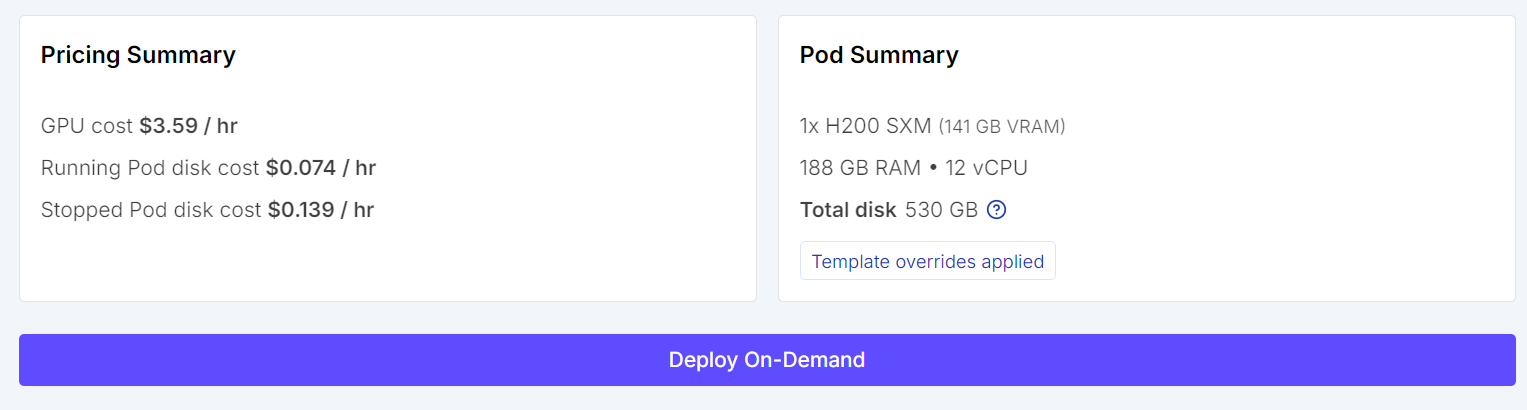
Cuando todo esté correcto, revisa el resumen del pod y haz clic en Deploy On-Demand.
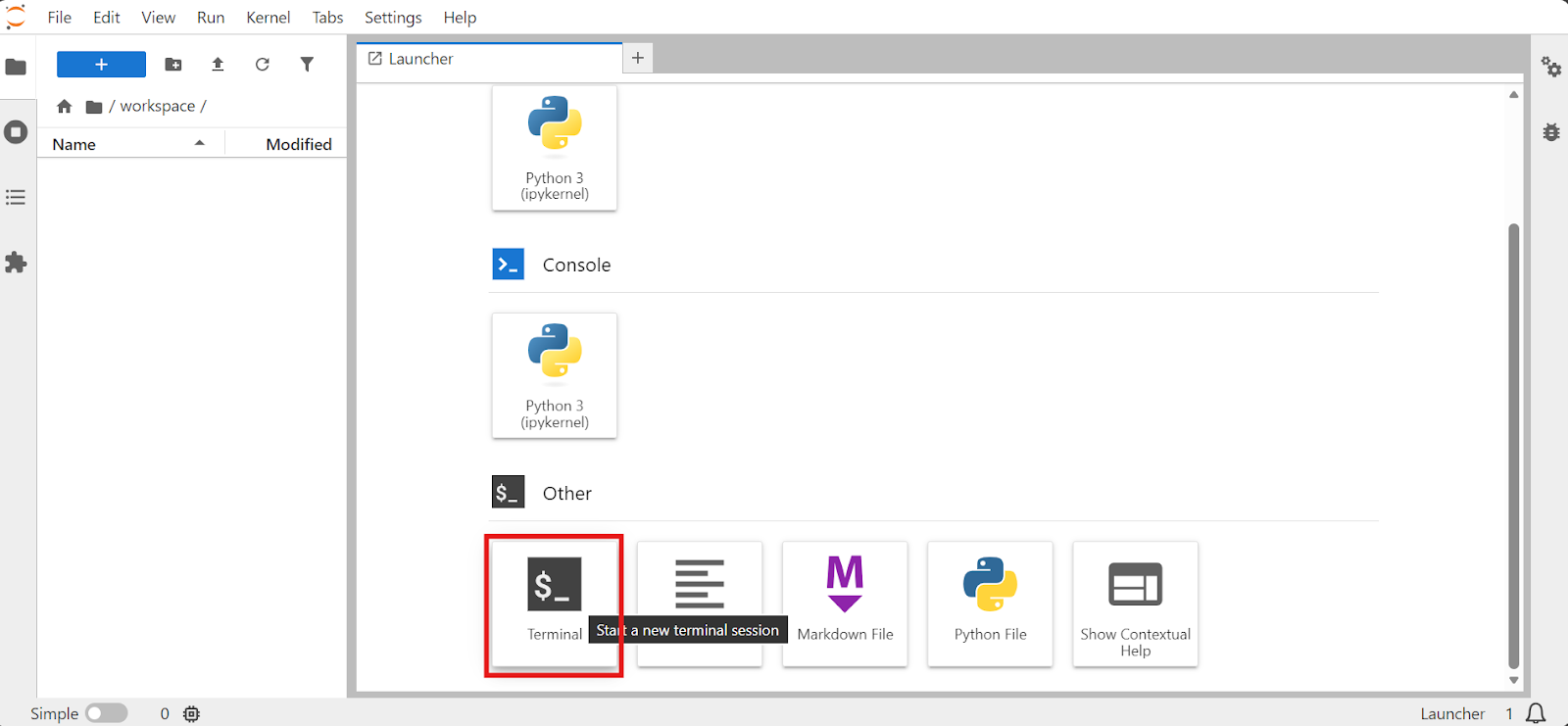
Cuando el pod esté listo, abre JupyterLab, lanza un Terminal y trabaja desde ahí. Usar el terminal de Jupyter es cómodo porque puedes ejecutar varias sesiones sin depender de SSH.
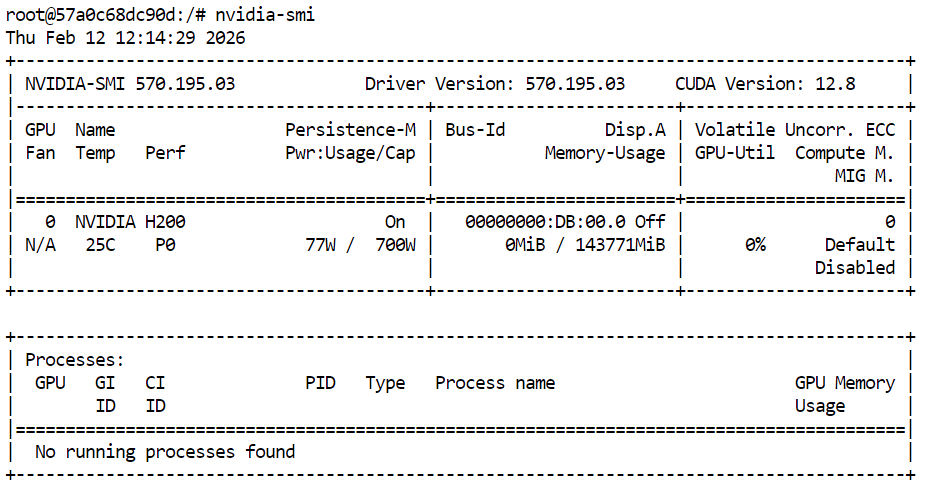
Primero, confirma que la GPU está disponible:
nvidia-smi Deberías ver la H200 listada en la salida.
Después, instala los paquetes de Linux necesarios para clonar y compilar llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqAhora que tu entorno en Runpod está listo y la GPU funciona, el siguiente paso es instalar y compilar llama.cpp con aceleración CUDA para que GLM-5 se ejecute de manera eficiente en la H200.
Primero, entra en el directorio de trabajo y clona el repositorio oficial de llama.cpp:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppEs importante destacar que la última versión estable de llama.cpp aún no ofrece compatibilidad completa con GLM-5 de serie. Debes traer una pull request específica del upstream que incluye cambios recientes necesarios para la compatibilidad adecuada.
Recupera y haz checkout de la rama actualizada:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..A continuación, configuramos el sistema de build para compilar llama.cpp con CUDA activado, permitiendo que el modelo use aceleración por GPU en lugar de ejecutarse solo en CPU.
Ejecuta CMake con la opción de CUDA activada:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Esto crea un directorio build/ dedicado y garantiza que los binarios del servidor de llama.cpp soporten la ejecución en GPU de NVIDIA.
Una vez completada la configuración, compila el objetivo llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Este paso puede tardar unos minutos según el pod, pero al finalizar tendrás un binario del servidor con CUDA listo para ejecutar GLM-5.
Por último, copia los ejecutables compilados a la carpeta principal para acceder a ellos más fácilmente:
cp llama.cpp/build/bin/llama-* llama.cppCon llama.cpp compilado y listo, el siguiente paso es descargar los archivos del modelo GLM-5 GGUF desde Hugging Face.
Como estos checkpoints son extremadamente grandes, es importante activar los métodos de descarga más rápidos disponibles.
Hugging Face ofrece herramientas opcionales como hf_xet y hf_transfer, que aceleran significativamente las descargas, especialmente en máquinas en la nube como Runpod.
Empieza instalando las utilidades de descarga de Hugging Face necesarias:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferEstos paquetes permiten descargas paralelas más rápidas y mejor rendimiento al traer cientos de gigabytes en fragmentos del modelo.
Ahora descarga la variante cuantizada específica que usamos en este tutorial. Solo queremos los archivos UD-Q2_K_XL, no todo el conjunto de subidas:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Esto guardará el modelo directamente en el directorio models/GLM-5-GGUF.
En nuestra configuración, las descargas alcanzan velocidades de alrededor de 1,2 GB/s porque activamos hf_xet y proporcionamos un token de Hugging Face. Las descargas anónimas suelen ser mucho más lentas, así que configurar la autenticación y la aceleración de transferencia marca una gran diferencia con modelos de este tamaño.
Ahora que el modelo está descargado y llama.cpp está compilado con soporte CUDA, podemos iniciar GLM-5 usando el llama-server incluido.
Ejecuta el siguiente comando para lanzar el servidor:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Algunos argumentos importantes a tener en cuenta:
--host 0.0.0.0 expone el servidor para que pueda accederse desde tu navegador--port 8080 coincide con el puerto que abrimos antes en Runpod--fit on garantiza el uso máximo de la GPU antes de pasar a RAM--ctx-size 16384 establece la ventana de contexto para la inferencia--flash-attn auto activa kernels de atención más rápidos cuando se soportaAl iniciar el servidor, verás que llama.cpp usa casi toda la memoria de GPU disponible, y descarga el resto de capas del modelo a la RAM del sistema. Es lo esperado y funciona bien en configuraciones con H200.
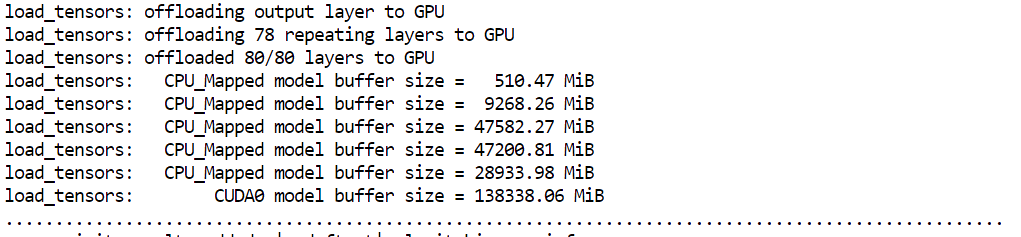
El modelo debería cargarse y empezar a servir en menos de un minuto. Si tu pod tarda mucho más, puede haber un problema con la instancia. En ese caso, suele ser más rápido terminar el pod y lanzar uno nuevo.

Cuando el servidor esté en marcha, verifica que GLM-5 está disponible consultando el endpoint compatible con OpenAI:
curl -s http://127.0.0.1:8080/v1/models | jqDeberías ver "GLM-5" en la respuesta, confirmando que el modelo está cargado y listo.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Con el servidor funcionando, puedes probar GLM-5 directamente desde la interfaz de Chat incorporada de llama.cpp.
Normalmente, la WebUI está disponible en local en: http://127.0.0.1:8080
Sin embargo, como estamos ejecutando en Runpod en la nube, ese enlace a localhost no funcionará desde tu máquina.
En su lugar, ve a tu panel de Runpod y haz clic en el enlace de HTTP Service para el puerto 8080. Esta es la URL pública que reenvía el tráfico a tu llama-server en ejecución.
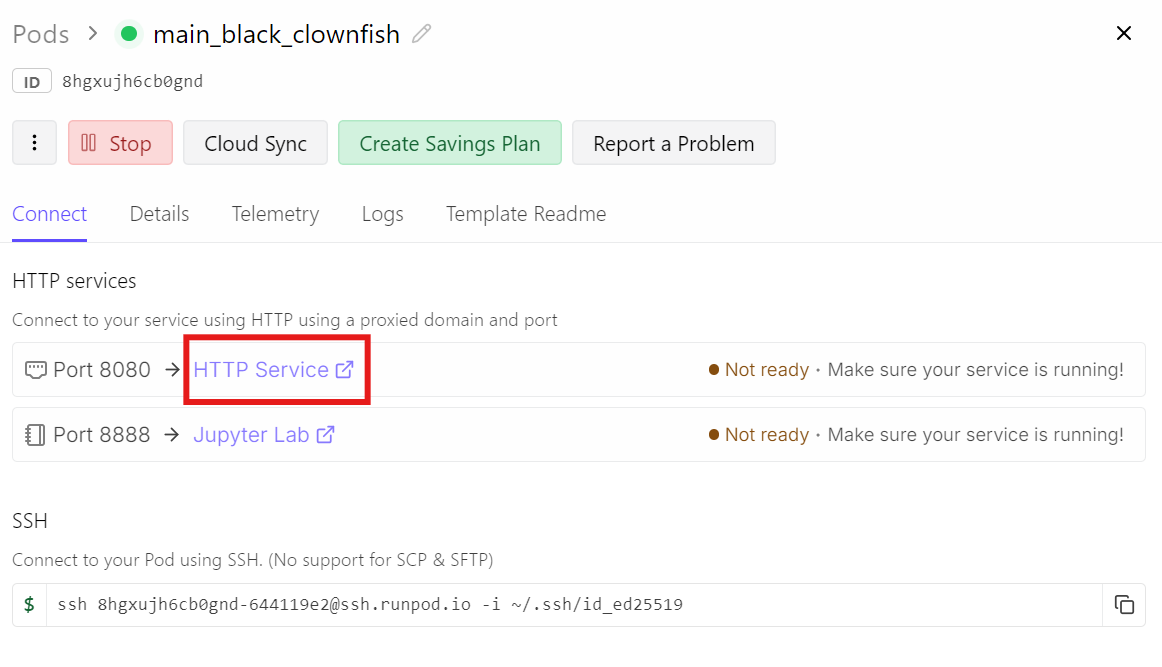 Al abrir ese enlace accederás a la interfaz de Chat, con el modelo GLM-5 ya cargado y listo.
Al abrir ese enlace accederás a la interfaz de Chat, con el modelo GLM-5 ya cargado y listo.
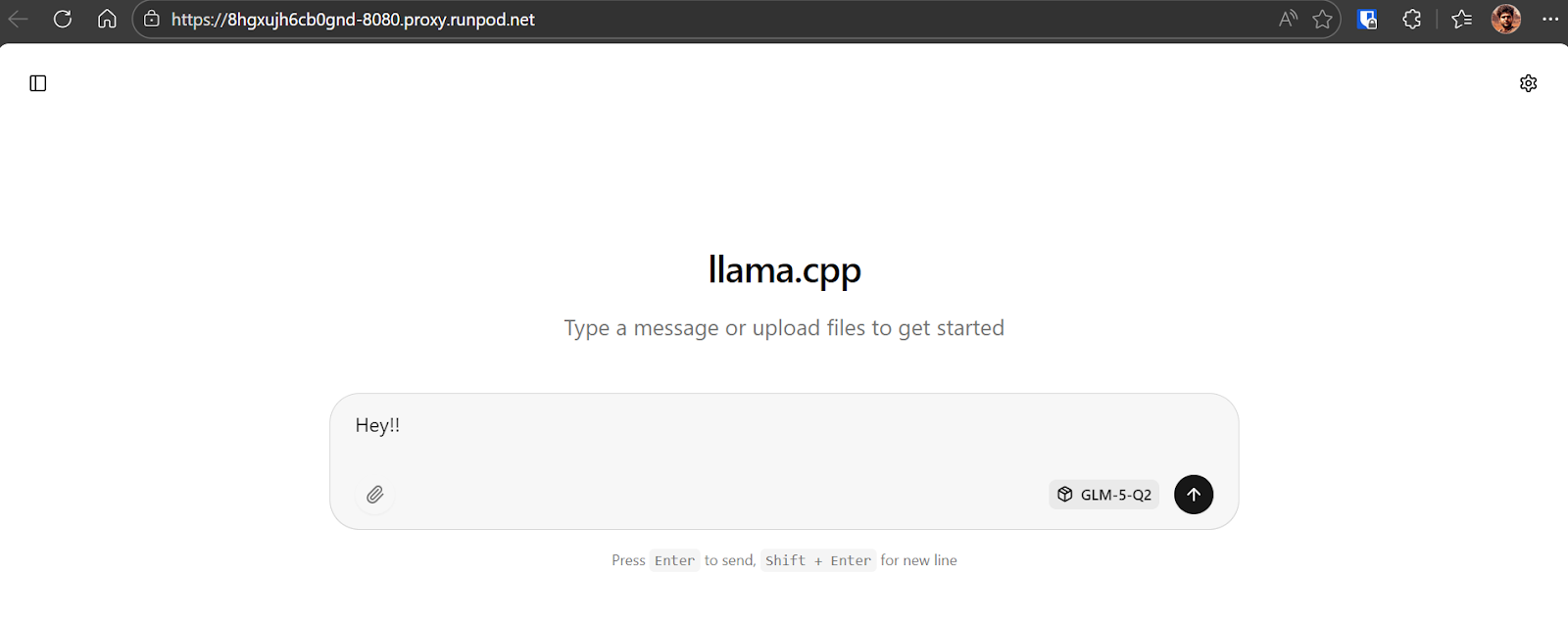
Para confirmar que todo funciona, envía un mensaje sencillo como “¡Hey!!”. Verás que el modelo responde al momento.
En nuestro caso, la inferencia corre a alrededor de 8,7 tokens por segundo, un rendimiento excelente teniendo en cuenta el tamaño de GLM-5 y el checkpoint cuantizado de 281 GB.
Aider es una herramienta de pair programming con IA basada en terminal que trabaja directamente dentro de la carpeta de tu proyecto.
Chateas con ella como con una pareja de programación, y puede crear, editar y refactorizar archivos en tu repo manteniendo todo anclado a tu base de código real y a tu flujo de trabajo con git.
También permite conectar con cualquier endpoint de API compatible con OpenAI, lo que lo hace ideal para usarlo contra nuestro servidor local de llama.cpp.
Primero, instala Aider:
pip install -U aider-chatDespués, apunta Aider a tu servidor local de llama.cpp compatible con OpenAI. Establecemos una clave ficticia porque llama.cpp no requiere una clave real de OpenAI:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEAhora crea una carpeta de proyecto de demo nueva (para que Aider tenga un repo limpio con el que trabajar):
mkdir -p glm5-demo-app
cd glm5-demo-appPor último, inicia Aider y conéctalo a GLM-5 usando el alias del modelo que expusimos antes:
aider --model openai/GLM-5 --no-show-model-warningsA partir de aquí, cualquier cosa que pidas dentro de Aider pasará por tu servidor local de GLM-5, y Aider aplicará cambios directamente a los archivos en glm5-demo-app.
 Usa GLM-5 como tu agente de programación
Usa GLM-5 como tu agente de programaciónUna vez que Aider esté conectado a GLM-5, puedes usarlo como agente de programación dentro de tu repo. Empieza con un saludo sencillo para confirmar que responde rápido.

Luego, dale una instrucción clara como esta:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider primero propondrá un plan y luego pedirá permiso para aplicar los cambios.
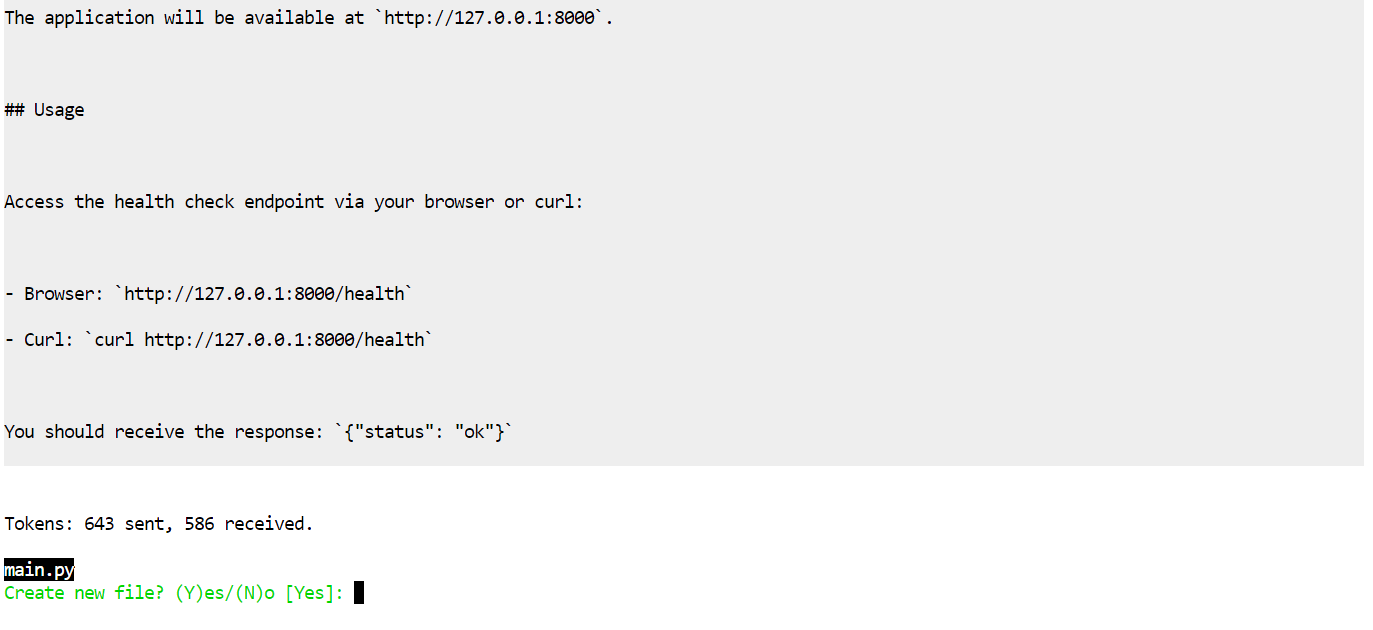
Acepta los cambios y generará los archivos automáticamente.
En una cuantización de 2 bits como GLM-5-UD-Q2_K_XL, puedes ver pequeños fallos, por ejemplo, crear un archivo como pip install -r requirements.txt, que es un error. El modelo completo es menos propenso a estos fallos, pero el de 2 bits sigue siendo muy usable con una rápida revisión humana.
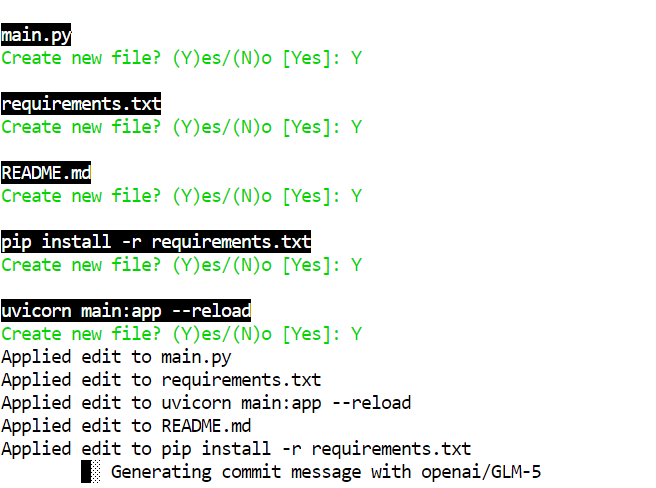
Cuando Aider termine de escribir el proyecto, entra en la carpeta, instala dependencias y ejecuta el servidor:
cd glm5-demo-app/pip install -r requirements.txtInicia la app de FastAPI con Uvicorn:
uvicorn main:app --reloadEl servidor se ejecutará en el puerto 8000.
Prueba el endpoint de salud:
curl -s http://127.0.0.1:8000/healthDeberías obtener:
{"status":"ok"}GLM-5 se está convirtiendo rápidamente en uno de los modelos de pesos abiertos más comentados en la comunidad de IA, sobre todo porque acerca el rendimiento open source al de modelos propietarios mientras está diseñado para razonamiento profundo, flujos de trabajo con agentes y tareas de programación.
A pesar del hype, seguir ejecutando modelos a gran escala en local es un desafío para la mayoría.
Incluso con cuantización, modelos como GLM-5 requieren cientos de gigabytes de memoria y GPUs rápidas, algo que mucha gente no tiene en casa.
Esto significa que la mayoría recurre a pods de GPU en la nube (como la H200 de este tutorial) o a servicios de API alojados.
El carácter de pesos abiertos de GLM-5 es potente porque te permite alojar y controlar tu propia instancia sin depender de proveedores de API propietarios, pero también deja claro por qué open source en IA no significa mágicamente “se ejecuta en un portátil” para todo el mundo.
En este tutorial, hemos visto cómo superar esas barreras de hardware usando una versión cuantizada de 2 bits de GLM-5 en una GPU H200 de Runpod. Hemos repasado la configuración del entorno, la compilación de llama.cpp con soporte CUDA, la descarga eficiente del modelo, el lanzamiento del servidor de inferencia, su prueba desde el navegador y, por último, la conexión de una herramienta de programación como Aider para usar GLM-5 como agente en tareas de desarrollo reales.
Los mejores cursos de IA
programa
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
13 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita


