

Program
Veri Bilimcileri için Yardımcı Yapay Zeka Mühendisi
40 sa
GLM-5, Z.ai’nin en yeni açık-akıl yürütme modelidir ve kodlama, ajan iş akışları ve uzun-bağlamlı sohbetlerdeki güçlü performansıyla hızla dikkat çekmiştir.
Pek çok geliştirici, web sitelerini tek seferde oluşturmaktan küçük uygulamalar geliştirmeye ve yerel yapay zeka ajanlarıyla denemeler yapmaya kadar çeşitli amaçlarla şimdiden kullanıyor.
Zorluk şu ki GLM-5 çok büyük bir model ve tüketici donanımında yerel olarak çalıştırmak gerçekçi değil. Kuantize sürümler bile yüzlerce gigabayt bellek ve yetkin bir GPU kurulumu gerektiriyor.
Bu eğitimde, GLM-5’i NVIDIA H200 pod üzerinde 2-bit GGUF kuant ile yerelde çalıştırmanın pratik bir yolunu adım adım anlatıyoruz; llama.cpp üzerinden sunuyor ve Aider’a bağlayarak GLM-5’i projelerinizin içinde gerçek bir kodlama ajanı olarak kullanmanızı sağlıyoruz.
Ayrıca, GLM 4.7 Flash’i Yerelde Çalıştırma rehberimize de göz atmanızı öneririm.
GLM-5’i yerelde çalıştırmadan önce, doğru model varyantına, onu yüklemek için yeterli belleğe ve çalışan bir GPU yazılım yığınına ihtiyacınız olacak.
Donanım gereksinimleri kuant boyutuna bağlıdır:
En iyi performans için, VRAM + sistem RAM toplamınız kuant boyutuna yakın olmalıdır. Değilse, llama.cpp SSD’ye offload edebilir ancak çıkarım daha yavaş olur. GPU kullanımını en üst düzeye çıkarmak için llama.cpp’de --fit kullanın.
Kurulumumuzda, GLM-5-UD-Q2_K_XL’ı bir NVIDIA H200 üzerinde çalıştırıyoruz; modeli verimli şekilde sığdırmak için yeterli VRAM ve sistem RAM mevcut.
Yazılım ön koşulları:
Aşağıda, GLM-5’i yerelde çalıştırmak için adım adım talimatları bulabilirsiniz:
GLM-5’in 1-bit sürümü bile çoğu tüketici dizüstü bilgisayarında çalıştırılamayacak kadar büyük, bu yüzden bu eğitimde Runpod üzerinde NVIDIA H200 GPU kullanacağım.
Yeni bir pod oluşturarak ve en güncel PyTorch şablonunu seçerek başlayın.
Ardından pod ayarlarını düzenlemek için Edit’e tıklayın:
Her şey doğru görünüyorsa, pod özetini gözden geçirip Deploy On-Demand’e tıklayın.
Pod hazır olduğunda JupyterLab’i açın, bir Terminal başlatın ve oradan çalışın. Jupyter terminalini kullanmak, SSH’ye güvenmeden birden fazla oturumu sorunsuzca çalıştırabildiğiniz için pratiktir.
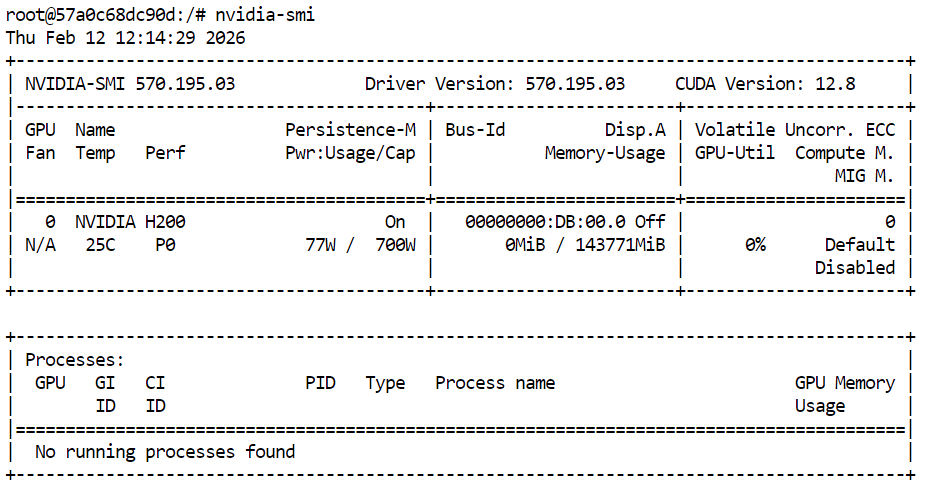
Önce, GPU’nun hazır olduğunu doğrulayın:
nvidia-smi Çıktıda H200’ü görmelisiniz.
Sonraki adımda, llama.cpp’yi klonlamak ve derlemek için gereken Linux paketlerini kurun:
sudo apt update
sudo apt install -y git cmake build-essential curl jqArtık Runpod ortamınız hazır ve GPU çalışıyor; sıradaki adım, llama.cpp’yi CUDA hızlandırmasıyla kurup derlemek, böylece GLM-5’i H200 üzerinde verimli şekilde çalıştırabilmek.
Önce, çalışma alanı dizinine gidin ve resmi llama.cpp deposunu klonlayın:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppBu noktada, en son kararlı llama.cpp sürümünün GLM-5’i henüz kutudan çıktığı gibi tam olarak desteklemediğini belirtmek önemlidir. Doğru uyumluluk için gerekli son değişiklikleri içeren belirli bir upstream çekme isteğini almanız gerekir.
Güncellenmiş dalı fetch edip checkout yapın:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Sırada, llama.cpp’nin CUDA etkin şekilde derlenmesi için derleme sistemini yapılandırmak var; böylece model tamamen CPU’da çalışmak yerine GPU hızlandırması kullanabilecek.
CMake’i CUDA bayrağı açık şekilde çalıştırın:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Bu işlem özel bir build/ dizini oluşturur ve llama.cpp sunucu ikililerinin NVIDIA GPU yürütmesini desteklemesini sağlar.
Yapılandırma tamamlandığında, llama-server hedefini derleyin:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Bu adım, poda bağlı olarak birkaç dakika sürebilir; bittiğinde GLM-5’i çalıştırmaya hazır CUDA etkin bir sunucu ikilisine sahip olacaksınız.
Son olarak, derlenen çalıştırılabilir dosyaları kolay erişim için ana klasöre kopyalayın:
cp llama.cpp/build/bin/llama-* llama.cppllama.cpp derlenip hazır olduğuna göre, sıradaki adım GLM-5 GGUF model dosyalarını Hugging Face’ten indirmektir.
Bu model checkpoint’leri son derece büyük olduğundan, mevcut en hızlı indirme yöntemlerini etkinleştirmek önemlidir.
Hugging Face, özellikle Runpod gibi bulut makinelerinde indirme hızını önemli ölçüde artıran hf_xet ve hf_transfer gibi isteğe bağlı araçlar sunar.
Gerekli Hugging Face indirme yardımcı programlarını kurarak başlayın:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferBu paketler, yüzlerce gigabaytlık model parçalarını çekerken daha hızlı paralel indirmelere ve daha iyi performansa olanak tanır.
Şimdi bu eğitimde kullanılan belirli kuantize model varyantını indirin. Tam yüklemeler yerine yalnızca UD-Q2_K_XL dosyalarını istiyoruz:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Bu işlem modeli doğrudan models/GLM-5-GGUF dizinine kaydedecektir.
Kurulumumuzda indirme hızları yaklaşık 1.2 GB/sn civarına ulaşıyor; çünkü hf_xet’i etkinleştirdik ve daha önce bir Hugging Face belirteci sağladık. Anonim indirmeler genellikle çok daha yavaştır; bu ölçekteki modellerle çalışırken kimlik doğrulama ve transfer hızlandırması kurmak büyük fark yaratır.
Artık model indirildi ve llama.cpp CUDA desteğiyle derlendi; yerleşik llama-server kullanarak GLM-5’i başlatabiliriz.
Sunucuyu başlatmak için aşağıdaki komutu çalıştırın:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Buradaki birkaç önemli argüman:
--host 0.0.0.0 sunucuyu tarayıcınızdan erişilebilir kılar--port 8080 Runpod’da daha önce açtığımız porta karşılık gelir--fit on RAM’e taşmadan önce maksimum GPU kullanımını sağlar--ctx-size 16384 çıkarım için bağlam penceresini ayarlar--flash-attn auto desteklendiğinde daha hızlı attention çekirdeklerini etkinleştirirSunucuyu başlattığınızda, llama.cpp’nin mevcut GPU belleğinin neredeyse tamamını kullandığını, kalan model katmanlarının sistem RAM’ine offload edildiğini fark edeceksiniz. Bu beklenen bir durumdur ve H200 kurulumlarında iyi çalışır.
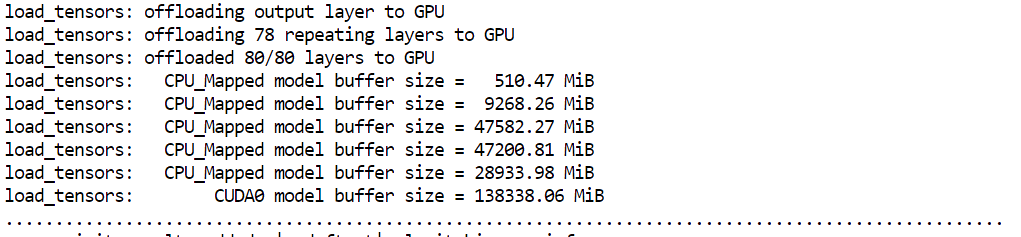
Model bir dakikadan kısa sürede yüklenip servis vermeye başlamalıdır. Podunuz belirgin şekilde daha uzun sürüyorsa, örnekte bir sorun olabilir; bu durumda podu sonlandırıp yenisini başlatmak genellikle daha hızlıdır.

Sunucu çalışmaya başladıktan sonra, OpenAI uyumlu uç noktayı sorgulayarak GLM-5’in hazır olduğunu doğrulayın:
curl -s http://127.0.0.1:8080/v1/models | jqYanıtta "GLM-5" görmelisiniz; bu, modelin yüklendiğini ve kullanıma hazır olduğunu teyit eder.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Sunucu çalışmaya başladıktan sonra, GLM-5’i yerleşik llama.cpp Sohbet Arayüzü üzerinden doğrudan test edebilirsiniz.
Normalde WebUI şu yerel adresten erişilebilirdir: http://127.0.0.1:8080
Ancak biz bulutta Runpod üzerinde çalıştırdığımız için bu localhost bağlantısı makinenizden çalışmayacaktır.
Bunun yerine, Runpod panonuza gidin ve 8080 portu için HTTP Service bağlantısına tıklayın. Bu bağlantı, trafiği çalışan llama-server’ınıza ileten herkese açık URL’dir.
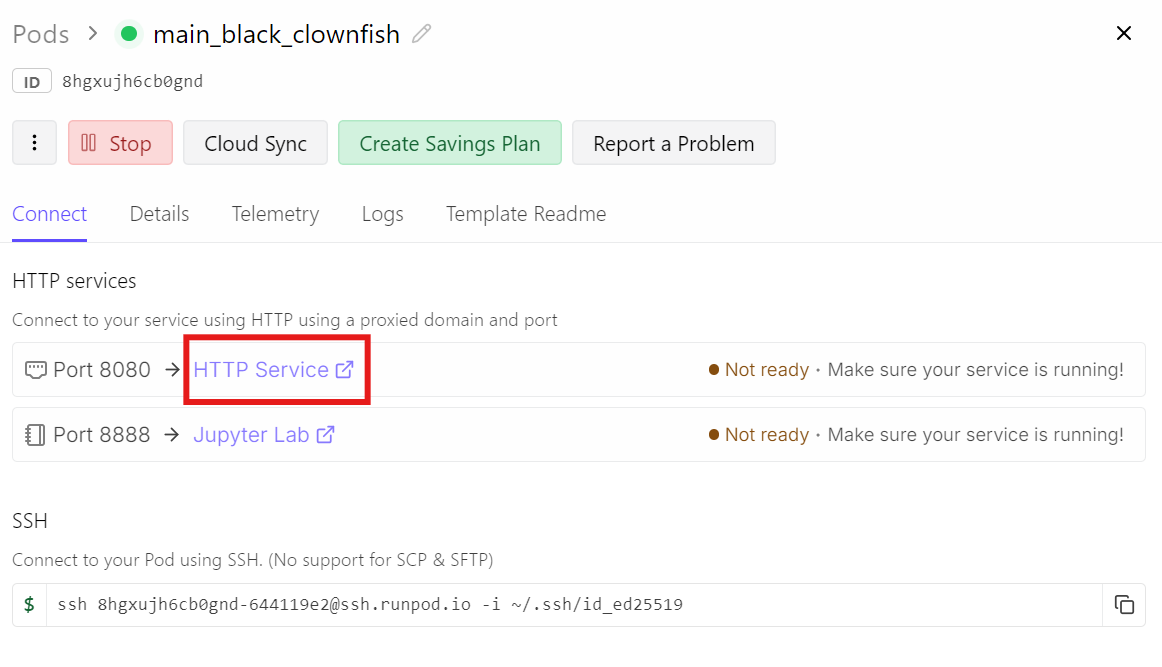 Bu bağlantıyı açmak sizi Sohbet Arayüzüne götürecek; GLM-5 modeli zaten yüklü ve hazır olacaktır.
Bu bağlantıyı açmak sizi Sohbet Arayüzüne götürecek; GLM-5 modeli zaten yüklü ve hazır olacaktır.
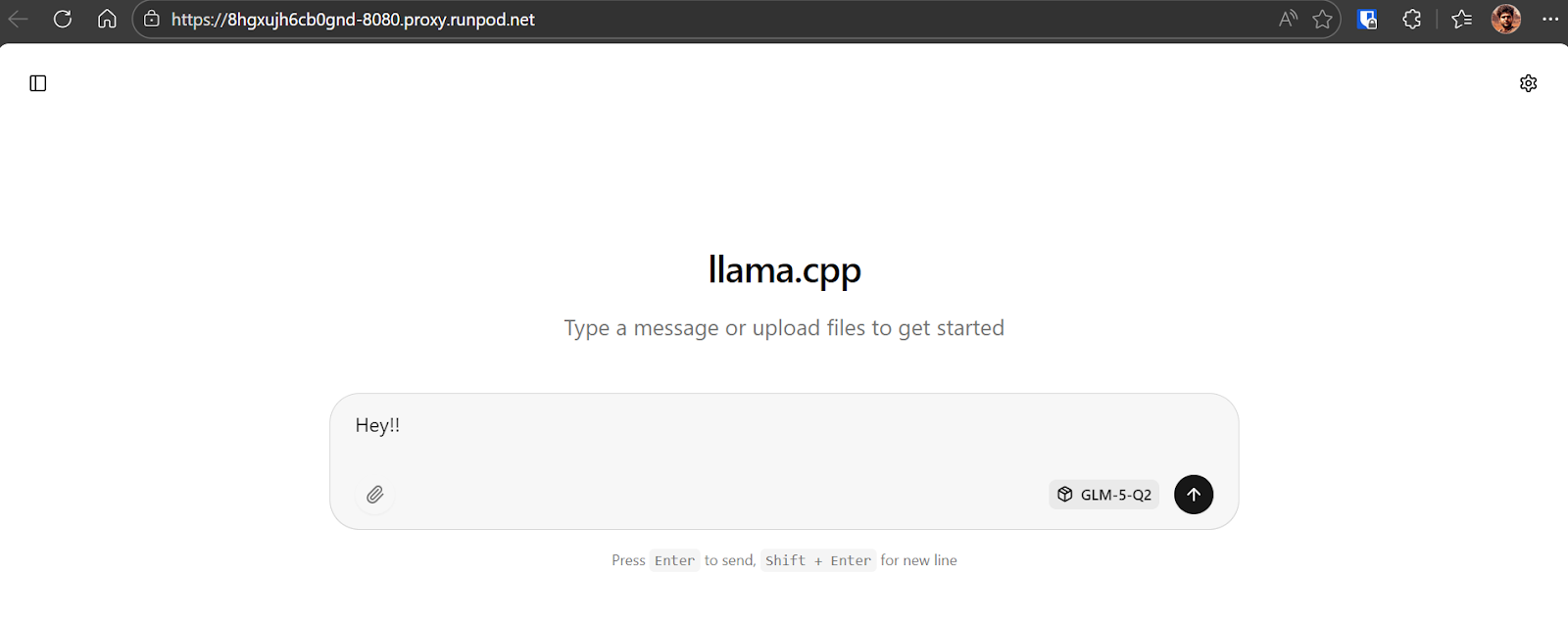
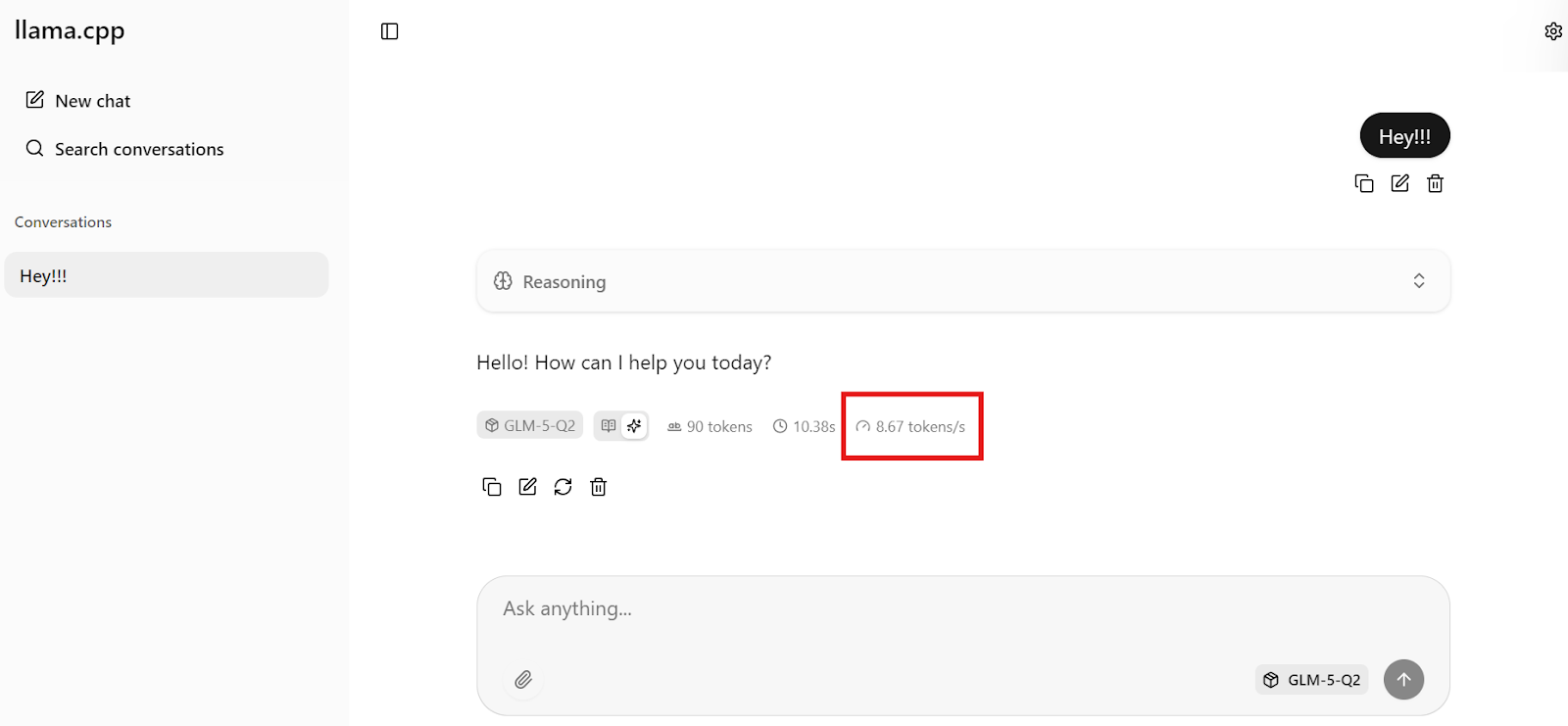
Her şeyin çalıştığını doğrulamak için “Hey!!” gibi basit bir mesaj gönderin. Modelin anında yanıt verdiğini görmelisiniz.
Bizim durumda çıkarım hızı yaklaşık saniyede 8.7 token civarındadır; GLM-5’in boyutu ve 281GB’lık kuantize checkpoint göz önüne alındığında bu mükemmel bir performanstır.
Aider, doğrudan proje klasörünüzün içinde çalışan, terminal tabanlı bir yapay zeka eş programlama aracıdır.
Onunla bir kodlama ortağı gibi sohbet edersiniz; depo genelinde dosyalar oluşturabilir, düzenleyebilir ve yeniden düzenleyebilir; tüm bunları gerçek kod tabanınız ve git iş akışınıza dayandırır.
Ayrıca herhangi bir OpenAI uyumlu API uç noktasına bağlanmayı destekler; bu da onu yerel llama.cpp sunucumuza karşı çalıştırmak için harika bir seçenek yapar.
Önce Aider’ı kurun:
pip install -U aider-chatArdından Aider’ı yerel llama.cpp OpenAI uyumlu sunucunuza yönlendirin. Sahte bir anahtar ayarlıyoruz çünkü llama.cpp gerçek bir OpenAI anahtarı gerektirmez:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEŞimdi yeni bir demo proje klasörü oluşturun (Aider’ın çalışacağı temiz bir depo olsun):
mkdir -p glm5-demo-app
cd glm5-demo-appSon olarak Aider’ı başlatın ve daha önce açığa çıkardığımız model takma adını kullanarak GLM-5’e bağlayın:
aider --model openai/GLM-5 --no-show-model-warningsBu noktada Aider içinde sorduğunuz her şey yerel GLM-5 sunucunuz üzerinden yönlendirilecek ve Aider değişiklikleri doğrudan glm5-demo-app içindeki dosyalara uygulayacaktır.
 GLM-5’i Kodlama Ajanınız Olarak Kullanın
GLM-5’i Kodlama Ajanınız Olarak KullanınAider GLM-5’e bağlandıktan sonra, onu deponuz içinde bir kodlama ajanı gibi kullanabilirsiniz. Hızlı yanıt verdiğini doğrulamak için basit bir selamla başlayın.

Ardından buna benzer net bir görev istemi verin:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider önce bir plan önerecek, sonra düzenlemeleri uygulamak için izin isteyecektir.
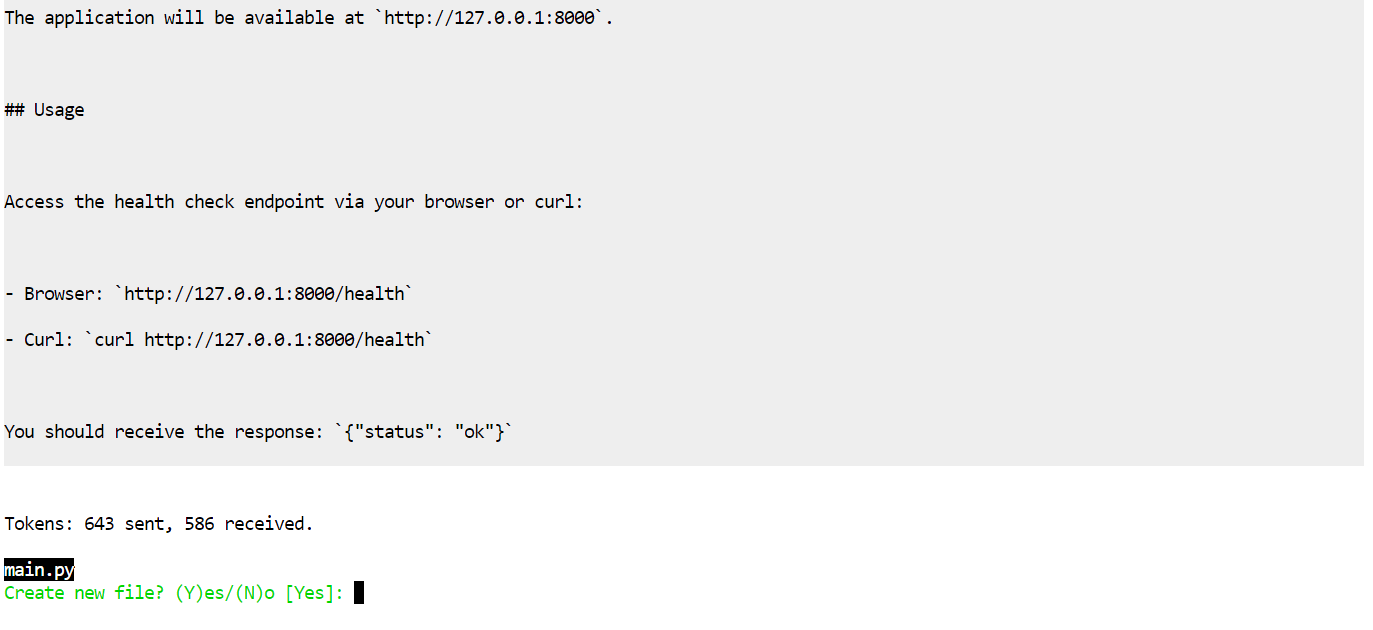
Düzenlemeleri kabul edin; dosyaları otomatik olarak oluşturacaktır.
GLM-5-UD-Q2_K_XL gibi 2-bit bir kuant üzerinde küçük hatalar görebilirsiniz; örneğin pip install -r requirements.txt gibi bir dosya oluşturmak; bu bir hatadır. Tam model bu tür hataları yapma olasılığı daha düşüktür; ancak 2-bit model de hızlı bir insan gözden geçirmesiyle gayet kullanılabilirdir.
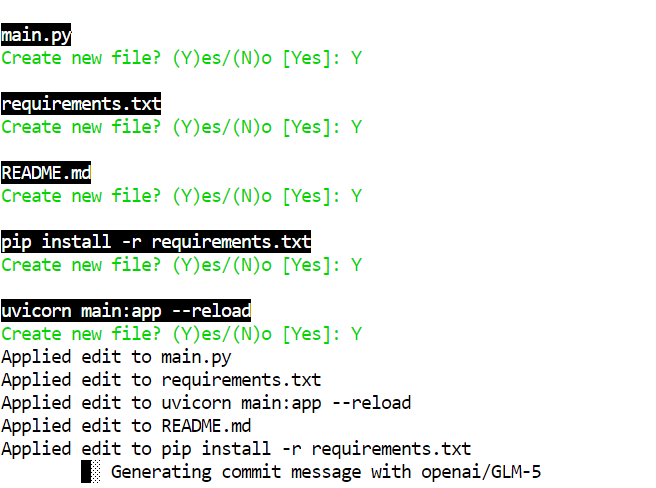
Aider proje yazımını tamamladıktan sonra, klasöre geçin, bağımlılıkları kurun ve sunucuyu çalıştırın:
cd glm5-demo-app/pip install -r requirements.txtFastAPI uygulamasını Uvicorn ile başlatın:
uvicorn main:app --reloadSunucu 8000 portunda çalışacaktır.
Sağlık uç noktasını test edin:
curl -s http://127.0.0.1:8000/healthŞunu almalısınız:
{"status":"ok"}GLM-5, özellikle açık kaynak performansını mülkiyetli modellere yaklaştırdığı ve derin akıl yürütme, ajan iş akışları ve kodlama görevleri için tasarlandığı için, yapay zeka topluluğunda hızla en çok konuşulan açık-ağırlıklı modellerden biri haline geliyor.
Tüm bu heyecana rağmen, tam ölçekli modelleri yerelde çalıştırmak hâlâ sıradan kullanıcılar için bir zorluktur.
Kuantizasyona rağmen, GLM-5 gibi modeller yüzlerce gigabayt bellek ve hızlı GPU’lar gerektirir; bu da pek çok kişinin ev makinesinde bulunmaz.
Bu, çoğu kişinin ya bulut GPU podlarına (bu eğitimdeki H200 kurulumu gibi) güvenmesi ya da barındırılan API hizmetlerini kullanması anlamına gelir.
GLM-5’in açık-ağırlıklı doğası, kendi örneğinizi mülkiyetli API sağlayıcılarına bağımlı olmadan barındırıp kontrol etmenize olanak tanıdığı için güçlüdür; ancak aynı zamanda yapay zekâda açık kaynağın herkes için sihirli bir şekilde “dizüstünde çalışır” anlamına gelmediğini de vurgular.
Bu eğitimde, Runpod H200 GPU üzerinde GLM-5’in 2-bit kuantize sürümünü kullanarak bu donanım engellerinin nasıl aşılacağını gördük. Ortamı kurmayı, llama.cpp’yi CUDA desteğiyle derlemeyi, modeli verimli şekilde indirmeyi, çıkarım sunucusunu başlatmayı, tarayıcı arayüzüyle test etmeyi ve son olarak Aider gibi bir kodlama aracını gerçek geliştirme görevleri için GLM-5’i bir ajan olarak kullanacak şekilde bağlamayı adım adım ele aldık.
En İyi Yapay Zeka Kursları
Program
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
