

Tracks
Kỹ sư AI cấp bậc Associate dành cho các nhà khoa học dữ liệu
40 giờ
GLM-5 là mô hình open-reasoning mới nhất của Z.ai và nhanh chóng thu hút sự chú ý nhờ hiệu năng mạnh trong lập trình, quy trình tác tử và trò chuyện ngữ cảnh dài.
Nhiều nhà phát triển đã dùng nó để tạo website một lần nhắc, xây app nhỏ và thử nghiệm với tác tử AI cục bộ.
Thách thức là GLM-5 là một mô hình rất lớn, và chạy cục bộ trên phần cứng tiêu dùng là không thực tế. Ngay cả các bản lượng tử hóa cũng cần hàng trăm gigabyte bộ nhớ và một cấu hình GPU đủ mạnh.
Trong hướng dẫn này, chúng tôi sẽ đi qua cách thực tế để chạy GLM-5 cục bộ bằng bản GGUF 2-bit trên một pod NVIDIA H200, phục vụ qua llama.cpp, và kết nối với Aider để bạn có thể dùng GLM-5 như một tác tử lập trình thực thụ trong chính dự án của mình.
Tôi cũng khuyên bạn xem hướng dẫn của chúng tôi về chạy GLM 4.7 Flash cục bộ.
Trước khi chạy GLM-5 cục bộ, bạn sẽ cần đúng biến thể mô hình, đủ bộ nhớ để tải, và một ngăn xếp phần mềm GPU hoạt động.
Yêu cầu phần cứng phụ thuộc vào kích thước lượng tử hóa:
Để đạt hiệu năng tốt nhất, tổng VRAM + RAM hệ thống của bạn nên xấp xỉ kích thước lượng tử hóa. Nếu không, llama.cpp có thể offload xuống SSD, nhưng suy luận sẽ chậm hơn. Dùng --fit trong llama.cpp để tối đa hóa việc sử dụng GPU.
Trong thiết lập của chúng tôi, chúng tôi chạy GLM-5-UD-Q2_K_XL trên NVIDIA H200, với đủ VRAM và RAM hệ thống để chứa mô hình hiệu quả.
Điều kiện phần mềm:
Bên dưới là hướng dẫn từng bước để chạy GLM-5 cục bộ:
Ngay cả bản 1-bit của GLM-5 cũng quá lớn để chạy trên hầu hết laptop tiêu dùng, nên trong hướng dẫn này, tôi sẽ dùng Runpod với GPU NVIDIA H200.
Bắt đầu bằng cách tạo một pod mới và chọn template PyTorch mới nhất.
Sau đó nhấp Edit để điều chỉnh cài đặt pod:
Khi mọi thứ đã ổn, xem lại tóm tắt pod và nhấp Deploy On-Demand.
Khi pod sẵn sàng, mở JupyterLab, khởi chạy một Terminal và làm việc từ đó. Dùng terminal của Jupyter tiện lợi vì bạn có thể chạy nhiều phiên mượt mà mà không cần dựa vào SSH.
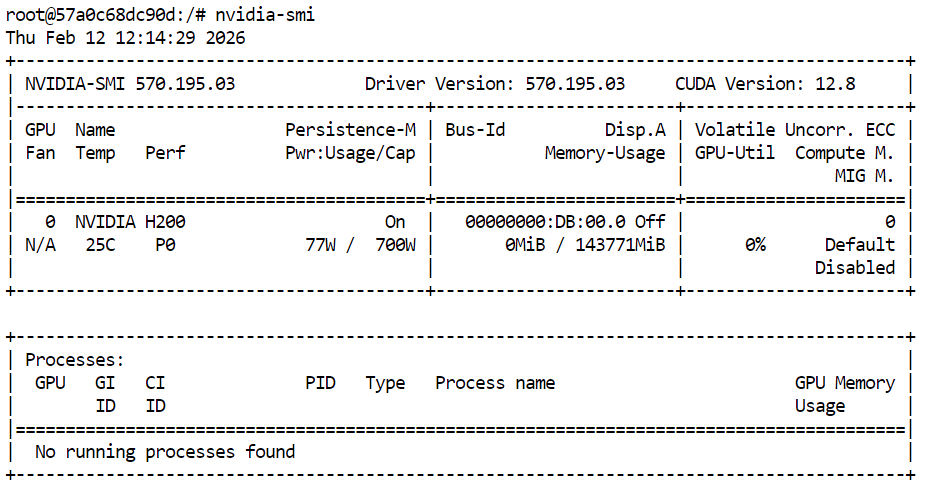
Trước hết, xác nhận GPU khả dụng:
nvidia-smi Bạn sẽ thấy H200 được liệt kê trong đầu ra.
Tiếp theo, cài đặt các gói Linux cần thiết để clone và build llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqGiờ khi môi trường Runpod đã sẵn sàng và GPU hoạt động, bước tiếp theo là cài đặt và biên dịch llama.cpp với tăng tốc CUDA để GLM-5 có thể chạy hiệu quả trên H200.
Trước tiên, chuyển vào thư mục workspace và clone kho chính thức của llama.cpp:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppTại thời điểm này, cần lưu ý rằng bản phát hành ổn định mới nhất của llama.cpp vẫn chưa hỗ trợ đầy đủ GLM-5 ngay lập tức. Bạn cần kéo một pull request upstream cụ thể chứa các thay đổi gần đây cần thiết cho khả năng tương thích đúng.
Fetch và checkout nhánh đã cập nhật:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Tiếp theo, chúng ta cấu hình hệ thống build để biên dịch llama.cpp với CUDA bật, cho phép mô hình dùng tăng tốc GPU thay vì chạy hoàn toàn trên CPU.
Chạy CMake với cờ CUDA bật:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Lệnh này tạo một thư mục build/ riêng và đảm bảo các binary máy chủ của llama.cpp sẽ hỗ trợ chạy trên GPU NVIDIA.
Khi cấu hình xong, build mục tiêu llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Bước này có thể mất vài phút tùy pod, nhưng sau khi hoàn tất bạn sẽ có một binary máy chủ hỗ trợ CUDA sẵn sàng để chạy GLM-5.
Cuối cùng, sao chép các tệp thực thi đã biên dịch vào thư mục chính để dễ truy cập:
cp llama.cpp/build/bin/llama-* llama.cppKhi llama.cpp đã biên dịch xong, bước tiếp theo là tải tệp mô hình GLM-5 GGUF từ Hugging Face.
Do các checkpoint mô hình này cực lớn, điều quan trọng là bật các phương thức tải nhanh nhất có thể.
Hugging Face cung cấp các công cụ tùy chọn như hf_xet và hf_transfer, giúp tăng đáng kể tốc độ tải, đặc biệt trên máy cloud như Runpod.
Bắt đầu bằng cách cài các tiện ích tải của Hugging Face:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferCác gói này cho phép tải song song nhanh hơn và hiệu năng tốt hơn khi kéo hàng trăm gigabyte shard mô hình.
Giờ hãy tải biến thể mô hình lượng tử hóa cụ thể dùng trong hướng dẫn này. Chúng ta chỉ muốn các tệp UD-Q2_K_XL, không phải toàn bộ tải lên:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Lệnh này sẽ lưu mô hình trực tiếp vào thư mục models/GLM-5-GGUF.
Trong thiết lập của chúng tôi, tốc độ tải đạt khoảng 1,2 GB/s, vì chúng tôi đã bật hf_xet và cung cấp token Hugging Face từ trước. Tải ẩn danh thường chậm hơn nhiều, nên thiết lập xác thực và tăng tốc truyền tải tạo khác biệt lớn khi làm việc với mô hình ở quy mô này.
Giờ khi mô hình đã tải và llama.cpp đã biên dịch với hỗ trợ CUDA, chúng ta có thể khởi động GLM-5 bằng llama-server tích hợp.
Chạy lệnh sau để khởi chạy máy chủ:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Một vài tham số quan trọng cần hiểu:
--host 0.0.0.0 mở máy chủ để có thể truy cập từ trình duyệt--port 8080 khớp với cổng chúng ta đã mở trước đó trên Runpod--fit on đảm bảo tận dụng tối đa GPU trước khi đổ sang RAM--ctx-size 16384 đặt cửa sổ ngữ cảnh cho suy luận--flash-attn auto bật kernel attention nhanh hơn khi được hỗ trợKhi bạn khởi động máy chủ, bạn sẽ thấy llama.cpp dùng gần như toàn bộ bộ nhớ GPU khả dụng, với các lớp mô hình còn lại được offload sang RAM hệ thống. Điều này là bình thường và hoạt động tốt trên thiết lập H200.
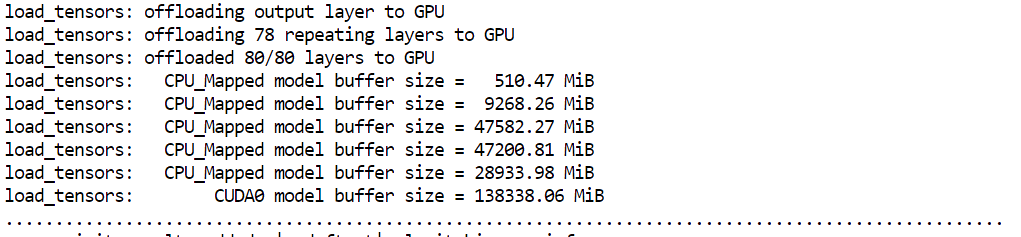
Mô hình sẽ tải và bắt đầu phục vụ trong vòng chưa đầy một phút. Nếu pod của bạn mất nhiều thời gian hơn đáng kể, có thể có vấn đề với instance. Khi đó, thường nhanh hơn nếu dừng pod và khởi chạy cái mới.

Khi máy chủ đã chạy, hãy kiểm tra GLM-5 khả dụng bằng cách truy vấn endpoint tương thích OpenAI:
curl -s http://127.0.0.1:8080/v1/models | jqBạn sẽ thấy "GLM-5" được liệt kê trong phản hồi, xác nhận mô hình đã tải và sẵn sàng dùng.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Khi máy chủ đã chạy, bạn có thể kiểm thử GLM-5 trực tiếp qua giao diện Chat tích hợp của llama.cpp.
Thông thường, WebUI khả dụng cục bộ tại: http://127.0.0.1:8080
Tuy nhiên, vì chúng ta đang chạy trên Runpod trên cloud, liên kết localhost này sẽ không hoạt động từ máy của bạn.
Thay vào đó, vào bảng điều khiển Runpod và nhấp liên kết HTTP Service cho cổng 8080. Đây là URL công khai chuyển tiếp lưu lượng tới llama-server của bạn đang chạy.
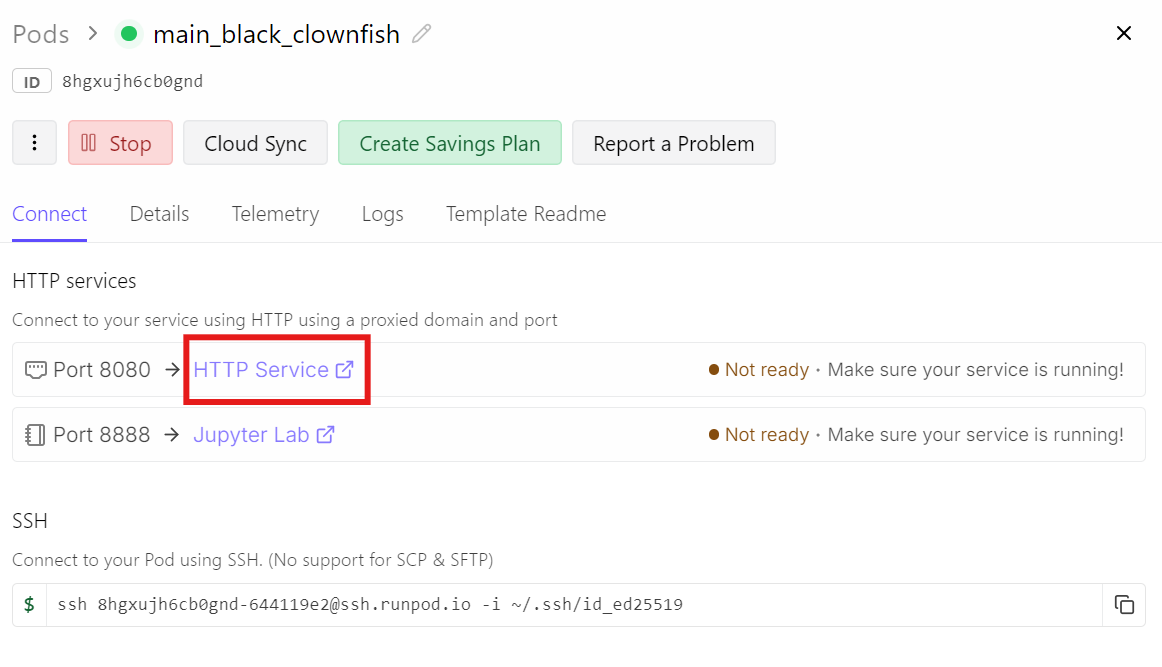 Mở liên kết đó sẽ đưa bạn tới Chat UI, với mô hình GLM-5 đã được tải sẵn và sẵn sàng.
Mở liên kết đó sẽ đưa bạn tới Chat UI, với mô hình GLM-5 đã được tải sẵn và sẵn sàng.
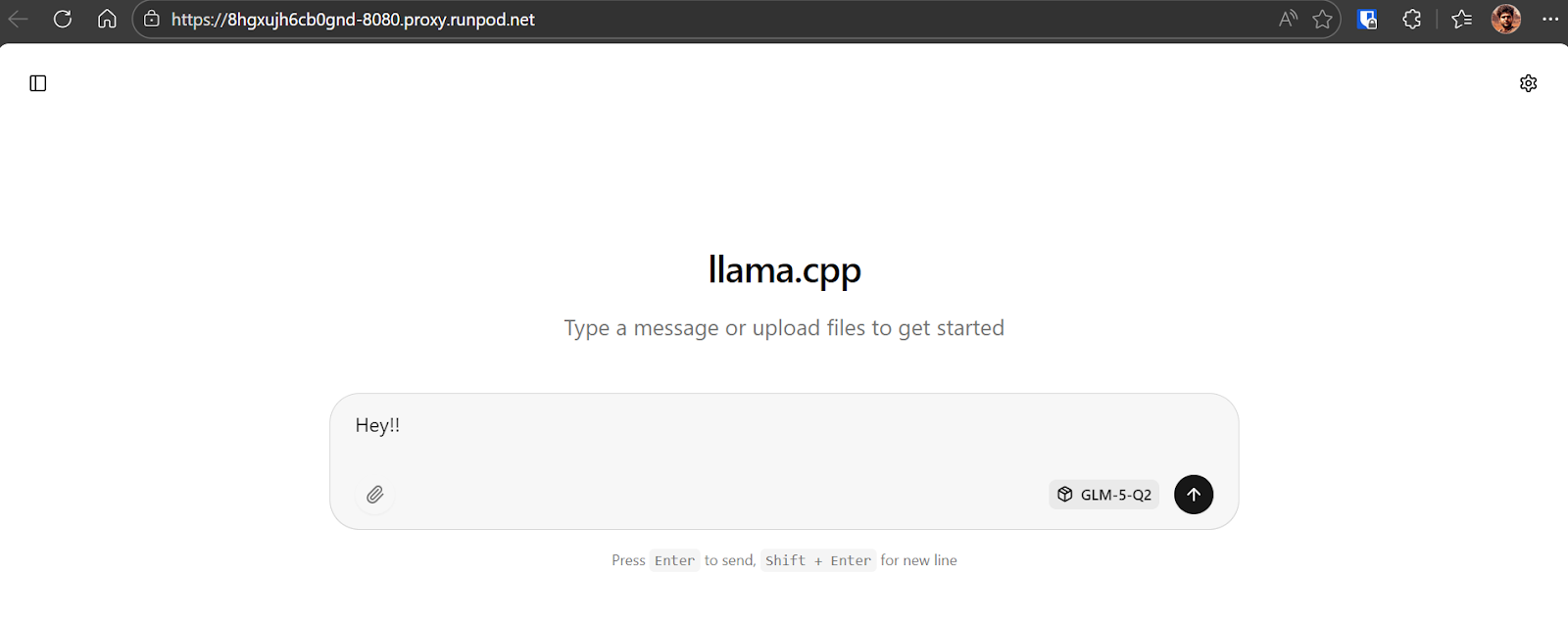
Để xác nhận mọi thứ hoạt động, hãy gửi một tin nhắn đơn giản như “Hey!!”. Bạn sẽ thấy mô hình phản hồi ngay lập tức.
Trong trường hợp của chúng tôi, suy luận chạy khoảng 8,7 token mỗi giây, là hiệu năng rất tốt nếu xét đến kích thước GLM-5 và checkpoint lượng tử hóa 281GB.
Aider là công cụ lập trình cặp AI dựa trên terminal hoạt động trực tiếp trong thư mục dự án của bạn.
Bạn trò chuyện với nó như một cộng sự lập trình, và nó có thể tạo, chỉnh sửa, tái cấu trúc tệp trên toàn repo, đồng thời bám sát codebase thực và quy trình git của bạn.
Nó cũng hỗ trợ kết nối tới bất kỳ endpoint API tương thích OpenAI, điều này khiến nó rất phù hợp để chạy với máy chủ llama.cpp cục bộ của chúng ta.
Trước tiên, cài đặt Aider:
pip install -U aider-chatTiếp theo, trỏ Aider tới máy chủ tương thích OpenAI của llama.cpp cục bộ. Chúng ta đặt một key giả vì llama.cpp không yêu cầu key OpenAI thật:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEGiờ hãy tạo một thư mục dự án demo mới (để Aider có một repo sạch để làm việc):
mkdir -p glm5-demo-app
cd glm5-demo-appCuối cùng, khởi động Aider và kết nối nó với GLM-5 bằng alias mô hình chúng ta đã công khai trước đó:
aider --model openai/GLM-5 --no-show-model-warningsTại thời điểm này, mọi thứ bạn yêu cầu trong Aider sẽ được định tuyến qua máy chủ GLM-5 cục bộ của bạn, và Aider sẽ áp dụng thay đổi trực tiếp vào các tệp trong glm5-demo-app.
 Dùng GLM-5 Là Tác Tử Lập Trình Của Bạn
Dùng GLM-5 Là Tác Tử Lập Trình Của BạnKhi Aider đã kết nối với GLM-5, bạn có thể dùng nó như một tác tử lập trình trong repo của bạn. Bắt đầu với một lời chào đơn giản để xác nhận nó phản hồi nhanh.

Sau đó, đưa ra một prompt nhiệm vụ rõ ràng như sau:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider sẽ đề xuất một kế hoạch trước, sau đó xin phép áp dụng các chỉnh sửa.
Chấp nhận các chỉnh sửa, và nó sẽ tự động tạo tệp.
Với bản lượng tử 2-bit như GLM-5-UD-Q2_K_XL, bạn có thể thấy lỗi nhỏ, ví dụ tạo một tệp như pip install -r requirements.txt, đây là lỗi. Bản đầy đủ ít có khả năng mắc lỗi này hơn, nhưng bản 2-bit vẫn rất hữu dụng nếu có rà soát nhanh của con người.
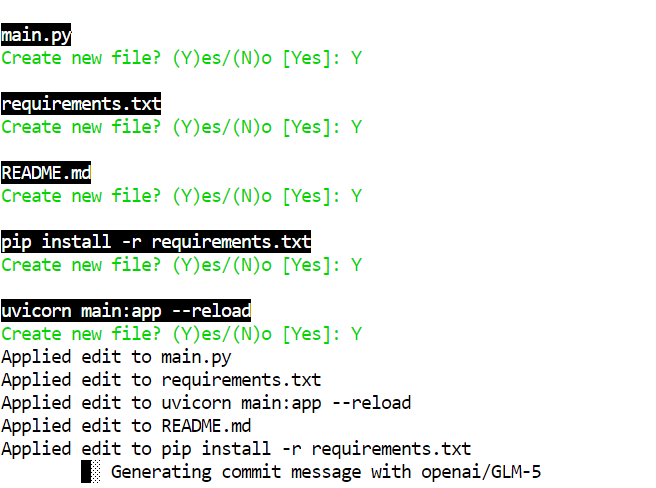
Sau khi Aider viết xong dự án, chuyển vào thư mục, cài phụ thuộc, và chạy máy chủ:
cd glm5-demo-app/pip install -r requirements.txtKhởi động ứng dụng FastAPI với Uvicorn:
uvicorn main:app --reloadMáy chủ sẽ chạy trên cổng 8000.
Kiểm thử endpoint health:
curl -s http://127.0.0.1:8000/healthBạn sẽ nhận được:
{"status":"ok"}GLM-5 đang nhanh chóng trở thành một trong những mô hình open-weight được bàn luận nhiều nhất trong cộng đồng AI, đặc biệt vì nó đẩy hiệu năng nguồn mở tiến gần hơn tới các mô hình độc quyền, đồng thời được thiết kế cho suy luận sâu, quy trình tác tử và nhiệm vụ lập trình.
Bất chấp sự cường điệu, chạy mô hình quy mô đầy đủ cục bộ vẫn là thách thức với người dùng phổ thông.
Ngay cả khi lượng tử hóa, các mô hình như GLM-5 cần hàng trăm gigabyte bộ nhớ và GPU nhanh, điều mà nhiều người không có trên máy ở nhà.
Điều này có nghĩa hầu hết mọi người hoặc dựa vào pod GPU trên cloud (như thiết lập H200 trong hướng dẫn này) hoặc dùng dịch vụ API được host sẵn.
Tính open-weight của GLM-5 rất mạnh vì nó cho phép bạn tự host và kiểm soát instance của mình mà không phụ thuộc nhà cung cấp API độc quyền, nhưng nó cũng nhấn mạnh lý do vì sao nguồn mở trong AI không đồng nghĩa “chạy trên laptop” cho mọi người.
Trong hướng dẫn này, chúng ta đã thấy cách vượt qua rào cản phần cứng bằng bản GLM-5 lượng tử 2-bit trên GPU Runpod H200. Chúng ta đã đi qua thiết lập môi trường, biên dịch llama.cpp với hỗ trợ CUDA, tải mô hình hiệu quả, khởi chạy máy chủ suy luận, kiểm thử qua giao diện trình duyệt, và cuối cùng kết nối công cụ lập trình như Aider để dùng GLM-5 như một tác tử cho các nhiệm vụ phát triển thực tế.
Các khóa học AI hàng đầu
Tracks