

Lernpfad
Associate AI Engineer für Datenwissenschaftler
40 Std.
GLM-5 ist Z.ai’s neuestes Open-Reasoning-Modell und hat dank seiner starken Leistung beim Programmieren, in Agent-Workflows und in langen Chats schnell Aufmerksamkeit erregt.
Viele Entwickler nutzen es bereits, um Websites in einem Rutsch zu erstellen, kleine Apps zu bauen und mit lokalen KI-Agenten zu experimentieren.
Die Herausforderung: GLM-5 ist ein sehr großes Modell, und die lokale Ausführung ist auf Consumer-Hardware kaum realistisch. Selbst quantisierte Versionen benötigen Hunderte Gigabyte Speicher und eine leistungsfähige GPU-Umgebung.
In diesem Tutorial zeigen wir einen pragmatischen Weg, GLM-5 lokal mit einer 2-Bit-GGUF-Quantisierung auf einem NVIDIA-H200-Pod auszuführen, es über llama.cpp bereitzustellen und mit Aider zu verbinden, sodass du GLM-5 als echten Coding-Agenten direkt in deinen Projekten einsetzen kannst.
Ich empfehle außerdem unseren Leitfaden zum lokalen Ausführen von GLM 4.7 Flash.
Bevor du GLM-5 lokal ausführst, brauchst du die passende Modellvariante, genug Speicher zum Laden und eine funktionierende GPU-Software-Stack.
Hardware-Anforderungen je nach Quantisierungsgröße:
Für die beste Performance sollten VRAM + System-RAM zusammen in etwa der Quantisierungsgröße entsprechen. Andernfalls kann llama.cpp auf SSD auslagern, was die Inferenz jedoch verlangsamt. Verwende --fit in llama.cpp, um die GPU-Auslastung zu maximieren.
In unserem Setup betreiben wir GLM-5-UD-Q2_K_XL auf einer NVIDIA H200 mit ausreichend VRAM und System-RAM, um das Modell effizient zu laden.
Software-Voraussetzungen:
Hier findest du die Schritt-für-Schritt-Anleitung, um GLM-5 lokal auszuführen:
Selbst die 1-Bit-Version von GLM-5 ist für die meisten Consumer-Laptops zu groß. Für dieses Tutorial nutze ich daher Runpod mit einer NVIDIA H200 GPU.
Erstelle zunächst einen neuen Pod und wähle das neueste PyTorch-Template.
Klicke dann auf Edit, um die Pod-Einstellungen anzupassen:
Wenn alles passt, prüfe die Pod-Übersicht und klicke auf Deploy On-Demand.
Sobald der Pod bereit ist, öffne JupyterLab, starte ein Terminal und arbeite von dort. Das Jupyter-Terminal ist praktisch, weil du mehrere Sessions reibungslos ohne SSH laufen lassen kannst.
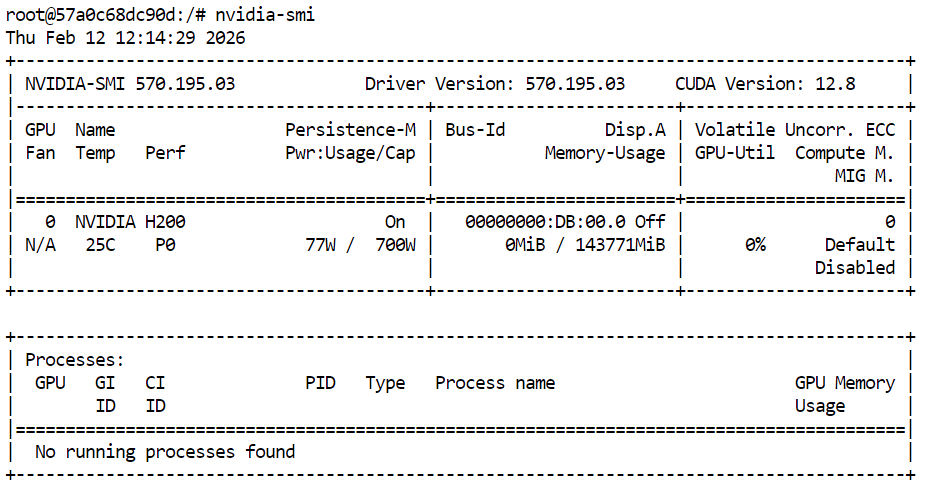
Prüfe zuerst, ob die GPU verfügbar ist:
nvidia-smi Du solltest die H200 in der Ausgabe sehen.
Installiere als Nächstes die benötigten Linux-Pakete zum Klonen und Bauen von llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqJetzt, da die Runpod-Umgebung steht und die GPU funktioniert, installierst und kompilierst du llama.cpp mit CUDA-Beschleunigung, damit GLM-5 effizient auf der H200 läuft.
Wechsle zunächst ins Workspace-Verzeichnis und klone das offizielle llama.cpp-Repository:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppWichtig: Der neueste stabile Release von llama.cpp unterstützt GLM-5 noch nicht vollständig out of the box. Du musst einen bestimmten Upstream-Pull-Request einziehen, der die notwendigen Änderungen für die Kompatibilität enthält.
Hole und checke den aktualisierten Branch aus:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Als Nächstes konfigurieren wir das Build-System, damit llama.cpp mit aktiviertem CUDA kompiliert wird. So nutzt das Modell die GPU statt komplett auf der CPU zu laufen.
Führe CMake mit aktiviertem CUDA-Flag aus:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Damit wird ein eigenes build/-Verzeichnis erstellt und sichergestellt, dass die llama.cpp-Server-Binaries die Ausführung auf NVIDIA-GPUs unterstützen.
Sobald die Konfiguration steht, baue das Target llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Dieser Schritt kann je nach Pod ein paar Minuten dauern. Danach hast du ein CUDA-fähiges Server-Binary, das bereit ist, GLM-5 auszuführen.
Kopiere zum Schluss die kompilierten Executables ins Hauptverzeichnis für den bequemen Zugriff:
cp llama.cpp/build/bin/llama-* llama.cppNachdem llama.cpp kompiliert ist, lädst du als Nächstes die GLM-5-GGUF-Modelldateien von Hugging Face herunter.
Da diese Checkpoints extrem groß sind, solltest du die schnellsten Download-Methoden aktivieren.
Hugging Face bietet optionale Tools wie hf_xet und hf_transfer, die die Downloadgeschwindigkeit deutlich erhöhen, vor allem auf Cloud-Maschinen wie Runpod.
Installiere zunächst die erforderlichen Hugging-Face-Downloadtools:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferDiese Pakete ermöglichen schnellere parallele Downloads und bessere Performance beim Herunterladen von Hunderten Gigabyte an Modell-Shards.
Lade nun die in diesem Tutorial genutzte quantisierte Modellvariante herunter. Wir wollen nur die UD-Q2_K_XL-Dateien, nicht den kompletten Upload:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Das Modell wird direkt im Verzeichnis models/GLM-5-GGUF gespeichert.
In unserem Setup erreichen die Downloads ca. 1,2 GB/s, weil wir hf_xet aktiviert und zuvor einen Hugging-Face-Token hinterlegt haben. Anonyme Downloads sind meist deutlich langsamer – Authentifizierung und Transferbeschleunigung machen bei dieser Modellgröße einen großen Unterschied.
Nachdem das Modell heruntergeladen und llama.cpp mit CUDA-Unterstützung kompiliert ist, können wir GLM-5 mit dem integrierten llama-server starten.
Starte den Server mit folgendem Befehl:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Einige wichtige Argumente:
--host 0.0.0.0 macht den Server von außen erreichbar--port 8080 entspricht dem zuvor in Runpod geöffneten Port--fit on sorgt für maximale GPU-Nutzung, bevor auf RAM ausgelagert wird--ctx-size 16384 setzt das Kontextfenster für die Inferenz--flash-attn auto aktiviert schnellere Attention-Kernel, wenn verfügbarBeim Start nutzt llama.cpp nahezu den gesamten verfügbaren GPU-Speicher; verbleibende Modellschichten werden in den System-RAM ausgelagert. Das ist zu erwarten und funktioniert auf H200-Setups gut.
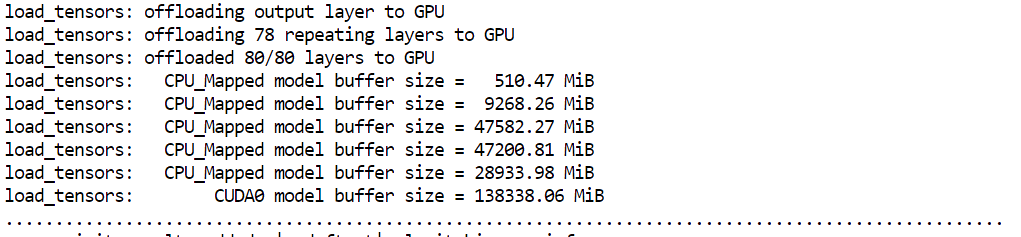
Das Modell sollte in unter einer Minute laden und Anfragen bedienen. Dauert es deutlich länger, könnte es an der Instanz liegen – dann ist es meist schneller, den Pod zu beenden und neu zu starten.

Wenn der Server läuft, prüfe die Verfügbarkeit von GLM-5 über den OpenAI-kompatiblen Endpoint:
curl -s http://127.0.0.1:8080/v1/models | jqDu solltest in der Antwort "GLM-5" sehen – damit ist bestätigt, dass das Modell geladen und einsatzbereit ist.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Wenn der Server läuft, kannst du GLM-5 direkt über die integrierte llama.cpp-Chat-UI testen.
Normalerweise ist die WebUI lokal unter: http://127.0.0.1:8080 erreichbar.
Da wir jedoch auf Runpod in der Cloud laufen, funktioniert dieser Localhost-Link von deinem Rechner aus nicht.
Gehe stattdessen in dein Runpod-Dashboard und klicke auf den Link HTTP Service für Port 8080. Das ist die öffentliche URL, die auf deinen laufenden llama-server weiterleitet.
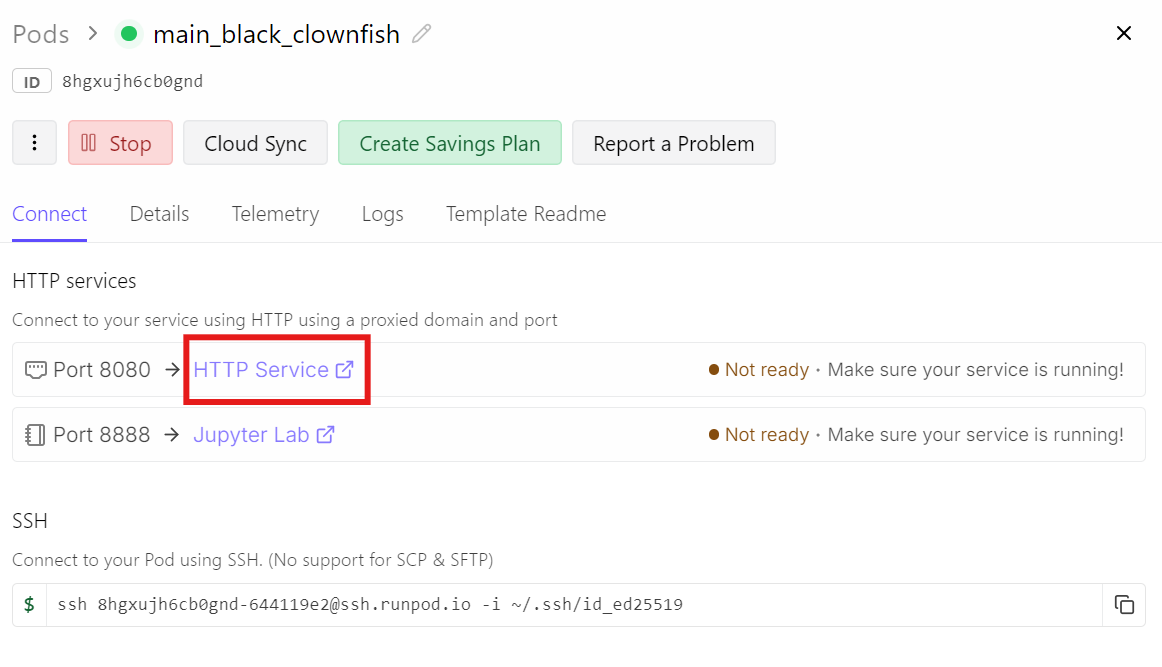 Beim Öffnen landest du in der Chat-UI, mit dem bereits geladenen und einsatzbereiten GLM-5-Modell.
Beim Öffnen landest du in der Chat-UI, mit dem bereits geladenen und einsatzbereiten GLM-5-Modell.
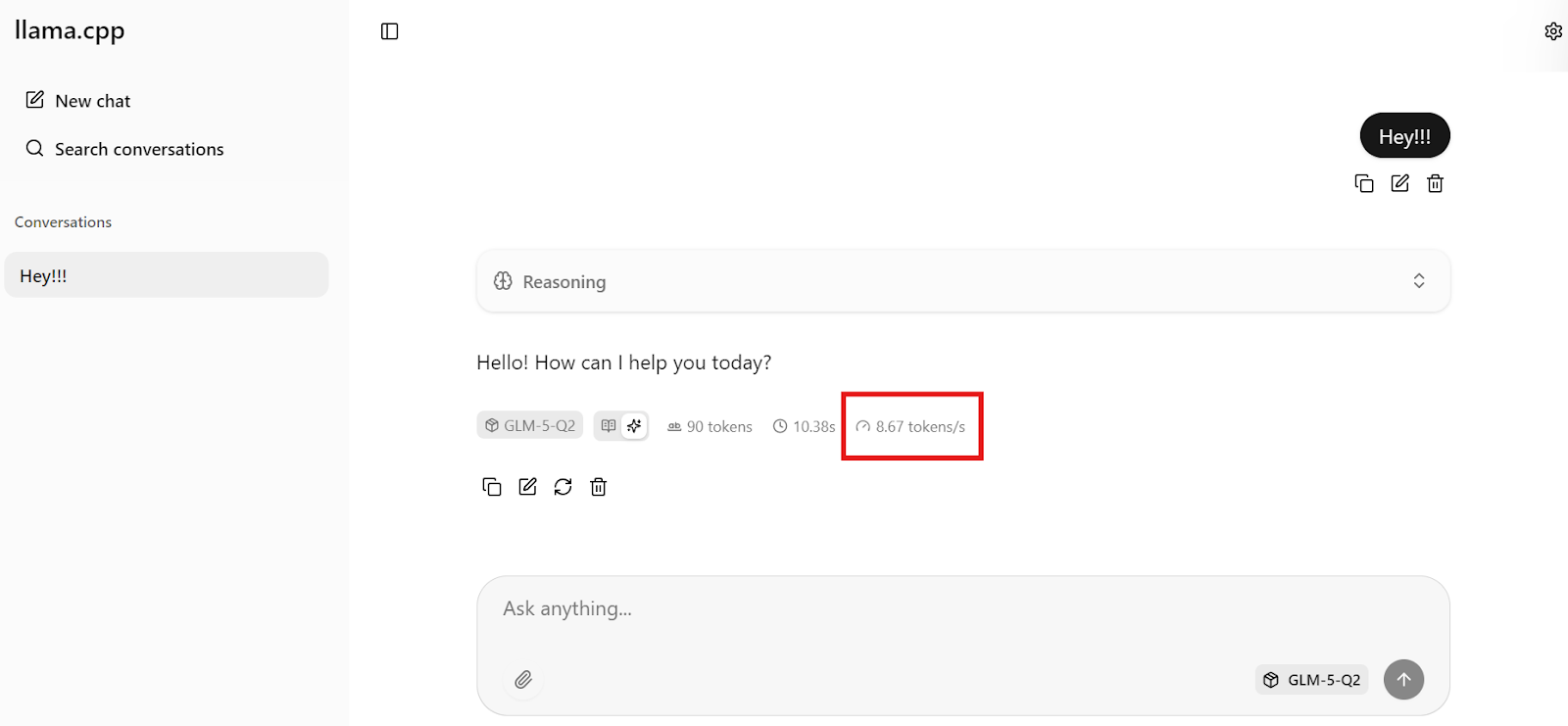
Sende zur Kontrolle eine einfache Nachricht wie „Hey!!“. Das Modell sollte direkt reagieren.
Bei uns läuft die Inferenz mit rund 8,7 Tokens pro Sekunde – stark, gemessen an der Größe von GLM-5 und dem 281-GB-quantisierten Checkpoint.
Aider ist ein terminalbasiertes Pair-Programming-Tool mit KI, das direkt in deinem Projektordner arbeitet.
Du unterhältst dich damit wie mit einem Coding-Partner. Es kann Dateien im gesamten Repo erstellen, bearbeiten und refaktorisieren – stets auf Basis deines echten Codebestands und Git-Workflows.
Es unterstützt zudem jede OpenAI-kompatible API, was es ideal macht, um gegen unseren lokalen llama.cpp-Server zu laufen.
Installiere zuerst Aider:
pip install -U aider-chatRichte Aider dann auf deinen lokalen, OpenAI-kompatiblen llama.cpp-Server aus. Wir setzen einen Dummy-Key, da llama.cpp keinen echten OpenAI-Key verlangt:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEErstelle jetzt einen frischen Demo-Projektordner (damit Aider ein sauberes Repo hat):
mkdir -p glm5-demo-app
cd glm5-demo-appStarte abschließend Aider und verbinde es mit GLM-5 über den zuvor vergebenen Alias:
aider --model openai/GLM-5 --no-show-model-warningsAb jetzt läuft alles, was du in Aider fragst, über deinen lokalen GLM-5-Server, und Aider nimmt Änderungen direkt in den Dateien von glm5-demo-app vor.
 Nutze GLM-5 als deinen Coding-Agenten
Nutze GLM-5 als deinen Coding-AgentenSobald Aider mit GLM-5 verbunden ist, kannst du es wie einen Coding-Agenten in deinem Repo verwenden. Starte mit einer kurzen Begrüßung, um die Reaktionszeit zu prüfen.

Gib ihm anschließend eine klare Aufgabe, zum Beispiel:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider schlägt zunächst einen Plan vor und fragt dann um Erlaubnis, die Änderungen anzuwenden.
Bestätige die Änderungen, und die Dateien werden automatisch erzeugt.
Bei einer 2-Bit-Quantisierung wie GLM-5-UD-Q2_K_XL können kleine Fehler auftreten, etwa dass eine Datei wie pip install -r requirements.txt angelegt wird – das ist natürlich falsch. Das Vollmodell macht solche Fehler seltener, doch auch das 2-Bit-Modell ist mit kurzem Human-in-the-Loop sehr gut nutzbar.
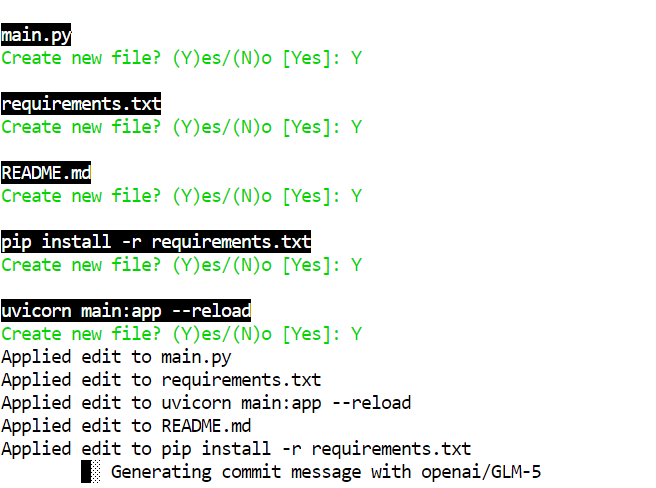
Wenn Aider das Projekt fertig geschrieben hat, wechsle in den Ordner, installiere die Abhängigkeiten und starte den Server:
cd glm5-demo-app/pip install -r requirements.txtStarte die FastAPI-App mit Uvicorn:
uvicorn main:app --reloadDer Server läuft auf Port 8000.
Teste den Health-Endpoint:
curl -s http://127.0.0.1:8000/healthDu solltest Folgendes erhalten:
{"status":"ok"}GLM-5 entwickelt sich rasant zu einem der meistdiskutierten Open-Weight-Modelle in der KI-Community, weil es die Open-Source-Performance näher an proprietäre Modelle bringt und zugleich für Deep Reasoning, agentische Workflows und Coding-Aufgaben ausgelegt ist.
Trotz des Hypes ist das lokale Ausführen von großen Modellen für die meisten weiterhin eine Hürde.
Selbst mit Quantisierung verlangen Modelle wie GLM-5 Hunderte Gigabyte Speicher und schnelle GPUs – etwas, das viele zu Hause nicht haben.
Die meisten greifen daher auf Cloud-GPU-Pods (wie das H200-Setup in diesem Tutorial) oder gehostete API-Services zurück.
Der Open-Weight-Charakter von GLM-5 ist stark, weil du deine eigene Instanz hosten und kontrollieren kannst, ohne von proprietären API-Anbietern abzuhängen. Gleichzeitig zeigt er aber auch, dass Open Source in der KI nicht automatisch bedeutet, dass es „auf dem Laptop“ für alle läuft.
In diesem Tutorial haben wir gezeigt, wie man diese Hardware-Hürden mit einer 2-Bit-quantisierten Version von GLM-5 auf einer Runpod-H200-GPU überwindet. Wir sind die Einrichtung der Umgebung durchgegangen, das Kompilieren von llama.cpp mit CUDA-Unterstützung, das effiziente Herunterladen des Modells, das Starten des Inferenzservers, das Testen über die Browser-UI und schließlich die Verbindung eines Coding-Tools wie Aider, um GLM-5 als Agent für echte Entwicklungsaufgaben zu nutzen.
Top-Kurse zu KI
Lernpfad
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Kurtis Pykes
Tutorial
Sejal Jaiswal