

Programa
Engenheiro associado de IA para cientistas de dados
40 h
O GLM-5 é o novo modelo de open-reasoning da Z.ai e rapidamente ganhou atenção pelo ótimo desempenho em código, fluxos de trabalho com agentes e conversas de longo contexto.
Muitos desenvolvedores já estão usando para criar sites em uma tacada só, construir apps pequenos e experimentar com agentes de IA locais.
O desafio é que o GLM-5 é um modelo muito grande, e rodá-lo localmente não é realista em hardware de consumidor. Mesmo versões quantizadas exigem centenas de gigabytes de memória e uma GPU robusta.
Neste tutorial, vamos mostrar uma forma prática de rodar o GLM-5 localmente usando um quant GGUF de 2 bits em um pod com NVIDIA H200, servi-lo pelo llama.cpp e conectá-lo ao Aider para usar o GLM-5 como um agente de código de verdade dentro dos seus projetos.
Também recomendo conferir nosso guia sobre como rodar o GLM 4.7 Flash localmente.
Antes de rodar o GLM-5 localmente, você vai precisar da variante certa do modelo, memória suficiente para carregá-lo e uma stack de software de GPU funcionando.
Os requisitos de hardware dependem do tamanho do quant:
Para melhor desempenho, a soma de VRAM + RAM do sistema deve ficar próxima do tamanho do quant. Caso contrário, o llama.cpp pode fazer offload para o SSD, mas a inferência será mais lenta. Use --fit no llama.cpp para maximizar o uso da GPU.
Na nossa configuração, rodamos o GLM-5-UD-Q2_K_XL em uma NVIDIA H200, com VRAM e RAM suficientes para acomodar o modelo com eficiência.
Pré-requisitos de software:
Abaixo estão as instruções passo a passo para rodar o GLM-5 localmente:
Mesmo a versão de 1 bit do GLM-5 é grande demais para a maioria dos notebooks de consumo, então, para este tutorial, vou usar o Runpod com uma GPU NVIDIA H200.
Comece criando um novo pod e selecionando o template mais recente do PyTorch.
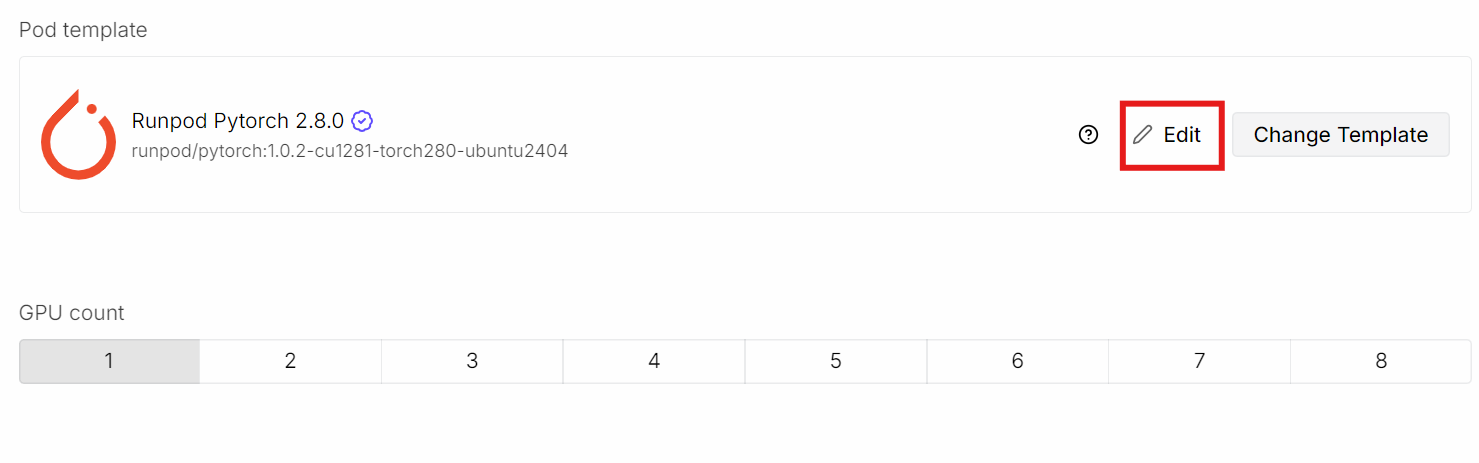
Depois clique em Edit para ajustar as configurações do pod:
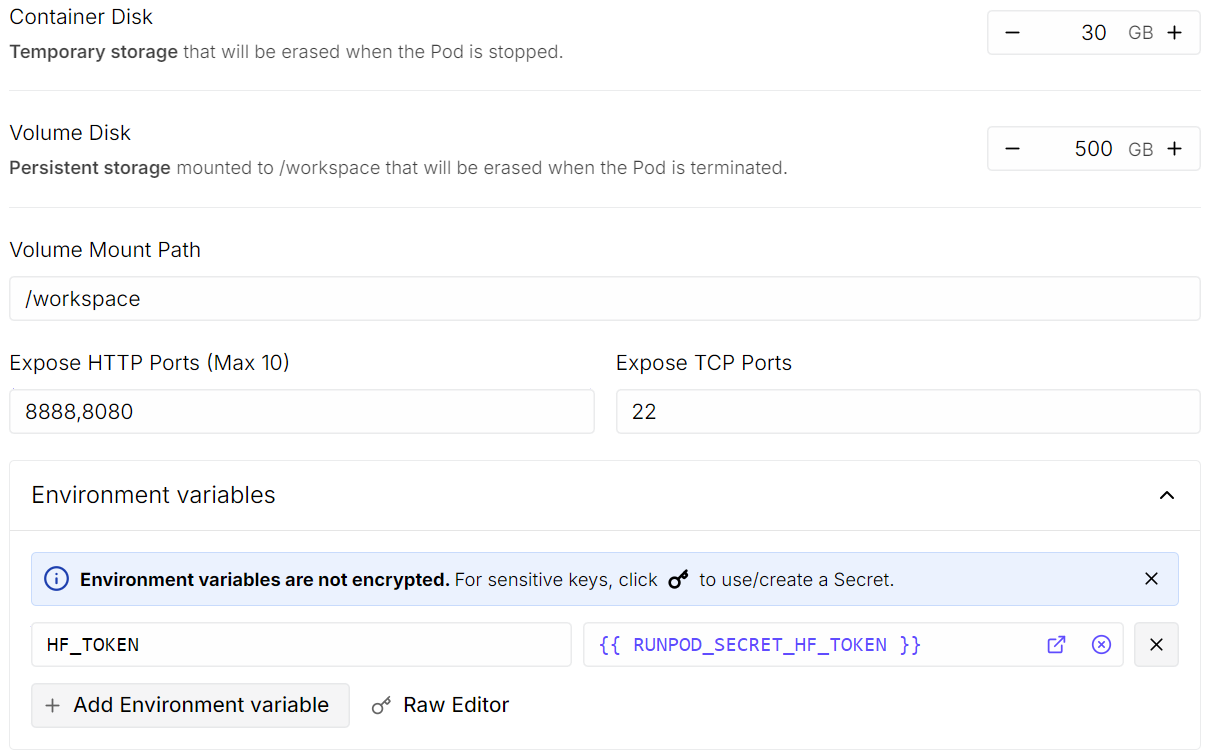
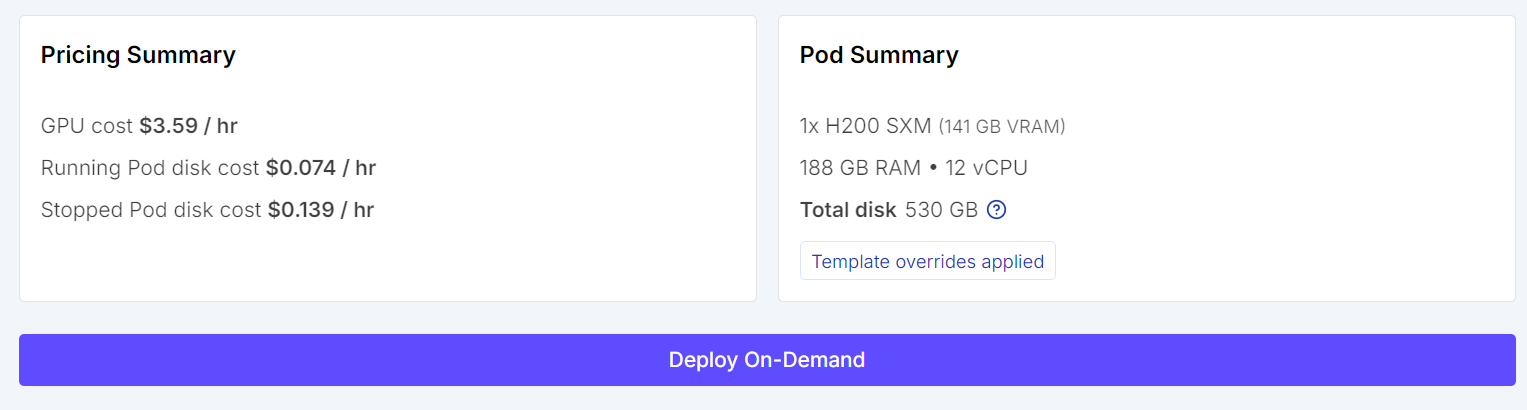
Quando tudo estiver certo, revise o resumo do pod e clique em Deploy On-Demand.
Quando o pod estiver pronto, abra o JupyterLab, inicie um Terminal e trabalhe por lá. Usar o terminal do Jupyter é prático porque você consegue rodar várias sessões de forma estável sem depender de SSH.
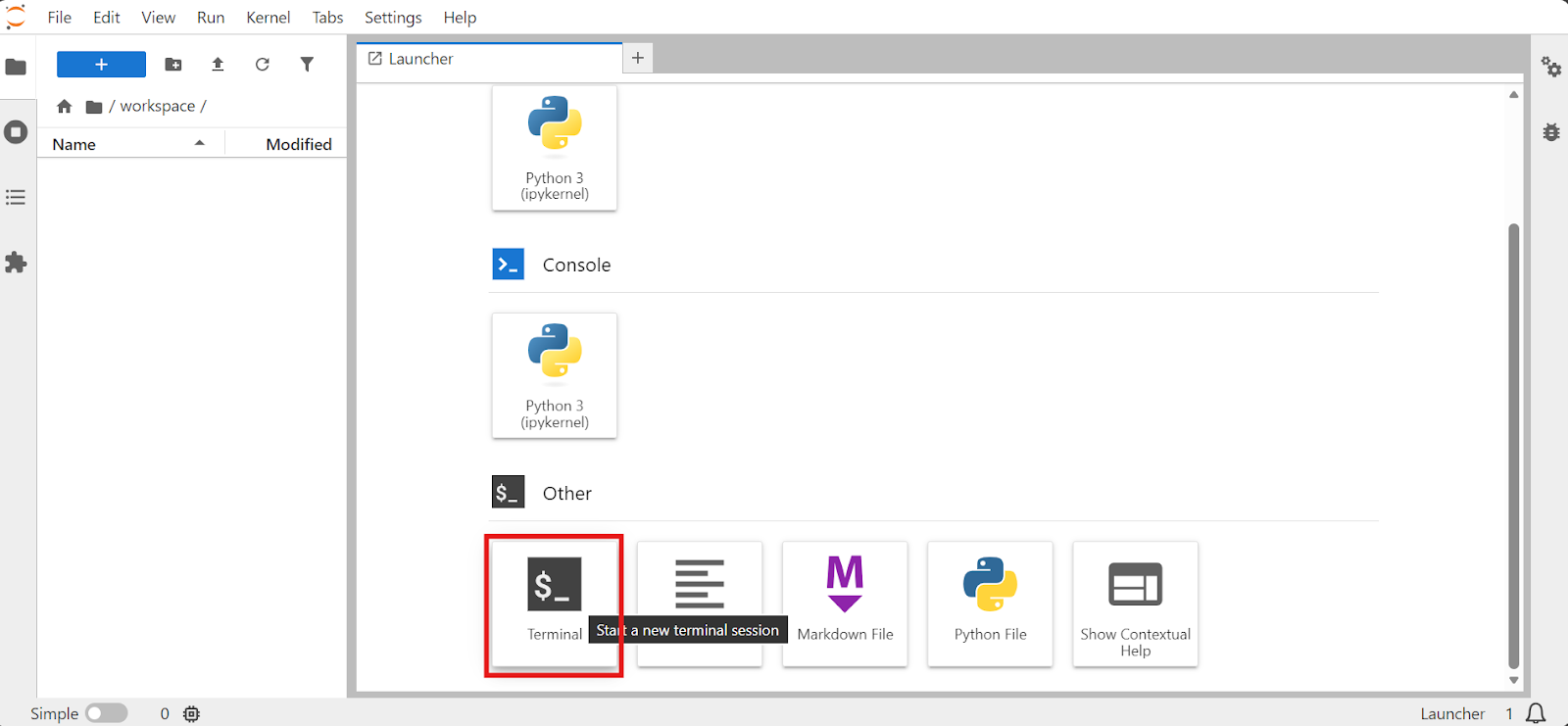
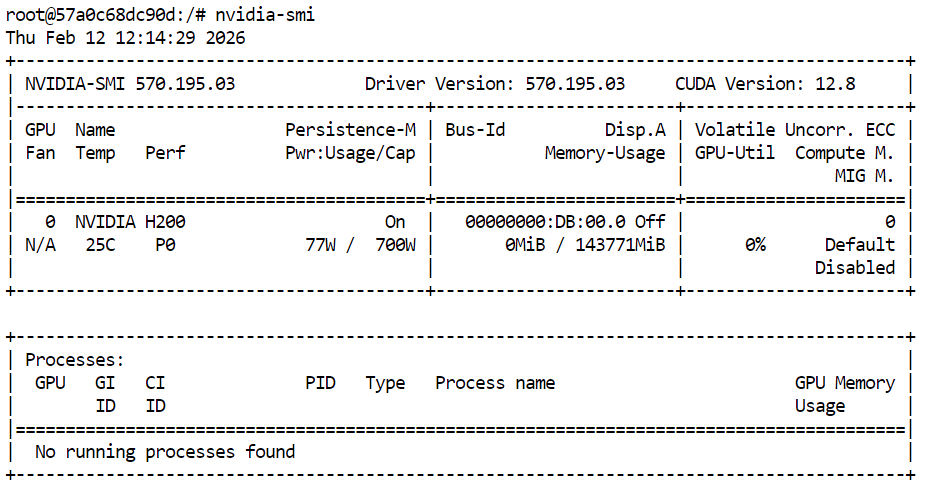
Primeiro, confirme que a GPU está disponível:
nvidia-smi Você deve ver a H200 listada na saída.
Em seguida, instale os pacotes Linux necessários para clonar e compilar o llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqAgora que seu ambiente no Runpod está pronto e a GPU está funcionando, o próximo passo é instalar e compilar o llama.cpp com aceleração CUDA para que o GLM-5 rode com eficiência na H200.
Primeiro, vá até o diretório de trabalho e clone o repositório oficial do llama.cpp:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppÉ importante observar que a versão estável mais recente do llama.cpp ainda não tem suporte completo ao GLM-5 por padrão. Você precisa puxar um pull request específico com mudanças recentes necessárias para a compatibilidade adequada.
Busque e faça checkout da branch atualizada:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Agora, vamos configurar o sistema de build para compilar o llama.cpp com CUDA habilitado, permitindo que o modelo use aceleração de GPU em vez de rodar totalmente na CPU.
Execute o CMake com a flag de CUDA ativada:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Isso cria um diretório build/ dedicado e garante que os binários do servidor do llama.cpp terão suporte à execução em GPUs NVIDIA.
Quando a configuração terminar, faça o build do target llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Esse passo pode levar alguns minutos, dependendo do pod, mas ao finalizar você terá um binário do servidor com CUDA pronto para rodar o GLM-5.
Por fim, copie os executáveis compilados para a pasta principal para facilitar o acesso:
cp llama.cpp/build/bin/llama-* llama.cppCom o llama.cpp compilado e pronto, o próximo passo é baixar os arquivos do modelo GLM-5 GGUF no Hugging Face.
Como esses checkpoints são extremamente grandes, é importante habilitar os métodos de download mais rápidos disponíveis.
O Hugging Face oferece ferramentas opcionais como hf_xet e hf_transfer, que aceleram bastante o download, especialmente em máquinas na nuvem como o Runpod.
Comece instalando os utilitários de download do Hugging Face:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferEsses pacotes permitem downloads paralelos mais rápidos e melhor desempenho ao baixar centenas de gigabytes de shards do modelo.
Agora baixe a variante quantizada específica usada neste tutorial. Queremos apenas os arquivos UD-Q2_K_XL, não todo o conjunto:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Isso salvará o modelo diretamente no diretório models/GLM-5-GGUF.
Na nossa configuração, os downloads chegam a cerca de 1,2 GB/s, porque habilitamos o hf_xet e fornecemos um token do Hugging Face. Downloads anônimos costumam ser bem mais lentos, então configurar autenticação e aceleração de transferência faz muita diferença em modelos desse porte.
Com o modelo baixado e o llama.cpp compilado com suporte a CUDA, podemos iniciar o GLM-5 usando o llama-server embutido.
Execute o comando abaixo para subir o servidor:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Alguns argumentos importantes aqui:
--host 0.0.0.0 expõe o servidor para acesso via navegador--port 8080 corresponde à porta que abrimos no Runpod--fit on garante uso máximo da GPU antes de usar a RAM--ctx-size 16384 define a janela de contexto para inferência--flash-attn auto habilita kernels de atenção mais rápidos quando suportadosAo iniciar o servidor, você vai notar que o llama.cpp usa praticamente toda a memória de GPU disponível, com o restante das camadas do modelo descarregado na RAM do sistema. Isso é esperado e funciona bem em setups com H200.
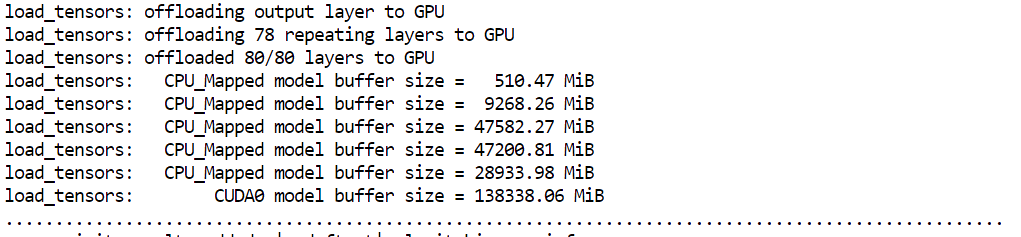
O modelo deve carregar e começar a servir em menos de um minuto. Se seu pod demorar muito mais, pode haver um problema com a instância. Nesse caso, costuma ser mais rápido encerrar o pod e iniciar outro.

Com o servidor no ar, verifique se o GLM-5 está disponível consultando o endpoint compatível com OpenAI:
curl -s http://127.0.0.1:8080/v1/models | jqVocê deve ver "GLM-5" na resposta, confirmando que o modelo está carregado e pronto para uso.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Com o servidor no ar, você pode testar o GLM-5 direto pela interface de Chat do llama.cpp.
Normalmente, a WebUI fica disponível localmente em: http://127.0.0.1:8080
Porém, como estamos rodando no Runpod na nuvem, esse link localhost não vai funcionar a partir da sua máquina.
Em vez disso, vá ao seu dashboard do Runpod e clique no link de HTTP Service para a porta 8080. Esse é o URL público que encaminha o tráfego para o seu llama-server.
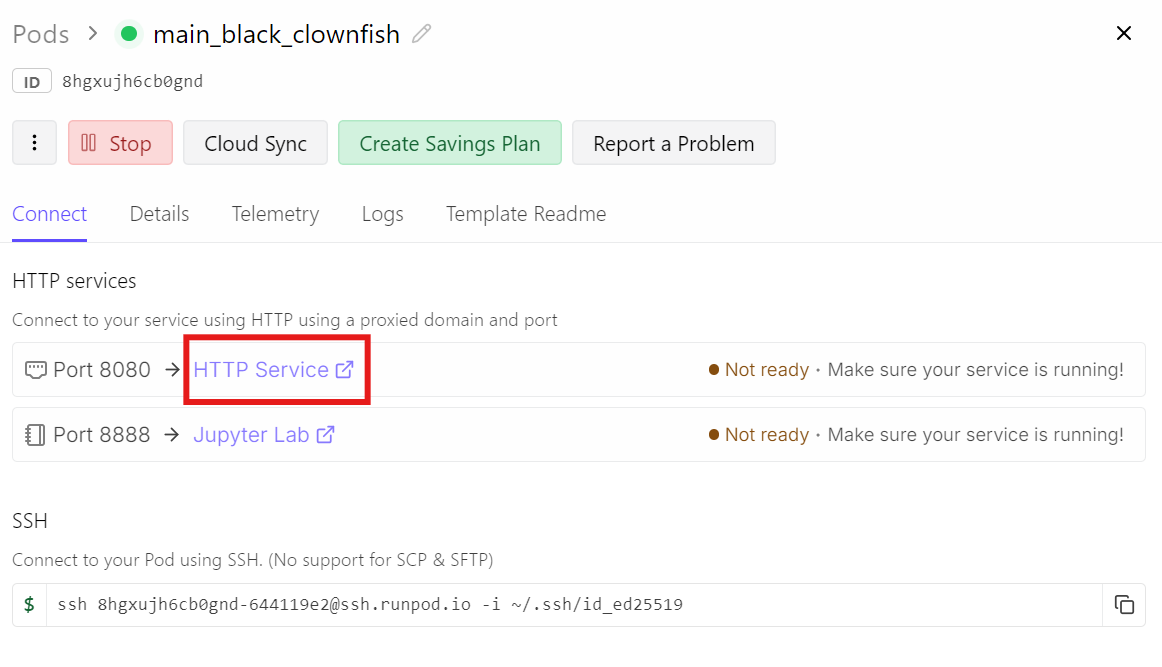 Abrindo esse link você acessa a interface de Chat, com o modelo GLM-5 já carregado e pronto.
Abrindo esse link você acessa a interface de Chat, com o modelo GLM-5 já carregado e pronto.
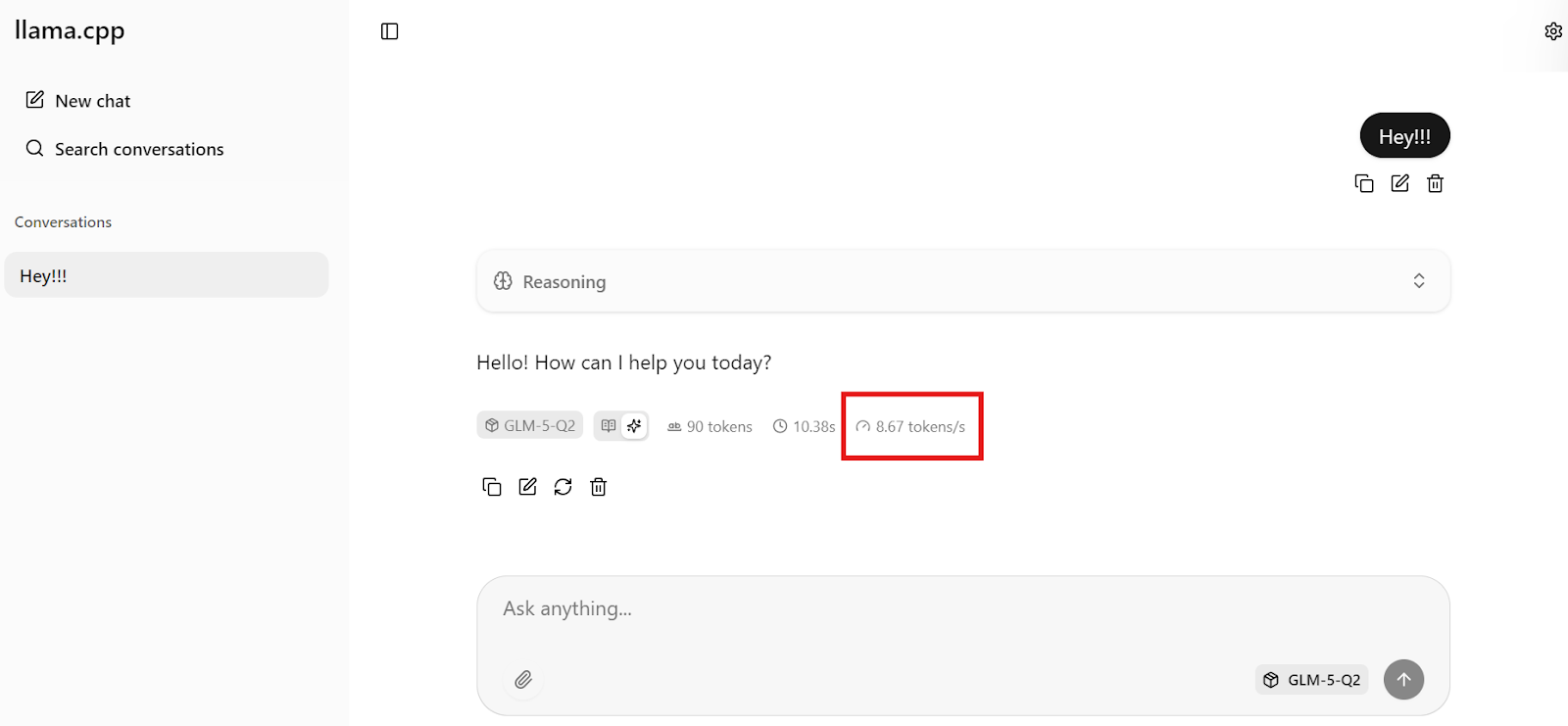
Para confirmar que está tudo certo, envie uma mensagem simples como “Oi!!”. O modelo deve responder imediatamente.
No nosso caso, a inferência roda por volta de 8,7 tokens por segundo, o que é um desempenho excelente considerando o tamanho do GLM-5 e o checkpoint quantizado de 281GB.
Aider é uma ferramenta de pair programming com IA no terminal que funciona direto dentro da pasta do seu projeto.
Você conversa com ele como um parceiro de código, e ele pode criar, editar e refatorar arquivos no seu repositório mantendo tudo ancorado na sua base de código real e no fluxo de trabalho com git.
Ele também se conecta a qualquer endpoint de API compatível com OpenAI, o que o torna perfeito para rodar contra nosso servidor local do llama.cpp.
Primeiro, instale o Aider:
pip install -U aider-chatDepois, aponte o Aider para o seu servidor local do llama.cpp compatível com OpenAI. Definimos uma chave fictícia porque o llama.cpp não exige uma chave real da OpenAI:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEAgora crie uma pasta de projeto demo (para o Aider trabalhar em um repo limpo):
mkdir -p glm5-demo-app
cd glm5-demo-appPor fim, inicie o Aider e conecte-o ao GLM-5 usando o alias do modelo que expusemos antes:
aider --model openai/GLM-5 --no-show-model-warningsA partir daqui, tudo que você pedir dentro do Aider será roteado pelo seu servidor local do GLM-5, e o Aider aplicará mudanças diretamente nos arquivos em glm5-demo-app.
 Use o GLM-5 como seu agente de código
Use o GLM-5 como seu agente de códigoCom o Aider conectado ao GLM-5, você pode usá-lo como um agente de código dentro do seu repo. Comece com uma saudação simples para confirmar a resposta rápida.

Depois, dê um prompt de tarefa claro como este:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
O Aider primeiro propõe um plano e depois pede permissão para aplicar as edições.
Aceite as edições e ele vai gerar os arquivos automaticamente.
Em um quant de 2 bits como o GLM-5-UD-Q2_K_XL, você pode ver pequenos erros, por exemplo, criar um arquivo chamado pip install -r requirements.txt, o que é um engano. O modelo completo tende a errar menos, mas a versão de 2 bits continua bem utilizável com uma revisão humana rápida.
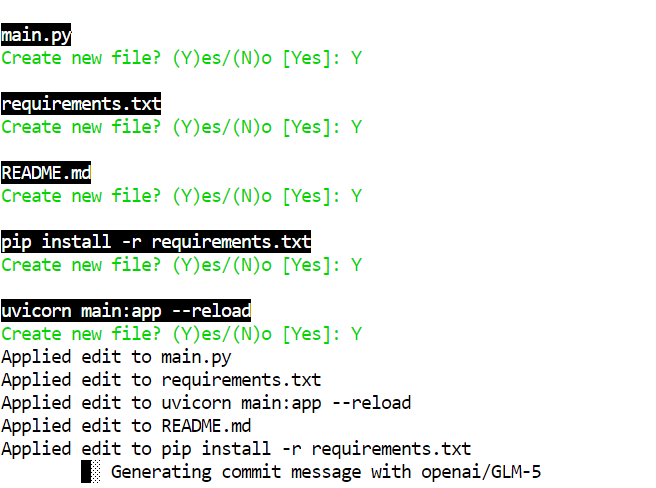
Depois que o Aider terminar de escrever o projeto, entre na pasta, instale as dependências e rode o servidor:
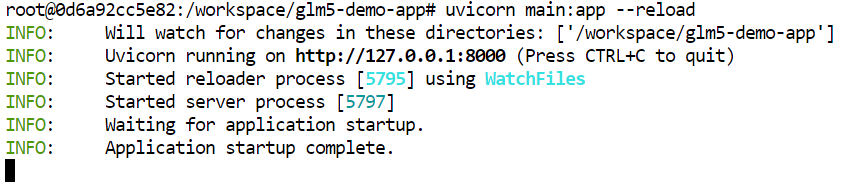
cd glm5-demo-app/pip install -r requirements.txtInicie o app FastAPI com o Uvicorn:
uvicorn main:app --reloadO servidor vai rodar na porta 8000.
Teste o endpoint de saúde:
curl -s http://127.0.0.1:8000/healthVocê deve receber:
{"status":"ok"}O GLM-5 está rapidamente se tornando um dos modelos open-weight mais comentados na comunidade de IA, especialmente por aproximar o desempenho open-source dos modelos proprietários, além de ser projetado para raciocínio profundo, fluxos com agentes e tarefas de código.
Apesar do hype, rodar modelos em escala total localmente ainda é um desafio para usuários comuns.
Mesmo com quantização, modelos como o GLM-5 exigem centenas de gigabytes de memória e GPUs rápidas — algo que muita gente não tem em casa.
Isso significa que a maioria das pessoas depende de pods de GPU na nuvem (como o setup com H200 deste tutorial) ou de serviços de API hospedados.
O caráter open-weight do GLM-5 é poderoso porque permite que você hospede e controle sua própria instância sem depender de provedores proprietários de API, mas também deixa claro por que open source em IA não significa, magicamente, “roda no notebook” para todo mundo.
Neste tutorial, vimos como superar essas barreiras de hardware usando uma versão quantizada de 2 bits do GLM-5 em uma GPU H200 no Runpod. Passamos pela configuração do ambiente, compilação do llama.cpp com suporte a CUDA, download eficiente do modelo, inicialização do servidor de inferência, teste via interface no navegador e, por fim, a conexão de uma ferramenta de código como o Aider para usar o GLM-5 como agente em tarefas reais de desenvolvimento.
Melhores cursos de IA
Programa
blog
Abid Ali Awan
8 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Ryan Ong

