

Programma
Ingegnere AI associato per scienziati dei dati
40 h
GLM-5 è il nuovo modello di open-reasoning di Z.ai e ha attirato rapidamente l'attenzione per le sue ottime prestazioni nel coding, nei workflow agentici e nelle chat con contesto esteso.
Molti sviluppatori lo stanno già usando per creare siti web in un solo passaggio, sviluppare piccole app e sperimentare con agenti AI locali.
La sfida è che GLM-5 è un modello molto grande, e farlo girare in locale non è realistico sull'hardware consumer. Anche le versioni quantizzate richiedono centinaia di gigabyte di memoria e una GPU adeguata.
In questo tutorial, vediamo un modo pratico per eseguire GLM-5 in locale usando una quantizzazione GGUF a 2 bit su un pod NVIDIA H200, servirlo tramite llama.cpp e collegarlo ad Aider così da poter usare GLM-5 come vero agente di coding all'interno dei tuoi progetti.
Ti consiglio anche di dare un'occhiata alla nostra guida su eseguire GLM 4.7 Flash in locale.
Prima di eseguire GLM-5 in locale, ti serviranno la variante di modello giusta, abbastanza memoria per caricarlo e uno stack software GPU funzionante.
I requisiti hardware dipendono dalla dimensione della quantizzazione:
Per le migliori prestazioni, la tua VRAM + RAM di sistema combinate dovrebbero essere vicine alla dimensione della quantizzazione. In caso contrario, llama.cpp può eseguire l'offloading su SSD, ma l'inferenza sarà più lenta. Usa --fit in llama.cpp per massimizzare l'uso della GPU.
Nel nostro setup, eseguiamo GLM-5-UD-Q2_K_XL su una NVIDIA H200, con sufficiente VRAM e RAM di sistema per caricare il modello in modo efficiente.
Prerequisiti software:
Di seguito trovi le istruzioni passo passo per eseguire GLM-5 in locale:
Anche la versione a 1 bit di GLM-5 è troppo grande per girare sulla maggior parte dei laptop consumer, quindi per questo tutorial userò Runpod con una GPU NVIDIA H200.
Inizia creando un nuovo pod e selezionando il template PyTorch più recente.
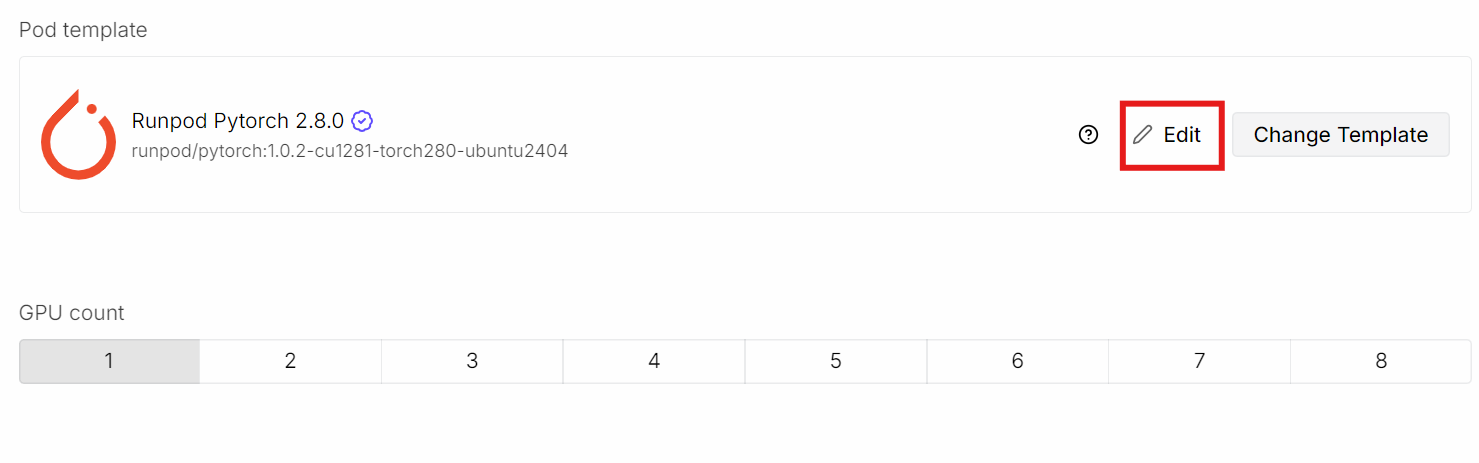
Poi clicca su Edit per modificare le impostazioni del pod:
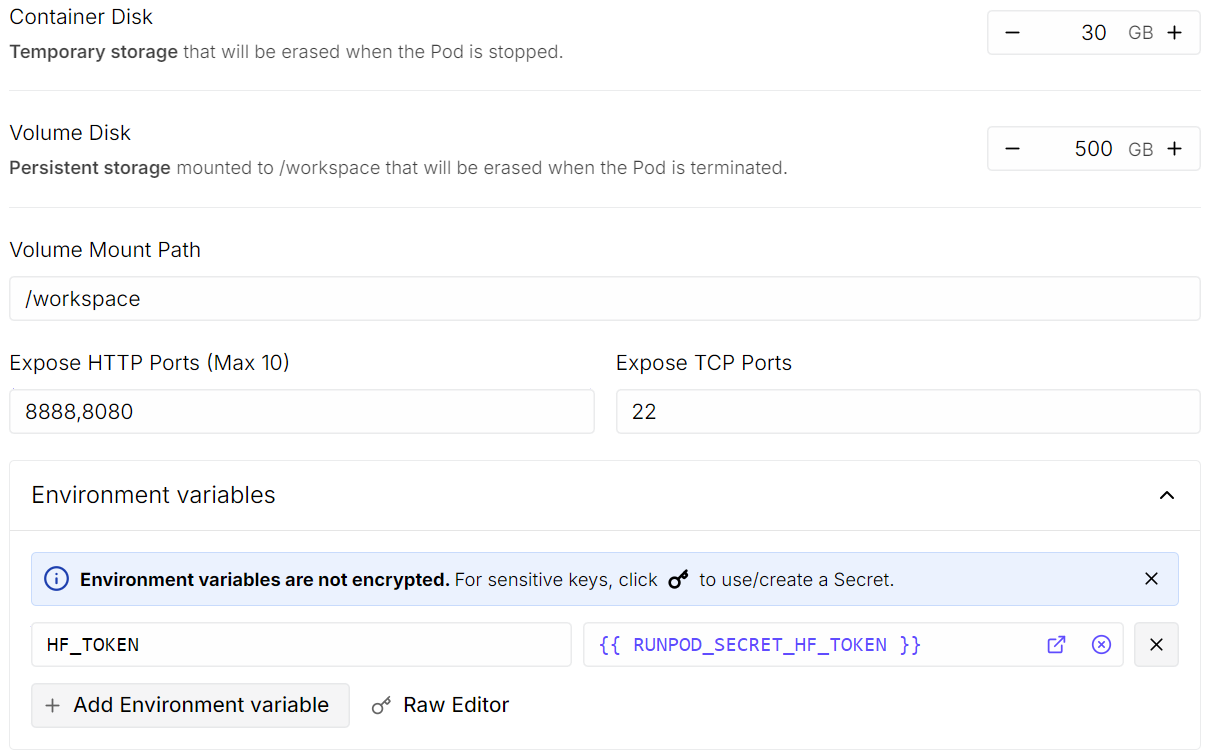
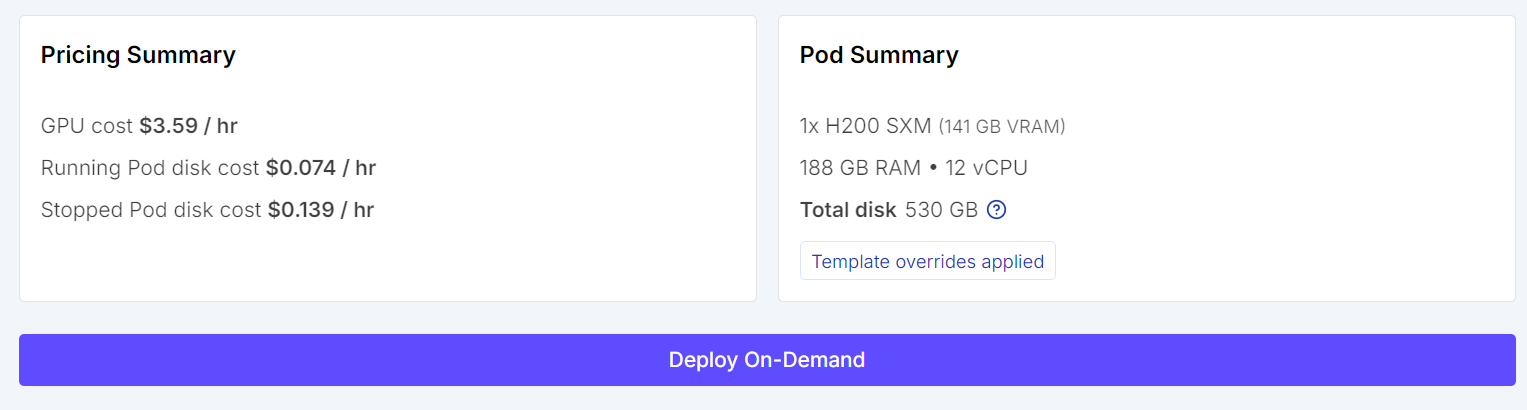
Quando tutto è a posto, rivedi il riepilogo del pod e clicca su Deploy On-Demand.
Quando il pod è pronto, apri JupyterLab, avvia un Terminal e lavora da lì. Usare il terminale di Jupyter è comodo perché puoi eseguire più sessioni senza dover ricorrere all'SSH.
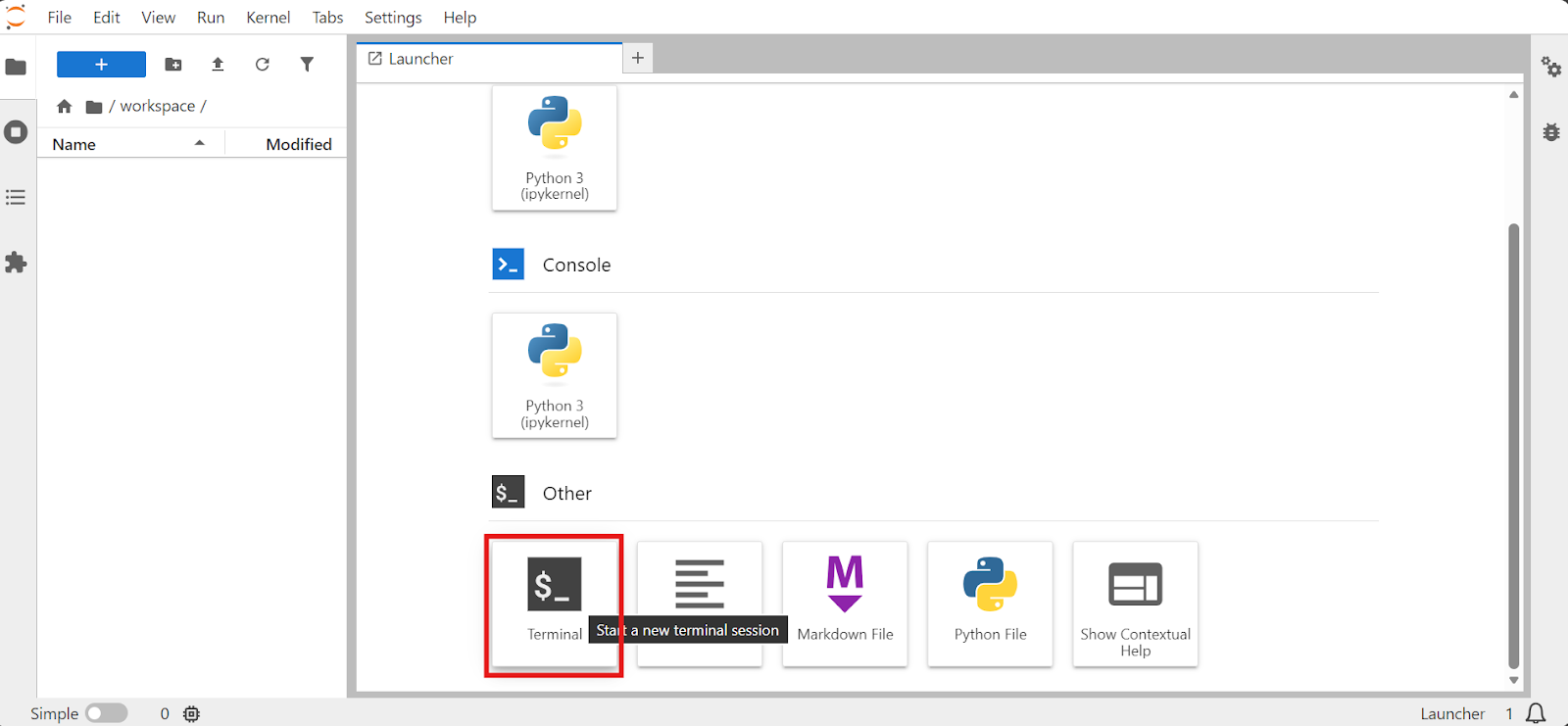
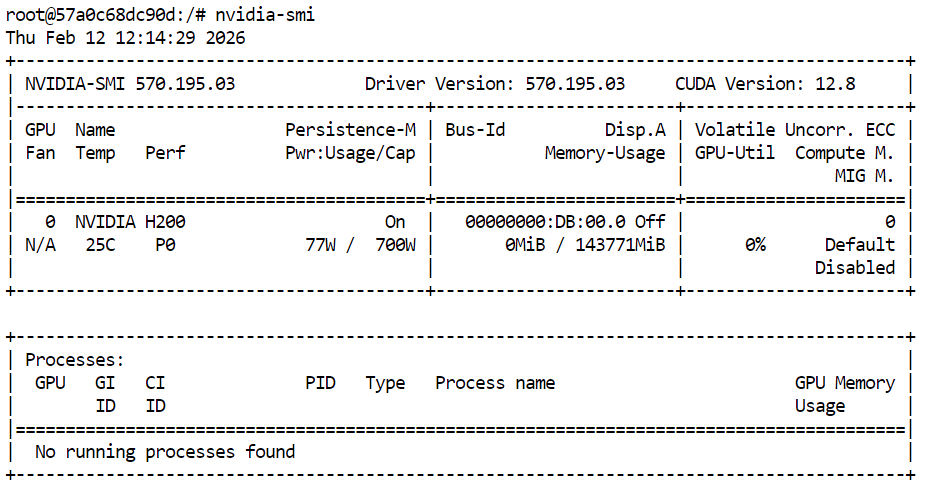
Per prima cosa, verifica che la GPU sia disponibile:
nvidia-smi Dovresti vedere l'H200 elencata nell'output.
Poi installa i pacchetti Linux necessari per clonare e compilare llama.cpp:
sudo apt update
sudo apt install -y git cmake build-essential curl jqOra che l'ambiente Runpod è pronto e la GPU funziona, il passo successivo è installare e compilare llama.cpp con accelerazione CUDA così che GLM-5 possa girare in modo efficiente sull'H200.
Per prima cosa, entra nella directory di lavoro e clona il repository ufficiale di llama.cpp:
cd /workspace
git clone https://github.com/ggml-org/llama.cpp
cd llama.cppA questo punto, è importante notare che l'ultima release stabile di llama.cpp non supporta ancora pienamente GLM-5 out of the box. Devi prendere una specifica pull request a monte che contiene modifiche recenti necessarie per la compatibilità corretta.
Recupera e fai checkout del branch aggiornato:
git fetch origin pull/19460/head:MASTER && git checkout MASTER && cd ..Ora configuriamo il sistema di build in modo che llama.cpp venga compilato con CUDA abilitata, permettendo al modello di usare l'accelerazione GPU invece di girare interamente su CPU.
Esegui CMake con il flag CUDA attivato:
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
Questo crea una directory build/ dedicata e garantisce che i binari del server di llama.cpp supportino l'esecuzione su GPU NVIDIA.
Una volta completata la configurazione, compila il target llama-server:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Questo passaggio può richiedere qualche minuto a seconda del pod, ma una volta terminato avrai un binario del server con supporto CUDA pronto per eseguire GLM-5.
Infine, copia gli eseguibili compilati nella cartella principale per un accesso più semplice:
cp llama.cpp/build/bin/llama-* llama.cppCon llama.cpp compilato e pronto, il passo successivo è scaricare i file del modello GLM-5 GGUF da Hugging Face.
Poiché questi checkpoint sono estremamente grandi, è importante abilitare i metodi di download più veloci disponibili.
Hugging Face fornisce strumenti opzionali come hf_xet e hf_transfer, che migliorano notevolmente la velocità di download, soprattutto su macchine cloud come Runpod.
Inizia installando le utility di download di Hugging Face necessarie:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferQuesti pacchetti consentono download paralleli più veloci e migliori prestazioni quando si scaricano centinaia di gigabyte di shard del modello.
Ora scarica la specifica variante quantizzata usata in questo tutorial. Vogliamo solo i file UD-Q2_K_XL, non l'intero set di upload:
hf download unsloth/GLM-5-GGUF \
--local-dir models/GLM-5-GGUF \
--include "*UD-Q2_K_XL*"Questo salverà il modello direttamente nella directory models/GLM-5-GGUF.
Nel nostro setup, i download raggiungono velocità intorno a 1,2 GB/s, perché abbiamo abilitato hf_xet e fornito prima un token Hugging Face. I download anonimi sono di solito molto più lenti, quindi configurare l'autenticazione e l'accelerazione del trasferimento fa una grande differenza quando si lavora con modelli di queste dimensioni.
Ora che il modello è stato scaricato e llama.cpp è compilato con supporto CUDA, possiamo avviare GLM-5 usando il llama-server integrato.
Esegui il seguente comando per lanciare il server:
./llama.cpp/llama-server \
--model models/GLM-5-GGUF/UD-Q2_K_XL/GLM-5-UD-Q2_K_XL-00001-of-00007.gguf \
--alias "GLM-5" \
--host 0.0.0.0 \
--port 8080 \
--jinja \
--fit on \
--threads 32 \
--ctx-size 16384 \
--batch-size 512 \
--ubatch-size 128 \
--flash-attn auto \
--temp 0.7 \
--top-p 0.95Alcuni argomenti importanti da capire qui:
--host 0.0.0.0 espone il server in modo che sia accessibile dal tuo browser--port 8080 corrisponde alla porta che abbiamo aperto prima in Runpod--fit on garantisce il massimo utilizzo della GPU prima di riversare in RAM--ctx-size 16384 imposta la finestra di contesto per l'inferenza--flash-attn auto abilita kernel di attenzione più veloci quando supportatiQuando avvii il server, noterai che llama.cpp utilizza quasi tutta la memoria GPU disponibile, con i layer rimanenti del modello offloadati nella RAM di sistema. È previsto e funziona bene con i setup H200.
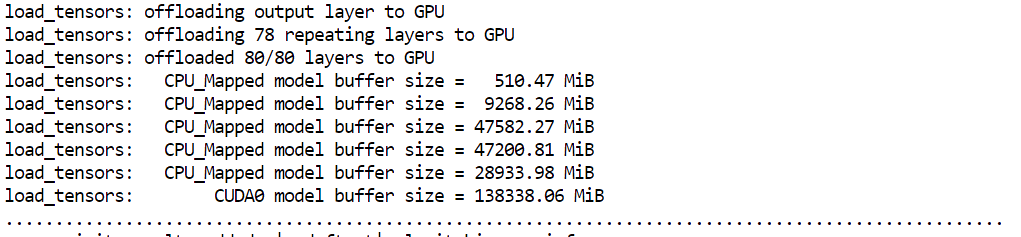
Il modello dovrebbe caricarsi e iniziare a servire in meno di un minuto. Se il tuo pod impiega molto più tempo, potrebbe esserci un problema con l'istanza. In tal caso, di solito è più veloce terminare il pod e avviarne uno nuovo.

Una volta che il server è in esecuzione, verifica che GLM-5 sia disponibile interrogando l'endpoint compatibile con OpenAI:
curl -s http://127.0.0.1:8080/v1/models | jqDovresti vedere "GLM-5" elencato nella risposta, a conferma che il modello è caricato e pronto all'uso.
{
"models": [
{
"name": "GLM-5",
"model": "GLM-5",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "GLM-5",
"object": "model",
"created": 1770900487,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 2,
"n_vocab": 154880,
"n_ctx_train": 202752,
"n_embd": 6144,
"n_params": 753864139008,
"size": 281373251584
}
}
]
}Una volta che il server è in esecuzione, puoi testare GLM-5 direttamente tramite la Chat UI integrata di llama.cpp.
Di norma, la WebUI è disponibile in locale su: http://127.0.0.1:8080
Tuttavia, dato che stiamo eseguendo su Runpod nel cloud, questo link localhost non funzionerà dalla tua macchina.
Vai invece alla tua dashboard di Runpod e clicca sul link HTTP Service per la porta 8080. Questo è l'URL pubblico che inoltra il traffico al tuo llama-server in esecuzione.
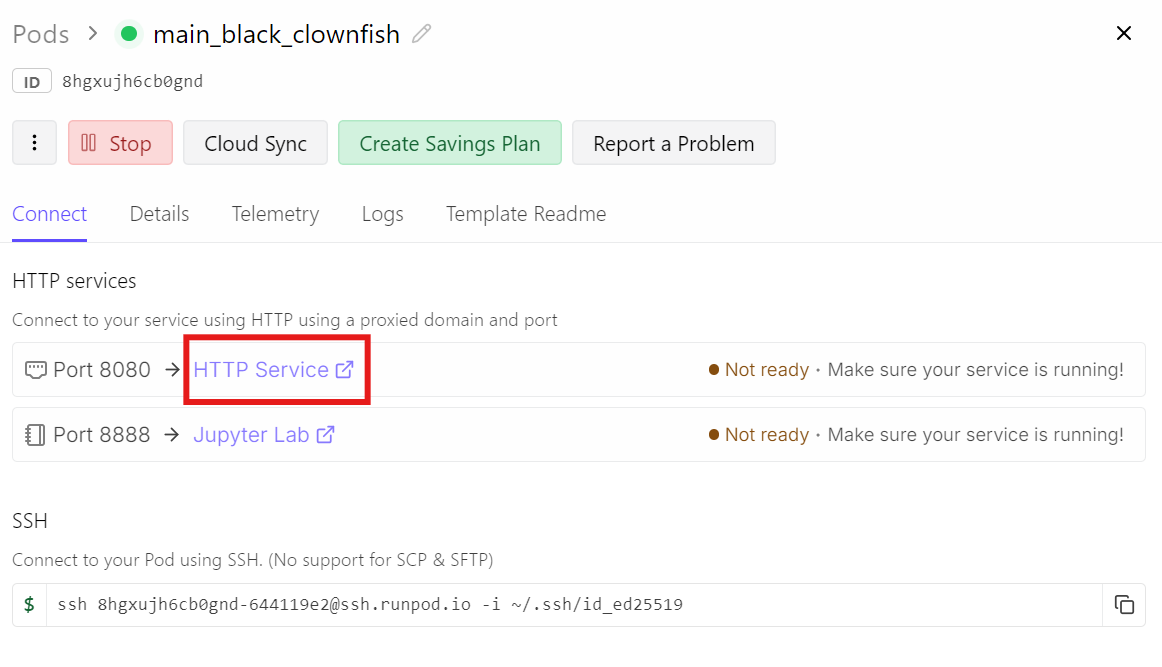 Aprendo quel link arriverai alla Chat UI, con il modello GLM-5 già caricato e pronto.
Aprendo quel link arriverai alla Chat UI, con il modello GLM-5 già caricato e pronto.
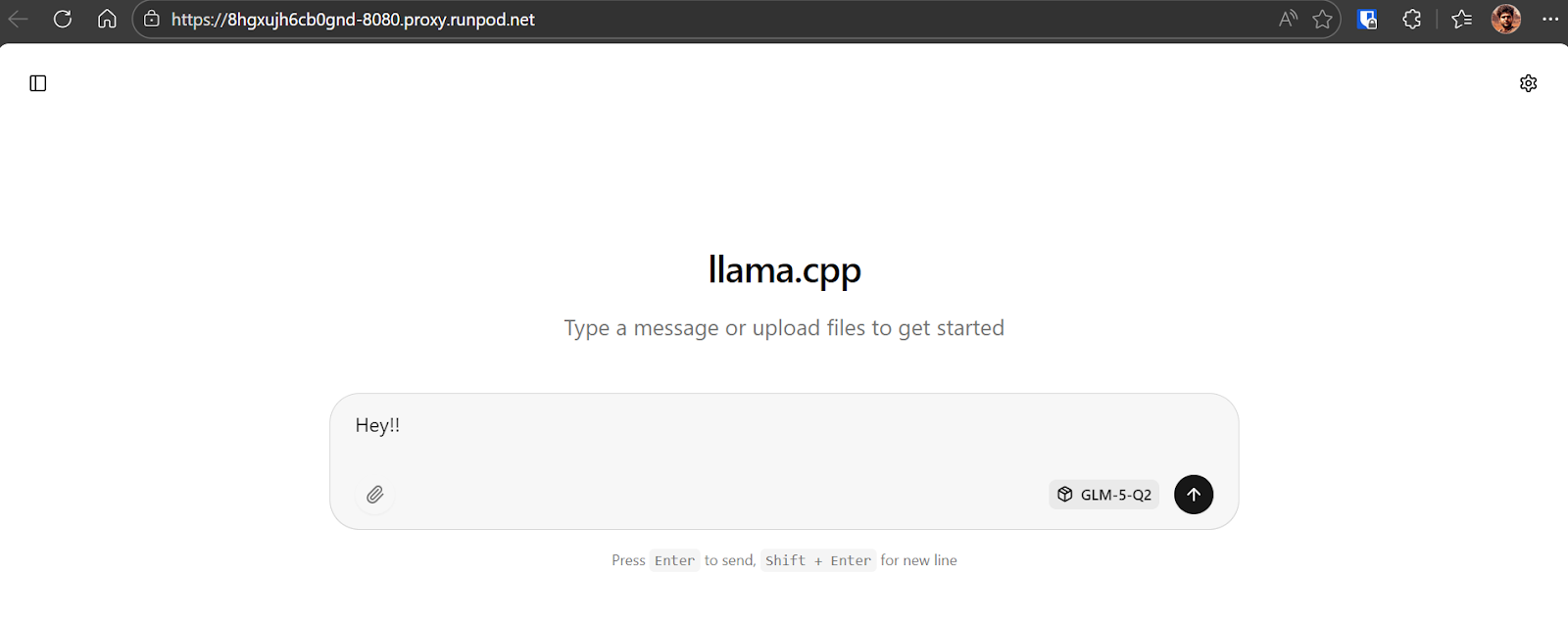
Per confermare che tutto funzioni, invia un messaggio semplice come "Ehi!!". Dovresti vedere il modello rispondere immediatamente.
Nel nostro caso, l'inferenza gira a circa 8,7 token al secondo, che è un'ottima prestazione considerando la dimensione di GLM-5 e il checkpoint quantizzato da 281 GB.
Aider è uno strumento di pair programming AI basato su terminale che funziona direttamente dentro la cartella del tuo progetto.
Ci chiacchieri come con un partner di coding, e può creare, modificare e refattorizzare file in tutto il tuo repo mantenendo tutto ancorato alla tua codebase reale e al workflow git.
Supporta anche la connessione a qualsiasi endpoint API compatibile con OpenAI, il che lo rende perfetto per lavorare contro il nostro server locale di llama.cpp.
Per prima cosa, installa Aider:
pip install -U aider-chatPoi punta Aider al tuo server locale di llama.cpp compatibile con OpenAI. Impostiamo una chiave fittizia perché llama.cpp non richiede una vera chiave OpenAI:
export OPENAI_API_BASE=http://127.0.0.1:8080/v1
export OPENAI_API_KEY=local
export OPENAI_BASE_URL=$OPENAI_API_BASEOra crea una nuova cartella di progetto demo (così Aider ha un repo pulito su cui lavorare):
mkdir -p glm5-demo-app
cd glm5-demo-appInfine, avvia Aider e connettiti a GLM-5 usando l'alias del modello che abbiamo esposto prima:
aider --model openai/GLM-5 --no-show-model-warningsA questo punto, qualsiasi cosa tu chieda dentro Aider verrà instradata attraverso il tuo server GLM-5 locale, e Aider applicherà le modifiche direttamente ai file in glm5-demo-app.
 Usa GLM-5 come tuo coding agent
Usa GLM-5 come tuo coding agentUna volta che Aider è connesso a GLM-5, puoi usarlo come un agente di coding dentro il tuo repo. Inizia con un semplice saluto per confermare che risponde rapidamente.

Poi dagli un prompt di task chiaro come questo:
Create a simple Python FastAPI project with one /health endpoint, a README, and instructions to run it locally.
Aider proporrà prima un piano, poi chiederà il permesso di applicare le modifiche.
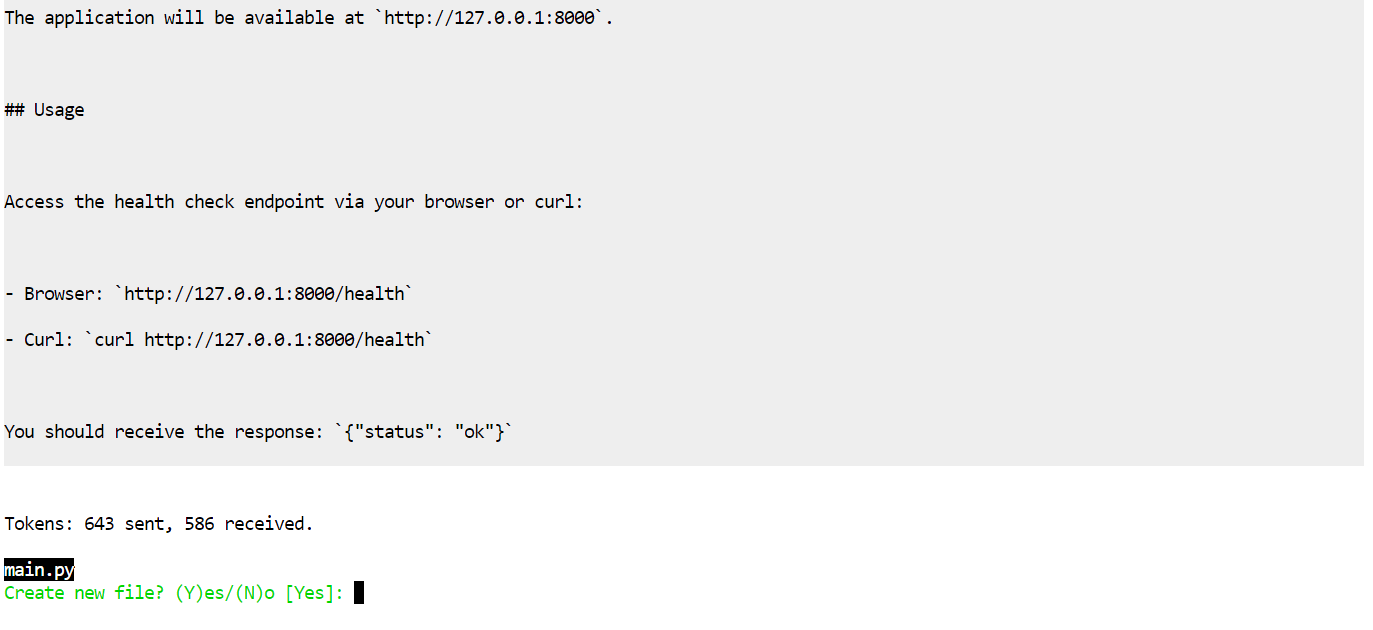
Accetta le modifiche e genererà i file automaticamente.
Con una quantizzazione a 2 bit come GLM-5-UD-Q2_K_XL, potresti vedere piccoli errori, ad esempio la creazione di un file come pip install -r requirements.txt, che è un errore. Il modello completo è meno incline a questi errori, ma quello a 2 bit è comunque molto utilizzabile con una rapida revisione umana.
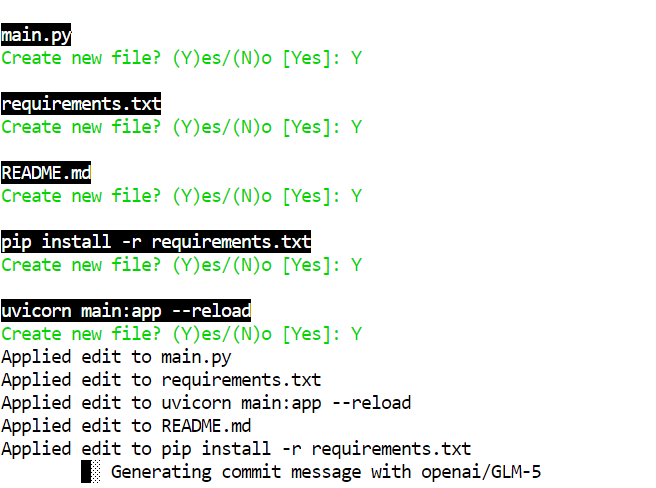
Dopo che Aider ha terminato di scrivere il progetto, entra nella cartella, installa le dipendenze ed esegui il server:
cd glm5-demo-app/pip install -r requirements.txtAvvia l'app FastAPI con Uvicorn:
uvicorn main:app --reloadIl server girerà sulla porta 8000.
Testa l'endpoint di health:
curl -s http://127.0.0.1:8000/healthDovresti ottenere:
{"status":"ok"}GLM-5 sta rapidamente diventando uno dei modelli open-weight più discussi nella community AI, soprattutto perché avvicina le prestazioni open-source a quelle dei modelli proprietari, ed è pensato per il deep reasoning, i workflow agentici e i task di coding.
Nonostante tutto il clamore, eseguire modelli su larga scala in locale è ancora una sfida per gli utenti comuni.
Anche con la quantizzazione, modelli come GLM-5 richiedono centinaia di gigabyte di memoria e GPU veloci, qualcosa che molti non hanno sulle macchine di casa.
Questo significa che la maggior parte delle persone si affida a pod GPU nel cloud (come il setup H200 in questo tutorial) o a servizi API hosted.
La natura open-weight di GLM-5 è potente perché ti consente di ospitare e controllare la tua istanza senza dipendere da provider API proprietari, ma evidenzia anche perché l'open source nell'AI non significa magicamente "gira su un laptop" per tutti.
In questo tutorial, abbiamo visto come superare queste barriere hardware usando una versione quantizzata a 2 bit di GLM-5 su una GPU H200 di Runpod. Abbiamo visto come configurare l'ambiente, compilare llama.cpp con supporto CUDA, scaricare il modello in modo efficiente, lanciare il server di inferenza, testarlo via UI browser e infine collegare uno strumento di coding come Aider per usare GLM-5 come agente per attività di sviluppo reali.
I migliori corsi di AI
Programma
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

