Web Scraping in Python
BasicSkill Level
4 Hr
92.8K learners
Web scraping adalah istilah yang digunakan untuk menggambarkan penggunaan program atau algoritme untuk mengekstrak dan memproses sejumlah besar data dari web. Baik Anda seorang data scientist, engineer, atau siapa pun yang menganalisis dataset berukuran besar, kemampuan untuk melakukan scraping data dari web adalah keterampilan yang berguna. Misalnya, Anda menemukan data di web, tetapi tidak ada cara langsung untuk mengunduhnya; web scraping menggunakan Python adalah keterampilan yang dapat Anda gunakan untuk mengekstrak data tersebut ke dalam bentuk yang berguna dan dapat diimpor.
Dalam tutorial ini, Anda akan mempelajari hal-hal berikut:
Dataset yang digunakan dalam tutorial ini diambil dari lomba lari 10K yang berlangsung di Hillsboro, OR pada Juni 2017. Secara khusus, Anda akan menganalisis performa pelari 10K dan menjawab pertanyaan seperti:
Menggunakan Jupyter Notebook, Anda sebaiknya mulai dengan mengimpor modul yang diperlukan (pandas, numpy, matplotlib.pyplot, Seaborn). Jika Anda belum menginstal Jupyter Notebook, saya sarankan menginstalnya menggunakan distribusi Anaconda Python, yang tersedia di internet. Agar mudah menampilkan plot, pastikan menyertakan baris %matplotlib inline seperti di bawah ini.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Untuk melakukan web scraping, Anda juga perlu mengimpor pustaka yang ditunjukkan di bawah. Modul urllib.request digunakan untuk membuka URL. Paket BeautifulSoup digunakan untuk mengekstrak data dari file html. Nama pustaka BeautifulSoup adalah bs4, yang merupakan singkatan dari BeautifulSoup versi 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Setelah mengimpor modul yang diperlukan, Anda harus menentukan URL yang berisi dataset dan meneruskannya ke urlopen() untuk mendapatkan html dari halaman tersebut.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Mendapatkan html dari halaman adalah langkah pertama saja. Langkah berikutnya adalah membuat objek BeautifulSoup dari html tersebut. Ini dilakukan dengan meneruskan html ke fungsi BeautifulSoup(). Paket BeautifulSoup digunakan untuk mengurai html, yaitu mengambil teks html mentah dan memecahnya menjadi objek Python. Argumen kedua lxml adalah parser html yang detailnya tidak perlu Anda khawatirkan pada tahap ini.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
Objek soup memungkinkan Anda mengekstrak informasi menarik tentang situs yang Anda scrap, misalnya mendapatkan judul halaman seperti ditunjukkan di bawah.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Anda juga dapat mengambil teks halaman web dan mencetaknya dengan cepat untuk memeriksa apakah sesuai dengan yang Anda harapkan.
# Print out the text
text = soup.get_text()
#print(soup.text)
Anda dapat melihat html dari halaman web dengan klik kanan di mana saja pada halaman lalu pilih "Inspect." Hasilnya akan terlihat seperti ini.
Anda dapat menggunakan metode find_all() dari soup untuk mengekstrak tag html yang berguna dalam sebuah halaman web. Contoh tag yang berguna termasuk < a > untuk hyperlink, < table > untuk tabel, < tr > untuk baris tabel, < th > untuk header tabel, dan < td > untuk sel tabel. Kode di bawah ini menunjukkan cara mengekstrak semua hyperlink dalam halaman web.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Seperti terlihat dari output di atas, tag html terkadang memiliki atribut seperti class, src, dan sebagainya. Atribut ini memberikan informasi tambahan tentang elemen html. Anda dapat menggunakan for loop dan metode get("href") untuk mengekstrak dan mencetak hanya hyperlink-nya.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Untuk mencetak hanya baris tabel, berikan argumen tr dalam soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Tujuan tutorial ini adalah mengambil tabel dari halaman web dan mengonversinya menjadi dataframe agar lebih mudah dimanipulasi menggunakan Python. Untuk mencapainya, Anda harus mengambil semua baris tabel dalam bentuk daftar terlebih dahulu dan kemudian mengonversi daftar tersebut menjadi dataframe. Di bawah ini ada for loop yang melakukan iterasi melalui baris tabel dan mencetak sel-sel dari baris tersebut.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
Output di atas menunjukkan bahwa setiap baris dicetak dengan tag html yang tertanam pada setiap baris. Ini bukan yang Anda inginkan. Anda dapat menghapus tag html menggunakan Beautiful Soup atau regular expression.
Cara termudah untuk menghapus tag html adalah menggunakan BeautifulSoup, dan ini hanya memerlukan satu baris kode. Teruskan string yang diminati ke BeautifulSoup() dan gunakan metode get_text() untuk mengekstrak teks tanpa tag html.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Menggunakan regular expression sangat tidak dianjurkan karena memerlukan beberapa baris kode dan mudah terjadi kesalahan. Ini membutuhkan impor modul re (untuk regular expression). Kode di bawah ini menunjukkan cara membangun regular expression yang menemukan semua karakter di dalam tag html < td > dan menggantinya dengan string kosong untuk setiap baris tabel. Pertama, Anda menyusun regular expression dengan meneruskan string yang akan dicocokkan ke re.compile(). Titik, bintang, dan tanda tanya (.*?) akan mencocokkan tanda kurung sudut pembuka diikuti apa pun dan diakhiri dengan tanda kurung sudut penutup. Ini mencocokkan teks secara non-greedy, yaitu mencocokkan string terpendek yang mungkin. Jika Anda menghilangkan tanda tanya, ini akan mencocokkan semua teks antara tanda kurung sudut pembuka pertama dan tanda kurung sudut penutup terakhir. Setelah menyusun regular expression, Anda dapat menggunakan metode re.sub() untuk menemukan semua substring yang cocok dengan regular expression dan menggantinya dengan string kosong. Kode lengkap di bawah menghasilkan daftar kosong, mengekstrak teks di antara tag html untuk setiap baris, dan menambahkannya ke daftar yang ditetapkan.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
Langkah berikutnya adalah mengonversi daftar tersebut menjadi dataframe dan melihat sekilas 10 baris pertama menggunakan Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers:, 577] |
| 1 | [Male:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Dataframe belum dalam format yang kita inginkan. Untuk membersihkannya, Anda harus membagi kolom "0" menjadi beberapa kolom pada posisi koma. Ini dilakukan dengan menggunakan metode str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Ini terlihat jauh lebih baik, tetapi masih ada pekerjaan yang harus dilakukan. Dataframe memiliki tanda kurung siku yang tidak diinginkan mengelilingi setiap baris. Anda dapat menggunakan metode strip() untuk menghapus tanda kurung siku pembuka pada kolom "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
Tabel tersebut belum memiliki header. Anda dapat menggunakan metode find_all() untuk mendapatkan header tabel.
col_labels = soup.find_all('th')
Seperti pada baris tabel, Anda dapat menggunakan BeautifulSoup untuk mengekstrak teks di antara tag html untuk header tabel.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Kemudian Anda dapat mengonversi daftar header menjadi dataframe pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Place, Bib, Name, Gender, City, State, Chip T... |
Demikian pula, Anda dapat membagi kolom "0" menjadi beberapa kolom pada posisi koma untuk semua baris.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Kedua dataframe dapat digabungkan menjadi satu menggunakan metode concat() seperti diilustrasikan di bawah ini.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Di bawah ini menunjukkan cara menetapkan baris pertama sebagai header tabel.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

Pada tahap ini, tabel hampir diformat dengan benar. Untuk analisis, Anda dapat mulai dengan mendapatkan gambaran umum data seperti di bawah ini.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
Tabel memiliki 597 baris dan 14 kolom. Anda dapat menghapus semua baris yang memiliki nilai hilang apa pun.
df6 = df5.dropna(axis=0, how='any')
Perhatikan juga bahwa header tabel terduplikasi sebagai baris pertama di df5. Ini dapat dihapus dengan baris kode berikut.
df7 = df6.drop(df6.index[0])
df7.head()

Anda dapat melakukan pembersihan data lebih lanjut dengan mengganti nama kolom '[Place' dan ' Team]'. Python sangat sensitif terhadap spasi. Pastikan Anda menyertakan spasi setelah tanda kutip pada ' Team]'.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

Langkah pembersihan data terakhir melibatkan penghapusan tanda kurung penutup untuk sel di kolom ' Team' .
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Perlu waktu untuk sampai di sini, tetapi pada tahap ini, dataframe sudah dalam format yang diinginkan. Sekarang Anda dapat beralih ke bagian yang menarik dan mulai memplot data serta menghitung statistik yang menarik.
Pertanyaan pertama yang perlu dijawab adalah, berapa rata-rata waktu finis (dalam menit) para pelari? Anda perlu mengonversi kolom "Chip Time" menjadi hanya menit. Salah satu caranya adalah dengan mengonversi kolom tersebut menjadi daftar terlebih dahulu untuk dimanipulasi.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
Langkah berikutnya adalah mengonversi kembali daftar tersebut menjadi dataframe dan membuat kolom baru (Runner_mins) untuk waktu chip pelari yang dinyatakan hanya dalam menit.
df7['Runner_mins'] = time_mins
df7.head()

Kode di bawah ini menunjukkan cara menghitung statistik untuk kolom numerik saja dalam dataframe.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| count | 577.000000 |
| mean | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
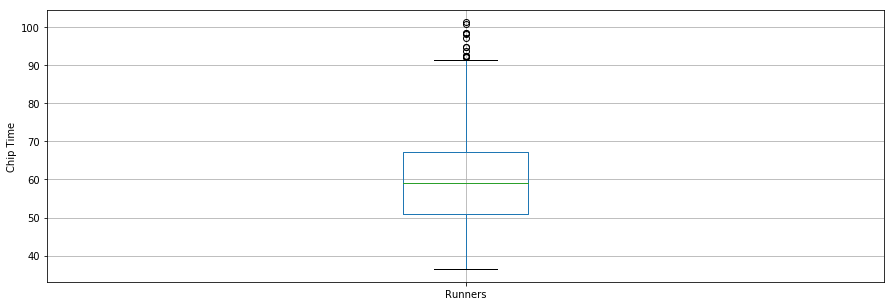
Menariknya, rata-rata waktu chip untuk semua pelari sekitar 60 menit. Pelari 10K tercepat finis dalam 36,35 menit, dan yang paling lambat finis dalam 101,30 menit.
Boxplot adalah alat lain yang berguna untuk memvisualisasikan statistik ringkasan (maksimum, minimum, median, kuartil pertama, kuartil ketiga, termasuk pencilan). Di bawah ini adalah statistik ringkas data untuk para pelari yang ditampilkan dalam boxplot. Untuk visualisasi data, akan lebih nyaman jika terlebih dahulu mengimpor parameter dari modul pylab yang disertakan dengan matplotlib dan menetapkan ukuran yang sama untuk semua figur agar tidak perlu melakukannya untuk setiap figur.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
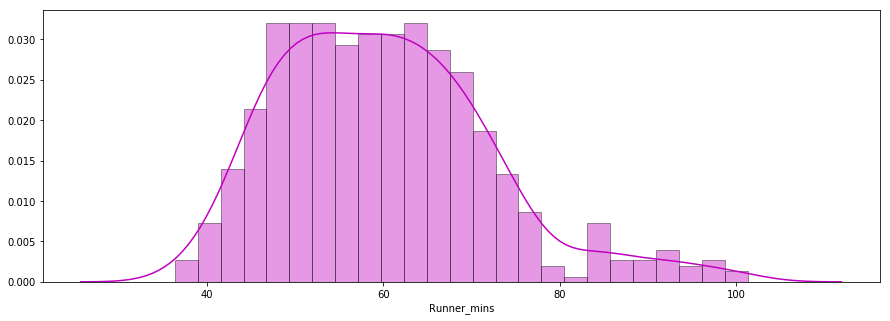
Pertanyaan kedua yang perlu dijawab: Apakah waktu finis para pelari mengikuti distribusi normal?
Di bawah ini adalah plot distribusi waktu chip para pelari yang diplot menggunakan pustaka seaborn. Distribusinya terlihat hampir normal.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
Pertanyaan ketiga berkaitan dengan apakah ada perbedaan performa antara laki-laki dan perempuan pada berbagai kelompok usia. Di bawah ini adalah plot distribusi waktu chip untuk laki-laki dan perempuan.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
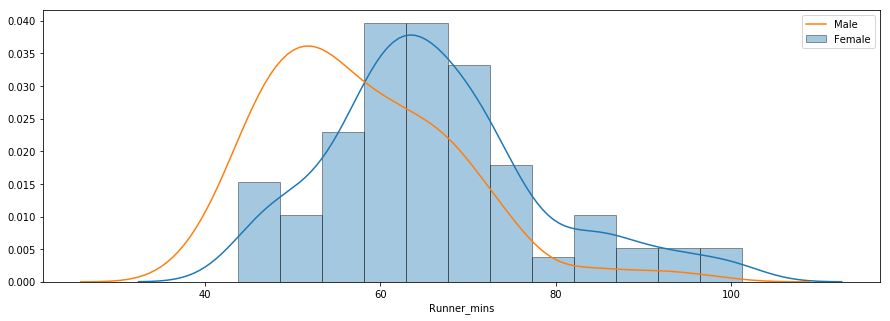
Distribusi tersebut menunjukkan bahwa perempuan rata-rata lebih lambat dibanding laki-laki. Anda dapat menggunakan metode groupby() untuk menghitung statistik ringkasan secara terpisah untuk laki-laki dan perempuan seperti di bawah ini.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
Rata-rata waktu chip untuk semua perempuan dan laki-laki masing-masing sekitar 66 menit dan 58 menit. Di bawah ini adalah perbandingan boxplot berdampingan untuk waktu finis laki-laki dan perempuan.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

Dalam tutorial ini, Anda melakukan web scraping menggunakan Python. Anda menggunakan pustaka Beautiful Soup untuk mengurai data html dan mengonversinya ke dalam bentuk yang dapat digunakan untuk analisis. Anda melakukan pembersihan data di Python dan membuat plot yang berguna (box plot, bar plot, dan distribution plot) untuk mengungkap tren menarik menggunakan pustaka matplotlib dan seaborn di Python. Setelah tutorial ini, Anda seharusnya dapat menggunakan Python untuk dengan mudah melakukan scraping data dari web, menerapkan teknik pembersihan, dan mengekstrak wawasan yang berguna dari data.
Jika Anda ingin mempelajari lebih lanjut tentang Python, ikuti kursus gratis DataCamp Intro to Python for Data Science dan lihat tutorial kami tentang cara melakukan scraping Amazon menggunakan Python.
Pelajari lebih lanjut tentang Python
Kursus
Kursus
Kursus