Web Scraping in Python
BasicSkill Level
4 giờ
92.9K learners
Web scraping là thuật ngữ mô tả việc sử dụng một chương trình hoặc thuật toán để trích xuất và xử lý lượng dữ liệu lớn từ web. Dù bạn là nhà khoa học dữ liệu, kỹ sư, hay bất kỳ ai phân tích các bộ dữ liệu lớn, khả năng lấy dữ liệu từ web là một kỹ năng hữu ích. Giả sử bạn tìm thấy dữ liệu trên web nhưng không có cách tải trực tiếp, kỹ năng web scraping bằng Python sẽ giúp bạn trích xuất dữ liệu sang dạng hữu dụng có thể nhập vào.
Trong hướng dẫn này, bạn sẽ học về các nội dung sau:
Bộ dữ liệu dùng trong hướng dẫn này được lấy từ một cuộc đua 10K diễn ra tại Hillsboro, OR vào tháng 6/2017. Cụ thể, bạn sẽ phân tích thành tích của các vận động viên chạy 10K và trả lời các câu hỏi như:
Sử dụng Jupyter Notebook, bạn nên bắt đầu bằng cách nhập các mô-đun cần thiết (pandas, numpy, matplotlib.pyplot, Seaborn). Nếu bạn chưa cài Jupyter Notebook, tôi khuyên cài đặt qua bản phân phối Anaconda Python có sẵn trên internet. Để hiển thị biểu đồ dễ dàng, hãy thêm dòng %matplotlib inline như bên dưới.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Để thực hiện web scraping, bạn cũng cần nhập các thư viện bên dưới. Mô-đun urllib.request dùng để mở URL. Gói BeautifulSoup dùng để trích xuất dữ liệu từ các tệp html. Tên thư viện của BeautifulSoup là bs4, viết tắt của BeautifulSoup, phiên bản 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Sau khi nhập các mô-đun cần thiết, bạn cần chỉ định URL chứa bộ dữ liệu và truyền vào urlopen() để lấy html của trang.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Lấy html của trang chỉ là bước đầu tiên. Bước tiếp theo là tạo đối tượng BeautifulSoup từ html. Thực hiện bằng cách truyền html vào hàm BeautifulSoup(). Gói BeautifulSoup dùng để phân tách html, tức là lấy văn bản html thô và chuyển thành các đối tượng Python. Đối số thứ hai lxml là bộ phân tích html; ở thời điểm này bạn chưa cần bận tâm đến chi tiết của nó.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
Đối tượng soup cho phép bạn trích xuất thông tin thú vị về trang bạn đang thu thập, chẳng hạn như lấy tiêu đề trang như dưới đây.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Bạn cũng có thể lấy văn bản của trang và in nhanh để kiểm tra xem có đúng như mong đợi hay không.
# Print out the text
text = soup.get_text()
#print(soup.text)
Bạn có thể xem html của trang bằng cách nhấp chuột phải ở bất kỳ đâu trên trang và chọn "Inspect." Kết quả trông như sau.
Bạn có thể dùng phương thức find_all() của soup để trích xuất các thẻ html hữu ích trong một trang. Các thẻ hữu ích gồm < a > cho siêu liên kết, < table > cho bảng, < tr > cho hàng, < th > cho tiêu đề cột, và < td > cho ô dữ liệu. Đoạn mã dưới đây cho thấy cách trích xuất tất cả các siêu liên kết trong trang.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Như bạn thấy ở đầu ra trên, các thẻ html đôi khi đi kèm thuộc tính như class, src, v.v. Các thuộc tính này cung cấp thông tin bổ sung về phần tử html. Bạn có thể dùng vòng lặp for và phương thức get("href") để trích xuất và in ra chỉ các siêu liên kết.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Để chỉ in ra các hàng của bảng, truyền đối số tr vào soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Mục tiêu của hướng dẫn này là lấy một bảng từ một trang web và chuyển nó thành dataframe để dễ thao tác bằng Python. Để làm được, trước tiên bạn cần lấy tất cả các hàng bảng dưới dạng danh sách rồi chuyển danh sách đó thành dataframe. Dưới đây là vòng lặp for duyệt qua các hàng và in ra các ô của hàng.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
Đầu ra trên cho thấy mỗi hàng được in kèm các thẻ html nhúng trong từng hàng. Đây không phải điều bạn muốn. Bạn có thể loại bỏ thẻ html bằng Beautiful Soup hoặc biểu thức chính quy.
Cách dễ nhất để loại bỏ thẻ html là dùng BeautifulSoup, chỉ cần một dòng mã. Truyền chuỗi cần xử lý vào BeautifulSoup() và dùng phương thức get_text() để trích xuất văn bản không kèm thẻ html.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Việc dùng biểu thức chính quy không được khuyến khích vì cần nhiều dòng mã và dễ mắc lỗi. Nó yêu cầu nhập mô-đun re (dành cho regular expressions). Mã dưới đây cho thấy cách xây dựng biểu thức chính quy để tìm tất cả ký tự bên trong thẻ html < td > và thay thế chúng bằng chuỗi rỗng với mỗi hàng. Đầu tiên, bạn biên dịch một biểu thức chính quy bằng cách truyền chuỗi cần khớp vào re.compile(). Dấu chấm, sao và dấu hỏi (.*?) sẽ khớp một dấu ngoặc nhọn mở theo sau là bất kỳ thứ gì và kết thúc bằng dấu ngoặc nhọn đóng. Nó khớp theo cách không tham lam, tức là khớp chuỗi ngắn nhất có thể. Nếu bỏ dấu hỏi, nó sẽ khớp toàn bộ văn bản giữa dấu ngoặc mở đầu tiên và dấu ngoặc đóng cuối cùng. Sau khi biên dịch biểu thức chính quy, bạn có thể dùng phương thức re.sub() để tìm tất cả các chuỗi con khớp và thay thế chúng bằng chuỗi rỗng. Toàn bộ mã dưới đây tạo danh sách rỗng, trích xuất văn bản giữa các thẻ html cho từng hàng và thêm vào danh sách.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
Bước tiếp theo là chuyển danh sách thành dataframe và xem nhanh 10 hàng đầu bằng Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers:, 577] |
| 1 | [Male:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Dataframe chưa ở định dạng mong muốn. Để dọn dẹp, bạn nên tách cột "0" thành nhiều cột tại vị trí dấu phẩy. Thực hiện bằng phương thức str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Trông tốt hơn nhiều, nhưng vẫn còn việc phải làm. Dataframe đang có dấu ngoặc vuông không mong muốn bao quanh mỗi hàng. Bạn có thể dùng phương thức strip() để loại bỏ dấu ngoặc vuông mở ở cột "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
Bảng đang thiếu tiêu đề cột. Bạn có thể dùng phương thức find_all() để lấy các tiêu đề cột.
col_labels = soup.find_all('th')
Tương tự các hàng, bạn có thể dùng BeautifulSoup để trích xuất văn bản giữa các thẻ html cho tiêu đề cột.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Sau đó, bạn có thể chuyển danh sách tiêu đề thành một dataframe của pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Place, Bib, Name, Gender, City, State, Chip T... |
Tương tự, bạn có thể tách cột "0" thành nhiều cột tại vị trí dấu phẩy cho tất cả các hàng.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Hai dataframe có thể được nối lại thành một bằng phương thức concat() như minh họa dưới đây.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Dưới đây là cách gán hàng đầu tiên làm tiêu đề bảng.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

Ở thời điểm này, bảng gần như đã được định dạng đúng. Để phân tích, bạn có thể bắt đầu bằng cách có cái nhìn tổng quan về dữ liệu như bên dưới.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
Bảng có 597 hàng và 14 cột. Bạn có thể loại bỏ tất cả các hàng có giá trị thiếu bất kỳ.
df6 = df5.dropna(axis=0, how='any')
Ngoài ra, lưu ý tiêu đề bảng bị lặp lại là hàng đầu tiên trong df5. Có thể xóa bằng dòng mã sau.
df7 = df6.drop(df6.index[0])
df7.head()

Bạn có thể làm sạch dữ liệu thêm bằng cách đổi tên các cột '[Place' và ' Team]'. Python rất khắt khe với khoảng trắng. Hãy chắc chắn bạn thêm dấu cách sau dấu nháy trong ' Team]'.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

Bước làm sạch dữ liệu cuối cùng là loại bỏ dấu ngoặc đóng cho các ô trong cột ' Team' .
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Mất một lúc để đến đây, nhưng lúc này dataframe đã ở định dạng mong muốn. Giờ bạn có thể chuyển sang phần thú vị hơn: vẽ biểu đồ dữ liệu và tính toán các thống kê thú vị.
Câu hỏi đầu tiên: thời gian về đích trung bình (tính bằng phút) của các vận động viên là bao nhiêu? Bạn cần chuyển cột "Chip Time" về chỉ phút. Một cách là chuyển cột này thành danh sách trước để thao tác.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
Bước tiếp theo là chuyển danh sách trở lại dataframe và tạo một cột mới (Runner_mins) cho thời gian chip của vận động viên chỉ tính theo phút.
df7['Runner_mins'] = time_mins
df7.head()

Đoạn mã dưới đây cho thấy cách tính các thống kê cho các cột số trong dataframe.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| count | 577.000000 |
| mean | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
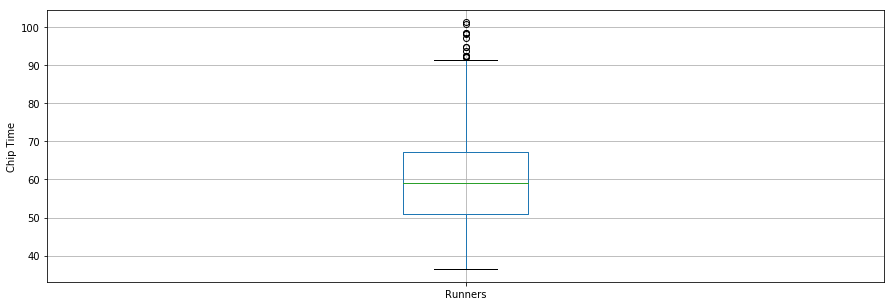
Thú vị là thời gian chip trung bình cho tất cả các vận động viên khoảng ~60 phút. Vận động viên chạy 10K nhanh nhất hoàn thành trong 36,35 phút, và chậm nhất trong 101,30 phút.
Biểu đồ hộp là một công cụ hữu ích khác để trực quan hóa thống kê tóm tắt (giá trị lớn nhất, nhỏ nhất, trung vị, tứ phân vị thứ nhất, tứ phân vị thứ ba, bao gồm ngoại lệ). Dưới đây là thống kê tóm tắt cho các vận động viên thể hiện bằng biểu đồ hộp. Để trực quan hóa dữ liệu, tiện nhất là nhập trước các tham số từ mô-đun pylab đi kèm matplotlib và đặt cùng kích thước cho mọi hình để khỏi phải đặt cho từng hình.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
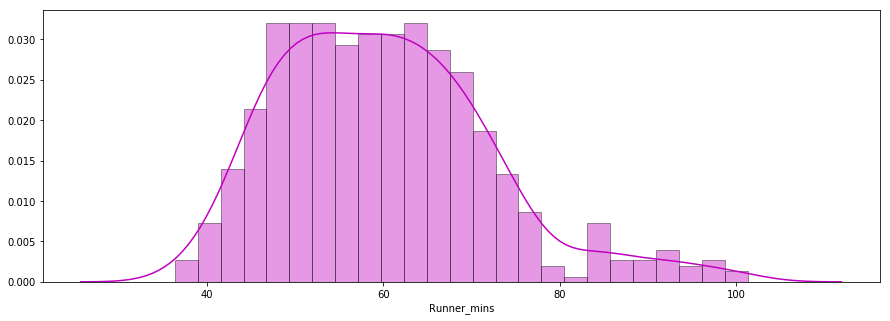
Câu hỏi thứ hai: Thời gian về đích của các vận động viên có tuân theo phân phối chuẩn không?
Dưới đây là biểu đồ phân phối thời gian chip của vận động viên vẽ bằng thư viện seaborn. Phân phối trông gần như chuẩn.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
Câu hỏi thứ ba liên quan đến việc liệu có sự khác biệt về thành tích giữa nam và nữ ở các nhóm tuổi khác nhau không. Dưới đây là biểu đồ phân phối thời gian chip cho nam và nữ.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
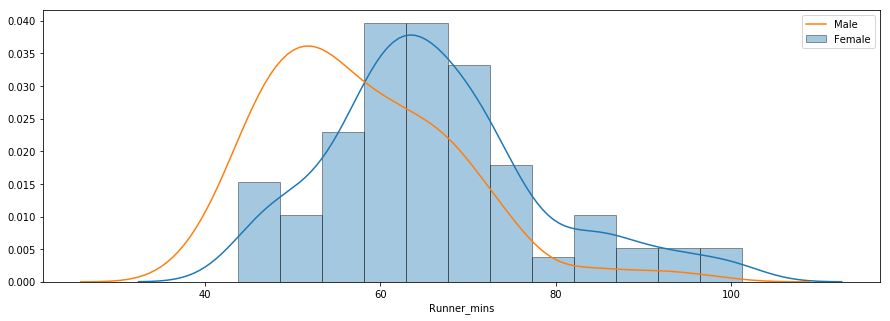
Phân phối cho thấy trung bình nữ chậm hơn nam. Bạn có thể dùng phương thức groupby() để tính thống kê tóm tắt riêng cho nam và nữ như dưới đây.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
Thời gian chip trung bình của tất cả nữ và nam lần lượt là ~66 phút và ~58 phút. Dưới đây là biểu đồ hộp so sánh cạnh nhau giữa thời gian về đích của nam và nữ.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

Trong hướng dẫn này, bạn đã thực hiện web scraping bằng Python. Bạn đã dùng thư viện Beautiful Soup để phân tích dữ liệu html và chuyển nó sang dạng có thể dùng để phân tích. Bạn đã làm sạch dữ liệu trong Python và tạo các biểu đồ hữu ích (box plot, bar plot và biểu đồ phân phối) để bộc lộ các xu hướng thú vị bằng thư viện matplotlib và seaborn của Python. Sau hướng dẫn này, bạn sẽ có thể dễ dàng dùng Python để lấy dữ liệu từ web, áp dụng kỹ thuật làm sạch và rút ra insight hữu ích từ dữ liệu.
Nếu bạn muốn tìm hiểu thêm về Python, hãy tham gia khóa miễn phí Intro to Python for Data Science của DataCamp và xem hướng dẫn cách thu thập dữ liệu Amazon bằng python.
Tìm hiểu thêm về Python
Courses
Courses
Courses