Web Scraping in Python
BeginnerSkill Level
4 h
84.2K learners
Web scraping é um termo usado para descrever o uso de um programa ou algoritmo para extrair e processar grandes quantidades de dados da Web. Se você é um cientista de dados, engenheiro ou qualquer pessoa que analise grandes quantidades de conjuntos de dados, a capacidade de extrair dados da Web é uma habilidade útil. Digamos que você encontre dados da Web e não haja uma maneira direta de baixá-los. A raspagem da Web usando Python é uma habilidade que você pode usar para extrair os dados em um formato útil que possa ser importado.
Neste tutorial, você aprenderá o seguinte:
O conjunto de dados usado neste tutorial foi extraído de uma corrida de 10 km realizada em Hillsboro, OR, em junho de 2017. Especificamente, você analisará o desempenho dos corredores de 10 km e responderá a perguntas como
Usando o Jupyter Notebook, você deve começar importando os módulos necessários (pandas, numpy, matplotlib.pyplot, seaborn). Se você não tiver o Jupyter Notebook instalado, recomendo que o instale usando a distribuição Anaconda Python, disponível na Internet. Para exibir facilmente os gráficos, certifique-se de incluir a linha %matplotlib inline, conforme mostrado abaixo.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Para realizar a raspagem da Web, você também deve importar as bibliotecas mostradas abaixo. O módulo urllib.request é usado para abrir URLs. O pacote Beautiful Soup é usado para extrair dados de arquivos html. O nome da biblioteca Beautiful Soup é bs4, que significa Beautiful Soup, versão 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Depois de importar os módulos necessários, você deve especificar o URL que contém o conjunto de dados e passá-lo para urlopen() para obter o html da página.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Obter o html da página é apenas a primeira etapa. A próxima etapa é criar um objeto Beautiful Soup a partir do html. Isso é feito passando o html para a função BeautifulSoup(). O pacote Beautiful Soup é usado para analisar o html, ou seja, pegar o texto html bruto e dividi-lo em objetos Python. O segundo argumento 'lxml' é o analisador de html, com cujos detalhes você não precisa se preocupar neste momento.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
O objeto soup permite extrair informações interessantes sobre o site que você está extraindo, como obter o título da página, conforme mostrado abaixo.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Você também pode obter o texto da página da Web e imprimi-lo rapidamente para verificar se é o que você espera.
# Print out the text
text = soup.get_text()
#print(soup.text)
Você pode visualizar o html da página da Web clicando com o botão direito do mouse em qualquer lugar da página e selecionando "Inspecionar". É assim que você vê o resultado.
Você pode usar o método find_all() do soup para extrair tags html úteis em uma página da Web. Exemplos de tags úteis incluem < a > para hiperlinks, < table > para tabelas, < tr > para linhas de tabelas, < th > para cabeçalhos de tabelas e < td > para células de tabelas. O código abaixo mostra como você pode extrair todos os hiperlinks da página da Web.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Como você pode ver no resultado acima, as tags html às vezes vêm com atributos como class, src, etc. Esses atributos fornecem informações adicionais sobre os elementos html. Você pode usar um loop for e o método get('"href") para extrair e imprimir somente os hiperlinks.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Para imprimir somente as linhas da tabela, passe o argumento 'tr' em soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
O objetivo deste tutorial é pegar uma tabela de uma página da Web e convertê-la em um dataframe para facilitar a manipulação usando Python. Para chegar lá, você deve primeiro obter todas as linhas da tabela em forma de lista e, em seguida, converter essa lista em um dataframe. Abaixo está um loop for que itera pelas linhas da tabela e imprime as células das linhas.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
A saída acima mostra que cada linha é impressa com tags html incorporadas em cada linha. Não é isso que você deseja. Você pode remover as tags html usando Beautiful Soup ou expressões regulares.
A maneira mais fácil de remover tags html é usar o Beautiful Soup, e você só precisa de uma linha de código para fazer isso. Passe a string de interesse para BeautifulSoup() e use o método get_text() para extrair o texto sem as tags html.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
O uso de expressões regulares é altamente desaconselhado, pois requer várias linhas de código e você pode cometer erros facilmente. Isso requer a importação do módulo re (para expressões regulares). O código abaixo mostra como criar uma expressão regular que localiza todos os caracteres dentro das tags html < td > e os substitui por uma string vazia para cada linha da tabela. Primeiro, você compila uma expressão regular passando uma string para corresponder a re.compile(). O ponto, a estrela e o ponto de interrogação (.*?) corresponderão a um colchete angular de abertura seguido por qualquer coisa e seguido por um colchete angular de fechamento. Ele corresponde ao texto de forma não gananciosa, ou seja, corresponde à string mais curta possível. Se você omitir o ponto de interrogação, ele corresponderá a todo o texto entre o primeiro colchete angular de abertura e o último colchete angular de fechamento. Depois de compilar uma expressão regular, você pode usar o método re.sub() para localizar todas as substrings em que a expressão regular corresponde e substituí-las por uma string vazia. O código completo abaixo gera uma lista vazia, extrai o texto entre as tags html de cada linha e o anexa à lista atribuída.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
A próxima etapa é converter a lista em um dataframe e obter uma visualização rápida das 10 primeiras linhas usando o Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finalizadores:, 577] |
| 1 | [Male:, 414] |
| 2 | [Feminino:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
O dataframe não está no formato que você deseja. Para limpá-la, você deve dividir a coluna "0" em várias colunas na posição da vírgula. Isso é feito com o uso do método str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Isso parece muito melhor, mas ainda há trabalho a ser feito. O dataframe tem colchetes indesejados ao redor de cada linha. Você pode usar o método strip() para remover o colchete de abertura na coluna "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
A tabela não tem cabeçalhos de tabela. Você pode usar o método find_all() para obter os cabeçalhos da tabela.
col_labels = soup.find_all('th')
Da mesma forma que as linhas da tabela, você pode usar o Beautiful Soup para extrair o texto entre as tags html para os cabeçalhos da tabela.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Em seguida, você pode converter a lista de cabeçalhos em um dataframe do pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Local, código de barras, nome, sexo, cidade, estado, chip T... |
Da mesma forma, você pode dividir a coluna "0" em várias colunas na posição de vírgula para todas as linhas.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Os dois quadros de dados podem ser concatenados em um usando o método concat(), conforme ilustrado abaixo.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

A seguir, você verá como atribuir a primeira linha como cabeçalho da tabela.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

Nesse ponto, a tabela está quase devidamente formatada. Para análise, você pode começar obtendo uma visão geral dos dados, conforme mostrado abaixo.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
A tabela tem 597 linhas e 14 colunas. Você pode eliminar todas as linhas com valores ausentes.
df6 = df5.dropna(axis=0, how='any')
Além disso, observe como o cabeçalho da tabela é replicado como a primeira linha em df5. Ele pode ser eliminado usando a seguinte linha de código.
df7 = df6.drop(df6.index[0])
df7.head()

Você pode realizar mais limpeza de dados renomeando as colunas '[Place' e ' Team]'. A Python é muito exigente quanto ao espaço. Certifique-se de incluir um espaço após as aspas em ' Team]'.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

A etapa final de limpeza de dados envolve a remoção do colchete de fechamento das células na coluna "Equipe".
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Você demorou um pouco para chegar até aqui, mas, neste ponto, o dataframe está no formato desejado. Agora você pode passar para a parte interessante e começar a plotar os dados e calcular estatísticas interessantes.
A primeira pergunta a ser respondida é: qual foi o tempo médio de chegada (em minutos) dos corredores? Você precisa converter a coluna "Chip Time" em apenas minutos. Uma maneira de fazer isso é converter a coluna em uma lista primeiro para que você possa manipulá-la.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
A próxima etapa é converter a lista novamente em um quadro de dados e criar uma nova coluna ("Runner_mins") para os tempos de chip dos corredores expressos em apenas minutos.
df7['Runner_mins'] = time_mins
df7.head()

O código abaixo mostra como calcular estatísticas para colunas numéricas somente no dataframe.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| contar | 577.000000 |
| média | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
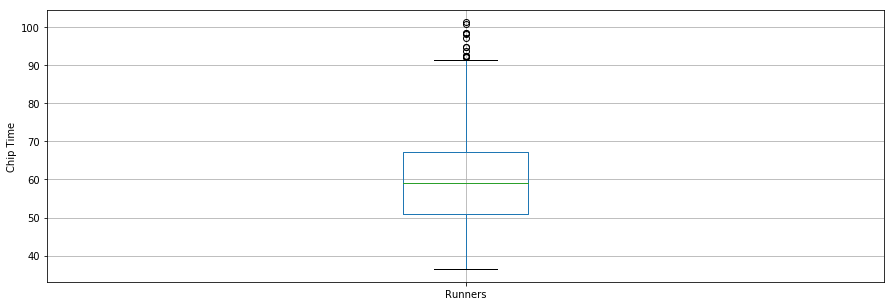
É interessante notar que o tempo médio de chip de todos os corredores foi de aproximadamente 60 minutos. O corredor mais rápido dos 10 km terminou em 36,35 minutos e o corredor mais lento terminou em 101,30 minutos.
Um boxplot é outra ferramenta útil para visualizar estatísticas resumidas (máximo, mínimo, médio, primeiro quartil, terceiro quartil, incluindo outliers). Abaixo estão as estatísticas de resumo de dados para os corredores mostradas em um boxplot. Para a visualização de dados, é conveniente primeiro importar os parâmetros do módulo pylab que vem com o matplotlib e definir o mesmo tamanho para todas as figuras para evitar que você faça isso para cada figura.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
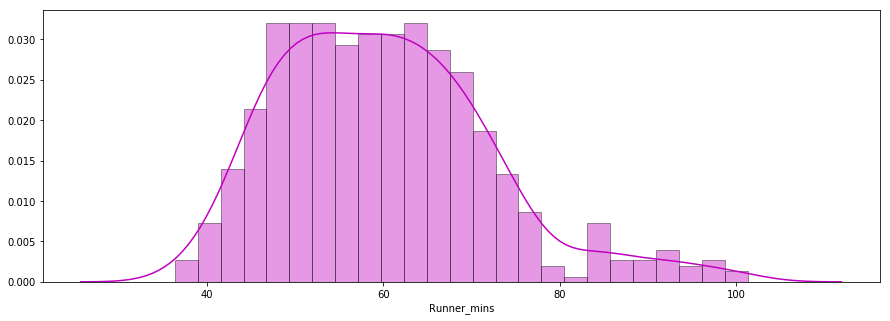
A segunda pergunta a ser respondida é: Os tempos de chegada dos corredores seguiram uma distribuição normal?
Abaixo, você vê um gráfico de distribuição dos tempos de chip dos corredores plotados usando a biblioteca seaborn. A distribuição parece quase normal.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
A terceira pergunta trata da existência de diferenças de desempenho entre homens e mulheres de várias faixas etárias. Abaixo você encontra um gráfico de distribuição dos tempos de chip para homens e mulheres.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
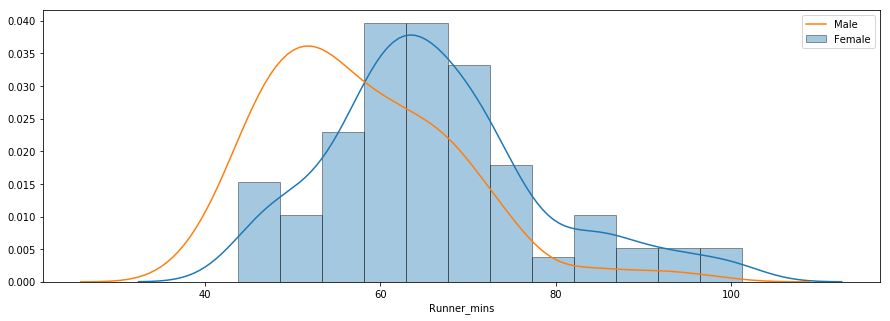
A distribuição indica que as mulheres foram mais lentas do que os homens, em média. Você pode usar o método groupby() para calcular estatísticas resumidas para homens e mulheres separadamente, conforme mostrado abaixo.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
O tempo médio de chip para todas as mulheres e homens foi de aproximadamente 66 minutos e 58 minutos, respectivamente. Abaixo você encontra uma comparação lado a lado dos tempos de chegada de homens e mulheres.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

Neste tutorial, você realizou a raspagem da Web usando Python. Você usou a biblioteca Beautiful Soup para analisar dados html e convertê-los em um formulário que pode ser usado para análise. Você realizou a limpeza dos dados em Python e criou gráficos úteis (gráficos de caixa, gráficos de barras e gráficos de distribuição) para revelar tendências interessantes usando as bibliotecas matplotlib e seaborn do Python. Após este tutorial, você deverá ser capaz de usar o Python para extrair facilmente dados da Web, aplicar técnicas de limpeza e extrair insights úteis dos dados.
Se você quiser saber mais sobre Python, faça o curso gratuito Intro to Python for Data Science da DataCamp e confira nosso tutorial sobre como fazer scraping da Amazon usando python.
Saiba mais sobre Python
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Vidhi Chugh
Tutorial
Karlijn Willems
Tutorial
Kevin Babitz
Tutorial
Moez Ali

