Web Scraping in Python
BasicSkill Level
4 h
92.8K learners
Web scraping è un termine usato per descrivere l’uso di un programma o di un algoritmo per estrarre ed elaborare grandi quantità di dati dal web. Che tu sia un data scientist, un ingegnere o chiunque analizzi grandi moli di dati, la capacità di fare scraping dal web è una competenza utile. Mettiamo che trovi dei dati online e non ci sia un modo diretto per scaricarli: lo scraping con Python è un’abilità che puoi usare per estrarre i dati in un formato utile e importabile.
In questo tutorial imparerai a:
Il dataset usato in questo tutorial proviene da una gara da 10 km che si è tenuta a Hillsboro, OR, a giugno 2017. In particolare, analizzerai le prestazioni dei corridori dei 10 km e risponderai a domande come:
Usando Jupyter Notebook, inizia importando i moduli necessari (pandas, numpy, matplotlib.pyplot, Seaborn). Se non hai installato Jupyter Notebook, ti consiglio di installarlo tramite la distribuzione Anaconda di Python, disponibile online. Per visualizzare facilmente i grafici, assicurati di includere la riga %matplotlib inline come mostrato sotto.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Per eseguire il web scraping, importa anche le librerie qui sotto. Il modulo urllib.request serve per aprire URL. Il pacchetto BeautifulSoup è usato per estrarre dati da file HTML. Il nome della libreria BeautifulSoup è bs4, che sta per BeautifulSoup, versione 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Dopo aver importato i moduli necessari, specifica l’URL che contiene il dataset e passalo a urlopen() per ottenere l’HTML della pagina.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Ottenere l’HTML della pagina è solo il primo passo. Il successivo è creare un oggetto BeautifulSoup a partire dall’HTML. Questo si fa passando l’HTML alla funzione BeautifulSoup(). Il pacchetto BeautifulSoup serve a effettuare il parsing dell’HTML, cioè a prendere il testo HTML grezzo e convertirlo in oggetti Python. Il secondo argomento lxml è il parser HTML: per ora non serve conoscerne i dettagli.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
L’oggetto soup ti permette di estrarre informazioni interessanti sul sito che stai analizzando, ad esempio ottenere il titolo della pagina come mostrato sotto.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Puoi anche ricavare il testo della pagina web e stamparlo rapidamente per verificare che sia quello che ti aspetti.
# Print out the text
text = soup.get_text()
#print(soup.text)
Puoi visualizzare l’HTML della pagina facendo clic con il tasto destro in un punto qualsiasi della pagina e selezionando "Inspect". Il risultato appare così.
Puoi usare il metodo find_all() di soup per estrarre tag HTML utili all’interno di una pagina. Esempi di tag utili includono < a > per i collegamenti ipertestuali, < table > per le tabelle, < tr > per le righe, < th > per le intestazioni e < td > per le celle. Il codice seguente mostra come estrarre tutti i collegamenti ipertestuali presenti nella pagina.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Come vedi dall’output sopra, i tag HTML a volte hanno attributi come class, src, ecc. Questi attributi forniscono informazioni aggiuntive sugli elementi HTML. Puoi usare un ciclo for e il metodo get("href") per estrarre e stampare solo i link.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Per stampare solo le righe della tabella, passa l’argomento tr in soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
L’obiettivo di questo tutorial è prendere una tabella da una pagina web e convertirla in un dataframe per manipolarla più facilmente con Python. Per arrivarci, prima recupera tutte le righe della tabella sotto forma di lista e poi converti quella lista in un dataframe. Sotto trovi un ciclo for che itera sulle righe della tabella e stampa le celle delle righe.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
L’output sopra mostra che ogni riga è stampata con i tag HTML incorporati. Non è quello che vogliamo. Puoi rimuovere i tag HTML usando Beautiful Soup o le espressioni regolari.
Il modo più semplice per rimuovere i tag HTML è usare BeautifulSoup, e basta una riga di codice. Passa la stringa di interesse a BeautifulSoup() e usa il metodo get_text() per estrarre il testo senza i tag HTML.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Usare le espressioni regolari è fortemente sconsigliato, perché richiede diverse righe di codice ed è facile sbagliare. Serve importare il modulo re (per le espressioni regolari). Il codice sotto mostra come costruire un’espressione regolare che trovi tutti i caratteri all’interno dei tag HTML < td > e li sostituisca con una stringa vuota per ogni riga della tabella. Per prima cosa compili un’espressione regolare passando a re.compile() una stringa da cercare. Il punto, l’asterisco e il punto interrogativo (.*?) corrispondono a una parentesi angolare aperta seguita da qualsiasi cosa e poi da una parentesi angolare chiusa. Effettua il match in modo non avido, cioè sul testo più corto possibile. Se ometti il punto interrogativo, verrà fatto il match di tutto il testo tra la prima parentesi angolare aperta e l’ultima chiusa. Dopo aver compilato l’espressione regolare, puoi usare il metodo re.sub() per trovare tutte le sottostringhe che corrispondono all’espressione e sostituirle con una stringa vuota. Il codice completo qui sotto genera una lista vuota, estrae il testo tra i tag HTML per ogni riga e lo aggiunge alla lista.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
Il passo successivo è convertire la lista in un dataframe e dare un’occhiata rapida alle prime 10 righe con Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers:, 577] |
| 1 | [Male:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Il dataframe non è nel formato desiderato. Per ripulirlo, dividi la colonna "0" in più colonne in corrispondenza delle virgole. Questo si fa con il metodo str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Va già meglio, ma c’è ancora da fare. Il dataframe ha delle parentesi quadre indesiderate all’inizio e alla fine di ogni riga. Puoi usare il metodo strip() per rimuovere la parentesi quadra di apertura sulla colonna "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
Alla tabella mancano le intestazioni. Puoi usare il metodo find_all() per ottenere le intestazioni della tabella.
col_labels = soup.find_all('th')
Come per le righe, puoi usare BeautifulSoup per estrarre il testo tra i tag HTML anche per le intestazioni.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Puoi quindi convertire la lista di intestazioni in un dataframe pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Place, Bib, Name, Gender, City, State, Chip T... |
Allo stesso modo, puoi dividere la colonna "0" in più colonne in corrispondenza delle virgole per tutte le righe.
df3 = df2[0].str.split(',', expand=True)
df3.head()

I due dataframe possono essere concatenati in uno solo usando il metodo concat() come illustrato sotto.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Qui sotto vedi come impostare la prima riga come intestazione della tabella.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

A questo punto, la tabella è quasi formattata correttamente. Per l’analisi, puoi iniziare ottenendo una panoramica dei dati come mostrato sotto.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
La tabella ha 597 righe e 14 colonne. Puoi eliminare tutte le righe con valori mancanti.
df6 = df5.dropna(axis=0, how='any')
Nota anche come l’intestazione della tabella sia replicata come prima riga in df5. Può essere rimossa con la riga seguente.
df7 = df6.drop(df6.index[0])
df7.head()

Puoi fare altra pulizia rinominando le colonne '[Place' e ' Team]'. Python è molto severo con gli spazi: assicurati di includere lo spazio dopo l’apice in ' Team]'.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

L’ultimo passaggio di pulizia consiste nel rimuovere la parentesi di chiusura per le celle nella colonna ' Team' .
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Ci è voluto un po’ per arrivare fin qui, ma ora il dataframe è nel formato desiderato. Adesso puoi passare alla parte interessante: creare grafici sui dati e calcolare statistiche utili.
La prima domanda: qual è stato il tempo medio di arrivo (in minuti) dei corridori? Devi convertire la colonna "Chip Time" in soli minuti. Un modo per farlo è prima convertire la colonna in una lista per manipolarla.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
Il passo successivo è riconvertire la lista in un dataframe e creare una nuova colonna (Runner_mins) con i chip time dei corridori espressi solo in minuti.
df7['Runner_mins'] = time_mins
df7.head()

Il codice sotto mostra come calcolare le statistiche solo per le colonne numeriche del dataframe.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| count | 577.000000 |
| mean | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
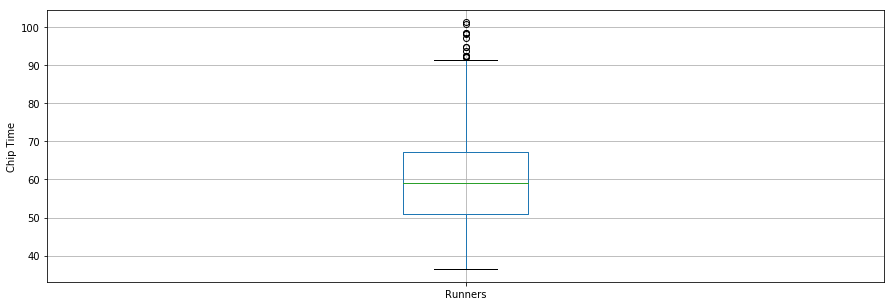
Curiosamente, il chip time medio per tutti i corridori è stato ~60 minuti. Il corridore più veloce sui 10 km ha finito in 36,35 minuti, e il più lento in 101,30 minuti.
Un boxplot è un altro strumento utile per visualizzare statistiche riassuntive (massimo, minimo, mediana, primo quartile, terzo quartile, inclusi gli outlier). Sotto trovi le statistiche riassuntive dei corridori mostrate in un boxplot. Per la visualizzazione, conviene prima importare i parametri dal modulo pylab che accompagna matplotlib e impostare la stessa dimensione per tutte le figure, così da non doverlo fare ogni volta.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
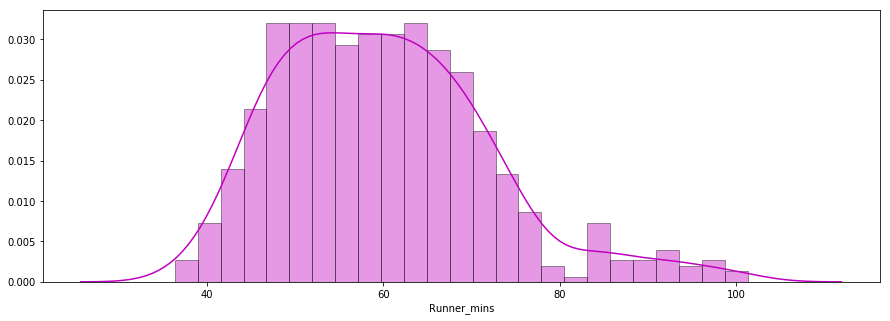
La seconda domanda: i tempi di arrivo hanno seguito una distribuzione normale?
Qui sotto c’è un grafico di distribuzione dei chip time dei corridori tracciato con la libreria seaborn. La distribuzione sembra quasi normale.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
La terza domanda riguarda l’eventuale differenza di prestazioni tra uomini e donne in varie fasce d’età. Qui sotto c’è un grafico di distribuzione dei chip time per uomini e donne.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
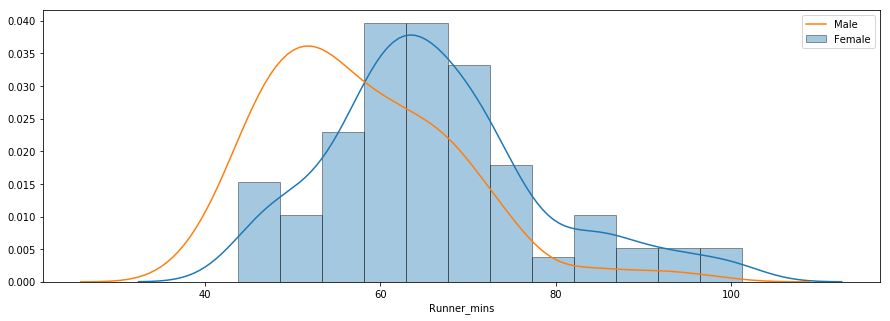
La distribuzione indica che in media le donne sono state più lente degli uomini. Puoi usare il metodo groupby() per calcolare separatamente le statistiche riassuntive per uomini e donne, come mostrato sotto.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
Il chip time medio per tutte le donne e gli uomini è stato rispettivamente di ~66 e ~58 minuti. Sotto trovi un boxplot affiancato che confronta i tempi di arrivo di uomini e donne.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

In questo tutorial hai eseguito web scraping con Python. Hai usato la libreria Beautiful Soup per effettuare il parsing dei dati HTML e convertirli in una forma utilizzabile per l’analisi. Hai pulito i dati in Python e creato grafici utili (box plot, bar plot e grafici di distribuzione) per mettere in evidenza tendenze interessanti usando le librerie matplotlib e seaborn di Python. Dopo questo tutorial, dovresti essere in grado di usare Python per fare facilmente scraping dal web, applicare tecniche di pulizia ed estrarre insight utili dai dati.
Se vuoi saperne di più su Python, segui il corso gratuito di DataCamp Intro to Python for Data Science e dai un’occhiata al nostro tutorial su come fare scraping di Amazon con Python.
Scopri di più su Python
Corso
Corso
Corso