Web Scraping in Python
BasicSkill Level
4 sa
92.8K learners
Web kazıma, webden büyük miktarda veriyi çıkarmak ve işlemek için bir program veya algoritma kullanmayı ifade eden bir terimdir. İster veri bilimcisi, ister mühendis ya da büyük veri kümelerini analiz eden biri olun, webden veri kazıyabilme becerisi faydalıdır. Diyelim ki webde bir veri buldunuz ve bunu indirmenin doğrudan bir yolu yok; Python ile web kazıma, veriyi içe aktarılabilir yararlı bir biçime çıkarmak için kullanabileceğiniz bir beceridir.
Bu eğitimde aşağıdakileri öğreneceksiniz:
Bu eğitimde kullanılan veri kümesi, Haziran 2017'de Hillsboro, OR'da gerçekleşen bir 10K koşusundan alınmıştır. Özellikle 10K koşucularının performansını analiz edecek ve şu gibi soruları yanıtlayacaksınız:
Jupyter Notebook kullanarak, gerekli modülleri (pandas, numpy, matplotlib.pyplot, Seaborn) içe aktararak başlamalısınız. Jupyter Notebook kurulu değilse, internette bulunan Anaconda Python dağıtımı ile kurmanızı öneririm. Grafiklerin kolayca görüntülenmesi için, aşağıda gösterildiği gibi %matplotlib inline satırını eklediğinizden emin olun.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Web kazıma yapmak için aşağıda gösterilen kütüphaneleri de içe aktarmalısınız. urllib.request modülü URL'leri açmak için kullanılır. BeautifulSoup paketi ise html dosyalarından veri çıkarmak için kullanılır. BeautifulSoup kütüphanesinin adı bs4’tür; BeautifulSoup sürüm 4 anlamına gelir.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Gerekli modülleri içe aktardıktan sonra, veri kümesini içeren URL’yi belirtip sayfanın html’ini almak için urlopen() fonksiyonuna geçirmelisiniz.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Sayfanın html’ini almak sadece ilk adımdır. Sonraki adım, bu html’den bir BeautifulSoup nesnesi oluşturmaktır. Bu, html’yi BeautifulSoup() fonksiyonuna geçirerek yapılır. BeautifulSoup paketi, ham html metnini alıp Python nesnelerine ayırarak html’yi ayrıştırmak için kullanılır. İkinci argüman olan lxml, html ayrıştırıcısıdır; ayrıntıları bu noktada dert etmenize gerek yok.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
soup nesnesi, kazıma yaptığınız web sitesi hakkında ilginç bilgiler çıkarmanıza olanak tanır; örneğin aşağıda gösterildiği gibi sayfanın başlığını alabilirsiniz.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Ayrıca web sayfasının metnini alıp hızlıca yazdırarak beklediğiniz gibi olup olmadığını kontrol edebilirsiniz.
# Print out the text
text = soup.get_text()
#print(soup.text)
Bir web sayfasının html’ini, sayfanın herhangi bir yerine sağ tıklayıp "İncele"yi seçerek görüntüleyebilirsiniz. Sonuç aşağıdaki gibidir.
Bir web sayfasındaki yararlı html etiketlerini çıkarmak için soup’un find_all() metodunu kullanabilirsiniz. Yararlı etiket örnekleri arasında bağlantılar için < a >, tablolar için < table >, satırlar için < tr >, başlıklar için < th > ve hücreler için < td > bulunur. Aşağıdaki kod, web sayfasındaki tüm bağlantıların nasıl çıkarılacağını gösterir.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Yukarıdaki çıktıda görüldüğü gibi, html etiketleri bazen class, src vb. özniteliklerle gelir. Bu öznitelikler, html öğeleri hakkında ilave bilgi sağlar. Bir for döngüsü ve get("href") metodunu kullanarak yalnızca bağlantıları çıkarıp yazdırabilirsiniz.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Yalnızca tablo satırlarını yazdırmak için, soup.find_all() içinde tr argümanını geçin.
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Bu eğitimin hedefi, bir web sayfasındaki bir tabloyu alıp Python kullanarak daha kolay işlem yapmak için bir veri çerçevesine (dataframe) dönüştürmektir. Bunun için önce tüm tablo satırlarını liste biçiminde almalı, ardından bu listeyi bir veri çerçevesine dönüştürmelisiniz. Aşağıda, tablo satırlarında dolaşıp satır hücrelerini yazdıran bir for döngüsü yer alır.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
Yukarıdaki çıktı, her satırın içinde gömülü html etiketleriyle basıldığını gösterir. İstediğiniz bu değildir. Html etiketlerini Beautiful Soup veya düzenli ifadelerle kaldırabilirsiniz.
Html etiketlerini kaldırmanın en kolay yolu BeautifulSoup kullanmaktır ve bunu yapmak yalnızca tek satır kod gerektirir. İlgilendiğiniz dizeyi BeautifulSoup() içine geçirin ve get_text() metodunu kullanarak html etiketleri olmadan metni çıkarın.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Düzenli ifadeler kullanmak pek tavsiye edilmez; çünkü birkaç satır kod gerektirir ve kolayca hata yapılabilir. re (düzenli ifadeler için) modülünü içe aktarmayı gerektirir. Aşağıdaki kod, < td > html etiketlerinin içindeki tüm karakterleri bulan ve her tablo satırı için bunları boş bir dizeyle değiştiren bir düzenli ifadeyi nasıl oluşturacağınızı gösterir. Önce, eşleştirilecek bir dizeyi re.compile() fonksiyonuna geçirerek bir düzenli ifade derlersiniz. Nokta, yıldız ve soru işareti (.*?) bir açılı ayraç, ardından herhangi bir şey ve ardından kapanış ayraçla eşleşir. Metni açgözlü olmayan biçimde eşleştirir; yani mümkün olan en kısa dizeyle eşleşir. Soru işaretini atarsanız, ilk açılı ayraç ile son kapanış ayraç arasındaki tüm metinle eşleşir. Bir düzenli ifade derledikten sonra, re.sub() metodunu kullanarak düzenli ifadeyle eşleşen tüm alt dizeleri bulup bunları boş bir dizeyle değiştirebilirsiniz. Aşağıdaki tam kod bir boş liste üretir, her satır için html etiketleri arasındaki metni çıkarır ve atanan listeye ekler.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
Sonraki adım, listeyi bir veri çerçevesine dönüştürmek ve Pandas kullanarak ilk 10 satıra hızlıca göz atmaktır.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers:, 577] |
| 1 | [Male:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Veri çerçevesi istediğimiz biçimde değil. Temizlemek için, "0" sütununu virgül konumundan birden çok sütuna bölmelisiniz. Bu, str.split() yöntemiyle yapılır.
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Bu çok daha iyi görünüyor, ancak hâlâ yapılacak işler var. Veri çerçevesinde her satırı saran köşeli parantezler istenmiyor. "0" sütunundaki açılış köşeli parantezi kaldırmak için strip() metodunu kullanabilirsiniz.
df1[0] = df1[0].str.strip('[')
df1.head(10)
Tabloda tablo başlıkları eksik. Tablo başlıklarını almak için find_all() metodunu kullanabilirsiniz.
col_labels = soup.find_all('th')
Tablo satırlarına benzer şekilde, tablo başlıkları için de html etiketleri arasındaki metni çıkarmak üzere BeautifulSoup kullanabilirsiniz.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Ardından başlık listesini bir pandas veri çerçevesine dönüştürebilirsiniz.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Place, Bib, Name, Gender, City, State, Chip T... |
Benzer şekilde, tüm satırlar için "0" sütununu virgül konumundan birden çok sütuna bölebilirsiniz.
df3 = df2[0].str.split(',', expand=True)
df3.head()

İki veri çerçevesi, aşağıda gösterildiği gibi concat() yöntemiyle tek bir çerçevede birleştirilebilir.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Aşağıda ilk satırın tablo başlığı olarak nasıl atanacağı gösterilmektedir.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

Bu noktada, tablo neredeyse doğru biçimdedir. Analiz için, aşağıda gösterildiği gibi verilere genel bir bakış alarak başlayabilirsiniz.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
Tabloda 597 satır ve 14 sütun vardır. Herhangi bir eksik değeri olan tüm satırları düşürebilirsiniz.
df6 = df5.dropna(axis=0, how='any')
Ayrıca, df5'te tablo başlığının ilk satır olarak yinelendiğine dikkat edin. Aşağıdaki kod satırıyla kaldırılabilir.
df7 = df6.drop(df6.index[0])
df7.head()

'[Place' ve ' Team]' sütunlarını yeniden adlandırarak daha fazla veri temizliği yapabilirsiniz. Python boşluklar konusunda çok titizdir. ' Team]' içinde tırnaktan sonra boşluk bıraktığınızdan emin olun.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

Son veri temizleme adımı, ' Team' sütunundaki hücreler için kapanış köşeli parantezin kaldırılmasını içerir.
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Buraya gelmek biraz zaman aldı, ancak bu noktada veri çerçevesi istenen biçimdedir. Şimdi heyecanlı kısma geçebilir, veriyi çizdirip ilginç istatistikler hesaplamaya başlayabilirsiniz.
İlk yanıtlanacak soru: Koşucular için ortalama bitiş süresi (dakika cinsinden) neydi? "Chip Time" sütununu yalnızca dakika cinsine dönüştürmeniz gerekir. Bunu yapmanın bir yolu, önce sütunu düzenleme için bir listeye dönüştürmektir.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
Sonraki adım, listeyi tekrar bir veri çerçevesine dönüştürmek ve koşucu çip sürelerini yalnızca dakika cinsinden ifade eden yeni bir sütun (Runner_mins) oluşturmaktır.
df7['Runner_mins'] = time_mins
df7.head()

Aşağıdaki kod, veri çerçevesindeki yalnızca sayısal sütunlar için istatistiklerin nasıl hesaplanacağını gösterir.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| count | 577.000000 |
| mean | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
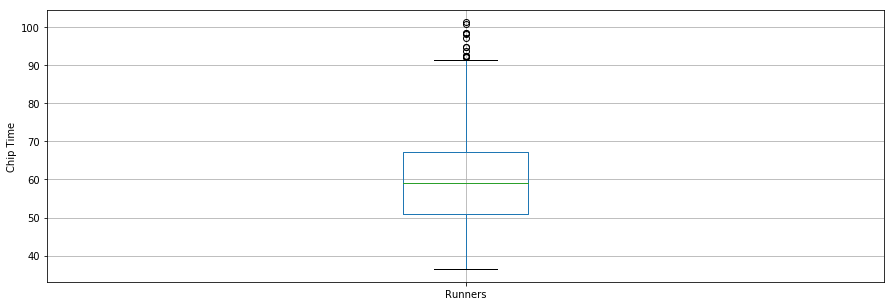
İlginç bir şekilde, tüm koşucular için ortalama çip süresi ~60 dakikadır. En hızlı 10K koşucusu 36,35 dakikada, en yavaş koşucu ise 101,30 dakikada bitirmiştir.
Kutu grafiği, özet istatistikleri (maksimum, minimum, medyan, birinci çeyrek, üçüncü çeyrek ve aykırı değerler dahil) görselleştirmek için başka bir kullanışlı araçtır. Aşağıda koşucular için özet istatistikler bir kutu grafiğinde gösterilmektedir. Veri görselleştirme için, matplotlib ile gelen pylab modülünden parametreleri içe aktarmak ve her şekil için tek tek ayarlamamak adına tüm şekiller için aynı boyutu belirlemek uygundur.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
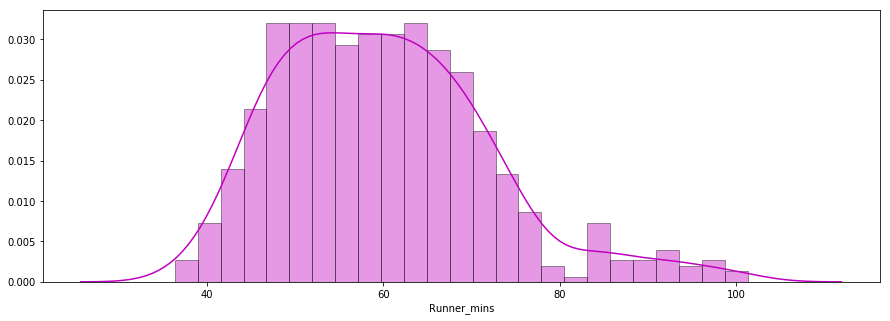
Yanıtlanacak ikinci soru: Koşucuların bitiş süreleri normal dağılımı takip etti mi?
Aşağıda, seaborn kütüphanesi kullanılarak çizilmiş koşucuların çip sürelerinin bir dağılım grafiği yer alır. Dağılım neredeyse normal görünüyor.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
Üçüncü soru, farklı yaş gruplarındaki erkekler ve kadınlar arasında performans farkları olup olmadığıyla ilgilidir. Aşağıda kadın ve erkekler için çip sürelerinin dağılım grafiği gösterilmiştir.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
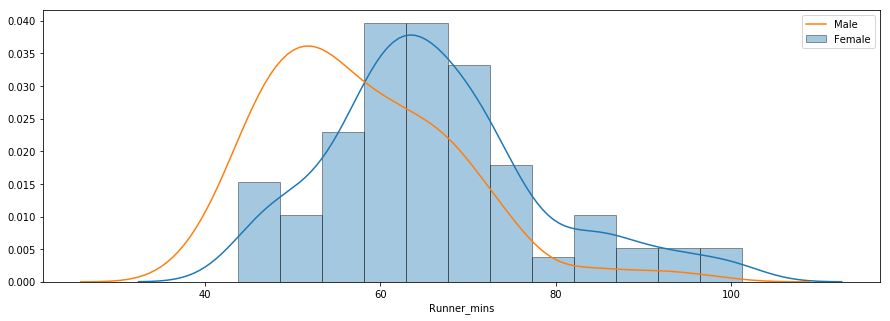
Dağılım, kadınların ortalama olarak erkeklerden daha yavaş olduğunu göstermektedir. Aşağıda gösterildiği gibi, kadınlar ve erkekler için ayrı ayrı özet istatistikler hesaplamak üzere groupby() metodunu kullanabilirsiniz.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
Tüm kadınlar ve erkekler için ortalama çip süresi sırasıyla ~66 dk ve ~58 dk’dır. Aşağıda erkek ve kadın bitiş sürelerinin yan yana kutu grafiği karşılaştırması yer almaktadır.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

Bu eğitimde, Python kullanarak web kazıma yaptınız. Beautiful Soup kütüphanesini kullanarak html verisini ayrıştırıp analize uygun bir biçime dönüştürdünüz. Python’da veri temizliği yaptınız ve Python’un matplotlib ve seaborn kütüphanelerini kullanarak ilginç eğilimleri ortaya koyan yararlı grafikler (kutu grafikleri, çubuk grafikler ve dağılım grafikleri) oluşturdunuz. Bu eğitimden sonra, Python ile webden kolayca veri kazıyabilir, temizleme tekniklerini uygulayabilir ve verilerden yararlı içgörüler çıkarabilirsiniz.
Daha fazla Python öğrenmek isterseniz, DataCamp’in ücretsiz Veri Bilimi için Python’a Giriş kursunu alın ve Python kullanarak Amazon’u nasıl kazıyacağınıza dair eğitimimize göz atın.
Python hakkında daha fazlasını öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
