Web Scraping in Python
BeginnerSkill Level
4 h
84.2K learners
Le web scraping est un terme utilisé pour décrire l'utilisation d'un programme ou d'un algorithme pour extraire et traiter de grandes quantités de données du web. Que vous soyez un data scientist, un ingénieur ou toute personne qui analyse de grandes quantités de données, la capacité à récupérer des données sur le web est une compétence utile. Imaginons que vous trouviez des données sur le web et qu'il n'y ait pas de moyen direct de les télécharger, le web scraping à l'aide de Python est une compétence que vous pouvez utiliser pour extraire les données sous une forme utile qui peut être importée.
Dans ce tutoriel, vous apprendrez ce qui suit :
Le jeu de données utilisé dans ce tutoriel provient d'une course de 10 km qui s'est déroulée à Hillsboro, OR, en juin 2017. Plus précisément, vous analyserez les performances des coureurs du 10 km et répondrez aux questions suivantes :
En utilisant Jupyter Notebook, vous devez commencer par importer les modules nécessaires (pandas, numpy, matplotlib.pyplot, seaborn). Si vous n'avez pas installé Jupyter Notebook, je vous recommande de l'installer en utilisant la distribution Python Anaconda qui est disponible sur internet. Pour afficher facilement les graphiques, assurez-vous d'inclure la ligne %matplotlib inline comme indiqué ci-dessous.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Pour effectuer du web scraping, vous devez également importer les bibliothèques présentées ci-dessous. Le module urllib.request est utilisé pour ouvrir les URL. Le paquet Beautiful Soup est utilisé pour extraire des données de fichiers html. Le nom de la bibliothèque Beautiful Soup est bs4, ce qui signifie Beautiful Soup, version 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Après avoir importé les modules nécessaires, vous devez spécifier l'URL contenant le jeu de données et la passer à urlopen() pour obtenir le html de la page.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Obtenir le code html de la page n'est que la première étape. L'étape suivante consiste à créer un objet Beautiful Soup à partir du code html. Pour ce faire, vous devez transmettre le code html à la fonction BeautifulSoup(). Le paquetage Beautiful Soup est utilisé pour analyser le html, c'est-à-dire prendre le texte html brut et le décomposer en objets Python. Le second argument 'lxml' est l'analyseur html dont vous n'avez pas à vous soucier pour l'instant.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
L'objet soupe vous permet d'extraire des informations intéressantes sur le site web que vous scrapez, par exemple le titre de la page, comme indiqué ci-dessous.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Vous pouvez également obtenir le texte de la page web et l'imprimer rapidement pour vérifier s'il correspond à vos attentes.
# Print out the text
text = soup.get_text()
#print(soup.text)
Vous pouvez visualiser le code html de la page web en cliquant avec le bouton droit de la souris n'importe où sur la page web et en sélectionnant "Inspecter". Voici à quoi ressemble le résultat.
Vous pouvez utiliser la méthode find_all() de soup pour extraire les balises html utiles dans une page web. Voici quelques exemples de balises utiles : < a > pour les hyperliens, < table > pour les tableaux, < tr > pour les rangées de tableaux, < th > pour les en-têtes de tableaux et < td > pour les cellules de tableaux. Le code ci-dessous montre comment extraire tous les liens hypertextes de la page web.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Comme vous pouvez le voir dans le résultat ci-dessus, les balises html sont parfois accompagnées d'attributs tels que class, src, etc. Ces attributs fournissent des informations supplémentaires sur les éléments html. Vous pouvez utiliser une boucle for et la méthode get('"href") pour extraire et imprimer uniquement les liens hypertextes.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Pour imprimer uniquement les tableaux, passez l'argument 'tr' dans soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Le but de ce tutoriel est de prendre un tableau à partir d'une page web et de le convertir en DataFrame pour une manipulation plus facile à l'aide de Python. Pour y parvenir, vous devez d'abord obtenir tous les tableaux sous forme de liste, puis convertir cette liste en DataFrame. Vous trouverez ci-dessous une boucle for qui parcourt les lignes d'un tableau et imprime les cellules des lignes.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
La sortie ci-dessus montre que chaque ligne est imprimée avec des balises html intégrées dans chaque ligne. Ce n'est pas ce que vous souhaitez. Vous pouvez supprimer les balises html en utilisant Beautiful Soup ou des expressions régulières.
La façon la plus simple de supprimer les balises html est d'utiliser Beautiful Soup, et il suffit d'une ligne de code pour le faire. Passez la chaîne de caractères qui vous intéresse à BeautifulSoup() et utilisez la méthode get_text() pour extraire le texte sans les balises html.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
L'utilisation d'expressions régulières est fortement déconseillée car elle nécessite plusieurs lignes de code et l'on peut facilement faire des erreurs. Il faut importer le module re (pour regular expressions). Le code ci-dessous montre comment construire une expression régulière qui trouve tous les caractères à l'intérieur des balises html < td > et les remplace par une chaîne vide pour chaque ligne du tableau. Tout d'abord, vous compilez une expression régulière en passant une chaîne de caractères à faire correspondre à re.compile(). Le point, l'étoile et le point d'interrogation (.* ?) correspondent à un crochet d'ouverture suivi de n'importe quoi et suivi d'un crochet de fermeture. Il recherche du texte de manière non gourmande, c'est-à-dire qu'il recherche la chaîne de caractères la plus courte possible. Si vous omettez le point d'interrogation, la recherche portera sur tout le texte compris entre le premier crochet ouvrant et le dernier crochet fermant. Après avoir compilé une expression régulière, vous pouvez utiliser la méthode re.sub() pour trouver toutes les sous-chaînes où l'expression régulière correspond et les remplacer par une chaîne vide. Le code complet ci-dessous génère une liste vide, extrait le texte entre les balises html pour chaque ligne et l'ajoute à la liste assignée.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
L'étape suivante consiste à convertir la liste en un DataFrame et à obtenir une vue rapide des 10 premières lignes à l'aide de Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finisseurs :, 577] |
| 1 | [Male :, 414] |
| 2 | [Femme :, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38 :... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Le DataFrame n'a pas le format souhaité. Pour le nettoyer, vous devez diviser la colonne "0" en plusieurs colonnes à la position de la virgule. Pour ce faire, vous pouvez utiliser la méthode str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Cela semble beaucoup mieux, mais il y a encore du travail à faire. Chaque ligne du DataFrame est entourée de crochets non désirés. Vous pouvez utiliser la méthode strip() pour supprimer le crochet d'ouverture de la colonne "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
Il manque des en-têtes au tableau. Vous pouvez utiliser la méthode find_all() pour obtenir les en-têtes de tableaux.
col_labels = soup.find_all('th')
Comme pour les tableaux, vous pouvez utiliser Beautiful Soup pour extraire le texte entre les balises html pour les en-têtes de tableau.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Vous pouvez ensuite convertir la liste des en-têtes en un DataFrame pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Lieu, dossard, nom, sexe, ville, état, puce T... |
De même, vous pouvez diviser la colonne "0" en plusieurs colonnes à la position de la virgule pour toutes les lignes.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Les deux DataFrame peuvent être concaténées en une seule à l'aide de la méthode concat(), comme illustré ci-dessous.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Le tableau ci-dessous montre comment affecter la première ligne à l'en-tête du tableau.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

À ce stade, le tableau est presque correctement formaté. Pour l'analyse, vous pouvez commencer par obtenir une vue d'ensemble des données, comme indiqué ci-dessous.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
Le tableau comporte 597 tableaux et 14 colonnes. Vous pouvez supprimer toutes les lignes contenant des valeurs manquantes.
df6 = df5.dropna(axis=0, how='any')
Remarquez également que l'en-tête du tableau est reproduit en tant que première ligne dans df5. Il peut être supprimé à l'aide de la ligne de code suivante.
df7 = df6.drop(df6.index[0])
df7.head()

Vous pouvez procéder à un nettoyage plus poussé des données en renommant les colonnes '[Lieu] et '[Équipe]'. Python est très exigeant en matière d'espace. Veillez à insérer un espace après les guillemets dans " Team] ".
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

La dernière étape du nettoyage des données consiste à supprimer le crochet de fermeture des cellules de la colonne "Équipe".
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Il a fallu un certain temps pour en arriver là, mais à ce stade, le DataFrame est au format souhaité. Vous pouvez maintenant passer à la partie la plus intéressante et commencer à tracer les données et à calculer des statistiques intéressantes.
La première question à laquelle il faut répondre est la suivante : quel a été le temps d'arrivée moyen (en minutes) des coureurs ? Vous devez convertir la colonne "Chip Time" en minutes. Une façon de procéder consiste à convertir d'abord la colonne en liste pour la manipuler.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
L'étape suivante consiste à reconvertir la liste en DataFrame et à créer une nouvelle colonne ("Runner_mins") pour les temps de passage des coureurs exprimés en minutes.
df7['Runner_mins'] = time_mins
df7.head()

Le code ci-dessous montre comment calculer les statistiques pour les colonnes numériques uniquement dans la DataFrame.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| compter | 577.000000 |
| moyenne | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
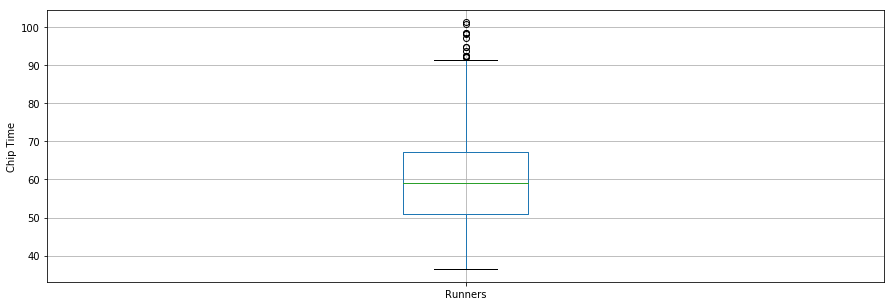
Il est intéressant de noter que le temps moyen de passage de la puce pour tous les coureurs était d'environ 60 minutes. Le coureur le plus rapide du 10 km a terminé en 36,35 minutes, et le coureur le plus lent a terminé en 101,30 minutes.
Le diagramme en boîte est un autre outil utile pour visualiser des statistiques sommaires (maximum, minimum, moyenne, premier quartile, troisième quartile, y compris les valeurs aberrantes). Vous trouverez ci-dessous les statistiques récapitulatives des données pour les coureurs, présentées sous forme de diagramme en boîte. Pour la visualisation des données, il est pratique d'importer d'abord les paramètres du module pylab fourni avec matplotlib et de définir la même taille pour toutes les figures afin d'éviter de le faire pour chaque figure.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
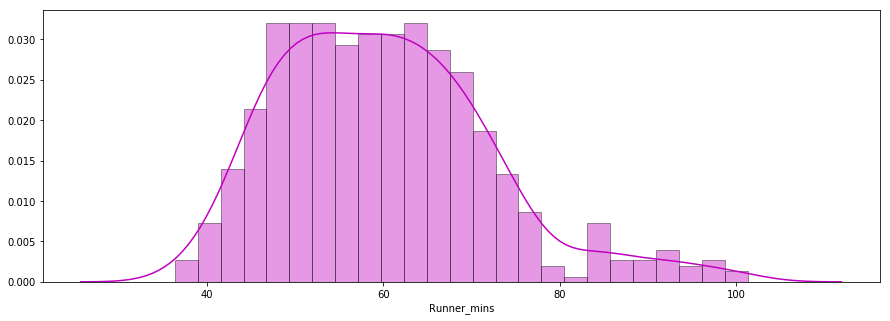
La deuxième question à laquelle il faut répondre est la suivante : Les temps d'arrivée des coureurs suivent-ils une distribution normale ?
Vous trouverez ci-dessous un graphique de distribution des temps de passage des coureurs, tracé à l'aide de la bibliothèque seaborn. La distribution semble presque normale.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
La troisième question vise à déterminer s'il existe des différences de performance entre les hommes et les femmes de différents groupes d'âge. Vous trouverez ci-dessous un diagramme de distribution des temps de passage pour les hommes et les femmes.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
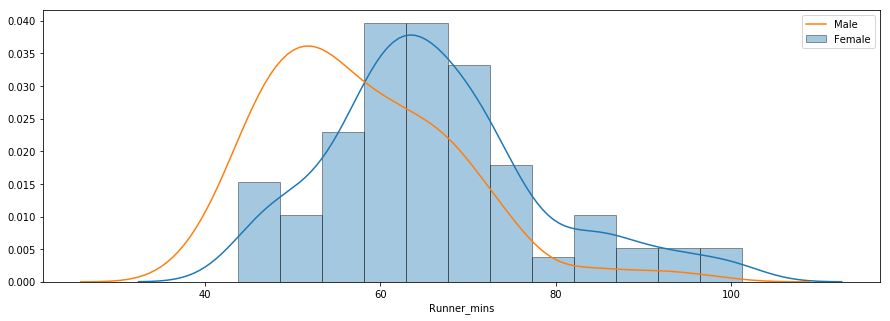
La distribution indique que les femmes sont en moyenne plus lentes que les hommes. Vous pouvez utiliser la méthode groupby() pour calculer des statistiques sommaires pour les hommes et les femmes séparément, comme indiqué ci-dessous.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
La durée moyenne de la puce pour l'ensemble des femmes et des hommes était respectivement de 66 minutes et de 58 minutes. Vous trouverez ci-dessous une comparaison côte à côte des temps d'arrivée des hommes et des femmes.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

Dans ce tutoriel, vous avez réalisé du web scraping à l'aide de Python. Vous avez utilisé la bibliothèque Beautiful Soup pour analyser des données html et les convertir sous une forme utilisable pour l'analyse. Vous avez procédé au nettoyage des données en Python et créé des graphiques utiles (diagrammes en boîte, diagrammes à barres et diagrammes de distribution) pour révéler des tendances intéressantes à l'aide des bibliothèques matplotlib et seaborn de Python. Après ce tutoriel, vous devriez être en mesure d'utiliser Python pour gratter facilement des données sur le web, appliquer des techniques de nettoyage et extraire des informations utiles à partir des données.
Si vous souhaitez en savoir plus sur Python, suivez le cours gratuit Intro to Python for Data Science de DataCamp et consultez notre tutoriel sur la façon de scraper Amazon à l'aide de python.
En savoir plus sur Python
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Satyabrata Pal