Introduction to Data Visualization with Matplotlib
BeginnerSkill Level
4 h
201.7K learners
Web scraping es un término utilizado para describir el uso de un programa o algoritmo para extraer y procesar grandes cantidades de datos de la web. Tanto si eres un científico de datos, un ingeniero o cualquiera que analice grandes cantidades de conjuntos de datos, la capacidad de raspar datos de la web es una habilidad útil que debes tener. Supongamos que encuentras datos en la web, y no hay forma directa de descargarlos, el web scraping utilizando Python es una habilidad que puedes utilizar para extraer los datos en una forma útil que se pueda importar.
En este tutorial, aprenderás lo siguiente:
El conjunto de datos utilizado en este tutorial procede de una carrera de 10 km que tuvo lugar en Hillsboro, Oregón, en junio de 2017. Concretamente, analizarás el rendimiento de los corredores de 10K y responderás a preguntas como
Utilizando Jupyter Notebook, debes empezar importando los módulos necesarios (pandas, numpy, matplotlib.pyplot, seaborn). Si no tienes instalado Jupyter Notebook, te recomiendo que lo instales utilizando la distribución Anaconda Python, que está disponible en Internet. Para visualizar fácilmente los gráficos, asegúrate de incluir la línea %matplotlib inline como se muestra a continuación.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Para realizar el web scraping, también debes importar las bibliotecas que se muestran a continuación. El módulo urllib.request se utiliza para abrir URLs. El paquete Beautiful Soup sirve para extraer datos de archivos html. El nombre de la biblioteca Sopa Bonita es bs4, que significa Sopa Bonita, versión 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Tras importar los módulos necesarios, debes especificar la URL que contiene el conjunto de datos y pasarla a urlopen() para obtener el html de la página.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Obtener el html de la página es sólo el primer paso. El siguiente paso es crear un objeto Beautiful Soup a partir del html. Esto se hace pasando el html a la función BeautifulSoup(). El paquete Beautiful Soup se utiliza para analizar el html, es decir, tomar el texto html en bruto y descomponerlo en objetos Python. El segundo argumento 'lxml' es el analizador html, de cuyos detalles no tienes que preocuparte en este momento.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
El objeto sopa te permite extraer información interesante sobre el sitio web que estás raspando, como obtener el título de la página, como se muestra a continuación.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
También puedes obtener el texto de la página web e imprimirlo rápidamente para comprobar si es lo que esperas.
# Print out the text
text = soup.get_text()
#print(soup.text)
Puedes ver el html de la página web haciendo clic con el botón derecho en cualquier parte de la página web y seleccionando "Inspeccionar". Este es el resultado.
Puedes utilizar el método find_all() de soup para extraer etiquetas html útiles dentro de una página web. Algunos ejemplos de etiquetas útiles son < a > para hipervínculos, < table > para tablas, < tr > para filas de tabla, < th > para encabezados de tabla y < td > para celdas de tabla. El código siguiente muestra cómo extraer todos los hiperenlaces de la página web.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Como puedes ver en el resultado anterior, las etiquetas html a veces vienen con atributos como class, src, etc. Estos atributos proporcionan información adicional sobre los elementos html. Puedes utilizar un bucle for y el método get('"href") para extraer e imprimir sólo los hipervínculos.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Para imprimir sólo las filas de la tabla, pasa el argumento 'tr' en sop.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
El objetivo de este tutorial es tomar una tabla de una página web y convertirla en un marco de datos para facilitar su manipulación con Python. Para conseguirlo, primero debes obtener todas las filas de la tabla en forma de lista y luego convertir esa lista en un marco de datos. A continuación se muestra un bucle for que itera a través de las filas de la tabla e imprime las celdas de las filas.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
La salida anterior muestra que cada fila se imprime con etiquetas html incrustadas en cada fila. Esto no es lo que quieres. Puedes eliminar las etiquetas html utilizando Beautiful Soup o expresiones regulares.
La forma más sencilla de eliminar las etiquetas html es utilizar Beautiful Soup, y sólo se necesita una línea de código para hacerlo. Pasa la cadena de interés a BeautifulSoup() y utiliza el método get_text() para extraer el texto sin etiquetas html.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
El uso de expresiones regulares está muy desaconsejado, ya que requiere varias líneas de código y es fácil cometer errores. Requiere importar el módulo re (para expresiones regulares). El código siguiente muestra cómo construir una expresión regular que encuentre todos los caracteres dentro de las etiquetas < td > html y los sustituya por una cadena vacía para cada fila de la tabla. En primer lugar, compila una expresión regular pasando una cadena para que coincida a re.compile(). El punto, la estrella y el signo de interrogación (.*?) coincidirán con un paréntesis angular de apertura seguido de cualquier cosa y seguido de un paréntesis angular de cierre. Hace coincidir el texto de forma no codiciosa, es decir, hace coincidir la cadena más corta posible. Si omites el signo de interrogación, coincidirá todo el texto entre el primer corchete angular de apertura y el último corchete angular de cierre. Después de compilar una expresión regular, puedes utilizar el método re.sub() para encontrar todas las subcadenas en las que coincida la expresión regular y sustituirlas por una cadena vacía. El código completo que aparece a continuación genera una lista vacía, extrae el texto entre las etiquetas html de cada fila y lo añade a la lista asignada.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
El siguiente paso es convertir la lista en un marco de datos y obtener una vista rápida de las 10 primeras filas utilizando Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finalizadores:, 577] |
| 1 | [Hombre:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
La trama de datos no tiene el formato que queremos. Para limpiarlo, debes dividir la columna "0" en varias columnas en la posición de la coma. Esto se consigue utilizando el método str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Esto tiene mucho mejor aspecto, pero aún queda trabajo por hacer. El marco de datos tiene corchetes no deseados alrededor de cada fila. Puedes utilizar el método strip() para eliminar el corchete de apertura de la columna "0".
df1[0] = df1[0].str.strip('[')
df1.head(10)
A la tabla le faltan los encabezados. Puedes utilizar el método find_all() para obtener las cabeceras de las tablas.
col_labels = soup.find_all('th')
De forma similar a las filas de tabla, puedes utilizar Beautiful Soup para extraer el texto entre las etiquetas html de los encabezados de tabla.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
A continuación, puedes convertir la lista de cabeceras en un marco de datos pandas.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Lugar, Dorsal, Nombre, Sexo, Ciudad, Estado, Chip T... |
Del mismo modo, puedes dividir la columna "0" en varias columnas en la posición de la coma para todas las filas.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Los dos marcos de datos se pueden concatenar en uno utilizando el método concat(), como se ilustra a continuación.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

A continuación se muestra cómo asignar la primera fila para que sea la cabecera de la tabla.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

En este punto, la tabla está casi correctamente formateada. Para el análisis, puedes empezar por obtener una visión general de los datos, como se muestra a continuación.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
La tabla tiene 597 filas y 14 columnas. Puedes eliminar todas las filas con valores perdidos.
df6 = df5.dropna(axis=0, how='any')
Además, observa cómo la cabecera de la tabla se replica como la primera fila en df5. Se puede eliminar utilizando la siguiente línea de código.
df7 = df6.drop(df6.index[0])
df7.head()

Puedes realizar más limpieza de datos renombrando las columnas '[Lugar' y ' Equipo]'. Python es muy exigente con el espacio. Asegúrate de incluir un espacio después de la comilla en ' Equipo]'.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

El último paso de la limpieza de datos consiste en eliminar el corchete de cierre de las celdas de la columna "Equipo".
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Ha costado un poco llegar hasta aquí, pero en este momento, el marco de datos tiene el formato deseado. Ahora puedes pasar a la parte emocionante y empezar a trazar los datos y calcular estadísticas interesantes.
La primera pregunta que hay que responder es: ¿cuál fue el tiempo medio de llegada a meta (en minutos) de los corredores? Tienes que convertir la columna "Tiempo de Chip" en sólo minutos. Una forma de hacerlo es convertir primero la columna en una lista para poder manipularla.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
El siguiente paso es volver a convertir la lista en un marco de datos y crear una nueva columna ("Runner_mins") para los tiempos de chip de los corredores expresados sólo en minutos.
df7['Runner_mins'] = time_mins
df7.head()

El código siguiente muestra cómo calcular estadísticas para columnas numéricas sólo en el marco de datos.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| cuenta | 577.000000 |
| media | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
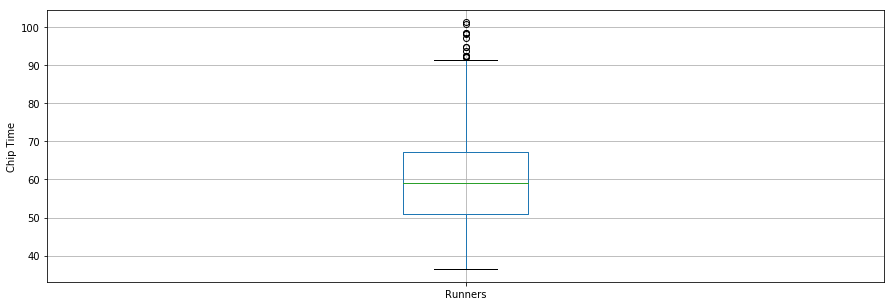
Curiosamente, el tiempo medio en chip de todos los corredores fue de unos 60 minutos. El corredor de 10 km más rápido terminó en 36,35 minutos, y el más lento en 101,30 minutos.
Un diagrama de caja es otra herramienta útil para visualizar estadísticas resumidas (máximo, mínimo, medio, primer cuartil, tercer cuartil, incluidos los valores atípicos). A continuación se muestran las estadísticas resumidas de los datos de los corredores en un diagrama de caja. Para la visualización de datos, es conveniente importar primero los parámetros del módulo pylab que viene con matplotlib y establecer el mismo tamaño para todas las figuras, para evitar hacerlo para cada figura.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
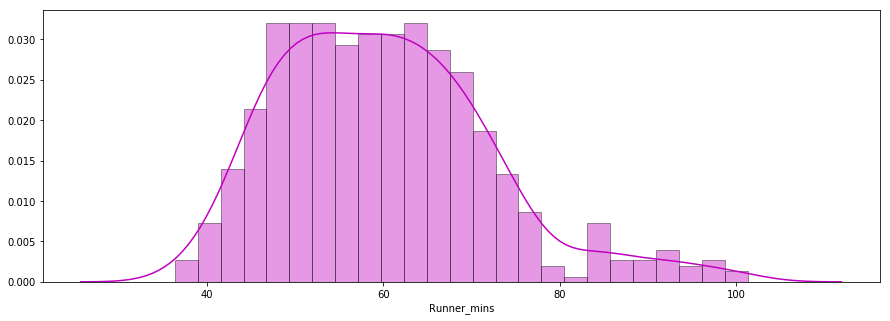
La segunda pregunta que hay que responder es: ¿Los tiempos de llegada de los corredores seguían una distribución normal?
A continuación se muestra un gráfico de distribución de los tiempos de chip de los corredores trazados con la biblioteca seaborn. La distribución parece casi normal.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
La tercera pregunta se refiere a si había diferencias de rendimiento entre hombres y mujeres de distintos grupos de edad. A continuación se muestra un gráfico de distribución de los tiempos de chip para hombres y mujeres.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
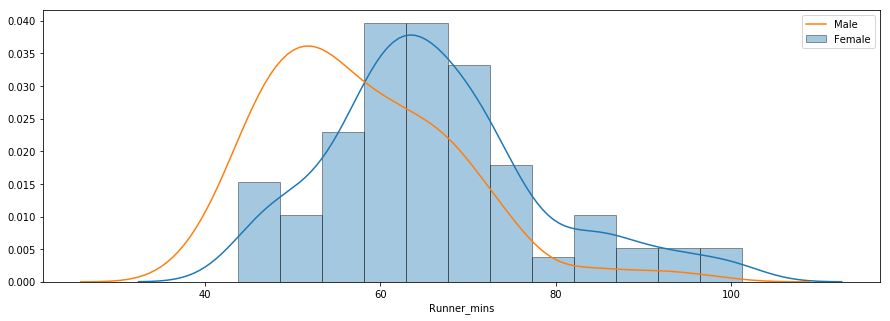
La distribución indica que las mujeres eran más lentas que los hombres por término medio. Puedes utilizar el método groupby() para calcular estadísticas de resumen para hombres y mujeres por separado, como se muestra a continuación.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
El tiempo medio de chip para todas las hembras y todos los machos fue de ~66 min y ~58 min, respectivamente. A continuación se muestra una comparación de los tiempos de llegada de hombres y mujeres.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

En este tutorial, has realizado raspado web utilizando Python. Has utilizado la biblioteca Beautiful Soup para analizar datos html y convertirlos en un formulario que pueda utilizarse para el análisis. Realizaste la limpieza de los datos en Python y creaste gráficos útiles (gráficos de caja, gráficos de barras y gráficos de distribución) para revelar tendencias interesantes utilizando las bibliotecas matplotlib y seaborn de Python. Después de este tutorial, deberías ser capaz de utilizar Python para raspar fácilmente datos de la web, aplicar técnicas de limpieza y extraer información útil de los datos.
Si quieres aprender más sobre Python, sigue el curso gratuito Introducción a Python para la Ciencia de Datos de DataCamp y echa un vistazo a nuestro tutorial sobre cómo scrapear Amazon utilizando python.
Más información sobre Python
Curso
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Kevin Babitz
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Moez Ali

