Webscraping in Python
BasicSkill Level
4 Hr
92K learners
Webscraping is een term voor het gebruik van een programma of algoritme om grote hoeveelheden data van het web te halen en te verwerken. Of je nu data scientist, engineer, of iemand bent die grote datasets analyseert: de vaardigheid om data van het web te scrapen is erg handig. Stel dat je data op het web vindt, maar er is geen directe manier om het te downloaden: met webscraping in Python kun je de data extraheren naar een bruikbaar formaat dat je kunt importeren.
In deze tutorial leer je het volgende:
De dataset in deze tutorial komt van een 10K-wedstrijd die plaatsvond in Hillsboro, OR in juni 2017. Je analyseert specifiek de prestaties van de 10K-lopers en beantwoordt vragen zoals:
Gebruikmakend van Jupyter Notebook begin je met het importeren van de benodigde modules (pandas, numpy, matplotlib.pyplot, Seaborn). Als je Jupyter Notebook niet hebt geïnstalleerd, raad ik aan om het te installeren via de Anaconda Python-distributie, die online beschikbaar is. Om de plots eenvoudig te tonen, voeg je de regel %matplotlib inline toe, zoals hieronder weergegeven.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Voor webscraping importeer je ook de onderstaande libraries. De module urllib.request wordt gebruikt om URL's te openen. Het BeautifulSoup-pakket wordt gebruikt om data uit html-bestanden te extraheren. De naam van de BeautifulSoup-bibliotheek is bs4, wat staat voor BeautifulSoup, versie 4.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Nadat je de nodige modules hebt geïmporteerd, geef je de URL met de dataset op en geef je die door aan urlopen() om de html van de pagina op te halen.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
De html van de pagina ophalen is slechts de eerste stap. De volgende stap is een BeautifulSoup-object maken van de html. Dit doe je door de html door te geven aan de functie BeautifulSoup(). Het BeautifulSoup-pakket wordt gebruikt om de html te parsen, oftewel: de ruwe html-tekst omzetten en opdelen in Python-objecten. Het tweede argument lxml is de html-parser; de details daarvan hoef je nu niet te kennen.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
Met het soup-object kun je interessante informatie halen over de website die je scraped, zoals de titel van de pagina, zoals hieronder.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Je kunt ook de tekst van de webpagina ophalen en snel uitprinten om te checken of het is wat je verwacht.
# Print out the text
text = soup.get_text()
#print(soup.text)
Je kunt de html van de webpagina bekijken door met de rechtermuisknop ergens op de pagina te klikken en "Inspect" te selecteren. Zo ziet het resultaat eruit.
Je kunt de methode find_all() van soup gebruiken om nuttige html-tags binnen een webpagina te extraheren. Voorbeelden van nuttige tags zijn < a > voor hyperlinks, < table > voor tabellen, < tr > voor tabelrijen, < th > voor tabelkoppen en < td > voor tabelcellen. De onderstaande code laat zien hoe je alle hyperlinks binnen de webpagina ophaalt.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Zoals je in de output hierboven ziet, hebben html-tags soms attributen zoals class, src, enzovoort. Deze attributen geven extra informatie over html-elementen. Je kunt een for-loop en de methode get("href") gebruiken om alleen hyperlinks te extraheren en te printen.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Om alleen tabelrijen te printen, geef je het argument tr door in soup.find_all().
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Het doel van deze tutorial is om een tabel van een webpagina om te zetten naar een dataframe, zodat je die makkelijker kunt bewerken met Python. Om daar te komen, haal je eerst alle tabelrijen op in lijstvorm en zet je die lijst daarna om naar een dataframe. Hieronder staat een for-loop die door de tabelrijen itereert en de cellen van de rijen print.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI]
bs4.element.ResultSet
De output hierboven laat zien dat elke rij wordt geprint met html-tags in elke rij. Dat is niet wat je wilt. Je kunt de html-tags verwijderen met Beautiful Soup of met reguliere expressies.
De makkelijkste manier om html-tags te verwijderen is met BeautifulSoup, en dat kost maar één regel code. Geef de string van interesse door aan BeautifulSoup() en gebruik de methode get_text() om de tekst zonder html-tags te extraheren.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Het gebruik van reguliere expressies wordt sterk afgeraden, omdat het meerdere regels code vergt en je makkelijk fouten maakt. Het vereist het importeren van de module re (voor reguliere expressies). De code hieronder laat zien hoe je een reguliere expressie maakt die alle tekens binnen de < td >-html-tags vindt en ze voor elke tabelrij vervangt door een lege string. Eerst compileer je een reguliere expressie door een string met het patroon door te geven aan re.compile(). De punt, ster en vraagteken (.*?) matchen een openingshoekhaakje gevolgd door alles en gevolgd door een sluitingshoekhaakje. Het matcht tekst op een non-greedy manier, dus het matcht de kortst mogelijke string. Als je het vraagteken weglaat, matcht het alle tekst tussen de eerste openingshoekhaak en de laatste sluitingshoekhaak. Na het compileren van een reguliere expressie kun je de methode re.sub() gebruiken om alle substrings waar de regex op matcht te vinden en ze te vervangen door een lege string. De volledige code hieronder genereert een lege lijst, extraheert tekst tussen html-tags voor elke rij en voegt die toe aan de toegewezen lijst.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
De volgende stap is de lijst omzetten naar een dataframe en snel de eerste 10 rijen bekijken met Pandas.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finishers:, 577] |
| 1 | [Male:, 414] |
| 2 | [Female:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Het dataframe heeft niet het gewenste formaat. Om het op te schonen, splits je kolom "0" in meerdere kolommen op de komma-positie. Dit doe je met de methode str.split().
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Dit ziet er al beter uit, maar er is nog werk te doen. Het dataframe heeft ongewenste rechte haken rond elke rij. Je kunt de methode strip() gebruiken om het openingshakje in kolom "0" te verwijderen.
df1[0] = df1[0].str.strip('[')
df1.head(10)
De tabel mist kolomkoppen. Je kunt de methode find_all() gebruiken om de tabelkoppen op te halen.
col_labels = soup.find_all('th')
Net als bij de tabelrijen kun je BeautifulSoup gebruiken om tekst tussen html-tags voor tabelkoppen te extraheren.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Je kunt de lijst met koppen vervolgens omzetten naar een pandas-dataframe.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Place, Bib, Name, Gender, City, State, Chip T... |
Op dezelfde manier kun je kolom "0" splitsen in meerdere kolommen op de komma-positie voor alle rijen.
df3 = df2[0].str.split(',', expand=True)
df3.head()

De twee dataframes kun je samenvoegen tot één met de methode concat(), zoals hieronder geïllustreerd.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Hieronder zie je hoe je de eerste rij als tabelkop instelt.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

Op dit punt is de tabel bijna goed opgemaakt. Voor de analyse kun je beginnen met een overzicht van de data, zoals hieronder.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
De tabel heeft 597 rijen en 14 kolommen. Je kunt alle rijen met ontbrekende waarden droppen.
df6 = df5.dropna(axis=0, how='any')
Merk ook op dat de tabelkop is gedupliceerd als eerste rij in df5. Die kun je verwijderen met de volgende regel code.
df7 = df6.drop(df6.index[0])
df7.head()

Je kunt meer opschonen door de kolommen '[Place' en ' Team]' te hernoemen. Python is erg strikt met spaties. Zorg dat je een spatie na het aanhalingsteken in ' Team]' opneemt.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

De laatste stap van het opschonen is het verwijderen van het sluitende hakje voor cellen in de kolom ' Team' .
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Het kostte even wat stappen om hier te komen, maar nu heeft het dataframe het gewenste formaat. Nu kun je doorgaan met het leuke deel: de data plotten en interessante statistieken berekenen.
De eerste vraag om te beantwoorden is: wat was de gemiddelde finishtijd (in minuten) voor de lopers? Je moet de kolom "Chip Time" omzetten naar alleen minuten. Een manier is om de kolom eerst om te zetten naar een lijst voor bewerking.
time_list = df7[' Chip Time'].tolist()
# Je kunt een for-loop gebruiken om 'Chip Time' naar minuten om te zetten
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
De volgende stap is de lijst terugzetten naar een dataframe en een nieuwe kolom (Runner_mins) maken voor de chip-tijden van lopers, uitgedrukt in alleen minuten.
df7['Runner_mins'] = time_mins
df7.head()

De onderstaande code laat zien hoe je statistieken berekent voor alleen numerieke kolommen in het dataframe.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| count | 577.000000 |
| mean | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
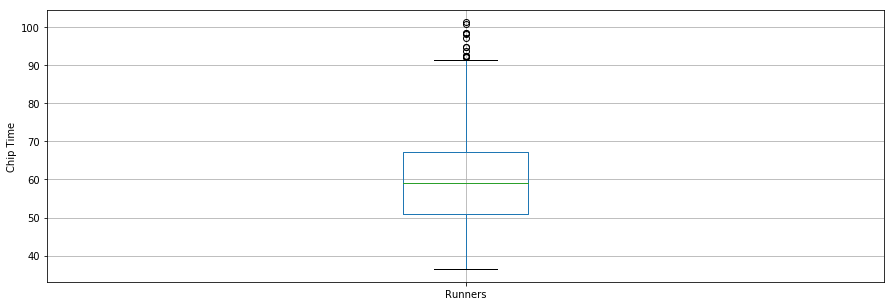
Interessant genoeg was de gemiddelde chip-tijd voor alle lopers ~60 minuten. De snelste 10K-loper finishte in 36,35 minuten en de langzaamste in 101,30 minuten.
Een boxplot is een andere handige manier om samenvattende statistieken te visualiseren (maximum, minimum, mediaan, eerste kwartiel, derde kwartiel, inclusief uitschieters). Hieronder staan de samenvattende statistieken voor de lopers in een boxplot. Voor datavisualisatie is het handig om eerst parameters uit de pylab-module van matplotlib te importeren en dezelfde afmeting voor alle figuren te zetten, zodat je dat niet per figuur hoeft te doen.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
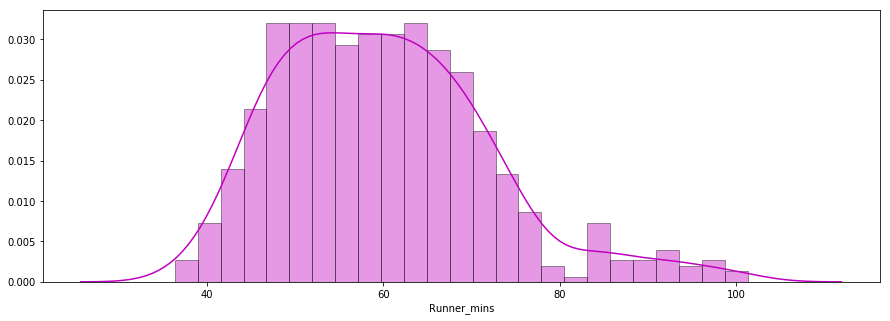
De tweede vraag: volgden de finishtijden van de lopers een normale verdeling?
Hieronder staat een verdelingsplot van de chip-tijden van lopers, gemaakt met de seaborn-bibliotheek. De verdeling oogt bijna normaal.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
De derde vraag gaat over eventuele prestatieverschillen tussen mannen en vrouwen in verschillende leeftijdsgroepen. Hieronder staat een verdelingsplot van chip-tijden voor mannen en vrouwen.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
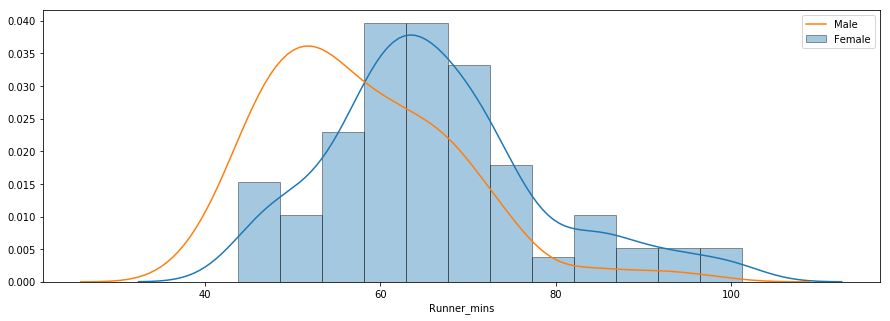
De verdeling geeft aan dat vrouwen gemiddeld langzamer waren dan mannen. Je kunt de methode groupby() gebruiken om samenvattende statistieken voor mannen en vrouwen apart te berekenen, zoals hieronder.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
De gemiddelde chip-tijd voor alle vrouwen en mannen was respectievelijk ~66 minuten en ~58 minuten. Hieronder staat een boxplot-vergelijking van finishtijden van mannen en vrouwen naast elkaar.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

In deze tutorial heb je webscraping met Python gedaan. Je gebruikte de Beautiful Soup-bibliotheek om html-data te parsen en om te zetten naar een vorm die je kunt analyseren. Je hebt de data in Python opgeschoond en nuttige plots (boxplots, staafdiagrammen en verdelingsplots) gemaakt om interessante trends te tonen met de matplotlib- en seaborn-bibliotheken van Python. Na deze tutorial kun je met Python eenvoudig data van het web scrapen, opschoontechnieken toepassen en nuttige inzichten uit de data halen.
Wil je meer leren over Python? Volg dan DataCamp’s gratis cursus Intro to Python for Data Science en bekijk onze tutorial over hoe je Amazon scrapt met Python.
Leer meer over Python
Cursus
Cursus
Cursus