Web Scraping in Python
BeginnerSkill Level
4 Std.
84.2K learners
Web Scraping ist ein Begriff, der die Verwendung eines Programms oder Algorithmus zur Extraktion und Verarbeitung großer Datenmengen aus dem Internet beschreibt. Egal, ob du Datenwissenschaftler/in, Ingenieur/in oder jemand bist, der große Mengen an Daten analysiert, die Fähigkeit, Daten aus dem Internet zu scrapen, ist eine nützliche Fähigkeit, die man haben sollte. Angenommen, du findest Daten im Internet und es gibt keinen direkten Weg, sie herunterzuladen. Dann kannst du mit Python Web Scraping betreiben, um die Daten in eine brauchbare Form zu bringen, die importiert werden kann.
In diesem Lernprogramm lernst du Folgendes:
Der Datensatz, der in diesem Tutorial verwendet wird, stammt von einem 10 km-Lauf, der im Juni 2017 in Hillsboro, OR, stattfand. Konkret wirst du die Leistung der 10 km-Läufer analysieren und Fragen beantworten wie:
Wenn du Jupyter Notebook verwendest, solltest du zunächst die notwendigen Module importieren (pandas, numpy, matplotlib.pyplot, seaborn). Wenn du Jupyter Notebook noch nicht installiert hast, empfehle ich dir, es mit der Anaconda Python-Distribution zu installieren, die im Internet erhältlich ist. Um die Diagramme einfach anzuzeigen, musst du die Zeile %matplotlib inline einfügen, wie unten gezeigt.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Um Web Scraping durchzuführen, solltest du auch die unten gezeigten Bibliotheken importieren. Das Modul urllib.request wird verwendet, um URLs zu öffnen. Das Beautiful Soup-Paket wird verwendet, um Daten aus HTML-Dateien zu extrahieren. Der Name der Beautiful Soup-Bibliothek ist bs4, was für Beautiful Soup, Version 4 steht.
from urllib.request import urlopen
from bs4 import BeautifulSoup
Nachdem du die notwendigen Module importiert hast, solltest du die URL angeben, die den Datensatz enthält, und sie an urlopen() übergeben, um die HTML der Seite zu erhalten.
url = "http://www.hubertiming.com/results/2017GPTR10K"
html = urlopen(url)
Die HTML der Seite zu bekommen ist nur der erste Schritt. Der nächste Schritt besteht darin, ein Beautiful Soup-Objekt aus der html-Datei zu erstellen. Dazu übergibst du die html-Datei an die Funktion BeautifulSoup(). Das Beautiful Soup-Paket wird verwendet, um den HTML-Text zu parsen, d.h. ihn in Python-Objekte zu zerlegen. Das zweite Argument "lxml" ist der HTML-Parser, um dessen Details du dich an dieser Stelle nicht kümmern musst.
soup = BeautifulSoup(html, 'lxml')
type(soup)
bs4.BeautifulSoup
Mit dem Soup-Objekt kannst du interessante Informationen über die Website, die du scrapen willst, extrahieren, z. B. den Titel der Seite, wie unten gezeigt.
# Get the title
title = soup.title
print(title)
<title>2017 Intel Great Place to Run 10K \ Urban Clash Games Race Results</title>
Du kannst auch den Text der Webseite abrufen und schnell ausdrucken, um zu prüfen, ob sie deinen Erwartungen entspricht.
# Print out the text
text = soup.get_text()
#print(soup.text)
Du kannst die HTML der Webseite anzeigen, indem du mit der rechten Maustaste auf die Webseite klickst und "Prüfen" wählst. So sieht das Ergebnis aus.
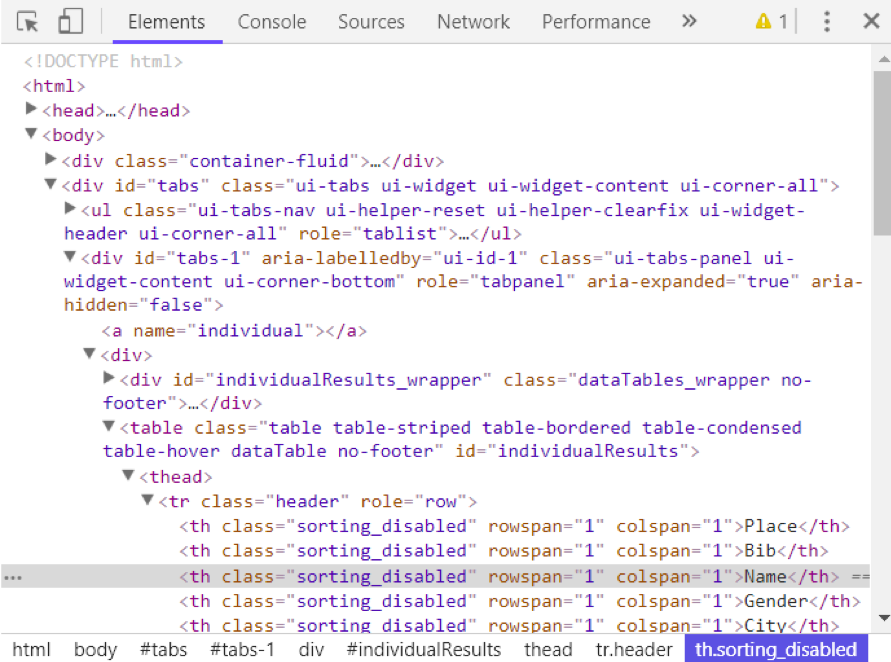
Du kannst die find_all()-Methode von Soup verwenden, um nützliche html-Tags innerhalb einer Webseite zu extrahieren. Beispiele für nützliche Tags sind < a > für Hyperlinks, < table > für Tabellen, < tr > für Tabellenzeilen, < th > für Tabellenüberschriften und < td > für Tabellenzellen. Der folgende Code zeigt, wie man alle Hyperlinks auf der Webseite extrahiert.
soup.find_all('a')
[<a class="btn btn-primary btn-lg" href="/results/2017GPTR" role="button">5K</a>,
<a href="http://hubertiming.com">Huber Timing Home</a>,
<a href="#individual">Individual Results</a>,
<a href="#team">Team Results</a>,
<a href="mailto:timing@hubertiming.com">timing@hubertiming.com</a>,
<a href="#tabs-1" style="font-size: 18px">Results</a>,
<a name="individual"></a>,
<a name="team"></a>,
<a href="http://www.hubertiming.com"><img height="65" src="/sites/all/themes/hubertiming/images/clockWithFinishSign_small.png" width="50"/>Huber Timing</a>,
<a href="http://facebook.com/hubertiming"><img src="/results/FB-f-Logo__blue_50.png"/></a>]
Wie du in der obigen Ausgabe sehen kannst, enthalten html-Tags manchmal Attribute wie class, src usw. Diese Attribute liefern zusätzliche Informationen über HTML-Elemente. Du kannst eine for-Schleife und die Methode get('"href") verwenden, um nur Hyperlinks zu extrahieren und auszudrucken.
all_links = soup.find_all("a")
for link in all_links:
print(link.get("href"))
/results/2017GPTR
http://hubertiming.com/
#individual
#team
mailto:timing@hubertiming.com
#tabs-1
None
None
http://www.hubertiming.com/
http://facebook.com/hubertiming/
Um nur Tabellenzeilen auszudrucken, gibst du das Argument "tr" in soup.find_all() an.
# Print the first 10 rows for sanity check
rows = soup.find_all('tr')
print(rows[:10])
[<tr><td>Finishers:</td><td>577</td></tr>, <tr><td>Male:</td><td>414</td></tr>, <tr><td>Female:</td><td>163</td></tr>, <tr class="header">
<th>Place</th>
<th>Bib</th>
<th>Name</th>
<th>Gender</th>
<th>City</th>
<th>State</th>
<th>Chip Time</th>
<th>Chip Pace</th>
<th>Gender Place</th>
<th>Age Group</th>
<th>Age Group Place</th>
<th>Time to Start</th>
<th>Gun Time</th>
<th>Team</th>
</tr>, <tr>
<td>1</td>
<td>814</td>
<td>JARED WILSON</td>
<td>M</td>
<td>TIGARD</td>
<td>OR</td>
<td>00:36:21</td>
<td>05:51</td>
<td>1 of 414</td>
<td>M 36-45</td>
<td>1 of 152</td>
<td>00:00:03</td>
<td>00:36:24</td>
<td></td>
</tr>, <tr>
<td>2</td>
<td>573</td>
<td>NATHAN A SUSTERSIC</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:36:42</td>
<td>05:55</td>
<td>2 of 414</td>
<td>M 26-35</td>
<td>1 of 154</td>
<td>00:00:03</td>
<td>00:36:45</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>3</td>
<td>687</td>
<td>FRANCISCO MAYA</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:37:44</td>
<td>06:05</td>
<td>3 of 414</td>
<td>M 46-55</td>
<td>1 of 64</td>
<td>00:00:04</td>
<td>00:37:48</td>
<td></td>
</tr>, <tr>
<td>4</td>
<td>623</td>
<td>PAUL MORROW</td>
<td>M</td>
<td>BEAVERTON</td>
<td>OR</td>
<td>00:38:34</td>
<td>06:13</td>
<td>4 of 414</td>
<td>M 36-45</td>
<td>2 of 152</td>
<td>00:00:03</td>
<td>00:38:37</td>
<td></td>
</tr>, <tr>
<td>5</td>
<td>569</td>
<td>DEREK G OSBORNE</td>
<td>M</td>
<td>HILLSBORO</td>
<td>OR</td>
<td>00:39:21</td>
<td>06:20</td>
<td>5 of 414</td>
<td>M 26-35</td>
<td>2 of 154</td>
<td>00:00:03</td>
<td>00:39:24</td>
<td>INTEL TEAM F</td>
</tr>, <tr>
<td>6</td>
<td>642</td>
<td>JONATHON TRAN</td>
<td>M</td>
<td>PORTLAND</td>
<td>OR</td>
<td>00:39:49</td>
<td>06:25</td>
<td>6 of 414</td>
<td>M 18-25</td>
<td>1 of 34</td>
<td>00:00:06</td>
<td>00:39:55</td>
<td></td>
</tr>]
Das Ziel dieses Tutorials ist es, eine Tabelle von einer Webseite in einen DataFrame zu konvertieren, um sie mit Python einfacher bearbeiten zu können. Um das zu erreichen, solltest du zunächst alle Zeilen der Tabelle in Listenform erhalten und diese Liste dann in einen DataFrame umwandeln. Im Folgenden findest du eine for-Schleife, die durch die Tabellenzeilen iteriert und die Zellen der Zeilen ausgibt.
for row in rows:
row_td = row.find_all('td')
print(row_td)
type(row_td)
[<td>14TH</td>, <td>INTEL TEAM M</td>, <td>04:43:23</td>, <td>00:58:59 - DANIELLE CASILLAS</td>, <td>01:02:06 - RAMYA MERUVA</td>, <td>01:17:06 - PALLAVI J SHINDE</td>, <td>01:25:11 - NALINI MURARI</td>]
bs4.element.ResultSet
Die Ausgabe oben zeigt, dass jede Zeile mit eingebetteten html-Tags gedruckt wird. Das ist nicht das, was du willst. Du kannst die html-Tags mit Beautiful Soup oder regulären Ausdrücken entfernen.
Die einfachste Art, html-Tags zu entfernen, ist Beautiful Soup, und dafür brauchst du nur eine Zeile Code. Übergib die gewünschte Zeichenkette an BeautifulSoup() und benutze die Methode get_text(), um den Text ohne html-Tags zu extrahieren.
str_cells = str(row_td)
cleantext = BeautifulSoup(str_cells, "lxml").get_text()
print(cleantext)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
Von der Verwendung regulärer Ausdrücke wird dringend abgeraten, da sie mehrere Codezeilen erfordern und man leicht Fehler machen kann. Dazu muss das Modul re (für reguläre Ausdrücke) importiert werden. Der folgende Code zeigt, wie man einen regulären Ausdruck erstellt, der alle Zeichen innerhalb der < td > html-Tags findet und sie für jede Tabellenzeile durch einen leeren String ersetzt. Zuerst kompilierst du einen regulären Ausdruck, indem du re.compile() eine Zeichenkette übergibst, auf die er passen soll. Der Punkt, der Stern und das Fragezeichen (.*?) passen zu einer öffnenden spitzen Klammer, gefolgt von einer beliebigen Zahl und einer schließenden spitzen Klammer. Sie passt auf eine nicht gierige Art und Weise auf den Text, d.h. sie passt auf die kürzestmögliche Zeichenkette. Wenn du das Fragezeichen weglässt, wird der gesamte Text zwischen der ersten öffnenden spitzen Klammer und der letzten schließenden spitzen Klammer abgeglichen. Nachdem du einen regulären Ausdruck kompiliert hast, kannst du die Methode re.sub() verwenden, um alle Teilzeichenketten zu finden, auf die der reguläre Ausdruck passt, und sie durch eine leere Zeichenkette zu ersetzen. Der vollständige Code unten erzeugt eine leere Liste, extrahiert Text zwischen html-Tags für jede Zeile und fügt ihn an die zugewiesene Liste an.
import re
list_rows = []
for row in rows:
cells = row.find_all('td')
str_cells = str(cells)
clean = re.compile('<.*?>')
clean2 = (re.sub(clean, '',str_cells))
list_rows.append(clean2)
print(clean2)
type(clean2)
[14TH, INTEL TEAM M, 04:43:23, 00:58:59 - DANIELLE CASILLAS, 01:02:06 - RAMYA MERUVA, 01:17:06 - PALLAVI J SHINDE, 01:25:11 - NALINI MURARI]
str
Als Nächstes wandeln wir die Liste in einen DataFrame um und erhalten mit Pandas einen schnellen Überblick über die ersten 10 Zeilen.
df = pd.DataFrame(list_rows)
df.head(10)
| 0 | |
|---|---|
| 0 | [Finisher:, 577] |
| 1 | [Männlich:, 414] |
| 2 | [Weiblich:, 163] |
| 3 | [] |
| 4 | [1, 814, JARED WILSON, M, TIGARD, OR, 00:36:21... |
| 5 | [2, 573, NATHAN A SUSTERSIC, M, PORTLAND, OR, ... |
| 6 | [3, 687, FRANCISCO MAYA, M, PORTLAND, OR, 00:3... |
| 7 | [4, 623, PAUL MORROW, M, BEAVERTON, OR, 00:38:... |
| 8 | [5, 569, DEREK G OSBORNE, M, HILLSBORO, OR, 00... |
| 9 | [6, 642, JONATHON TRAN, M, PORTLAND, OR, 00:39... |
Der DataFrame hat nicht das gewünschte Format. Um sie zu bereinigen, solltest du die Spalte "0" an der Kommastelle in mehrere Spalten aufteilen. Dies wird mit der Methode str.split() erreicht.
df1 = df[0].str.split(',', expand=True)
df1.head(10)

Das sieht schon viel besser aus, aber es gibt noch einiges zu tun. Der DataFrame hat unerwünschte eckige Klammern um jede Zeile. Du kannst die Methode strip() verwenden, um die öffnende eckige Klammer der Spalte "0" zu entfernen.
df1[0] = df1[0].str.strip('[')
df1.head(10)
In der Tabelle fehlen Tabellenüberschriften. Du kannst die Methode find_all() verwenden, um die Überschriften der Tabellen zu erhalten.
col_labels = soup.find_all('th')
Ähnlich wie bei Tabellenzeilen kannst du Beautiful Soup verwenden, um Text zwischen html-Tags für Tabellenüberschriften zu extrahieren.
all_header = []
col_str = str(col_labels)
cleantext2 = BeautifulSoup(col_str, "lxml").get_text()
all_header.append(cleantext2)
print(all_header)
['[Place, Bib, Name, Gender, City, State, Chip Time, Chip Pace, Gender Place, Age Group, Age Group Place, Time to Start, Gun Time, Team]']
Anschließend kannst du die Liste der Überschriften in einen Pandas DataFrame umwandeln.
df2 = pd.DataFrame(all_header)
df2.head()
| 0 | |
|---|---|
| 0 | [Ort, Lätzchen, Name, Geschlecht, Stadt, Bundesland, Chip T... |
Genauso kannst du die Spalte "0" an der Kommastelle für alle Zeilen in mehrere Spalten aufteilen.
df3 = df2[0].str.split(',', expand=True)
df3.head()

Die beiden DataFrames können mit der Methode concat() zu einem einzigen zusammengefügt werden, wie unten dargestellt.
frames = [df3, df1]
df4 = pd.concat(frames)
df4.head(10)

Im Folgenden wird gezeigt, wie du die erste Zeile als Kopfzeile der Tabelle festlegst.
df5 = df4.rename(columns=df4.iloc[0])
df5.head()

An dieser Stelle ist die Tabelle fast richtig formatiert. Für die Analyse kannst du dir zunächst einen Überblick über die Daten verschaffen, wie unten dargestellt.
df5.info()
df5.shape
<class 'pandas.core.frame.DataFrame'>
Int64Index: 597 entries, 0 to 595
Data columns (total 14 columns):
[Place 597 non-null object
Bib 596 non-null object
Name 593 non-null object
Gender 593 non-null object
City 593 non-null object
State 593 non-null object
Chip Time 593 non-null object
Chip Pace 578 non-null object
Gender Place 578 non-null object
Age Group 578 non-null object
Age Group Place 578 non-null object
Time to Start 578 non-null object
Gun Time 578 non-null object
Team] 578 non-null object
dtypes: object(14)
memory usage: 70.0+ KB
(597, 14)
Die Tabelle hat 597 Zeilen und 14 Spalten. Du kannst alle Zeilen mit fehlenden Werten löschen.
df6 = df5.dropna(axis=0, how='any')
Beachte auch, dass die Kopfzeile der Tabelle als erste Zeile in df5 repliziert wird. Sie kann mit der folgenden Code-Zeile gelöscht werden.
df7 = df6.drop(df6.index[0])
df7.head()

Du kannst weitere Datenbereinigungen vornehmen, indem du die Spalten "[Ort" und " Team" umbenennst. Python ist sehr wählerisch, was den Platz angeht. Achte darauf, dass du nach dem Anführungszeichen in ' Team]' ein Leerzeichen einfügst.
df7.rename(columns={'[Place': 'Place'},inplace=True)
df7.rename(columns={' Team]': 'Team'},inplace=True)
df7.head()

Im letzten Schritt der Datenbereinigung wird die schließende Klammer für die Zellen in der Spalte "Team" entfernt.
df7['Team'] = df7['Team'].str.strip(']')
df7.head()

Es hat eine Weile gedauert, aber jetzt hat der DataFrame das gewünschte Format. Jetzt kannst du zum spannenden Teil übergehen und anfangen, die Daten aufzuzeichnen und interessante Statistiken zu berechnen.
Die erste Frage, die es zu beantworten gilt, lautet: Wie lange haben die Läuferinnen und Läufer durchschnittlich gebraucht (in Minuten)? Du musst die Spalte "Chip-Zeit" in Minuten umrechnen. Eine Möglichkeit, dies zu tun, besteht darin, die Spalte zunächst in eine Liste umzuwandeln, damit sie bearbeitet werden kann.
time_list = df7[' Chip Time'].tolist()
# You can use a for loop to convert 'Chip Time' to minutes
time_mins = []
for i in time_list:
h, m, s = i.split(':')
math = (int(h) * 3600 + int(m) * 60 + int(s))/60
time_mins.append(math)
#print(time_mins)
Im nächsten Schritt wandeln wir die Liste wieder in einen DataFrame um und erstellen eine neue Spalte ("Runner_mins") für die Chipzeiten der Läufer in Minuten.
df7['Runner_mins'] = time_mins
df7.head()

Der folgende Code zeigt, wie man Statistiken nur für numerische Spalten im DataFrame berechnet.
df7.describe(include=[np.number])
| Runner_mins | |
|---|---|
| zählen | 577.000000 |
| mittlere | 60.035933 |
| std | 11.970623 |
| min | 36.350000 |
| 25% | 51.000000 |
| 50% | 59.016667 |
| 75% | 67.266667 |
| max | 101.300000 |
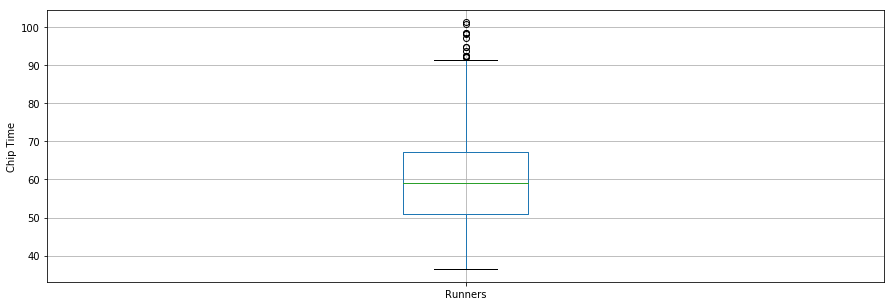
Interessanterweise lag die durchschnittliche Chip-Zeit für alle Läufer bei 60 Minuten. Der schnellste 10 km-Läufer kam in 36,35 Minuten ins Ziel und der langsamste Läufer in 101,30 Minuten.
Ein Boxplot ist ein weiteres nützliches Werkzeug, um zusammenfassende Statistiken zu visualisieren (Maximum, Minimum, Mittelwert, erstes Quartil, drittes Quartil, einschließlich Ausreißer). Nachfolgend findest du eine zusammenfassende Statistik für die Läufer, die in einem Boxplot dargestellt wird. Für die Datenvisualisierung ist es praktisch, zunächst Parameter aus dem pylab-Modul zu importieren, das mit matplotlib geliefert wird, und die gleiche Größe für alle Figuren einzustellen, damit du das nicht für jede einzelne Figur machen musst.
from pylab import rcParams
rcParams['figure.figsize'] = 15, 5
df7.boxplot(column='Runner_mins')
plt.grid(True, axis='y')
plt.ylabel('Chip Time')
plt.xticks([1], ['Runners'])
([<matplotlib.axis.XTick at 0x570dd106d8>],
<a list of 1 Text xticklabel objects>)
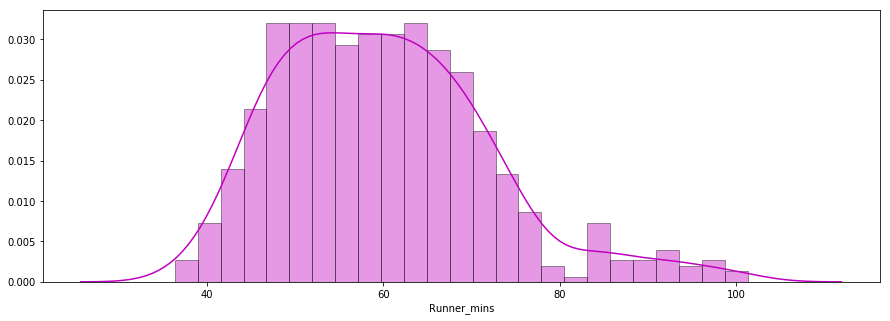
Die zweite Frage, die es zu beantworten gilt, lautet: Folgten die Zielzeiten der Läufer einer Normalverteilung?
Unten siehst du ein Verteilungsdiagramm der Chipzeiten der Läufer, das mit der Seaborn-Bibliothek erstellt wurde. Die Verteilung sieht fast normal aus.
x = df7['Runner_mins']
ax = sns.distplot(x, hist=True, kde=True, rug=False, color='m', bins=25, hist_kws={'edgecolor':'black'})
plt.show()
Bei der dritten Frage geht es darum, ob es Leistungsunterschiede zwischen Männern und Frauen verschiedener Altersgruppen gab. Unten siehst du ein Verteilungsdiagramm der Chipzeiten für Männer und Frauen.
f_fuko = df7.loc[df7[' Gender']==' F']['Runner_mins']
m_fuko = df7.loc[df7[' Gender']==' M']['Runner_mins']
sns.distplot(f_fuko, hist=True, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Female')
sns.distplot(m_fuko, hist=False, kde=True, rug=False, hist_kws={'edgecolor':'black'}, label='Male')
plt.legend()
<matplotlib.legend.Legend at 0x570e301fd0>
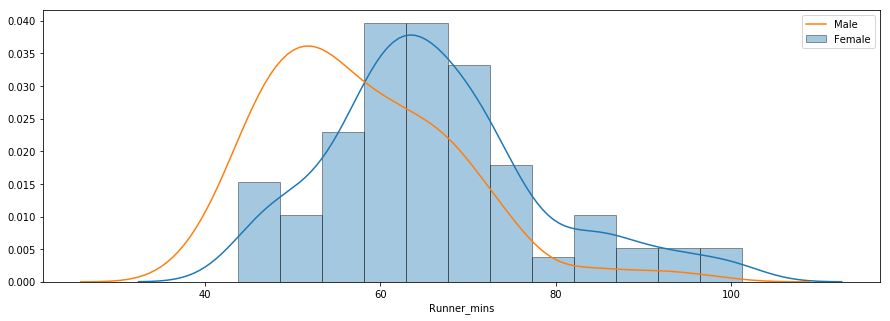
Die Verteilung zeigt, dass Frauen im Durchschnitt langsamer waren als Männer. Du kannst die Methode groupby() verwenden, um zusammenfassende Statistiken für Männer und Frauen getrennt zu berechnen, wie unten gezeigt.
g_stats = df7.groupby(" Gender", as_index=True).describe()
print(g_stats)
Runner_mins \
count mean std min 25% 50%
Gender
F 163.0 66.119223 12.184440 43.766667 58.758333 64.616667
M 414.0 57.640821 11.011857 36.350000 49.395833 55.791667
75% max
Gender
F 72.058333 101.300000
M 64.804167 98.516667
Die durchschnittliche Chipzeit für alle Frauen und Männer betrug ~66 Minuten bzw. ~58 Minuten. Unten siehst du einen Vergleich der Zielzeiten von Männern und Frauen in einem Boxplot nebeneinander.
df7.boxplot(column='Runner_mins', by=' Gender')
plt.ylabel('Chip Time')
plt.suptitle("")
C:\Users\smasango\AppData\Local\Continuum\anaconda3\lib\site-packages\numpy\core\fromnumeric.py:57: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
return getattr(obj, method)(*args, **kwds)
Text(0.5,0.98,'')

In diesem Lernprogramm hast du Web Scraping mit Python durchgeführt. Du hast die Beautiful Soup-Bibliothek verwendet, um Html-Daten zu parsen und in eine Form umzuwandeln, die für die Analyse verwendet werden kann. Du hast die Daten in Python bereinigt und mit den Python-Bibliotheken matplotlib und seaborn nützliche Diagramme (Boxplots, Balkendiagramme und Verteilungsdiagramme) erstellt, um interessante Trends zu erkennen. Nach diesem Tutorial solltest du in der Lage sein, mit Python Daten aus dem Internet zu scrapen, Bereinigungstechniken anzuwenden und nützliche Erkenntnisse aus den Daten zu gewinnen.
Wenn du mehr über Python erfahren möchtest, besuche den kostenlosen Kurs "Einführung in Python für Data Science " von DataCamp und sieh dir unser Tutorial über das Scrapen von Amazon mit Python an.
Erfahre mehr über Python
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Aditya Sharma
Tutorial
DataCamp Team
