
Leerpad
Containerisatie en virtualisatie met Docker en Kubernetes
13 Hr
Ik herinner me nog hoe ik me voorbereidde op mijn eerste Kubernetes-sollicitatie. Hoewel ik een goed begrip had van containerorkestratie, merkte ik al snel dat slagen voor een Kubernetes-sollicitatie veel meer vereiste dan alleen theoretische kennis. Het vroeg om praktijkervaring, troubleshooting-skills en het vermogen om uitdagingen uit de echte wereld op te lossen.
Nu, na uitgebreid met Kubernetes te hebben gewerkt en meerdere sollicitaties te hebben doorlopen, heb ik inzicht gekregen in wat in deze gesprekken echt telt.
In deze gids deel ik alles wat je nodig hebt om je voor te bereiden op je Kubernetes-sollicitatie, waaronder:
Aan het einde van dit artikel heb je een solide routekaart om je voor te bereiden op je Kubernetes-sollicitaties en je carrière naar een hoger niveau te tillen!
Voordat we in de vragen duiken, kijken we kort naar de basis van Kubernetes. Sla deze sectie gerust over als je deze concepten al kent.
Kubernetes (K8s) is een open-source platform voor containerorkestratie dat de uitrol, schaalvergroting en het beheer van gecontaineriseerde applicaties automatiseert. Het is oorspronkelijk ontwikkeld door Google en later gedoneerd aan de Cloud Native Computing Foundation (CNCF).
Kubernetes is uitgegroeid tot de industriestandaard voor het beheren van op microservices gebaseerde applicaties in cloudomgevingen.
Het biedt de volgende functies:
Maar waarom is het überhaupt zo belangrijk? Het vereenvoudigt de uitrol en het beheer van microservices en containers door complexe taken zoals rolling updates, service discovery en fouttolerantie te automatiseren. Kubernetes plant workloads dynamisch in over beschikbare compute-resources en schermt deze complexe principes af voor de eindgebruiker.
Kubernetes bestaat uit de volgende kerncomponenten:
Worker Node-componenten:
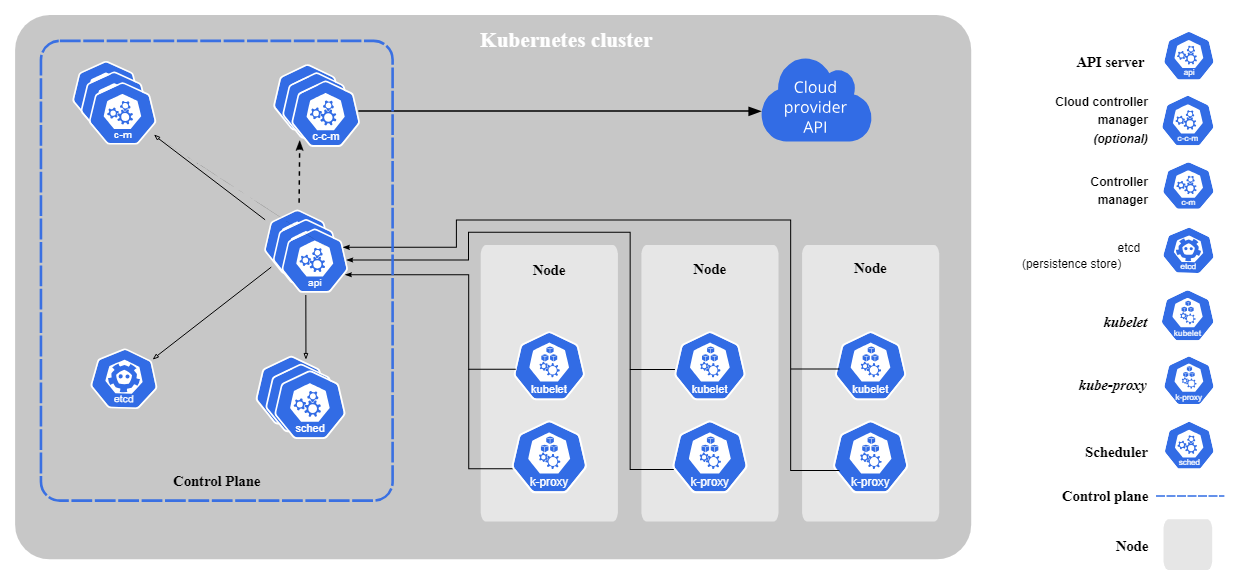
Kerncomponenten van Kubernetes. Afbeelding door Kubernetes.io
Kubernetes volgt een master-workerarchitectuur. De controlplane (voorheen masternode) beheert clusteroperaties, terwijl workernodes gecontaineriseerde applicaties draaien. Pods, de kleinste deploybare eenheid in Kubernetes, draaien containers en worden aan nodes toegewezen.
Kubernetes zorgt voor de gewenste status door workloads continu te monitoren en waar nodig aan te passen.
Nog steeds in de war over hoe Kubernetes en Docker zich tot elkaar verhouden? Bekijk deze uitgebreide vergelijking tussen Kubernetes en Docker om hun rollen in gecontaineriseerde omgevingen te begrijpen.
Laten we beginnen met basisvragen over Kubernetes. Deze vragen behandelen de fundamentele kennis die nodig is om met Kubernetes te werken en het te begrijpen.
Een Pod is de kleinste deploybare eenheid in Kubernetes. Het vertegenwoordigt één of meer containers die in een gedeelde omgeving draaien. Containers binnen een Pod delen netwerk- en opslagresources.
Hier is een eenvoudige YAML-definitie van een Pod:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx-container
image: nginx:1.21
ports:
- containerPort: 80Kubectl is de primaire CLI-tool voor het beheren van Kubernetes-resources en het interacten met het cluster. Hier zijn een paar veelvoorkomende kubectl-opdrachten die je zou moeten kennen:
kubectl get pods # list all Pods
kubectl get services # list all Services
kubectl logs <pod-name> # view logs of a Pod
kubectl exec -it <pod-name> – /bin/sh # open a shell inside a PodEen Deployment in Kubernetes is een abstractie op hoger niveau die de levenscyclus van Pods beheert. Het zorgt ervoor dat het gewenste aantal replicas actief is en biedt functies zoals rolling updates, rollbacks en self-healing.
Zo ziet een eenvoudige YAML-definitie van een Deployment eruit:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80Een Service in Kubernetes stelt een groep Pods bloot en maakt communicatie van en naar die Pods mogelijk.
Omdat Pods vluchtig zijn kunnen hun IP’s veranderen, wat betekent dat de applicatie die met de Pods praat ook het IP-adres zou moeten wijzigen. Services bieden daarom een stabiel netwerk-eindpunt met een vast IP-adres.
Een eenvoudige YAML-definitie van een Service:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIPBovenstaande Service leidt verkeer door naar Pods die het label app: my-app hebben.
Kubernetes biedt vier hoofdtypen Services, elk met een ander netwerkmateriaal:
ConfigMaps slaan niet-gevoelige configuratiegegevens op, terwijl Secrets gevoelige gegevens zoals API-sleutels en wachtwoorden opslaan.
Door Secrets te gebruiken voorkom je dat je geheime informatie in je applicatiecode stopt. ConfigMaps maken je applicaties juist beter configureerbaar, omdat deze waarden makkelijk aan te passen zijn en je ze niet in je applicatiecode hoeft te bewaren.
Voorbeeld YAML-definitie van een ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config
data:
database_url: "postgres://db.example.com"Voorbeeld YAML-definitie van een Secret (met base64-gecodeerde [niet versleutelde] data):
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
password: cGFzc3dvcmQ= # "password" encoded in Base64Een Namespace is een virtueel cluster binnen een Kubernetes-cluster. Het helpt workloads organiseren in multi-tenantomgevingen door resources binnen een cluster te isoleren.
Hieronder vind je een korte code snippet die laat zien hoe je met kubectl een Namespace maakt en hoe je in die Namespace Pods aanmaakt en ophaalt:
# create a namespace called “dev”
kubectl create namespace dev
# create a Pod in that namespace
kubectl run nginx --image=nginx --namespace=dev
# get Pods in that namespace
kubectl get pods --namespace=devLabels zijn key/value-paren die aan objecten (bijv. Pods) worden toegevoegd. Ze helpen Kubernetes-objecten te organiseren. Selectors filteren resources op basis van Labels.
Hier is een voorbeeld van een Pod met de labels environment: production en app: nginx:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:1.21
ports:
- containerPort: 80Je zou nu de volgende labelselector kunnen gebruiken om alle Pods op te halen die het label environment: pod hebben toegewezen:
kubectl get pods -l environment=productionPersistent Volumes (PVs) bieden opslag die blijft bestaan buiten de levenscyclus van Pods. De PV is een opslagonderdeel in het cluster dat is ingericht door een clusterbeheerder of dynamisch is ingericht met StorageClasses.
Een Persistent Volume Claim (PVC) is een opslagaanvraag van een gebruiker.
Hier is een voorbeeld YAML-definitie van een PV en PVC:
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
hostPath:
path: "/mnt/data"apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiNu je de basis geoefend hebt, kunnen we doorgaan met vragen op gemiddeld niveau. Inzicht in concepten zoals netwerken, beveiliging, resourcebeheer en troubleshooting is op dit niveau essentieel.
Kubernetes-networking maakt communicatie mogelijk tussen Pods, Services en externe clients. Het volgt een vlak netwerkmodel, wat betekent dat standaard alle Pods met elkaar kunnen communiceren.
Belangrijke netwerkconcepten in Kubernetes zijn onder andere:
RBAC is een beveiligingsmechanisme dat gebruikers en services beperkt op basis van hun permissies. Het bestaat uit:
De volgende YAML toont een voorbeeldrol die alleen-lezen toegang tot Pods toestaat:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]Deze pod-reader-rol kan nu aan een gebruiker worden gebonden met RoleBinding:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: pod-reader-binding
subjects:
- kind: User
name: dummy
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.ioKubernetes biedt drie soorten autoscaling om het resourcegebruik te optimaliseren:
Je kunt een HPA maken met kubectl:
kubectl autoscale deployment nginx --cpu-percent=50 --min=1 --max=10Bovenstaand commando maakt een HPA voor een Deployment met de naam nginx en probeert de gemiddelde CPU-belasting over alle Pods op 50% te houden, met een minimum van 1 replica en een maximum van 10 replicas.
Wanneer Pods falen, biedt Kubernetes meerdere manieren om te debuggen:
kubectl logs om containerlogs op fouten te controleren.kubectl describe pod om events en recente statuswijzigingen te inspecteren.kubectl exec om een interactieve shell te openen en van binnenuit de container te onderzoeken.kubectl get pods --field-selector=status.phase=Failed om alle falende Pods op te sommen.# get logs of a specific Pod
kubectl get logs <pod-name>
# describe the Pod and check events
kubectl describe pod <pod-name>
# open an interactive shell inside the Pod
kubectl exec -it <pod-name> – /bin/sh
# check all failing pods
kubectl get pods --field-selector=status.phase=FailedMet deze commando’s kun je misconfiguraties, resourcebeperkingen of applicatiefouten achterhalen.
Kubernetes Deployments ondersteunen rolling updates om downtime te voorkomen. Je kunt een rolling update uitvoeren door een Deployment te bewerken of expliciet de image naar een nieuwe versie te zetten met:
kubectl set image deployment/my-deployment nginx=nginx:1.21Vervolgens kun je de status van de Deployment controleren:
kubectl rollout status deployment my-deploymentAls je wilt terugdraaien naar de vorige versie, kun je uitvoeren:
kubectl rollout undo deployment my-deploymentEen Ingress is een API-object dat externe HTTP/HTTPS-toegang tot Services binnen een Kubernetes-cluster beheert. Het maakt routing van verzoeken op basis van hostnaam en paden mogelijk en fungeert als reverse proxy voor meerdere applicaties.
Voorbeeld YAML-definitie van een Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- host: my-app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-service
port:
number: 80De Gateway API is de moderne evolutie van Kubernetes-networking die de standaard Ingress wil vervangen. Hoewel Ingress is ontworpen voor eenvoudige HTTP-routing, werd het beperkt en gefragmenteerd naarmate clusters complexer werden.
De Gateway API verbetert dit door:
In Kubernetes kun je resource-requests en -limieten voor Pods instellen om eerlijke toewijzing te waarborgen en overmatig gebruik van clusterresources te voorkomen.
Voorbeeld YAML-definitie van een Pod met resource-requests en -limieten:
apiVersion: v1
kind: Pod
metadata:
name: resource-limited-pod
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"Als het geheugengebruik van een Pod de toegewezen geheugenlimiet overschrijdt, wordt de container onmiddellijk beëindigd met een out-of-memory (OOM)-fout. De container wordt herstart als er een restart policy is gedefinieerd.
In tegenstelling tot geheugen wordt een Pod die zijn toegewezen CPU-limiet overschrijdt niet beëindigd. In plaats daarvan knijpt Kubernetes het CPU-gebruik, waardoor de applicatie trager wordt.
Init-containers zijn speciale containers die draaien vóór de primaire containers starten. Ze bereiden de omgeving voor door afhankelijkheden te controleren, configuratiebestanden te laden of data klaar te zetten.
Een voorbeeld is een init-container die wacht tot een database is opgestart:
apiVersion: v1
kind: Pod
metadata:
name: app-with-init
spec:
initContainers:
- name: wait-for-db
image: busybox
command: ['sh', '-c', 'until nc -z db-service 5432; do sleep 2; done']
containers:
- name: my-app
image: my-app-imageKubernetes zorgt voor hoge beschikbaarheid via Pod Disruption Budgets (PDB’s), anti-affinity-regels en self-healing-mechanismen. Zo werken deze mechanismen:
Hier is een voorbeeld YAML-definitie van een PDB die ervoor zorgt dat minimaal twee Pods blijven draaien tijdens verstoringen:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-app-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: my-appDeze sectie behandelt gevorderde Kubernetes-vragen, met focus op stateful applicaties, multiclusterbeheer, beveiliging, prestatie-optimalisatie en troubleshooting. Als je solliciteert voor een seniorrol, zorg dan dat je deze doorneemt.
Een StatefulSet wordt gebruikt voor stateful applicaties die stabiele netwerkidentiteiten, persistente opslag en geordende deployment vereisen. In tegenstelling tot Deployments garanderen StatefulSets dat:
pod-0, pod-1 enz.Een service mesh beheert service-naar-service communicatie en biedt:
Al deze functies zitten in de infrastructuurlaag, dus er zijn geen codewijzigingen nodig.
Populaire service-mesh-oplossingen voor Kubernetes zijn: Istio, Linkerd en Consul.
Volg het 4C-beveiligingsmodel om een Kubernetes-cluster te beveiligen:
Taints en Tolerations bepalen waar Pods draaien:
Hier is een voorbeeld van het tainten van een node zodat alleen specifieke workloads worden geaccepteerd:
kubectl taint nodes node1 key1=value1:NoScheduleDit betekent dat er geen Pod op node1 kan worden ingepland totdat deze de vereiste Toleration heeft.
Een Toleration wordt toegevoegd in de PodSpec-sectie zoals hieronder:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "key1"
operator: "Equal"
value: “value1”
effect: "NoSchedule"De Pod mag dan worden ingepland op node1.
Een sidecar-container draait naast de hoofdapplicatiecontainer binnen dezelfde Pod. Veelgebruikte toepassingen zijn:
Voorbeeld van een sidecar-container voor logverwerking:
apiVersion: v1
kind: Pod
metadata:
name: app-with-sidecar
spec:
containers:
- name: main-app
image: my-app
volumeMounts:
- mountPath: /var/log
name: shared-logs
- name: log-collector
image: fluentd
volumeMounts:
- mountPath: /var/log
name: shared-logs
volumes:
- name: shared-logs
emptyDir: {}De sidecar-container draait Fluentd, dat logs verzamelt van de hoofdcontainer via een gedeelde volume.
Voor Kubernetes v1.28/1.29 waren sidecar-containers gewoon reguliere containers die naast je app draaiden. Dit veroorzaakte een "raceconditie": als je applicatie vóór je sidecar startte (bijv. een beveiligingsproxy of log-shipper), kon de app crashen of data verliezen omdat de helper nog niet klaar was.
Native Sidecars lossen dit op door sidecars te kunnen definiëren binnen de sectie initContainers met een restartPolicy: Always.
Pods kunnen vastlopen in de statussen Pending, CrashLoopBackOff of ImagePullBackOff:
Je kunt de events van de Pod controleren met het commando describe:
kubectl describe pod <pod-name>Een mutating admission webhook maakt realtime aanpassing van Kubernetes-objecten mogelijk voordat ze op het cluster worden toegepast en opgeslagen. Het draait een dynamische admission controller in Kubernetes die API-verzoeken onderschept voordat objecten in etcd worden opgeslagen. Het kan de requestpayload wijzigen door velden in te voegen, te veranderen of te verwijderen voordat het verzoek wordt toegestaan.
Ze worden vaak gebruikt voor:
Zero-downtime Deployments zorgen ervoor dat updates live verkeer niet onderbreken. Kubernetes bereikt dit met:
Readiness probes helpen Kubernetes voorkomen dat verkeer naar niet-klaarstaande Pods wordt gestuurd.
Een Custom Resource Definition (CRD) breidt de Kubernetes-API’s uit, waardoor gebruikers aangepaste resources kunnen definiëren en beheren. Ze worden gebruikt voor specifieke use-cases waarbij je nog steeds de Kubernetes-API wilt gebruiken om deze resources te beheren, zoals:
Voorbeeld YAML-definitie van een CRD:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: shirts.stable.example.com
spec:
group: stable.example.com
scope: Namespaced
names:
plural: shirts
singular: shirt
kind: Shirt
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
color:
type: string
size:
type: string
selectableFields:
- jsonPath: .spec.color
- jsonPath: .spec.size
additionalPrinterColumns:
- jsonPath: .spec.color
name: Color
type: string
- jsonPath: .spec.size
name: Size
type: stringJe zou nu bijvoorbeeld het object shirt kunnen ophalen met kubectl:
kubectl get shirtsOntdek hoe je Docker en Kubernetes kunt inzetten voor machinelearning-workflows in deze praktische tutorial over containerization.
Een Kubernetes-operator breidt de functionaliteit van Kubernetes uit door het uitrollen, schalen en beheren van complexe applicaties te automatiseren. Hij is gebouwd met CRD’s en custom controllers om applicatiespecifieke logica af te handelen.
Operators werken door aangepaste resources in Kubernetes te definiëren en te watchen op wijzigingen in het cluster om specifieke taken te automatiseren.
Dit zijn de belangrijkste componenten van een operator:
Kubernetes-beheerders onderhouden, beveiligen en optimaliseren clusters voor productie-workloads. Deze sectie behandelt vragen voor Kubernetes-beheerders met focus op clusterbeheer.
Etcd is de key-value store die de volledige clusterstatus bevat. Regelmatige back-ups zijn essentieel om dataverlies te voorkomen.
Je kunt een back-up maken met onderstaand commando:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>Als je nu wilt herstellen vanaf een back-up, kun je dit uitvoeren:
etcdutl --data-dir <data-dir-location> snapshot restore snapshot.dbHet upgraden van een Kubernetes-cluster is een meerstapsproces dat minimale downtime vereist en de clusterstabiliteit behoudt. Beheerders moeten een gestructureerde aanpak volgen om problemen tijdens de upgrade te voorkomen:
Kubernetes-beheerders moeten CPU, geheugen, opslag, netwerk en applicatiegezondheid monitoren. De volgende tools worden hiervoor aanbevolen:
Beveiliging is cruciaal, en iedere beheerder moet best practices volgen om een Kubernetes-cluster te beveiligen:
Leer hoe Kubernetes in de cloud wordt geïmplementeerd met deze gids over containerorkestratie met AWS Elastic Kubernetes Service (EKS).
Gecentraliseerde logging is nodig voor debugging en auditing. Twee verschillende loggingstacks:
Hoge beschikbaarheid is essentieel om downtime van applicaties in je Kubernetes-cluster te voorkomen. Je kunt hoge beschikbaarheid waarborgen door:
Multi-tenancy is erg belangrijk als je Kubernetes voor je organisatie inricht. Het stelt meerdere teams of applicaties in staat om een Kubernetes-cluster veilig te delen zonder elkaar te beïnvloeden.
Er zijn twee typen multi-tenancy:
Etcd slaat de volledige clusterstatus op, wat betekent dat er kritieke informatie in staat.
Standaard slaat Kubernetes secrets onversleuteld op in etcd, waardoor ze kwetsbaar zijn bij een compromis. Daarom kan het cruciaal zijn om secret-encryptie at REST in te schakelen zodat secrets versleuteld worden opgeslagen.
Als eerste stap moet je een encryptieconfiguratiebestand maken en daarin een versleutelings-/ontsleutelingssleutel opslaan:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <BASE64_ENCODED_SECRET>
- identity: {}De bovenstaande configuratie specificeert dat Kubernetes de provider aescbc zal gebruiken om Secret-resources te versleutelen, met een fallback naar identity voor onversleutelde data.
Vervolgens moet je het configuratiebestand van de kube-apiserver aanpassen, meestal te vinden op /etc/kubernetes/manifests/kube-apiserver.yaml op een controlplane-node, en de vlag -- encryption-provider-config toevoegen die verwijst naar het zojuist gemaakte encryptieconfiguratiebestand:
command:
- kube-apiserver
...
- --encryption-provider-config=/path/to/encryption-config.yamlSla de wijzigingen op en herstart de kube-apiserver om de nieuwe configuratie toe te passen.
Resource quotas voorkomen dat één tenant (namespace) buitensporig veel clusterresources verbruikt, waardoor andere tenants hinder ondervinden.
Je kunt ResourceQuotas definiëren voor namespaces om een bepaalde hoeveelheid resources aan die specifieke namespace toe te wijzen. Gebruikers van die namespace kunnen dan resources aanmaken die samen maximaal de in de ResourceQuota vastgelegde resources verbruiken.
Voorbeeld YAML-definitie van een ResourceQuota:
apiVersion: v1
kind: ResourceQuota
metadata:
name: namespace-quota
namespace: team-a
spec:
hard:
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "8"
limits.memory: "16Gi"
pods: "20"Je kunt een ResourceQuota van een namespace controleren met:
kubectl describe resourcequota namespace-quota -n team-aCoreDNS is de standaard DNS-provider voor Kubernetes-clusters. Het biedt service discovery en maakt het mogelijk dat Pods interne DNS-namen gebruiken in plaats van IP-adressen.
Functies van CoreDNS:
my-service.default.svc.cluster.local).Je kunt CoreDNS configureren met de ConfigMap in de namespace kube-system. Je kunt de huidige instellingen bekijken met:
kubectl get configmap coredns -n kube-system -o yamlWerk die ConfigMap bij en pas de wijzigingen toe om de CoreDNS-configuratie aan te passen.
Engineers krijgen in echte Kubernetes-omgevingen regelmatig te maken met complexe uitdagingen op het gebied van schaalbaarheid, netwerk, beveiliging, prestaties en troubleshooting, en dat weten de interviewers. Deze sectie presenteert scenario-gebaseerde vragen die je vermogen testen om praktische Kubernetes-problemen op te lossen.
“Je team meldt dat een applicatie die in Kubernetes draait traag is geworden en dat gebruikers hoge responstijden ervaren. Hoe los je dit op?”
Je kunt het probleem benaderen met de volgende stappen:
1. Controleer het resourcegebruik van de Pod. Verhoog resources als ze aan hun limieten zitten.
kubectl top pods --sort-by=cpu
kubectl top pods --sort-by=memory2. Beschrijf de trage Pod voor meer informatie. Let op resource throttling, aantal herstarts of liveness probe-fouten.
kubectl describe pod <pod-name>3. Controleer containerlogs op fouten. Let op time-outs, errors of verbindingsfouten.
kubectl logs <pod-name>4. Test netwerklatentie, want die kan applicaties vertragen.
kubectl exec -it <pod-name> -- ping my-database kubectl exec -it <pod-name> -- curl http://my-service5. Controleer de gezondheid van Kubernetes-nodes en kijk of nodes resources uitgeput zijn.
kubectl get nodes kubectl describe node <node-name>43. Een Nginx-webserver draait, maar de blootgestelde URL kan niet verbinden
“Je hebt een Nginx-webserver in Kubernetes uitgerold en de Pod draait prima, maar de applicatie is niet toegankelijk via de blootgestelde URL. Wat kun je doen?”
Stappen om het bovenstaande probleem te benaderen:
1. Verifieer dat de Nginx-Pod draait en gezond is.
kubectl get pods -o wide kubectl describe pod nginx-web2. Controleer de Service en poortmapping. Zorg dat de juiste poort wordt blootgesteld en overeenkomt met de containerpoort van de Pod. Controleer of de Service de juiste Pods vindt.
kubectl describe service nginx-service3. Controleer netwerkpolicies. Als een netwerkpolicy inkomend verkeer blokkeert, is de Service niet toegankelijk.
kubectl get networkpolicies kubectl describe networkpolicy <policy-name>4. Verifieer Ingress- en externe DNS-configuratie.
kubectl describe ingress nginx-ingress44. Kubernetes Deployment faalt na een upgrade
“Je hebt een nieuwe versie van je applicatie uitgerold, maar die start niet, waardoor er downtime voor je gebruikers ontstaat. Hoe los je dit op?”
Aanpak om het probleem te tackelen:
1. Rol terug naar de vorige werkende versie.
kubectl rollout undo deployment my-app2. Controleer de Deployment-geschiedenis en identificeer wat er in de nieuwe versie is gewijzigd.
kubectl rollout history deployment my-app3. Controleer de logs van de nieuwe Pods op fouten.
kubectl logs -l app=my-app4. Controleer readiness- en liveness-probes.
5. Verifieer image-pullproblemen. Soms is de nieuwe image verkeerd of niet beschikbaar.
45. De applicatie kan geen verbinding maken met een externe database
“Een microservice die in Kubernetes draait kan geen verbinding maken met een externe database, die buiten het cluster wordt gehost. Hoe los je dit op?”
Stappen om het probleem te benaderen:
1. Verifieer externe connectiviteit vanuit een Pod. Controleer of de database bereikbaar is vanuit het Kubernetes-netwerk.
kubectl exec -it <pod-name> -- curl http://my-database.example.com:54322. Controleer DNS-resolutie binnen de Pod. Als dit mislukt, is CoreDNS mogelijk verkeerd geconfigureerd.
kubectl exec -it <pod-name> -- nslookup my-database.example.com3. Controleer of er netwerkpolicies zijn die externe toegang blokkeren, want die kunnen uitgaand verkeer verhinderen.
kubectl get networkpolicies kubectl describe networkpolicy <policy-name>46. Clusterresources zijn uitgeput, waardoor nieuwe Pods in de pendingstatus blijven
“Nieuwe Pods blijven in de status Pending. Bij nadere inspectie zien we het bericht: “0/3 nodes are available: insufficient CPU and memory”. Hoe ga je te werk om dit te debuggen en op te lossen?”
Stappen om het probleem te benaderen:
1. Controleer de beschikbaarheid van clusterresources. Kijk naar hoog CPU-/geheugengebruik dat scheduling verhindert.
kubectl describe node <node-name> kubectl top nodes2. Controleer welke Pods de meeste resources verbruiken. Stel resources en limieten in voor Pods om overmatig gebruik te voorkomen. Je kunt dit ook voor alle namespaces in het cluster afdwingen.
kubectl top pods --all-namespaces3. Schaal niet-essentiële workloads omlaag om resources vrij te maken.
kubectl scale deployment <deployment-name> --replicas=04. Vergroot het aantal beschikbare nodes om clusterresources te verhogen. Je kunt ook meer nodes toevoegen aan de cluster autoscaler als die wordt gebruikt.
Tips om je voor te bereiden op een Kubernetes-sollicitatie
Uit mijn eigen ervaring met Kubernetes-sollicitaties heb ik geleerd dat succes meer vereist dan het onthouden van concepten. Je moet je kennis kunnen toepassen in praktijksituaties, efficiënt troubleshooten en je oplossingen helder uitleggen.
Als je wilt slagen in Kubernetes-sollicitaties, volg dan de onderstaande tips:
- Beheers de kernconcepten van Kubernetes. Zorg dat je Pods, Deployments, Services, Persistent Volumes, ConfigMaps, Secrets, enz. begrijpt.
- Doe praktijkervaring op met Kubernetes. Toen ik me voorbereidde, hielp het me enorm om mijn eigen Minikube-cluster op te zetten en microservices uit te rollen. Je kunt ook een managed Kubernetes-dienst van een cloudprovider gebruiken om op schaal te oefenen.
- Leer hoe je Kubernetes-problemen debugt, want troubleshooting is een groot onderdeel van werken met Kubernetes in de praktijk. Je zult op je werk waarschijnlijk het grootste deel van je tijd besteden aan troubleshooting van applicaties.
- Typische issues zijn vastzittende Pods, netwerkstoringen, persistent volumes die niet goed mounten en node-failures.
- Begrijp Kubernetes-networking en load balancing. Focus op hoe networking is geïmplementeerd, hoe Pods communiceren, welke servicetypen er zijn en hoe je applicaties exposeert.
- Weet hoe je Kubernetes-workloads schaalt en optimaliseert. Interviewers vragen vaak naar schaalstrategieën en kostenoptimalisatie. Wees vaardig met HPA, cluster autoscaler, resource-requests en -limieten.
- Begrijp best practices voor Kubernetes-beveiliging. Wees bekend met RBAC, Pod security context, netwerkpolicies en secretbeheer.
- Bestudeer de Kubernetes-architectuur en -internals. Weet hoe de controlplanecomponenten werken en hoe kubelet en de container runtime samenwerken.
Door theoretische kennis te combineren met praktijkervaring en te leren van troubleshooting in de echte wereld, slaag je voor elke Kubernetes-sollicitatie!
Conclusie
Kubernetes is een krachtig maar complex systeem voor containerorkestratie. Solliciteren voor Kubernetes-rollen vereist een diep begrip van theorie en probleemoplossing in de praktijk. Of je nu een junior engineer bent die op zoek is naar je eerste baan of een senior engineer die mikt op meer gevorderde rollen, voorbereiding is altijd de sleutel.
Ik kan niet genoeg benadrukken hoe belangrijk oefenen is. Het helpt je sneller issues in je applicaties te vinden en zelfverzekerder te worden in je kunnen.
Als je je basis wilt versterken, raad ik je aan om cursussen als Containerization and Virtualization Concepts te volgen om een solide fundament op te bouwen, gevolgd door Introduction to Kubernetes om praktische ervaring met Kubernetes op te doen. Als je er klaar voor bent, kun je kijken naar een Kubernetes-certificering om je skills te laten zien.
Heel veel succes met je sollicitaties!
Ik ben een Cloud Engineer met een sterke basis in elektrotechniek, machine learning en programmeren. Mijn carrière begon in computervisie, met een focus op beeldclassificatie, waarna ik overstapte naar MLOps en DataOps. Ik ben gespecialiseerd in het bouwen van MLOps-platformen, het ondersteunen van data scientists en het leveren van Kubernetes-gebaseerde oplossingen om machinelearning-workflows te stroomlijnen.
Leer meer over Docker en Kubernetes met deze cursussen!
Leerpad
Cursus
Cursus

blog
Adel Nehme
15 min