
Cursus
Conteneurisation et virtualisation avec Docker et Kubernetes
13 h
Je me souviens encore de la préparation de mon premier entretien Kubernetes. Même si j'avais une solide compréhension de l'orchestration de conteneurs, j'ai rapidement réalisé que réussir un entretien avec Kubernetes nécessitait bien plus que des connaissances théoriques. Il exigeait une expérience pratique, des compétences en matière de dépannage et la capacité de résoudre des problèmes concrets.
Aujourd'hui, après avoir travaillé de manière intensive avec Kubernetes et passé de nombreux entretiens, j'ai pu comprendre ce qui compte vraiment dans ces discussions.
Dans ce guide, je partagerai tout ce dont vous avez besoin pour vous préparer à votre entretien Kubernetes, notamment :
À la fin de cet article, vous disposerez d'une feuille de route solide pour préparer vos entretiens Kubernetes et faire passer votre carrière au niveau supérieur !
Avant d'aborder les questions de l'entretien, jetons un coup d'œil rapide aux principes fondamentaux de Kubernetes. N'hésitez pas à sauter cette section si vous êtes déjà familiarisé avec ces concepts.
Kubernetes (K8s) est une plateforme d'orchestration de conteneurs open-source qui automatise le déploiement, la mise à l'échelle et la gestion des applications conteneurisées. À l'origine, c'est Google qui l'a développé, avant d'en faire don à la Cloud Native Computing Foundation (CNCF).
Kubernetes est devenu la norme du secteur pour la gestion des applications basées sur les microservices dans les environnements cloud.
Il présente les caractéristiques suivantes :
Mais pourquoi est-ce essentiel ? Il simplifie le déploiement et l'exploitation des microservices et des conteneurs en automatisant des tâches complexes telles que les mises à jour continues, la découverte de services et la tolérance aux pannes. Kubernetes planifie dynamiquement les charges de travail sur les ressources informatiques disponibles et fait abstraction de ces principes conceptuels pour l'utilisateur final.
Kubernetes se compose des éléments de base suivants :
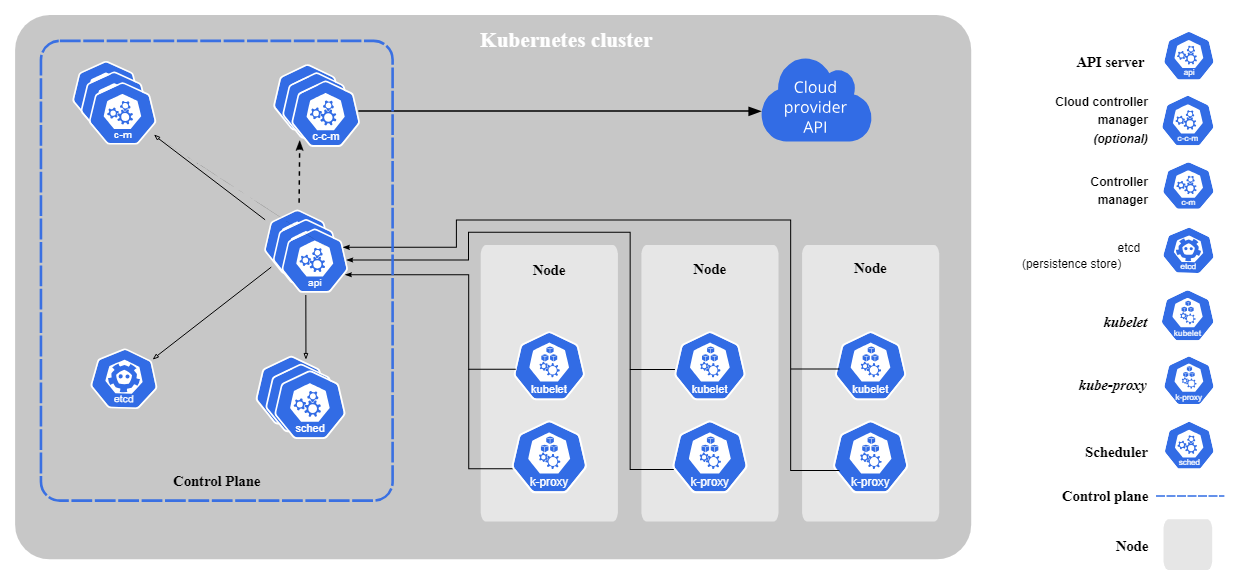
Composants de base de Kubernetes. Image par Kubernetes.io
Kubernetes suit une architecture maître-ouvrier. Le plan de contrôle (nœud maître) gère les opérations de la grappe tandis que les nœuds de travail exécutent les applications conteneurisées. Les pods, la plus petite unité déployable de Kubernetes, exécutent des conteneurs et sont affectés à des nœuds.
Kubernetes garantit l'état souhaité en surveillant et en ajustant en permanence les charges de travail selon les besoins.
Vous ne savez toujours pas comment comparer Kubernetes et Docker ? Consultez ce site approfondi Kubernetes vs. Comparaison Docker pour comprendre leur rôle dans les environnements conteneurisés.
Apprenez-en plus sur Docker et Kubernetes avec ces cours !
Cursus
Cours
Cours
blog
Zoumana Keita
15 min
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Lynn Heidmann
blog
Kurtis Pykes
9 min
Tutoriel

