
Programma
Containerizzazione e virtualizzazione con Docker e Kubernetes
13 h
Ricordo ancora quando mi preparavo per il mio primo colloquio su Kubernetes. Pur avendo una buona comprensione dell'orchestrazione dei container, ho capito presto che superare un colloquio su Kubernetes richiedeva molto più della semplice teoria. Servivano esperienza pratica, capacità di troubleshooting e la capacità di risolvere problemi reali.
Oggi, dopo aver lavorato a lungo con Kubernetes e aver sostenuto diversi colloqui, ho maturato alcune intuizioni su ciò che conta davvero in queste conversazioni.
In questa guida, condividerò tutto quello che ti serve per prepararti a un colloquio su Kubernetes, tra cui:
Alla fine di questo articolo, avrai una roadmap solida per prepararti ai colloqui su Kubernetes e far fare un salto di qualità alla tua carriera!
Prima di entrare nelle domande da colloquio, diamo un'occhiata veloce ai fondamentali di Kubernetes. Se conosci già questi concetti, sentiti libero di saltare questa sezione.
Kubernetes (K8s) è una piattaforma open-source per l'orchestrazione di container che automatizza il deployment, lo scaling e la gestione delle applicazioni containerizzate. Google l'ha sviluppata originariamente e successivamente l'ha donata alla Cloud Native Computing Foundation (CNCF).
Kubernetes è diventato lo standard di settore per la gestione di applicazioni basate su microservizi negli ambienti cloud.
Offre le seguenti funzionalità:
Ma perché è così importante? Semplifica il deployment e l'operatività di microservizi e container automatizzando attività complesse come rolling update, service discovery e tolleranza ai guasti. Kubernetes programma dinamicamente i carichi sulle risorse di calcolo disponibili e astrae questi principi complessi dall'utente finale.
Kubernetes è composto dai seguenti componenti principali:
Componenti dei Worker Node:
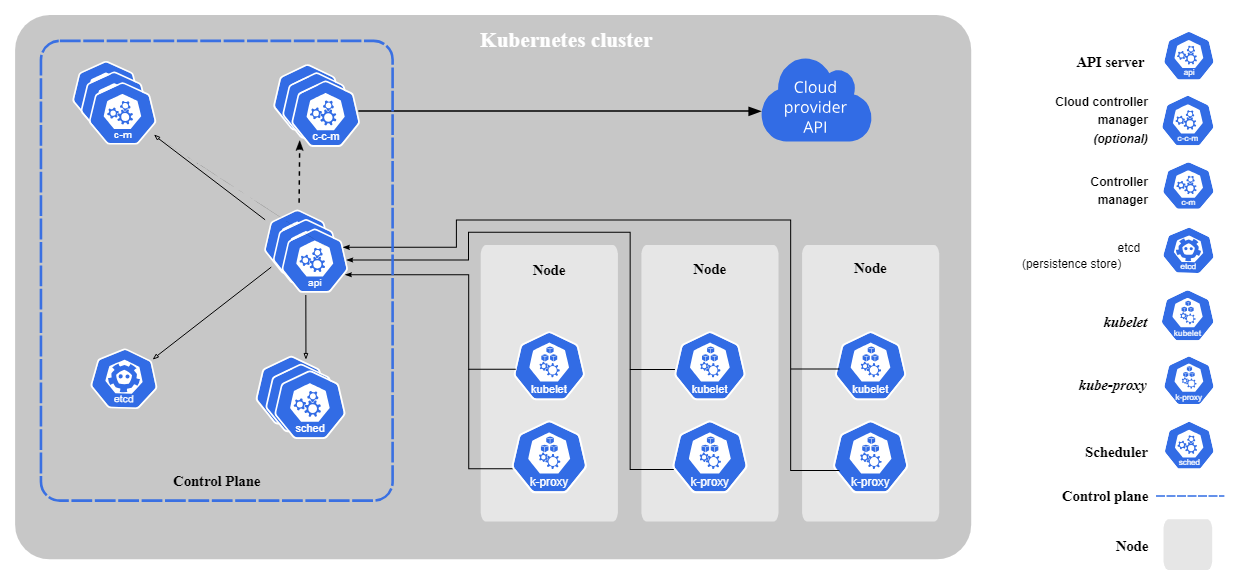
Componenti principali di Kubernetes. Immagine di Kubernetes.io
Kubernetes segue un' architettura master-worker. Il control plane (ex master node) gestisce le operazioni del cluster mentre i worker node eseguono le applicazioni containerizzate. I Pod, la più piccola unità distribuibile in Kubernetes, eseguono i container e vengono assegnati ai nodi.
Kubernetes garantisce lo stato desiderato monitorando e regolando continuamente i carichi quando necessario.
Hai ancora dubbi sul confronto tra Kubernetes e Docker? Dai un'occhiata a questo confronto approfondito tra Kubernetes e Docker per capire i loro ruoli negli ambienti containerizzati.
Approfondisci Docker e Kubernetes con questi corsi!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

