
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Ich erinnere mich noch gut an die Vorbereitung auf mein erstes Kubernetes-Interview. Ich hatte zwar ein solides Verständnis von Container-Orchestrierung, aber ich merkte schnell, dass man für ein Kubernetes-Interview viel mehr als nur theoretisches Wissen braucht. Sie verlangte praktische Erfahrung, Fähigkeiten zur Fehlersuche und die Fähigkeit, reale Herausforderungen zu lösen.
Nachdem ich ausgiebig mit Kubernetes gearbeitet und mehrere Interviews geführt habe, weiß ich jetzt, worauf es bei diesen Diskussionen wirklich ankommt.
In diesem Leitfaden erfährst du alles, was du zur Vorbereitung auf dein Kubernetes-Vorstellungsgespräch brauchst, darunter:
Am Ende dieses Artikels wirst du einen soliden Fahrplan haben, um dich auf deine Kubernetes-Vorstellungsgespräche vorzubereiten und deine Karriere auf die nächste Stufe zu bringen!
Bevor wir uns den Interviewfragen widmen, werfen wir einen kurzen Blick auf die Grundlagen von Kubernetes. Du kannst diesen Abschnitt gerne überspringen, wenn du mit diesen Konzepten bereits vertraut bist.
Kubernetes (K8s) ist eine Open-Source-Plattform zur Container-Orchestrierung ( ), die die Bereitstellung, Skalierung und Verwaltung von containerisierten Anwendungen automatisiert. Google hat es ursprünglich entwickelt und später an die Cloud Native Computing Foundation (CNCF) gespendet.
Kubernetes wurde zum Industriestandard für die Verwaltung von Microservices-basierten Anwendungen in Cloud-Umgebungen.
Es bietet die folgenden Funktionen:
Aber warum ist sie überhaupt notwendig? Sie vereinfacht die Bereitstellung und den Betrieb von Microservices und Containern, indem sie komplexe Aufgaben wie Rolling Updates, Service Discovery und Fehlertoleranz automatisiert. Kubernetes verteilt die Arbeitslasten dynamisch auf die verfügbaren Rechenressourcen und abstrahiert diese Konzeptprinzipien vom Endnutzer.
Kubernetes besteht aus den folgenden Kernkomponenten:
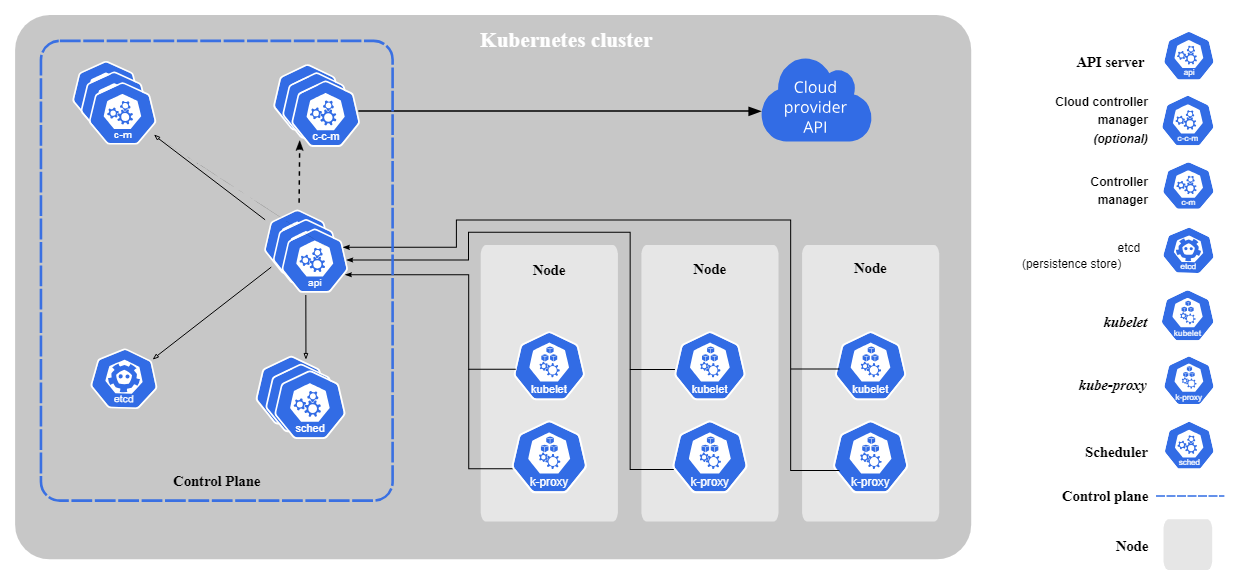
Kernkomponenten von Kubernetes. Bild von Kubernetes.io
Kubernetes folgt einer Master-Worker-Architektur. Die Steuerebene (Master Node) verwaltet den Clusterbetrieb, während die Worker Nodes containerisierte Anwendungen ausführen. Pods, die kleinste einsatzfähige Einheit in Kubernetes, führen Container aus und werden den Knoten zugewiesen.
Kubernetes stellt den gewünschten Zustand sicher, indem es die Workloads kontinuierlich überwacht und bei Bedarf anpasst.
Bist du immer noch verwirrt, wie Kubernetes und Docker im Vergleich aussehen? Schau dir diese ausführliche Kubernetes vs. Kubernetes an. Docker-Vergleich um ihre Rolle in containerisierten Umgebungen zu verstehen.
Lerne in diesen Kursen mehr über Docker und Kubernetes!
Lernpfad
Kurs
Kurs
Blog
Zoumana Keita
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
Tutorial
Kurtis Pykes