
Track
Containerization and Virtualization with Docker and Kubernetes
13 hr
I still remember preparing for my first Kubernetes interview. While I had a solid understanding of container orchestration, I quickly realized that passing a Kubernetes interview required much more than just theoretical knowledge. It demanded hands-on experience, troubleshooting skills, and the ability to solve real-world challenges.
Now, after working extensively with Kubernetes and navigating multiple interviews, I’ve gained insights into what truly matters in these discussions.
In this guide, I’ll share everything you need to prepare for your Kubernetes interview, including:
By the end of this article, you’ll have a solid roadmap to prepare for your Kubernetes interviews and take your career to the next level!
CrashLoopBackOff, OOMKilled, ImagePullBackOff, and resource exhaustion.Before getting into the interview questions, let’s have a quick look at Kubernetes fundamentals. Feel free to skip this section if you are already familiar with these concepts.
Kubernetes (K8s) is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Google originally developed it and later donated it to the Cloud Native Computing Foundation (CNCF).
Kubernetes became the industry standard for managing microservices-based applications in cloud environments. If you want a hands-on introduction to how it works before diving into the interview questions, our Kubernetes tutorial for beginners is a good starting point.
It brings the following features:
But why is it essential in the first place? It simplifies the deployment and operation of microservices and containers by automating complex tasks like rolling updates, service discovery, and fault tolerance. Kubernetes dynamically schedules workloads across available computing resources and abstracts away these complex principles from the end user.
Kubernetes consists of the following core components:
Worker Node Components:
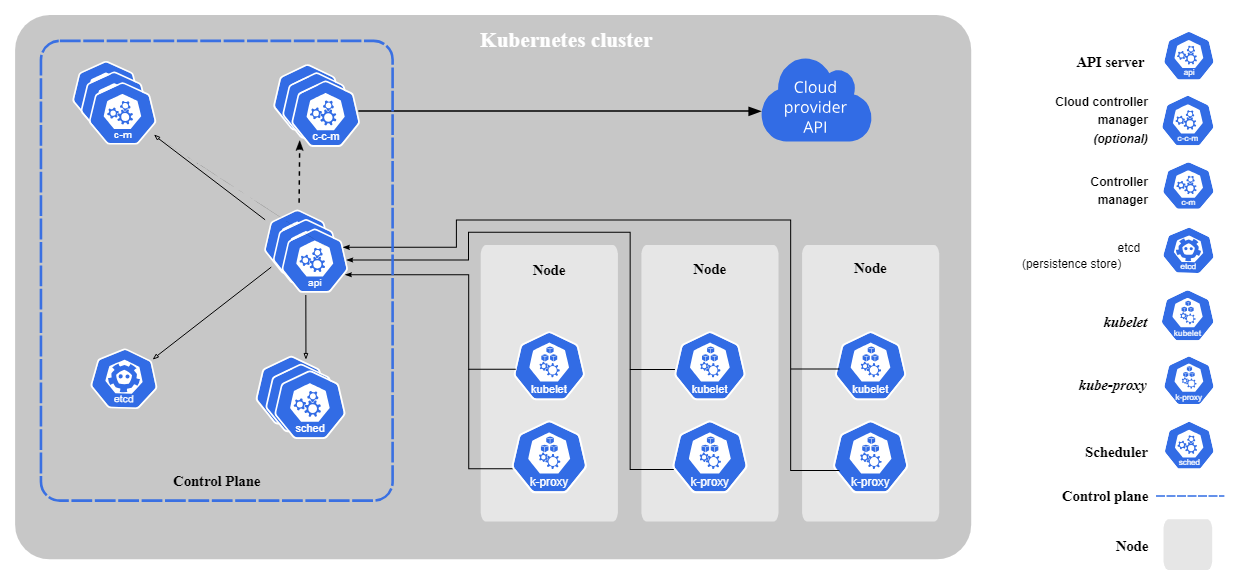
Core components of Kubernetes. Image by Kubernetes.io
Kubernetes follows a master-worker architecture. The control plane (formerly master node) manages cluster operations while worker nodes run containerized applications. Pods, the smallest deployable unit in Kubernetes, run containers and are assigned to nodes.
Kubernetes ensures the desired state by continuously monitoring and adjusting workloads as required.
Still unsure about how Kubernetes and Docker relate? Check out our in-depth Kubernetes vs. Docker comparison to understand their roles in containerized environments, or our guide on Docker Swarm vs. Kubernetes if you're weighing orchestration options.
Learn more about Docker and Kubernetes with these courses!
Track
Course
Course
blog
Laiba Siddiqui
15 min
blog
Thalia Barrera
15 min
blog
Patrick Brus
15 min
blog
Kurtis Pykes
15 min
blog
Abid Ali Awan
15 min
blog
Marie Fayard
15 min
