
Programa
Containerização e virtualização com o Docker e o Kubernetes
13 h
Ainda me lembro da preparação para minha primeira entrevista sobre Kubernetes. Embora eu tivesse uma sólida compreensão da orquestração de contêineres, percebi rapidamente que passar em uma entrevista sobre Kubernetes exigia muito mais do que apenas conhecimento teórico. Exigia experiência prática, habilidades de solução de problemas e a capacidade de resolver desafios do mundo real.
Agora, depois de trabalhar extensivamente com o Kubernetes e passar por várias entrevistas, obtive insights sobre o que realmente importa nessas discussões.
Neste guia, compartilharei tudo o que você precisa para se preparar para a entrevista sobre o Kubernetes, incluindo:
Ao final deste artigo, você terá um roteiro sólido para se preparar para as entrevistas sobre Kubernetes e levar sua carreira para o próximo nível!
Antes de entrar nas perguntas da entrevista, vamos dar uma olhada rápida nos fundamentos do Kubernetes. Sinta-se à vontade para pular esta seção se você já estiver familiarizado com esses conceitos.
O Kubernetes (K8s) é uma plataforma de orquestração de contêineres de código aberto que automatiza a implantação, o dimensionamento e o gerenciamento de aplicativos em contêineres. O Google o desenvolveu originalmente e depois o doou para a Cloud Native Computing Foundation (CNCF).
O Kubernetes tornou-se o padrão do setor para gerenciar aplicativos baseados em microsserviços em ambientes de nuvem.
Ele traz os seguintes recursos:
Mas, em primeiro lugar, por que isso é essencial? Ele simplifica a implantação e a operação de microsserviços e contêineres, automatizando tarefas complexas como atualizações contínuas, descoberta de serviços e tolerância a falhas. O Kubernetes programa dinamicamente as cargas de trabalho nos recursos de computação disponíveis e abstrai esses princípios conceituais do usuário final.
O Kubernetes consiste nos seguintes componentes principais:
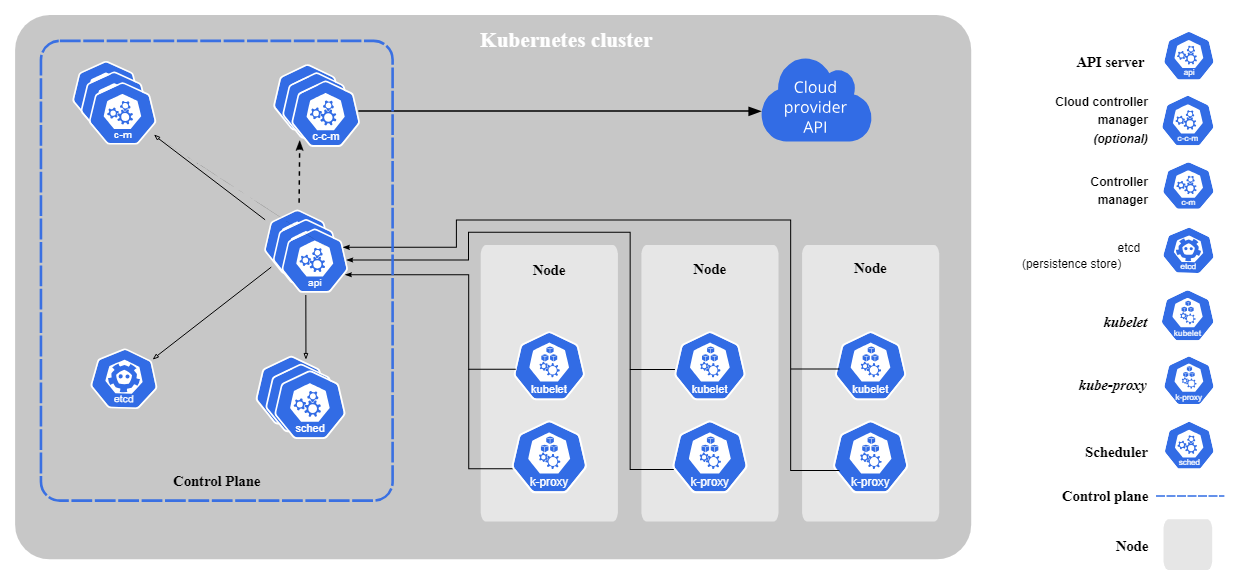
Componentes principais do Kubernetes. Imagem de Kubernetes.io
O Kubernetes segue uma arquitetura de mestre-trabalhador. O plano de controle (nó mestre) gerencia as operações do cluster, enquanto os nós de trabalho executam aplicativos em contêineres. Os pods, a menor unidade implantável no Kubernetes, executam contêineres e são atribuídos a nós.
O Kubernetes garante o estado desejado, monitorando e ajustando continuamente as cargas de trabalho, conforme necessário.
Você ainda está confuso sobre a comparação entre o Kubernetes e o Docker? Confira esta análise detalhada em Kubernetes vs. Kubernetes. Comparação do Docker para entender suas funções em ambientes em contêineres.
Saiba mais sobre o Docker e o Kubernetes com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
15 min
blog
Zoumana Keita
12 min
blog
Chloe Lubin
15 min
blog
Hesam Sheikh Hassani
15 min
blog
Chloe Lubin
15 min


