
programa
Contenedores y virtualización con Docker y Kubernetes
13 h
Aún recuerdo cómo me preparé para mi primera entrevista sobre Kubernetes. Aunque tenía sólidos conocimientos sobre la orquestación de contenedores, enseguida me di cuenta de que para superar una entrevista sobre Kubernetes hacía falta mucho más que conocimientos teóricos. Exigía experiencia práctica, capacidad para solucionar problemas y habilidad para resolver retos del mundo real.
Ahora, después de trabajar extensamente con Kubernetes y de pasar por múltiples entrevistas, he adquirido conocimientos sobre lo que realmente importa en estas discusiones.
En esta guía, compartiré todo lo que necesitas para preparar tu entrevista sobre Kubernetes, incluido:
Al final de este artículo, tendrás una sólida hoja de ruta para preparar tus entrevistas sobre Kubernetes y llevar tu carrera al siguiente nivel.
Antes de entrar en las preguntas de la entrevista, echemos un vistazo rápido a los fundamentos de Kubernetes. Puedes saltarte esta sección si ya estás familiarizado con estos conceptos.
Kubernetes (K8s) es una plataforma de orquestación de contenedores de código abierto que automatiza el despliegue, escalado y gestión de aplicaciones en contenedores. Google lo desarrolló originalmente y más tarde lo donó a la Fundación de Computación Nativa en la Nube (CNCF).
Kubernetes se convirtió en el estándar del sector para gestionar aplicaciones basadas en microservicios en entornos de nube.
Aporta las siguientes características:
¿Pero por qué es esencial en primer lugar? Simplifica el despliegue y el funcionamiento de microservicios y contenedores automatizando tareas complejas como las actualizaciones continuas, el descubrimiento de servicios y la tolerancia a fallos. Kubernetes programa dinámicamente las cargas de trabajo en los recursos informáticos disponibles y abstrae estos principios conceptuales del usuario final.
Kubernetes consta de los siguientes componentes básicos:
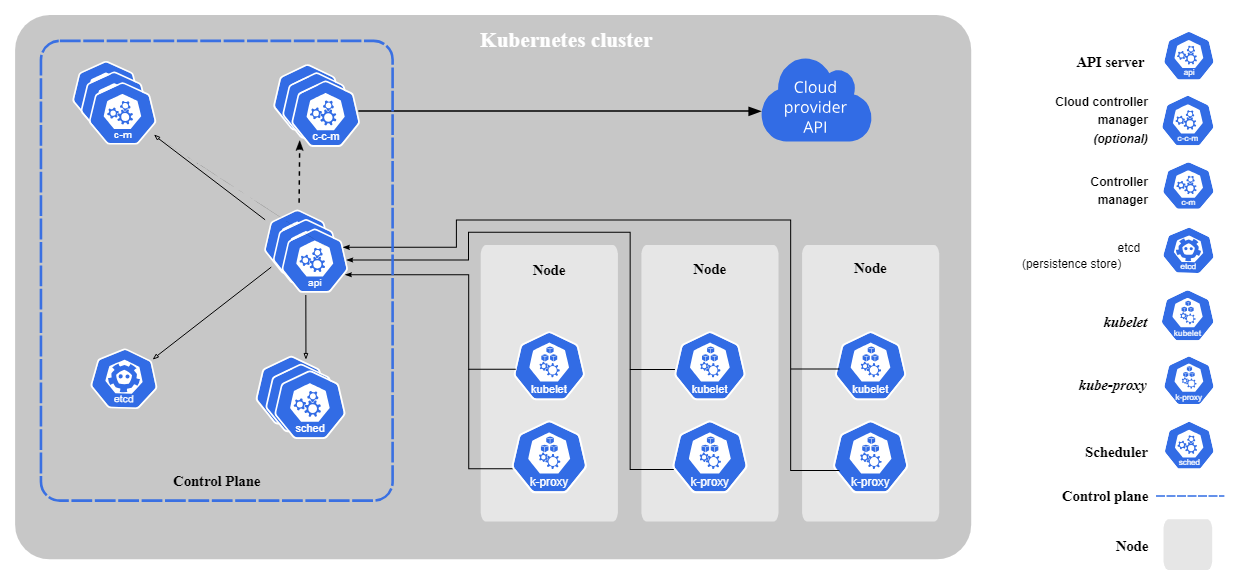
Componentes básicos de Kubernetes. Imagen de Kubernetes.io
Kubernetes sigue una arquitectura de maestro-trabajador. El plano de control (nodo maestro) gestiona las operaciones del clúster, mientras que los nodos trabajadores ejecutan aplicaciones en contenedores. Los pods, la unidad desplegable más pequeña de Kubernetes, ejecutan contenedores y se asignan a nodos.
Kubernetes garantiza el estado deseado supervisando y ajustando continuamente las cargas de trabajo según sea necesario.
¿Todavía no sabes cómo comparar Kubernetes y Docker? Echa un vistazo a este en profundidad Kubernetes vs. Kubernetes. Comparación de Docker para comprender sus funciones en los entornos de contenedores.
¡Aprende más sobre Docker y Kubernetes con estos cursos!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Josep Ferrer
15 min
blog
Zoumana Keita
12 min
blog
Abid Ali Awan
15 min
blog
Nisha Arya Ahmed
15 min
blog
Elena Kosourova
15 min

