
Cursus
Gegevensmodellering in Power BI
3 Hr
94.8K
Voordat we in de architectuur van Snowflake duiken, bekijken we eerst datawarehouses, zodat we allemaal op één lijn zitten.
Een datawarehouse is een centrale opslagplaats die grote hoeveelheden gestructureerde en georganiseerde data uit verschillende bronnen voor een bedrijf bewaart. Verschillende persona's (medewerkers) binnen organisaties gebruiken die data om uiteenlopende inzichten te verkrijgen.
Zo kunnen data-analisten, in samenwerking met het marketingteam, een A/B-test draaien voor een nieuwe marketingcampagne met behulp van de verkoopstabel. HR-specialisten kunnen personeelsinformatie bevragen om prestaties te volgen.
Dit zijn voorbeelden van hoe bedrijven wereldwijd datawarehouses inzetten om groei te versnellen. Maar zonder juiste implementatie en beheer met tools zoals Snowflake blijven datawarehouses slechts uitgewerkte concepten.
Je kunt meer over dit onderwerp leren met onze cursus Data Warehousing.
Snowflakes unieke architectuur, ontworpen voor snellere analytische queries, komt voort uit de scheiding van de opslag- en rekenlagen. Dit onderscheid draagt bij aan de voordelen die we eerder noemden.
In Snowflake is de opslaglaag een cruciaal onderdeel, waarin data efficiënt en schaalbaar wordt opgeslagen. Dit zijn enkele kernkenmerken van deze laag:
Laten we nu de rekenlaag bekijken.
Zoals de naam al aangeeft, is de rekenlaag de motor die je queries uitvoert. Deze werkt samen met de opslaglaag om de data te verwerken en verschillende rekenintensieve taken uit te voeren. Hieronder wat meer details over hoe deze laag werkt:
Deze ontwerpprincipes van de rekenlaag dragen allemaal bij aan Snowflakes vermogen om verschillende en veeleisende workloads in de cloud aan te kunnen.
De laatste laag is cloudservices. Omdat deze laag in elk onderdeel van Snowflakes architectuur is geïntegreerd, zijn er veel details over de werking. Naast features die samenhangen met andere lagen, heeft deze laag de volgende extra verantwoordelijkheden:
Nu we een globaal beeld hebben van de architectuur van Snowflake, gaan we wat SQL op het platform schrijven.
Snowflake heeft een eigen versie van SQL, genaamd Snowflake SQL. Het verschil met andere SQL-dialecten is vergelijkbaar met het verschil tussen Engelse accenten.
Veel analytische queries die je in dialecten als PostgreSQL uitvoert, veranderen niet, maar er zijn enkele verschillen in DDL-commando's (Data Definition Language).
Laten we nu eens kijken hoe je wat queries kunt uitvoeren!
Om te beginnen met Snowsight ga je naar de pagina voor de Snowflake-proefperiode van 120 dagen en maak je een account aan. Voer je persoonlijke gegevens in en kies een van de vermelde cloudproviders. Dit geeft je een proefperiode van 120 dagen in plaats van de meer gangbare 30 dagen die je elders ziet. De proef bevat ook $400 aan tegoed.
Bij het aanmelden voor een proef wordt aangeraden dat gebruikers AWS en de regio US-Oregon West kiezen. Oregon is onder meer een van de goedkoopste regio's voor AWS-infrastructuur en daardoor gaan proeftegoeden langer mee.
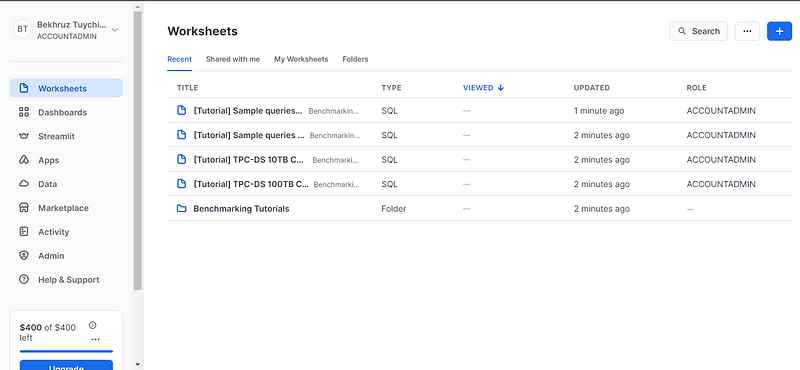
Na het verifiëren van je e-mailadres word je doorgestuurd naar de pagina Worksheets. Worksheets zijn interactieve live-codingomgevingen waar je de resultaten van je SQL-queries kunt schrijven, uitvoeren en bekijken.
Om wat queries te draaien, hebben we een database en een tabel nodig (we gebruiken de voorbeelddata in Snowsight niet). Om te beginnen stel ik voor dat je een nieuwe database maakt (je kunt die bijvoorbeeld test_db noemen) en een tabel aanmaakt met behulp van een lokaal CSV-bestand. Je kunt het CSV-bestand downloaden door de code in deze GitHub-gist in je terminal te draaien.
Daarna word je doorgestuurd naar een nieuw werkblad waar je elke gewenste SQL-query kunt uitvoeren. Ik vind de werkbladinterface behoorlijk overzichtelijk en zeer functioneel. Neem een paar minuten de tijd om de panelen, de knoppen en hun locaties te leren kennen.
Zo! We begonnen met eenvoudige concepten, maar naar het einde toe doken we echt de taaie details in. Nou, dat is mijn idee van een degelijke tutorial.
Je raadt het al: er is veel meer aan Snowflake dan we hier hebben behandeld. Sterker nog, de Snowflake-documentatie bevat quickstarts die eigenlijk 128 minuten duren! Maar voordat je daaraan begint, raad ik aan om eerst wat praktijkervaring op te doen met andere bronnen. Wat dacht je van deze:
Bedankt voor het lezen!
Begin vandaag nog aan je database-reis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
