
Curso
Manipulação de dados em SQL
4 h
324.5K
Em bancos de dados relacionais, os dados geralmente ficam espalhados por várias tabelas, cada uma guardando uma parte específica de um sistema maior. Essa separação é uma boa escolha de design, mas traz um desafio, pois os dados podem rapidamente se tornar difíceis de interpretar.
Para resolver esse desafio, os bancos de dados relacionais usam regras que garantem as relações entre as tabelas. Um dos mecanismos mais importantes para manter essa estrutura e confiabilidade é o uso de chaves estrangeiras, que são usadas para garantir que os dados relacionados fiquem alinhados.
Neste tutorial, vou explicar como as chaves estrangeiras funcionam. Se você está começando como engenheiro de banco de dados, recomendo fazer nossos cursos Introdução a Bancos de Dados Relacionais em SQL e Design de Bancos de Dados para aprender a criar relações ao definir o esquema do seu banco de dados.
Tanto a chave primária, sobre a qual temos outro artigo, quanto a chave estrangeira ajudam a manter a estrutura e a integridade de um banco de dados relacional. Deixa eu explicar os dois:
Uma chave estrangeira é um campo ou conjunto de campos em uma tabela que se refere à chave primária em outra tabela. Essa chave estrangeira cria uma ligação entre tabelas para garantir que os dados na tabela de referência correspondam às entradas válidas na tabela referenciada.
Vamos supor que você tem um banco de dados com uma tabela users e uma tabela orders. A tabela ` orders ` pode ter uma coluna ` user_id `, que precisa combinar com um ` user_id ` que já existe na tabela ` users `. A restrição de chave estrangeira garante que você não possa criar um pedido vinculado a um usuário que não existe.
Entender as chaves estrangeiras também exige entender as chaves primárias, já que as chaves estrangeiras dependem das chaves primárias para criar e manter essas relações.
Uma chave primária é uma coluna ou combinação de colunas que identifica de forma única cada registro em uma tabela. Nenhuma linha pode ter o mesmo valor de chave primária, e ela nunca pode ser um NULL. Então, uma tabela precisa ter uma chave primária, que é o identificador único que faz referência a todas as chaves estrangeiras em outras tabelas.
Por exemplo, a consulta abaixo cria a tabela users, com a coluna user_id como chave primária:
-- Create users table with user_id as primary key
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
);Resumi as diferenças entre as chaves primárias e estrangeiras na tabela abaixo:
|
Aspecto |
Chave primária |
Chave estrangeira |
|
Objetivo |
Identifica de forma única cada registro dentro de uma tabela |
Cria uma relação referenciando uma chave primária em outra tabela. |
|
Exclusividade |
Tem que ser único |
Pode ter valores duplicados |
|
Valores NULL |
Não pode ser NULL |
Pode ser NULL (a menos que restrito) |
|
Localização |
Definido na mesma tabela |
Faz referência à chave primária de outra tabela |
Pela explicação acima, vemos que as chaves primárias e estrangeiras são importantes para criar bancos de dados estruturados e confiáveis. Eles trabalham juntos para garantir que os dados sejam consistentes, as relações sejam mantidas e a integridade do banco de dados seja preservada.
Agora que você já entendeu o que são chaves estrangeiras e por que elas são importantes nos bancos de dados, vamos aprender como definir, gerenciar e controlar o comportamento delas ao projetar seu banco de dados.
Você pode configurar uma chave estrangeira no SQL de duas maneiras: quando criar a tabela ou adicioná-la posteriormente, se a tabela já existir.
O exemplo abaixo mostra a primeira opção de como definir uma chave estrangeira ao criar uma tabela no SQL Server.
-- Create parent table: users
CREATE TABLE users (
user_id INT IDENTITY(1,1) PRIMARY KEY,
username NVARCHAR(100),
email NVARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id INT IDENTITY(1,1) PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);A sintaxe é a mesma para o PostgreSQL, embora usemos SERIAL para autoincrementos para a chave primária.
-- Create parent table: users
CREATE TABLE users (
user_id SERIAL PRIMARY KEY, -- SERIAL auto-increments
username VARCHAR(100),
email VARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);Ao configurar uma chave estrangeira no MySQL, você precisa usar InnoDB, como mostrado abaixo.
-- Create parent table: users
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
) ENGINE=InnoDB; -- Must use InnoDB for FK support
-- Create child table: orders
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
) ENGINE=InnoDB;Se você estiver usando um banco de dados Oracle, pode definir a chave estrangeira, mas certifique-se de que os tipos de dados correspondam exatamente para ambas as tabelas.
-- Create parent table: users
CREATE TABLE users (
user_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
username VARCHAR2(100),
email VARCHAR2(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
user_id NUMBER,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);Para adicionar uma chave estrangeira a uma tabela já existente, use a seguinte consulta:
-- Assuming orders table already exists
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id);Recomendo fazer nossos cursos Introdução ao SQL Server e Criação de bancos de dados PostgreSQL para aprender mais sobre as diferenças entre os dialetos SQL na hora de criar bancos de dados.
Chaves estrangeiras são um tipo de restrição, uma regra aplicada pelo sistema de gerenciamento de banco de dados (DBMS) para validar dados durante operações como inserções, atualizações e exclusões. Quando uma restrição de chave estrangeira está ativa, o banco de dados garante que qualquer valor inserido na coluna da chave estrangeira já exista na coluna da chave primária referenciada.
Uma prática comum é nomear restrições seguindo o padrão fk__. Nos nossos exemplos, a chave estrangeira passa a ser fk_orders_users. Se você nomear suas chaves estrangeiras dessa forma, isso tornará os esquemas legíveis, ajudará na depuração de violações de restrições e funcionará bem com ferramentas de migração. A validação de restrições funciona se você fizer o seguinte:
INSERT: Rejeita uma linha se o valor pai referenciado não existir.
UPDATE: Impede modificações que poderiam quebrar as relações.
DELETE: Bloqueia as operações de exclusão quando existem linhas filhas dependentes.
A integridade referencial é o princípio básico que a restrição de chave estrangeira faz valer. As chaves estrangeiras ajudam a garantir isso, evitando registros órfãos, que acontecem quando as linhas em uma tabela filha apontam para linhas que não existem na tabela pai.
O SQL também permite configurar ações em cascata. São instruções automáticas que dizem ao sistema de gerenciamento de banco de dados (DBMS) exatamente como lidar com as alterações feitas no registro que está sendo consultado. Por exemplo, você pode usar essas operações em cascata para fazer coisas como:
|
Ação |
Comportamento |
|
|
Apaga as linhas secundárias quando a linha principal for apagada. |
|
|
Atualize a chave secundária quando a chave principal mudar. |
|
|
A chave estrangeira secundária passa a ser |
|
|
A criança recebe o valor padrão |
|
|
Evite mudanças que prejudiquem os relacionamentos |
Por exemplo, a consulta a seguir adiciona as operações em cascata para excluir um registro de usuário se ele remover seu pedido e atualiza automaticamente se seu user_id mudar.
-- Adds cascading rules to enforce hierarchical cleanup
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id)
ON DELETE CASCADE -- deleting a user deletes their orders
ON UPDATE CASCADE; -- if user_id changes, update automaticallyChaves estrangeiras são os blocos de construção usados na modelagem de dados que definem as relações entre tabelas em um banco de dados. Nesta seção, vamos ver os diferentes métodos pelos quais as chaves estrangeiras garantem a consistência dos dados ao conectar tabelas.
Em uma relação um-para-muitos (1:N), uma linha em uma tabela pai pode ser ligada a muitos registros em uma tabela filho. Essa relação é reforçada colocando a chave primária da tabela pai, como users.user_id, como uma chave estrangeira na tabela filho, como orders.customer_id.
Por exemplo, um usuário pode ter muitos pedidos, ou um departamento pode ter muitos funcionários.
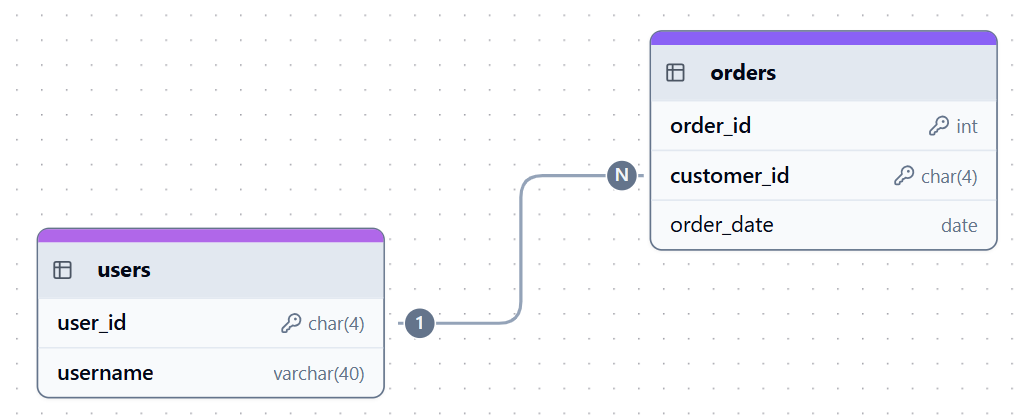
Exemplo de relação um-para-muitos. Imagem do autor.
Por outro lado, uma relação muitos-para-muitos (M:N) rola quando vários registros em uma tabela podem estar ligados a vários registros em outra tabela. Como não dá pra implementar diretamente uma relação muitos-para-muitos em um banco de dados normalizado, a gente usa uma tabela de junção (tabela ponte) com duas chaves estrangeiras.
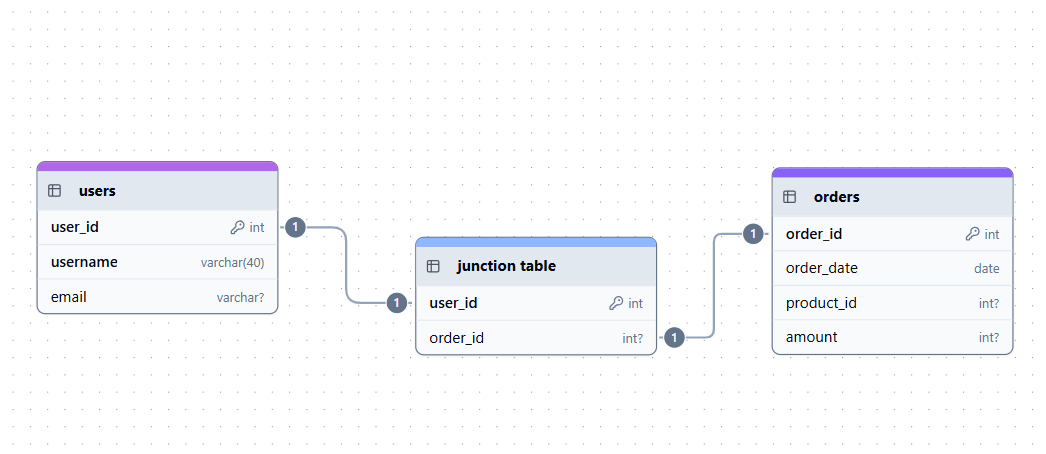
Exemplo de relação muitos-para-muitos. Imagem do autor.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Summer Worsley
13 min
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Kevin Babitz
Tutorial
Oluseye Jeremiah


