
Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
In relationalen Datenbanken sind die Daten normalerweise auf mehrere Tabellen verteilt, wobei jede einen bestimmten Teil eines größeren Systems speichert. Diese Trennung ist eine gute Designentscheidung, bringt aber die Herausforderung mit sich, dass Daten schnell schwer zu interpretieren sein können.
Um dieses Problem zu lösen, nutzen relationale Datenbanken Regeln, die die Beziehungen zwischen Tabellen sicherstellen. Einer der wichtigsten Mechanismen, um diese Struktur und Zuverlässigkeit zu halten, ist die Verwendung von Fremdschlüsseln, die dafür sorgen, dass zusammengehörige Daten aufeinander abgestimmt bleiben.
In diesem Tutorial erkläre ich dir, wie Fremdschlüssel funktionieren. Wenn du als Datenbankingenieur anfängst, empfehle ich dir, unsere Kurse „Einführung in relationale Datenbanken in SQL“ und „Datenbankdesign“ zu besuchen, um zu lernen, wie du beim Definieren deines Datenbankschemas Beziehungen erstellst.
Sowohl der Primärschlüssel, über den wir einen anderen Artikel haben, als auch der Fremdschlüssel helfen dabei, die Struktur und Integrität einer relationalen Datenbank zu halten. Ich erkläre dir beides:
Ein Fremdschlüssel ist ein Feld oder eine Gruppe von Feldern in einer Tabelle, die auf den Primärschlüssel in einer anderen Tabelle verweisen. Dieser Fremdschlüssel verbindet Tabellen miteinander, damit die Daten in der referenzierenden Tabelle mit den gültigen Einträgen in der referenzierten Tabelle übereinstimmen.
Nehmen wir mal an, du hast eine Datenbank mit einer Tabelle „ users ” und einer Tabelle „ orders ”. Die Tabelle „ orders “ kann eine Spalte „ user_id “ haben, die mit einem vorhandenen „ user_id “ in der Tabelle „ users “ übereinstimmen muss. Die Fremdschlüsselbeschränkung sorgt dafür, dass du keine Bestellung für einen nicht existierenden Benutzer anlegen kannst.
Um Fremdschlüssel zu verstehen, muss man auch Primärschlüssel verstehen, weil Fremdschlüssel auf Primärschlüssel angewiesen sind, um diese Beziehungen aufzubauen und zu pflegen.
Ein Primärschlüssel ist eine Spalte oder eine Kombination von Spalten, die jeden Datensatz in einer Tabelle eindeutig identifiziert. Keine zwei Zeilen dürfen denselben Primärschlüsselwert haben, und dieser darf niemals „ NULL “ sein. Deshalb muss eine Tabelle einen Primärschlüssel haben, der die eindeutige Kennung ist, die auf alle Fremdschlüssel in anderen Tabellen verweist.
Die folgende Abfrage erstellt zum Beispiel die Tabelle „ users “ mit der Spalte „ user_id “ als Primärschlüssel:
-- Create users table with user_id as primary key
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
);Ich hab die Unterschiede zwischen Primär- und Fremdschlüsseln in der Tabelle unten zusammengefasst:
|
Aspekt |
Primärschlüssel |
Fremdschlüssel |
|
Zweck |
Identifiziert jeden Datensatz in einer Tabelle eindeutig |
Erstellt eine Beziehung, indem auf einen Primärschlüssel in einer anderen Tabelle verwiesen wird. |
|
Einzigartigkeit |
Muss einzigartig sein |
Kann doppelte Werte haben |
|
NULL-Werte |
Darf nicht NULL sein |
Kann NULL sein (es sei denn, es gibt Einschränkungen) |
|
Ort |
In derselben Tabelle definiert |
Verweist auf den Primärschlüssel einer anderen Tabelle |
Aus der obigen Erklärung geht hervor, dass Primär- und Fremdschlüssel wichtig sind, um strukturierte und zuverlässige Datenbanken zu erstellen. Sie arbeiten zusammen, um sicherzustellen, dass die Daten konsistent sind, Beziehungen gepflegt werden und die Integrität der Datenbank erhalten bleibt.
Jetzt, wo du weißt, was Fremdschlüssel sind und warum sie in Datenbanken wichtig sind, schauen wir uns an, wie du sie beim Entwerfen deiner Datenbank definieren, verwalten und steuern kannst.
Du kannst einen Fremdschlüssel in SQL auf zwei Arten einrichten: entweder beim Erstellen der Tabelle oder nachträglich, wenn die Tabelle schon da ist.
Das folgende Beispiel zeigt die erste Möglichkeit, wie man einen Fremdschlüssel beim Erstellen einer Tabelle in SQL Server definiert.
-- Create parent table: users
CREATE TABLE users (
user_id INT IDENTITY(1,1) PRIMARY KEY,
username NVARCHAR(100),
email NVARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id INT IDENTITY(1,1) PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);Die Syntax ist die gleiche wie bei PostgreSQL, aber wir benutzen „ SERIAL ” für die automatische Inkrementierung des Primärschlüssels.
-- Create parent table: users
CREATE TABLE users (
user_id SERIAL PRIMARY KEY, -- SERIAL auto-increments
username VARCHAR(100),
email VARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);Wenn du in MySQL einen Fremdschlüssel einrichtest, musst du „ InnoDB “ wie unten gezeigt verwenden.
-- Create parent table: users
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
) ENGINE=InnoDB; -- Must use InnoDB for FK support
-- Create child table: orders
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
) ENGINE=InnoDB;Wenn du eine Oracle-Datenbank benutzt, kannst du den Fremdschlüssel festlegen, aber pass auf, dass die Datentypen für beide Tabellen genau übereinstimmen.
-- Create parent table: users
CREATE TABLE users (
user_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
username VARCHAR2(100),
email VARCHAR2(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
user_id NUMBER,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);Um einer bestehenden Tabelle einen Fremdschlüssel hinzuzufügen, benutze die folgende Abfrage:
-- Assuming orders table already exists
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id);Ich empfehle dir, unsere Kurse „Einführung in SQL Server“ und „Erstellen von PostgreSQL-Datenbanken“ zu machen, um mehr über die Unterschiede zwischen den SQL-Dialekten beim Erstellen von Datenbanken zu erfahren.
Fremdschlüssel sind eine Art von Einschränkung, eine Regel, die vom Datenbankmanagementsystem (DBMS) durchgesetzt wird, um Daten bei Vorgängen wie Einfügen, Aktualisieren und Löschen zu überprüfen. Wenn eine Fremdschlüsselbeschränkung aktiv ist, stellt die Datenbank sicher, dass jeder Wert, der in die Fremdschlüsselspalte eingegeben wird, schon in der referenzierten Primärschlüsselspalte vorhanden sein muss.
Es ist üblich, Einschränkungen nach dem Muster „ fk__ “ zu benennen. In unseren Beispielen wird der Fremdschlüssel zu „ fk_orders_users “. Wenn du deine Fremdschlüssel so benennst, macht das Schemata lesbarer, hilft beim Debuggen von Constraint-Verletzungen und funktioniert gut mit Migrationswerkzeugen. Die Validierung der Einschränkungen klappt, wenn du die folgenden Schritte machst:
INSERT: Lehnt eine Zeile ab, wenn der referenzierte übergeordnete Wert nicht da ist.
UPDATE: Verhindert Änderungen, die Beziehungen kaputt machen würden.
DELETE: Blöcke löschen Vorgänge, wenn abhängige untergeordnete Zeilen vorhanden sind.
Referenzielle Integrität ist das Hauptprinzip, das durch die Fremdschlüsselbeschränkung sichergestellt wird. Fremdschlüssel helfen dabei, indem sie verwaiste Datensätze verhindern, die entstehen, wenn Zeilen in einer untergeordneten Tabelle auf nicht vorhandene Zeilen in einer übergeordneten Tabelle verweisen.
Mit SQL kannst du auch kaskadierende Aktionen einrichten. Das sind automatische Anweisungen, die dem Datenbankmanagementsystem (DBMS) genau sagen, wie es mit Änderungen an dem Datensatz, auf den verwiesen wird, umgehen soll. Du kannst diese kaskadierenden Operationen zum Beispiel für folgende Aufgaben nutzen:
|
Aktion |
Verhalten |
|
|
Untergeordnete Zeilen löschen, wenn die übergeordnete Zeile gelöscht wird |
|
|
Aktualisiere den untergeordneten Schlüssel, wenn sich der übergeordnete Schlüssel ändert. |
|
|
Der Fremdschlüssel des Kindes wird zu |
|
|
Das Kind bekommt den Standardwert. |
|
|
Verhindere Änderungen, die Beziehungen kaputt machen |
Die folgende Abfrage fügt zum Beispiel die kaskadierenden Operationen hinzu, um einen Benutzerdatensatz zu löschen, wenn er seine Bestellung storniert, und aktualisiert ihn automatisch, wenn sich seine E-Mail-Adresse user_id ändert.
-- Adds cascading rules to enforce hierarchical cleanup
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id)
ON DELETE CASCADE -- deleting a user deletes their orders
ON UPDATE CASCADE; -- if user_id changes, update automaticallyFremdschlüssel sind die Bausteine, die man beim Datenmodellieren benutzt, um die Beziehungen zwischen Tabellen in einer Datenbank zu definieren. In diesem Abschnitt schauen wir uns die verschiedenen Methoden an, mit denen Fremdschlüssel die Datenkonsistenz beim Verknüpfen von Tabellen sicherstellen.
In einer Eins-zu-Viele-Beziehung (1:N) kann eine Zeile in einer übergeordneten Tabelle mit mehreren Datensätzen in einer untergeordneten Tabelle verbunden sein. Diese Beziehung wird hergestellt, indem der Primärschlüssel der übergeordneten Tabelle, z. B. „ users.user_id “, als Fremdschlüssel in der untergeordneten Tabelle, z. B. „ orders.customer_id “, eingefügt wird.
Zum Beispiel kann ein Nutzer mehrere Bestellungen haben oder eine Abteilung mehrere Mitarbeiter.
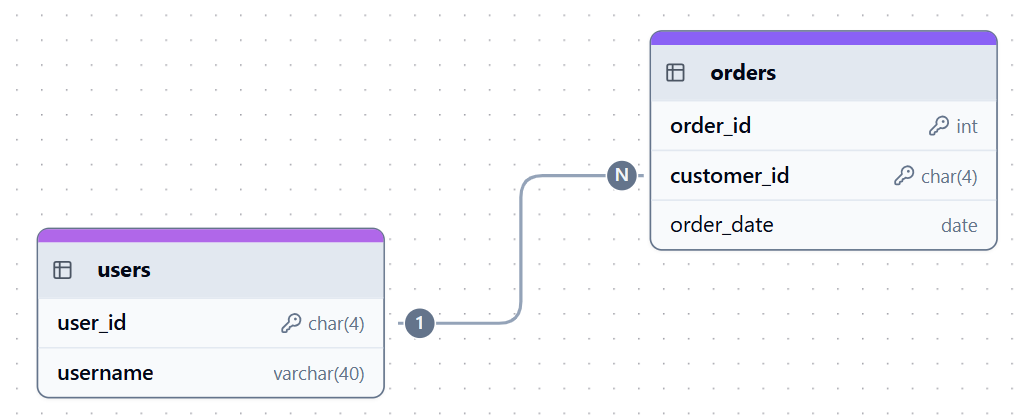
Beispiel für eine Eins-zu-Viele-Beziehung. Bild vom Autor.
Andererseits haben wir eine Viele-zu-Viele-Beziehung (M:N), wenn mehrere Datensätze in einer Tabelle mit mehreren Datensätzen in einer anderen Tabelle verbunden werden können. Da man eine Viele-zu-Viele-Beziehung in einer normalisierten Datenbank nicht direkt umsetzen kann, benutzen wir eine Verknüpfungstabelle (Brückentabelle), die zwei Fremdschlüssel enthält.
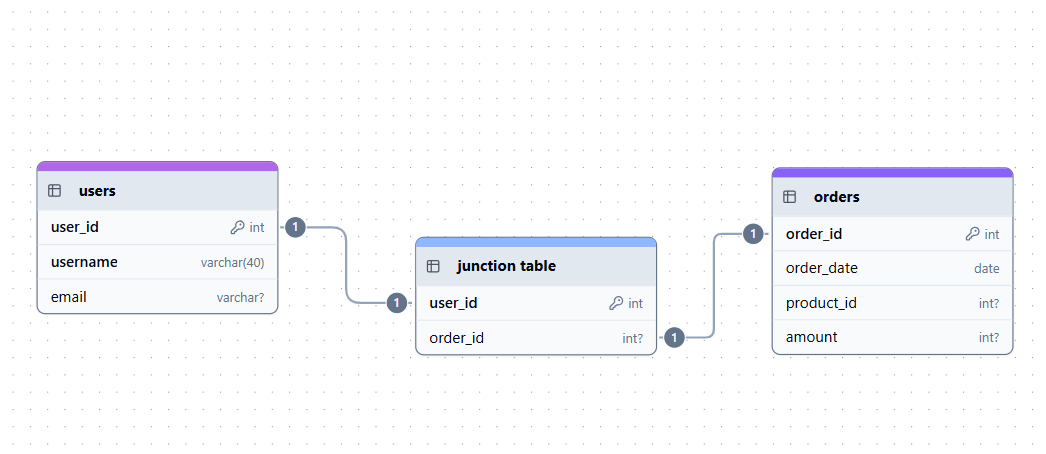
Beispiel für eine Viele-zu-Viele-Beziehung. Bild vom Autor.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
Javier Canales Luna
Tutorial
Sejal Jaiswal


