Course
Data Manipulation in SQL
4 hr
324.1K
In relational databases, data is usually spread across multiple tables, each storing a specific aspect of a larger system. This separation is a good design choice, but it does introduce a challenge in that data can quickly become difficult to interpret.
To address this challenge, relational databases rely on rules that enforce relationships between tables. One of the most important mechanisms for maintaining this structure and reliability is the use of foreign keys, which are used to make sure that related data stays aligned.
In this tutorial, I will explain how foreign keys work. If you are starting as a database engineer, I recommend taking our Introduction to Relational Databases in SQL and Database Design courses to learn how to create relationships when defining your database schema.
Both the primary key, which we have another article on, and the foreign key help maintain the structure and integrity of a relational database. Let me explain both:
A foreign key is a field or set of fields in one table that refers to the primary key in another table. This foreign key creates a link between tables to ensure that the data in the referencing table matches valid entries in the referenced table.
Let’s assume you have a database with a users table and an orders table. The orders table might include a user_id column, which must match an existing user_id in the users table. The foreign key constraint ensures you can’t create an order tied to a non-existent user.
Understanding foreign keys also requires understanding primary keys, as foreign keys depend on primary keys to establish and maintain these relationships.
A primary key is a column or combination of columns that uniquely identifies each record in a table. No two rows can share the same primary key value, and it can never be NULL. Therefore, a table must have one primary key which is the unique identifier that references all the foreign keys in other tables.
For example, the query below creates the users table, with the user_id column as the primary key:
-- Create users table with user_id as primary key
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
);I have summarized the differences between the primary and foreign keys in the table below:
|
Aspect |
Primary Key |
Foreign Key |
|
Purpose |
Uniquely identifies each record within a table |
Creates a relationship by referencing a primary key in another table |
|
Uniqueness |
Must be unique |
Can contain duplicate values |
|
NULL Values |
Cannot be NULL |
Can be NULL (unless restricted) |
|
Location |
Defined in the same table |
References another table’s primary key |
From the above explanation, we see that primary and foreign keys are important for creating structured and reliable databases. They work together to ensure that data is consistent, relationships are maintained, and the integrity of the database is preserved.
Now that you have understood what foreign keys are and why they are important in databases, let’s learn how to define, manage, and control their behavior when designing your database.
You can set up a foreign key in SQL in two ways; when you create the table or you can add it afterwards if the table already exists.
The example below shows the first option of how to define a foreign key when creating a table in SQL Server.
-- Create parent table: users
CREATE TABLE users (
user_id INT IDENTITY(1,1) PRIMARY KEY,
username NVARCHAR(100),
email NVARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id INT IDENTITY(1,1) PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);The syntax is the same for PostgreSQL, although we use SERIAL for auto-increments for the primary key.
-- Create parent table: users
CREATE TABLE users (
user_id SERIAL PRIMARY KEY, -- SERIAL auto-increments
username VARCHAR(100),
email VARCHAR(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);When setting up a foreign key in MySQL, you must use InnoDB as shown below.
-- Create parent table: users
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(100),
email VARCHAR(255)
) ENGINE=InnoDB; -- Must use InnoDB for FK support
-- Create child table: orders
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
) ENGINE=InnoDB;If you are using an Oracle database, you can define the foreign key, but ensure the data types match exactly for both tables.
-- Create parent table: users
CREATE TABLE users (
user_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
username VARCHAR2(100),
email VARCHAR2(255)
);
-- Create child table: orders
CREATE TABLE orders (
order_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
user_id NUMBER,
order_date DATE,
CONSTRAINT fk_orders_users FOREIGN KEY (user_id)
REFERENCES users(user_id)
);To add a foreign key to an existing table, use the following query:
-- Assuming orders table already exists
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id);I recommend taking our Introduction to SQL Server and Creating PostgreSQL Databases courses to learn more about the differences in the SQL dialects when creating databases.
Foreign keys are a type of constraint, a rule enforced by the database management system (DBMS) to validate data during operations like inserts, updates, and deletes. When a foreign key constraint is active, the database ensures that any value entered in the foreign key column must already exist in the referenced primary key column.
A common practice is to name constraints following the pattern fk_<child>_<parent>. From our examples, the foreign key becomes fk_orders_users. If you name your foreign keys this way, it makes schemas readable, helps with debugging constraint violations, and works well with migration tools. The constraint validation works if you perform the following operations:
INSERT: Rejects a row if the referenced parent value doesn’t exist
UPDATE: Prevents modification that would break relationships.
DELETE: Blocks delete operations when dependent child rows exist.
Referential integrity is the core principle enforced by the foreign key constraint. Foreign keys help enforce this by preventing orphaned records, which occur when rows in a child table point to non-existent rows in a parent table.
SQL also lets you set up cascading actions. These are automatic instructions that tell the database management system (DBMS) exactly how to handle changes made to the record being referenced. For example, you can use these cascading operations to do things like:
|
Action |
Behavior |
|
|
Delete child rows when the parent row is deleted |
|
|
Update the child key when the parent key changes |
|
|
Child foreign key becomes |
|
|
Child receives default value |
|
|
Prevent changes that break relationships |
For example, the following query adds the cascading operations to delete a user record if they remove their order, and updates automatically if their user_id changes.
-- Adds cascading rules to enforce hierarchical cleanup
ALTER TABLE orders
ADD CONSTRAINT fk_orders_users
FOREIGN KEY (user_id)
REFERENCES users(user_id)
ON DELETE CASCADE -- deleting a user deletes their orders
ON UPDATE CASCADE; -- if user_id changes, update automaticallyForeign keys are the building blocks used in data modeling that define the relationships between tables in a database. In this section, we will look at the different methods by which foreign keys ensure data consistency when linking tables.
In a one-to-many (1:N) relationship, one row in a parent table can be linked to many records in a child table. This relationship is enforced by placing the primary key of the parent table, such as users.user_id, as a foreign key in the child table, like orders.customer_id.
For example, one user can have many orders, or one department can have many employees.
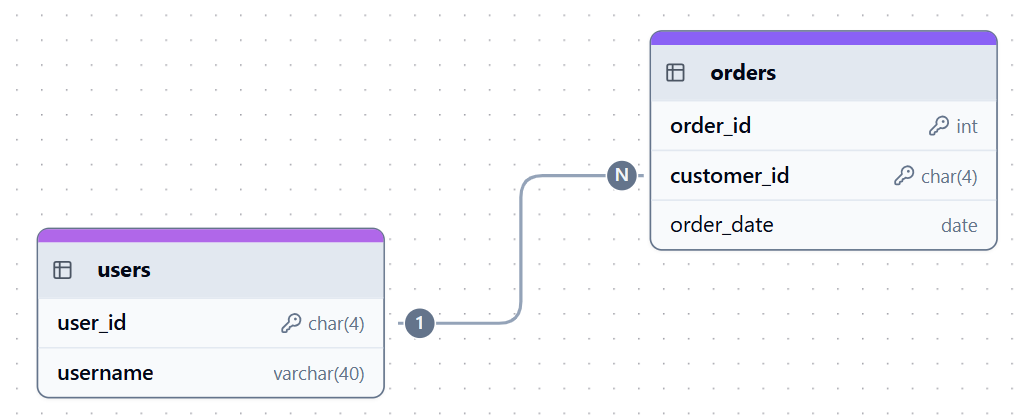
One-to-many relationship example. Image by Author.
On the other hand, a many-to-many (M:N) relationship occurs when multiple records in one table can be related to multiple records in another. Since you cannot directly implement a many-to-many relationship in a normalized database, we use a junction table (bridge table) containing two foreign keys.
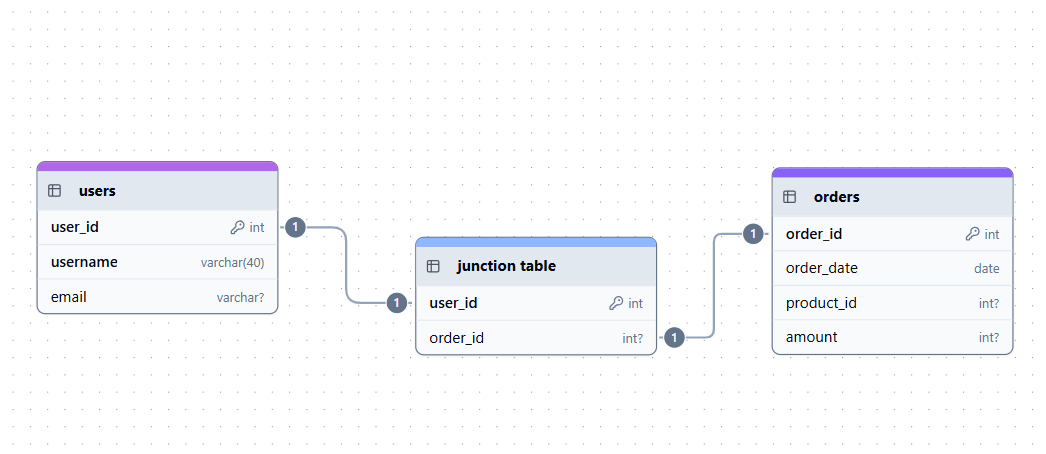
Many-to-many relationship example. Image by Author.
Learn with DataCamp
Course
Course
Course
Tutorial
Austin Chia
Tutorial
DataCamp Team
Tutorial
François Aubry
Tutorial
Allan Ouko
Tutorial
Allan Ouko
code-along
Kelsey McNeillie