Curso
Introdução ao Python
4 h
6.9M
O algoritmo de correspondência de strings fuzzy procura determinar o grau de proximidade entre duas strings diferentes. Isso é descoberto usando uma métrica de distância conhecida como "distância de edição". A distância de edição determina a proximidade entre duas cadeias de caracteres, encontrando o número mínimo de "edições" necessárias para transformar uma cadeia de caracteres em outra.
Se a distância de edição contar o número de operações de edição para nos informar quantas operações separam uma string de outra, uma edição é uma operação realizada em uma string para transformá-la em outra string.
Há quatro tipos principais de edições:
| Editar operação | Descrição | Exemplo |
|---|---|---|
| Inserir | Adicionar uma carta | "Londn" -> "Londres" |
| Excluir | Remover uma letra | "Londoon" -> "Londres" |
| Interruptor | Trocar duas letras adjacentes | "Lnodon" -> "Londres" |
| Substituir | Trocar uma letra por outra | "Londin" -> "London" (Londres) |
Essas quatro operações de edição permitem que você modifique qualquer string.
A combinação das operações de edição permite que você descubra a lista de possíveis cadeias de caracteres que estão a N edições de distância, em que N é o número de operações de edição. Por exemplo, a distância de edição entre "London" e "Londin" é um, pois a substituição do "i" por um "o" leva a uma correspondência exata.
Mas como especificamente a distância de edição é calculada, você pergunta?
Há diferentes variações de como calcular a distância de edição. Por exemplo, há a distância Levenshtein, a distância Hamming, a distância Jaro, entre outras.
Neste tutorial, estamos preocupados apenas com a distância de Levenshtein.
É uma métrica que leva o nome de Vladimir Levenshtein, que a considerou originalmente em 1965 para medir a diferença entre duas sequências de palavras. Podemos usá-lo para descobrir o número mínimo de edições que você precisa fazer para transformar uma sequência de uma palavra em outra.
Aqui está o cálculo formal:
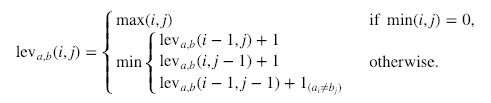
Em que 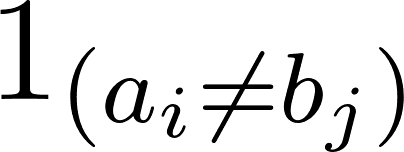 1ab denota 0 quando a=b e 1 caso contrário.
1ab denota 0 quando a=b e 1 caso contrário.
É importante observar que as linhas no mínimo acima correspondem a uma exclusão, uma inserção e uma substituição, nessa ordem.
Também é possível calcular a taxa de similaridade de Levenshtein com base na distância de Levenshtein. Isso pode ser feito usando a seguinte fórmula:
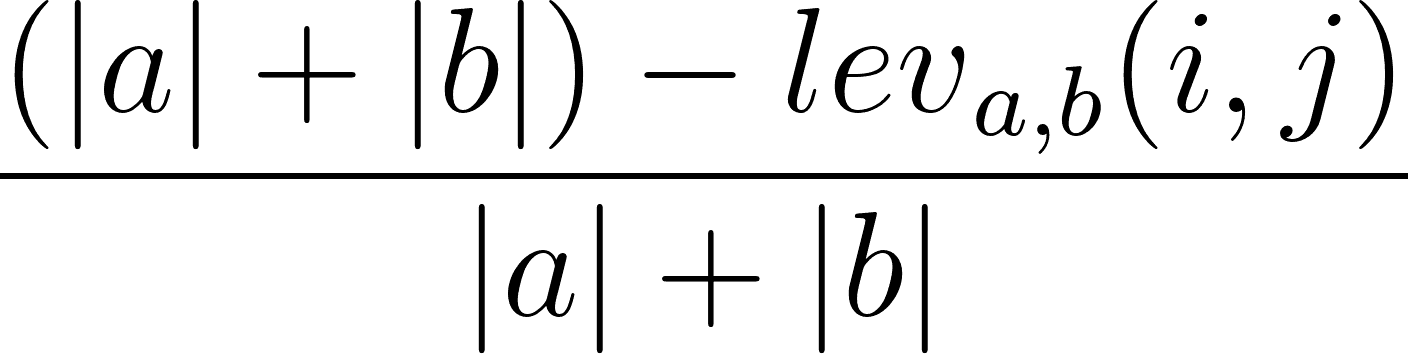
onde |a| e |b| são os comprimentos da sequência a e da sequência b, respectivamente.
Um dos pacotes mais populares para correspondência de strings fuzzy em Python foi o FuzzyWuzzy. No entanto, o FuzzyWuzzy foi atualizado e renomeado em 2021. Agora você usa o nome TheFuzz.
TheFuzz ainda é uma das bibliotecas de código aberto mais avançadas para correspondência de strings fuzzy em Python. Ele foi desenvolvido pela SeatGeek com o objetivo de distinguir se duas listagens de ingressos com nomes semelhantes eram para o mesmo evento.
De acordo com o FuzzyWuzzy, o TheFuzz usa a distância de edição Levenshtein para calcular o grau de proximidade entre duas cadeias de caracteres. Ele também oferece recursos para determinar a similaridade de strings em várias situações, como você verá neste tutorial.
Primeiro, precisamos instalar o pacotefuzz. Você pode fazer isso com o pip usando o seguinte comando:
!pip install thefuzzObservação: Essa biblioteca vem pré-instalada na pasta de trabalho do DataLab.
Agora, vamos dar uma olhada em algumas das coisas que podemos fazer com o thefuzz.
Acompanhe o código nesta pasta de trabalho do DataLab.
Podemos determinar a proporção simples entre duas cadeias de caracteres usando o método ratio() no objeto fuzz. Isso simplesmente calcula a distância de edição com base na ordenação das duas cadeias de caracteres de entrada difflib.ratio() - consulte a documentação do difflib para saber mais.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""No código, usamos duas variações do meu nome para comparar a pontuação de similaridade, que foi dada como 86.
Vamos verificar isso em relação à proporção parcial.
Para verificar a proporção parcial, tudo o que precisamos fazer no código acima é chamar partial_ratio() em nosso objeto fuzz em vez de ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Vemos uma diminuição. O que está acontecendo?
Bem, o partial_ratio() procura descobrir quão parcialmente semelhantes são duas cordas. Duas cadeias de caracteres são parcialmente semelhantes se tiverem algumas das palavras em uma ordem comum.
O site partial_ratio() calcula a similaridade pegando a string mais curta, que, nesse cenário, é armazenada na variável name e, em seguida, compara-a com as substrings do mesmo comprimento na string mais longa, que é armazenada em full_name.
Como a ordem é importante na proporção parcial, nossa pontuação caiu nesse caso. Portanto, para obter uma correspondência de 100% de similaridade, você teria que mover a parte "K D" (que significa meu nome do meio) para o final da cadeia. Por exemplo:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""E se quisermos que nosso combinador de strings fuzzy ignore a ordem?
Nesse caso, você pode querer usar a "taxa de classificação de token".
Então, queremos ignorar a ordem das palavras nas cadeias de caracteres, mas ainda assim determinar a semelhança entre elas - a classificação por token ajuda você a fazer exatamente isso. A classificação de tokens não se importa com a ordem em que as palavras ocorrem. Ele considera cadeias de caracteres semelhantes que não estão em ordem, conforme expresso acima.
Portanto, devemos obter uma pontuação de 100% usando a taxa de classificação de tokens com o exemplo mais recente:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""... e, como esperado, conseguimos.
Vamos voltar às variáveis originais name e full_name. O que você acha que acontecerá se usarmos o token sort agora?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""A pontuação cai.
Isso ocorre porque a classificação de tokens desconsidera apenas a ordem. Se houver palavras diferentes nas cadeias de caracteres, isso afetará negativamente a taxa de similaridade, como vimos acima.
Mas há uma solução alternativa.
O método token_set_ratio() é bastante semelhante ao token_sort_ratio(), exceto pelo fato de que ele retira os tokens comuns antes de calcular a semelhança entre as cadeias de caracteres: isso é extremamente útil quando as cadeias de caracteres têm comprimentos significativamente diferentes.
Como as variáveis name e full_name contêm "Kurtis Pykes", podemos esperar que a similaridade da proporção do conjunto de tokens seja de 100%.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""O módulo de processo permite que os usuários extraiam o texto de uma coleção usando a correspondência de strings difusa. A chamada do método extract() no módulo de processo retorna as cadeias de caracteres com uma pontuação de similaridade em um vetor. Por exemplo:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Podemos controlar o comprimento do vetor retornado pelo método extract() definindo o parâmetro limit como o comprimento desejado.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""Nesse caso, a função extract() retorna as três cadeias de caracteres correspondentes mais próximas com base no avaliador que definimos.
Na tabela abaixo, você pode ver uma comparação rápida dos diferentes tipos de técnicas disponíveis no TheFuzz:
| Técnica | Descrição | Exemplo de código |
|---|---|---|
| Proporção simples | Calcula a similaridade considerando a ordem das cadeias de caracteres de entrada. | fuzz.ratio(name, full_name) |
| Proporção parcial | Encontra similaridade parcial comparando a string mais curta com as substrings. | fuzz.partial_ratio(name, full_name) |
| Taxa de classificação de token | Ignora a ordem das palavras nas cadeias de caracteres. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Taxa de conjunto de tokens | Remove tokens comuns antes de calcular a similaridade. | fuzz.token_set_ratio(name, full_name) |
Nesta seção, veremos como fazer a correspondência fuzzy de strings em um dataframe do pandas.
Digamos que você tenha alguns dados que exportou para um dataframe do pandas e gostaria de juntá-los aos dados existentes.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Há um grande problema.
Os dados existentes têm a grafia correta para os países, mas os dados exportados não têm. Se tentarmos unir os dois quadros de dados na coluna country, o pandas não reconhecerá as palavras escritas incorretamente como sendo iguais às palavras escritas corretamente. Assim, o resultado retornado da função de mesclagem não será o esperado.
Aqui está o que aconteceria se tentássemos:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Isso anula todo o objetivo da tentativa de mesclar esses quadros de dados.
No entanto, podemos contornar esse problema com a correspondência de strings difusa.
Vamos ver como isso fica no código:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""Nesse código, renomeamos os valores com erros ortográficos na coluna de país dos dados exportados usando uma função lambda simples em associação com o método process.extractOne(). Observe que usamos um índice de 0 no resultado do extractOne() para retornar on-line a string semelhante em vez de uma lista que contém a string e o valor de semelhança.
Em seguida, mesclamos os quadros de dados na coluna do país usando uma união à esquerda. O resultado é um único quadro de dados que contém os países escritos corretamente (incluindo a união política do Reino Unido).
Se precisar de uma rápida recapitulação das técnicas mencionadas acima, você pode encontrá-las na tabela abaixo:
| Etapa | Descrição | Trecho de código |
|---|---|---|
| Criar DataFrames | Defina dados com possíveis erros ortográficos. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Tentativa de mesclagem com erros | A mesclagem inicial falha devido a cadeias de caracteres incompatíveis. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Corrigir erros de ortografia | Use a correspondência difusa para corrigir nomes de países com erros ortográficos. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Fusão bem-sucedida | Mesclar dataframes após a correção de erros de ortografia usando a correspondência de strings difusa. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
Neste tutorial, você aprendeu:
Os exemplos apresentados aqui podem ser simples, mas são suficientes para ilustrar como lidar com vários casos do que um computador pensa serem cadeias de caracteres incompatíveis. Há várias aplicações de correspondência fuzzy em áreas como verificação ortográfica e bioinformática, em que a lógica fuzzy é usada para combinar sequências de DNA.
Cursos de Python
Curso
Curso
Curso
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Adel Nehme
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Hafeezul Kareem Shaik
