Cours
Introduction à Python
4 h
6.9M
L'algorithme d'appariement flou des chaînes de caractères vise à déterminer le degré de proximité entre deux chaînes de caractères différentes. Ce résultat est obtenu à l'aide d'une mesure de distance connue sous le nom de "distance d'édition". La distance d'édition détermine la proximité de deux chaînes de caractères en déterminant le nombre minimum d'"éditions" nécessaires pour transformer une chaîne en une autre.
Si la distance d'édition compte le nombre d'opérations d'édition pour nous indiquer combien d'opérations séparent une chaîne d'une autre, une opération d'édition est une opération effectuée sur une chaîne pour la transformer en une autre chaîne.
Il existe quatre grands types d'édition :
| Opération d'édition | Description | Exemple |
|---|---|---|
| Insérer | Ajouter une lettre | "Londn" -> "London" |
| Supprimer | Supprimer une lettre | "Londoon" -> "London" |
| Interrupteur | Échanger deux lettres adjacentes | "Lnodon" -> "London" |
| Remplacer | Remplacer une lettre par une autre | "Londin" -> "London" |
Ces quatre opérations d'édition permettent de modifier n'importe quelle chaîne de caractères.
En combinant les opérations d'édition, vous pouvez découvrir la liste des chaînes de caractères possibles qui se trouvent à N éditions, où N est le nombre d'opérations d'édition. Par exemple, la distance d'édition entre "London" et "Londin" est de un puisque le remplacement du "i" par un "o" entraîne une correspondance exacte.
Mais comment la distance d'édition est-elle calculée ?
Il existe différentes variantes de calcul de la distance d'édition. Il existe par exemple la distance de Levenshtein, la distance de Hamming, la distance de Jaro, etc.
Dans ce tutoriel, nous ne nous intéressons qu'à la distance de Levenshtein.
Il s'agit d'une mesure nommée d'après Vladimir Levenshtein, qui l'a envisagée à l'origine, en 1965, pour mesurer la différence entre deux séquences de mots. Nous pouvons l'utiliser pour déterminer le nombre minimum de modifications à apporter pour transformer une séquence d'un mot en une autre.
Voici le calcul formel :
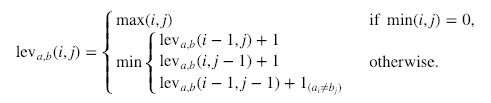
Où 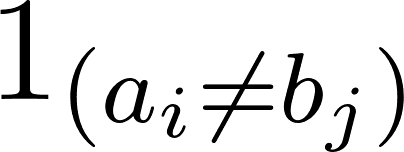 1ab indique 0 lorsque a=b et 1 dans le cas contraire.
1ab indique 0 lorsque a=b et 1 dans le cas contraire.
Il est important de noter que les lignes du minimum ci-dessus correspondent à une suppression, une insertion et une substitution dans cet ordre.
Il est également possible de calculer le taux de similitude de Levenshtein sur la base de la distance de Levenshtein. Pour ce faire, vous pouvez utiliser la formule suivante :
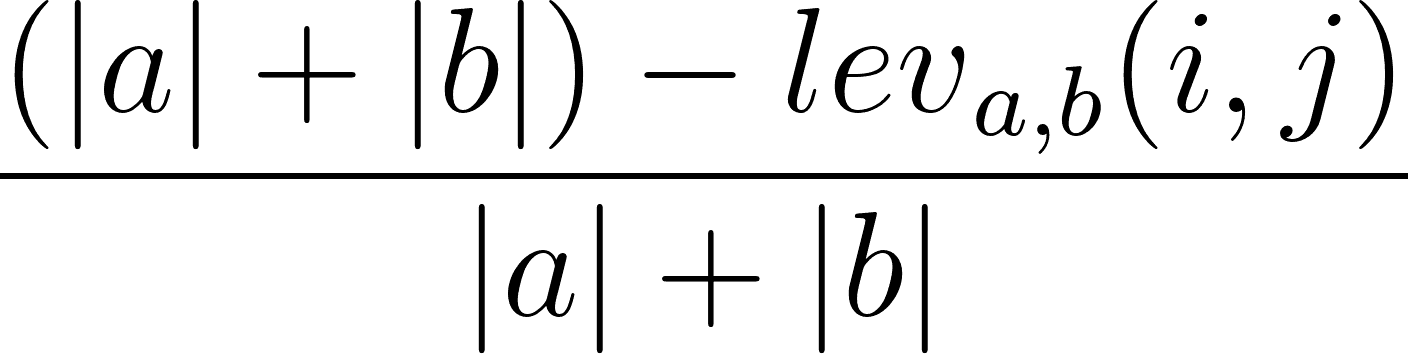
où |a| et |b| sont respectivement les longueurs de la séquence a et de la séquence b.
FuzzyWuzzy est l'un des logiciels les plus populaires pour la comparaison de chaînes de caractères floues en Python. Cependant, FuzzyWuzzy a été mis à jour et renommé en 2021. Il porte désormais le nom de TheFuzz.
TheFuzz reste l'une des bibliothèques open-source les plus avancées pour la correspondance floue de chaînes de caractères en Python. Il a d'abord été développé par SeatGeek dans le but de distinguer si deux listes de billets avec des noms similaires étaient pour le même événement.
Conformément à FuzzyWuzzy, TheFuzz utilise la distance d'édition de Levenshtein pour calculer le degré de proximité entre deux chaînes de caractères. Il offre également des fonctions permettant de déterminer la similarité des chaînes de caractères dans diverses situations, comme vous le verrez dans ce tutoriel.
Tout d'abord, nous devons installer le paquetfuzz. Vous pouvez le faire avec pip en utilisant la commande suivante :
!pip install thefuzzNote: Cette bibliothèque est préinstallée dans le classeur DataLab.
Voyons maintenant ce que nous pouvons faire avec thefuzz.
Suivez le code dans ce classeur DataLab.
Nous pouvons déterminer le rapport simple entre deux chaînes de caractères en utilisant la méthode ratio() de l'objet fuzz. Cette méthode calcule simplement la distance d'édition en fonction de l'ordre des deux chaînes d'entrée difflib.ratio() - consultez la documentation de difflib pour en savoir plus.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Dans le code, nous avons utilisé deux variantes de mon nom pour comparer le score de similarité, qui était de 86.
Vérifions cela par rapport au ratio partiel.
Pour vérifier le ratio partiel, tout ce que nous devons faire dans le code ci-dessus est d'appeler partial_ratio() sur notre objet fuzz au lieu de ratio().
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Nous constatons une diminution. Que se passe-t-il ?
Le site partial_ratio() cherche à déterminer le degré de similitude partielle de deux cordes. Deux chaînes de caractères sont partiellement similaires si certains mots sont dans le même ordre.
Le site partial_ratio() calcule la similarité en prenant la chaîne la plus courte, qui dans ce scénario est stockée dans la variable name, puis en la comparant aux sous-chaînes de même longueur de la chaîne la plus longue, qui est stockée dans full_name.
L'ordre étant important dans le rapport partiel, notre score a baissé dans ce cas. Par conséquent, pour obtenir une concordance de 100 %, vous devriez déplacer la partie "K D" (signifiant mon deuxième prénom) à la fin de la chaîne. Par exemple :
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Que se passe-t-il si nous voulons que notre outil de recherche de chaînes floues ne tienne pas compte de l'ordre ?
Dans ce cas, vous pouvez utiliser le "ratio de tri symbolique".
D'accord, nous voulons ignorer l'ordre des mots dans les chaînes de caractères, mais nous voulons quand même déterminer leur degré de similitude. Le tri par jeton ne se préoccupe pas de l'ordre dans lequel les mots apparaissent. Il tient compte des chaînes de caractères similaires qui ne sont pas dans l'ordre indiqué ci-dessus.
Ainsi, nous devrions obtenir un score de 100 % en utilisant le ratio de tri par jeton avec l'exemple le plus récent :
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""... et comme prévu, nous l'avons fait.
Revenons aux variables originales name et full_name. Que pensez-vous qu'il se passera si nous utilisons maintenant le tri par jeton ?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Le score baisse.
En effet, le tri par jeton ne tient pas compte de l'ordre. Si les chaînes contiennent des mots dissemblables, cela aura un impact négatif sur le taux de similitude, comme nous l'avons vu plus haut.
Mais il existe une solution de contournement.
La méthode token_set_ratio() est assez similaire à la méthode token_sort_ratio(), sauf qu'elle élimine les tokens communs avant de calculer la similarité des chaînes de caractères : ceci est extrêmement utile lorsque les chaînes de caractères ont des longueurs significativement différentes.
Comme les variables name et full_name contiennent toutes deux "Kurtis Pykes", nous pouvons nous attendre à ce que la similarité du ratio de l'ensemble de jetons soit de 100 %.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Le module de traitement permet aux utilisateurs d'extraire du texte d'une collection à l'aide d'une correspondance de chaîne floue. L'appel de la méthode extract() sur le module process renvoie les chaînes de caractères avec un score de similarité dans un vecteur. Par exemple :
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Nous pouvons contrôler la longueur du vecteur renvoyé par la méthode extract() en fixant le paramètre limit à la longueur souhaitée.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""Dans ce cas, la fonction extract() renvoie les trois chaînes les plus proches en fonction de l'évaluateur que nous avons défini.
Dans le tableau ci-dessous, vous pouvez voir une comparaison rapide des différents types de techniques disponibles dans TheFuzz :
| Technique | Description | Exemple de code |
|---|---|---|
| Ratio simple | Calcule la similarité en tenant compte de l'ordre des chaînes d'entrée. | fuzz.ratio(name, full_name) |
| Rapport partiel | Recherche une similarité partielle en comparant la chaîne la plus courte avec les sous-chaînes. | fuzz.partial_ratio(name, full_name) |
| Ratio de tri des jetons | Ignore l'ordre des mots dans les chaînes. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Ratio de l'ensemble des jetons | Supprime les tokens communs avant de calculer la similarité. | fuzz.token_set_ratio(name, full_name) |
Dans cette section, nous allons voir comment effectuer une correspondance de chaîne floue sur un DataFrame pandas.
Imaginons que vous ayez exporté des données dans un DataFrame pandas et que vous souhaitiez les joindre aux données existantes.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Il y a un problème majeur.
Les données existantes contiennent les orthographes correctes pour les pays, mais pas les données exportées. Si nous essayons de joindre les deux dataframes sur la colonne du pays, pandas ne reconnaîtra pas les mots mal orthographiés comme étant égaux aux mots correctement orthographiés. Ainsi, le résultat renvoyé par la fonction de fusion ne sera pas celui escompté.
Voici ce qui se passerait si nous essayions :
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Cela va à l'encontre de l'objectif poursuivi en tentant de fusionner ces DataFrames.
Toutefois, nous pouvons contourner ce problème grâce à la correspondance floue des chaînes de caractères.
Voyons ce que cela donne dans le code :
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""Dans ce code, nous avons renommé les valeurs mal orthographiées dans la colonne pays des données exportées en utilisant une fonction lambda soignée en association avec la méthode process.extractOne(). Notez que nous avons utilisé un index de 0 sur le résultat de extractOne() pour retourner en ligne la chaîne similaire au lieu d'une liste contenant la chaîne et la valeur de similarité.
Ensuite, nous avons fusionné les DataFrames sur la colonne du pays en utilisant une jointure gauche. Le résultat est un DataFrame unique contenant les pays correctement orthographiés (y compris l'union politique du Royaume-Uni).
Si vous avez besoin d'un récapitulatif rapide des techniques mentionnées ci-dessus, vous pouvez les trouver dans le tableau ci-dessous :
| Étape | Description | Extrait de code |
|---|---|---|
| Créer des DataFrame | Définir les données avec les fautes d'orthographe possibles. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Tentative de fusion avec erreurs | La fusion initiale échoue en raison de chaînes de caractères non concordantes. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Corriger les fautes d'orthographe | Utilisez la correspondance floue pour corriger les noms de pays mal orthographiés. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Fusion réussie | Fusionnez les dataframes après avoir corrigé les fautes d'orthographe à l'aide d'une correspondance floue des chaînes de caractères. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
Dans ce tutoriel, vous avez appris :
Les exemples présentés ici sont certes simples, mais ils suffisent à illustrer la manière de traiter les différents cas de chaînes de caractères que l'ordinateur considère comme non concordantes. Il existe plusieurs applications de la correspondance floue dans des domaines tels que la vérification orthographique et la bio-informatique, où la logique floue est utilisée pour faire correspondre des séquences d'ADN.
Cours de Python
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Adel Nehme
Tutoriel
Satyabrata Pal
Tutoriel
Laiba Siddiqui
Tutoriel
Sejal Jaiswal
Tutoriel
Sejal Jaiswal

