Kurs
Einführung in Python
4 Std.
6.9M
Der Fuzzy-String-Matching-Algorithmus versucht, den Grad der Ähnlichkeit zwischen zwei verschiedenen Strings zu bestimmen. Dies wird mithilfe einer Abstandsmetrik festgestellt, die als "Edit Distance" bekannt ist. Die Editierdistanz bestimmt, wie nahe zwei Zeichenfolgen beieinander liegen, indem sie die minimale Anzahl von "Edits" ermittelt, die erforderlich sind, um eine Zeichenfolge in eine andere umzuwandeln.
Wenn die Editierdistanz die Anzahl der Editieroperationen zählt, um uns zu sagen, wie viele Operationen eine Zeichenkette von einer anderen entfernt ist, ist eine Editierung eine Operation, die an einer Zeichenkette durchgeführt wird, um sie in eine andere Zeichenkette zu verwandeln.
Es gibt vier Hauptarten von Bearbeitungen:
| Betrieb bearbeiten | Beschreibung | Beispiel |
|---|---|---|
| einfügen | Einen Brief hinzufügen | "Londn" -> "London" |
| löschen | Einen Buchstaben entfernen | "Londoon" -> "London" |
| Schalter | Vertausche zwei benachbarte Buchstaben | "Lnodon" -> "London" |
| Ersetze | Einen Buchstaben durch einen anderen ersetzen | "Londin" -> "London" |
Mit diesen vier Bearbeitungsoperationen kannst du jede beliebige Zeichenfolge ändern.
Wenn du die Bearbeitungsvorgänge miteinander kombinierst, kannst du die Liste der möglichen Zeichenfolgen ermitteln, die N Bearbeitungen entfernt sind, wobei N die Anzahl der Bearbeitungsvorgänge ist. Zum Beispiel ist die Editierdistanz zwischen "London" und "Londin" eins, da das Ersetzen des "i" durch ein "o" zu einer exakten Übereinstimmung führt.
Aber wie genau wird der Bearbeitungsabstand berechnet, fragst du?
Es gibt verschiedene Varianten, wie man den Bearbeitungsabstand berechnen kann. Es gibt zum Beispiel die Levenshtein-Distanz, die Hamming-Distanz, die Jaro-Distanz und andere.
In diesem Lernprogramm befassen wir uns nur mit dem Levenshtein-Abstand.
Es ist eine Metrik, die nach Vladimir Levenshtein benannt ist, der sie 1965 zur Messung der Differenz zwischen zwei Wortfolgen entwickelt hat. Wir können damit herausfinden, wie viele Bearbeitungen du mindestens vornehmen musst, um eine Wortfolge in eine andere zu verwandeln.
Hier ist die formale Berechnung:
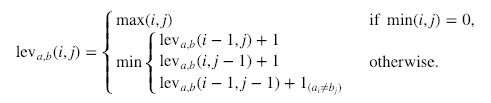
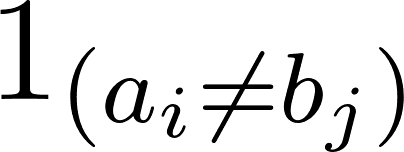 1ab bedeutet 0, wenn a=b und 1, wenn nicht.
1ab bedeutet 0, wenn a=b und 1, wenn nicht.
Es ist wichtig zu beachten, dass die Zeilen auf dem obigen Minimum einer Löschung, einer Einfügung und einer Ersetzung in dieser Reihenfolge entsprechen.
Es ist auch möglich, das Levenshtein-Ähnlichkeitsverhältnis auf der Grundlage des Levenshtein-Abstands zu berechnen. Dies kannst du mit der folgenden Formel tun:
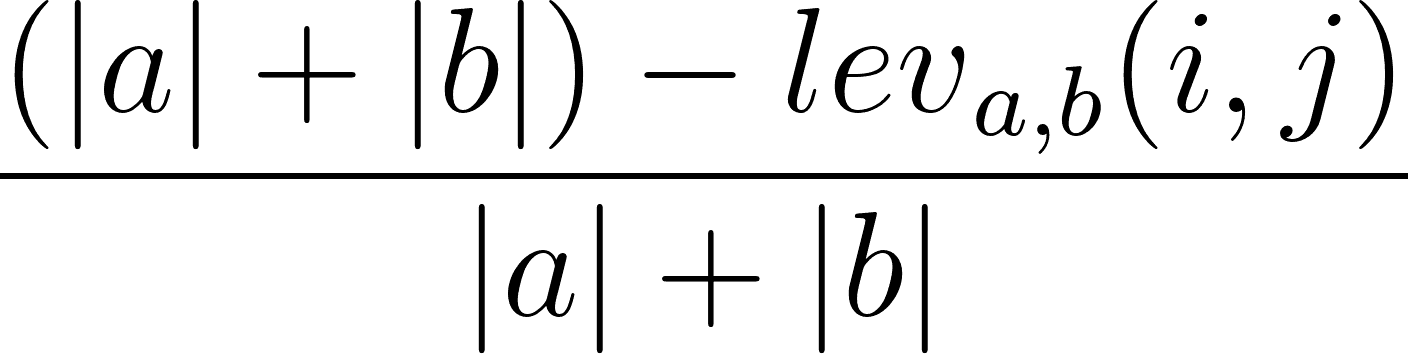
wobei |a| und |b| die Längen von a bzw. b sind.
Eines der beliebtesten Pakete für Fuzzy String Matching in Python war FuzzyWuzzy. FuzzyWuzzy wurde jedoch im Jahr 2021 aktualisiert und umbenannt. Sie trägt jetzt den Namen TheFuzz.
TheFuzz gilt nach wie vor als eine der fortschrittlichsten Open-Source-Bibliotheken für Fuzzy String Matching in Python. Sie wurde ursprünglich von SeatGeek entwickelt, um zu unterscheiden, ob zwei Ticketangebote mit ähnlichen Namen für dieselbe Veranstaltung gelten.
In Übereinstimmung mit FuzzyWuzzy verwendet TheFuzz die Levenshtein-Edit-Distanz, um den Grad der Nähe zwischen zwei Zeichenfolgen zu berechnen. Es bietet auch Funktionen, um die Ähnlichkeit von Zeichenfolgen in verschiedenen Situationen zu bestimmen, wie du in diesem Lernprogramm sehen wirst.
Zuerst müssen wir dasfuzz -Paket installieren. Du kannst dies mit pip mit folgendem Befehl tun:
!pip install thefuzzHinweis: Diese Bibliothek ist in der DataLab-Arbeitsmappe vorinstalliert.
Schauen wir uns nun einige der Dinge an, die wir mit thefuzz machen können.
Folge dem Code in dieser DataLab-Arbeitsmappe.
Mit der ratio()-Methode des Fuzz-Objekts können wir das einfache Verhältnis zwischen zwei Zeichenketten bestimmen. Dabei wird einfach die Editierdistanz auf der Grundlage der Reihenfolge der beiden Eingabestrings berechnet difflib.ratio() - siehe die difflib-Dokumentation, um mehr zu erfahren.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Im Code haben wir zwei Varianten meines Namens verwendet, um den Ähnlichkeitswert zu vergleichen, der mit 86 angegeben wurde.
Lass uns das mit dem Teilverhältnis vergleichen.
Um das Teilverhältnis zu prüfen, müssen wir im obigen Code nur partial_ratio() für unser Fuzz-Objekt anstelle von ratio() aufrufen.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Wir sehen einen Rückgang. Was ist hier los?
Nun, partial_ratio() versucht herauszufinden, wie ähnlich sich zwei Strings teilweise sind. Zwei Zeichenketten sind teilweise ähnlich, wenn sie einige der Wörter in einer gemeinsamen Reihenfolge haben.
Die partial_ratio() berechnet die Ähnlichkeit, indem sie die kürzeste Zeichenkette nimmt, die in diesem Szenario in der Variablen name gespeichert ist, und sie dann mit den Unterzeichnerzeichenketten der gleichen Länge in der längeren Zeichenkette vergleicht, die in full_name gespeichert ist.
Da die Reihenfolge beim Teilverhältnis eine Rolle spielt, ist unsere Punktzahl in diesem Fall gesunken. Um eine 100%ige Übereinstimmung zu erhalten, müsstest du also den Teil "K D" (der für meinen mittleren Namen steht) an das Ende der Zeichenfolge verschieben. Zum Beispiel:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Was also, wenn wir wollen, dass unser Fuzzy String Matcher die Reihenfolge ignoriert?
Dann solltest du vielleicht das "Token-Sortierverhältnis" verwenden.
Okay, wir wollen also die Reihenfolge der Wörter in den Zeichenketten ignorieren, aber trotzdem feststellen, wie ähnlich sie sind - mit Token Sort kannst du genau das tun. Bei der Token-Sortierung ist es egal, in welcher Reihenfolge die Wörter vorkommen. Sie berücksichtigt ähnliche Zeichenketten, die nicht in der oben beschriebenen Reihenfolge sind.
Wir sollten also eine 100%ige Punktzahl erhalten, wenn wir das Token-Sortierverhältnis mit dem letzten Beispiel verwenden:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""... und wie erwartet, haben wir das getan.
Gehen wir zurück zu den ursprünglichen Variablen name und full_name. Was denkst du, was passiert, wenn wir jetzt Token Sort verwenden?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Die Punktzahl sinkt.
Das liegt daran, dass die Token-Sortierung nur die Reihenfolge ignoriert. Wenn es in den Strings Wörter gibt, die sich nicht ähnlich sind, wirkt sich das negativ auf das Ähnlichkeitsverhältnis aus, wie wir oben gesehen haben.
Aber es gibt eine Abhilfe.
Die Methode token_set_ratio() ist der Methode token_sort_ratio() sehr ähnlich, mit dem Unterschied, dass sie gemeinsame Token herausnimmt, bevor sie berechnet, wie ähnlich die Zeichenketten sind: Das ist sehr hilfreich, wenn die Zeichenketten sehr unterschiedlich lang sind.
Da die Variablen name und full_name beide den Namen "Kurtis Pykes" enthalten, können wir davon ausgehen, dass die Ähnlichkeit der Tokenmenge 100% beträgt.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Mit dem Prozessmodul kannst du mithilfe von Fuzzy String Matching Text aus einer Sammlung extrahieren. Wenn du die Methode extract() im Prozessmodul aufrufst, erhältst du die Zeichenketten mit einer Ähnlichkeitsbewertung in einem Vektor zurück. Zum Beispiel:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""Wir können die Länge des Vektors, der von der extract()-Methode zurückgegeben wird, kontrollieren, indem wir den Parameter limit auf die gewünschte Länge setzen.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""In diesem Fall liefert extract() die drei am besten übereinstimmenden Zeichenfolgen auf der Grundlage des von uns definierten Scorers.
In der folgenden Tabelle siehst du einen schnellen Vergleich der verschiedenen in TheFuzz verfügbaren Techniken:
| Technik | Beschreibung | Code Beispiel |
|---|---|---|
| Einfache Ratio | Berechnet die Ähnlichkeit unter Berücksichtigung der Reihenfolge der Eingabestrings. | fuzz.ratio(name, full_name) |
| Teilweise Ratio | Findet partielle Ähnlichkeit, indem es die kürzeste Zeichenkette mit Teilzeichenketten vergleicht. | fuzz.partial_ratio(name, full_name) |
| Token-Sortier-Verhältnis | Ignoriert die Reihenfolge der Wörter in Zeichenketten. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token-Set-Verhältnis | Entfernt gemeinsame Token vor der Berechnung der Ähnlichkeit. | fuzz.token_set_ratio(name, full_name) |
In diesem Abschnitt sehen wir uns an, wie man ein Fuzzy-String-Matching in einem Pandas DataFrame durchführt.
Angenommen, du hast einige Daten in einen Pandas DataFrame exportiert und möchtest sie mit den vorhandenen Daten verbinden.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Es gibt ein großes Problem.
Die vorhandenen Daten haben die richtige Schreibweise für die Länder, die exportierten Daten jedoch nicht. Wenn wir versuchen, die beiden DataFrames über die Länderspalte zu verbinden, würde Pandas die falsch geschriebenen Wörter nicht als gleichwertig mit den richtig geschriebenen Wörtern erkennen. Daher wird das von der Zusammenführungsfunktion zurückgegebene Ergebnis nicht wie erwartet ausfallen.
Hier ist, was passieren würde, wenn wir es versuchen würden:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Dadurch wird der ganze Zweck der Zusammenführung dieser DataFrames zunichte gemacht.
Wir können dieses Problem jedoch mit Fuzzy String Matching umgehen.
Schauen wir uns an, wie es im Code aussieht:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""In diesem Code haben wir die falsch geschriebenen Werte in der Länderspalte der exportierten Daten mithilfe einer ordentlichen Lambda-Funktion in Verbindung mit der Methode process.extractOne() umbenannt. Beachte, dass wir einen Index von 0 für das Ergebnis von extractOne() verwendet haben, um die ähnliche Zeichenkette online zurückzugeben, anstatt eine Liste mit der Zeichenkette und dem Ähnlichkeitswert.
Als Nächstes haben wir die DataFrames in der Länderspalte mit einer Linksverknüpfung zusammengeführt. Das Ergebnis ist ein einziger DataFrame mit den richtig geschriebenen Ländern (einschließlich der politischen Union des Vereinigten Königreichs).
Wenn du eine schnelle Zusammenfassung der oben genannten Techniken brauchst, findest du sie in der folgenden Tabelle:
| Schritt | Beschreibung | Code-Schnipsel |
|---|---|---|
| DataFrames erstellen | Definiere Daten mit möglichen Rechtschreibfehlern. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Versuch der Zusammenführung mit Fehlern | Die ursprüngliche Zusammenführung schlägt wegen nicht übereinstimmender Zeichenfolgen fehl. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Rechtschreibfehler korrigieren | Verwende Fuzzy Matching, um falsch geschriebene Ländernamen zu korrigieren. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Erfolgreicher Zusammenschluss | Führe DataFrames zusammen, nachdem du Rechtschreibfehler mit Fuzzy String Matching korrigiert hast. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
In diesem Lernprogramm hast du gelernt:
Die hier vorgestellten Beispiele sind zwar einfach, aber sie reichen aus, um zu zeigen, wie man mit verschiedenen Fällen umgeht, in denen der Computer denkt, dass die Zeichenketten nicht übereinstimmen. Es gibt verschiedene Anwendungen von Fuzzy Matching in Bereichen wie der Rechtschreibprüfung und der Bioinformatik, wo Fuzzy-Logik verwendet wird, um DNA-Sequenzen zu vergleichen.
Python-Kurse
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Adel Nehme
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
