Curso
Introdução a Bancos de Dados em Python
4 h
101.3K

O SQLAlchemy é o kit de ferramentas Python SQL que permite aos desenvolvedores acessar e gerenciar bancos de dados SQL usando a linguagem de domínio Pythonic. Você pode escrever uma consulta na forma de uma string ou encadear objetos Python para consultas semelhantes. O trabalho com objetos oferece flexibilidade aos desenvolvedores e permite que eles criem aplicativos baseados em SQL de alto desempenho.
Em palavras simples, ele permite que os usuários conectem bancos de dados usando a linguagem Python, executem consultas SQL usando programação baseada em objetos e simplifiquem o fluxo de trabalho.
É bastante fácil instalar o pacote e começar a codificar.
Você pode instalar o SQLAlchemy usando o Gerenciador de pacotes Python (pip):
pip install sqlalchemyCaso esteja usando a distribuição Anaconda do Python, tente digitar o comando no terminal conda:
conda install -c anaconda sqlalchemyVamos verificar se o pacote foi instalado com sucesso:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Excelente, instalamos com sucesso a versão 1.4.41 do SQLAlchemy.
Nesta seção, aprenderemos a conectar bancos de dados SQLite, criar objetos de tabela e usá-los para executar a consulta SQL.
Usaremos o banco de dados SQLite de futebol europeu do Kaggle, que tem duas tabelas: divisões e partidas.
Primeiro, criaremos objetos do mecanismo SQLite usando 'create_object' e passaremos o endereço de localização do banco de dados. Em seguida, criaremos um objeto de conexão conectando o mecanismo. Usaremos o objeto "conn" para executar todos os tipos de consultas SQL.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Se você quiser conectar bancos de dados PostgreSQL, MySQL, Oracle e Microsoft SQL Server, verifique a configuração do mecanismo para obter uma conectividade suave com o servidor.
Este tutorial do SQLAlchemy pressupõe que você entenda os fundamentos do Python e do SQL. Caso contrário, não há problema algum. Você pode fazer o curso de habilidades SQL Fundamentals e Python Fundamentals para criar uma base sólida.
Para criar um objeto de tabela, precisamos fornecer nomes de tabelas e metadados. Você pode produzir metadados usando a função `MetaData()` do SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectVamos imprimir os metadados de "divisões".
print(repr(metadata.tables['divisions']))Os metadados contêm o nome da tabela, os nomes das colunas com o tipo e o esquema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Vamos usar o objeto de tabela "division" para imprimir os nomes das colunas.
print(division.columns.keys())A tabela consiste em uma coluna de divisão, nome e país.
['division', 'name', 'country']Agora vem a parte divertida. Usaremos o objeto de tabela para executar a consulta e extrair os resultados.
No código abaixo, estamos selecionando todas as colunas da tabela "division".
query = division.select() #SELECT * FROM divisions
print(query)Observação: você também pode escrever o comando select como 'db.select([division])'
Para visualizar a consulta, imprima o objeto de consulta e ele mostrará o comando SQL.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsAgora, executaremos a consulta usando o objeto de conexão e extrairemos as cinco primeiras linhas.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)O resultado mostra as cinco primeiras linhas da tabela.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]Nesta seção, veremos vários exemplos do SQLAlchemy para criar tabelas, inserir valores, executar consultas SQL, análise de dados e gerenciamento de tabelas.
Você pode acompanhar ou conferir o espaço de trabalho da DataCamp. Ele contém um banco de dados, código-fonte e resultados.
Primeiro, criaremos um novo banco de dados chamado "datacamp.sqlite". O create_engine criará um novo banco de dados automaticamente se não houver um banco de dados com o mesmo nome. Portanto, criar e conectar são bastante semelhantes.
Depois disso, conectaremos o banco de dados e criaremos um objeto de metadados.
Usaremos a função Table (Tabela) do SQLAlchmy para criar uma tabela chamada "Student" (Aluno)
Ele consiste em colunas:
Criamos a estrutura da tabela. Vamos adicioná-lo ao banco de dados usando `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Para adicionar uma única linha, primeiro usaremos `insert` e adicionaremos o objeto de tabela. Depois disso, use `values` e adicione valores às colunas manualmente. Funciona de forma semelhante à adição de argumentos às funções Python.
Por fim, executaremos a consulta usando a conexão para executar a função.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Vamos verificar se adicionamos a linha à tabela "Student" executando uma consulta de seleção e obtendo todas as linhas.
output = conn.execute(Student.select()).fetchall()
print(output)Adicionamos os valores com sucesso.
[(1, 'Matthew', 'English', True)]Adicionar valores um a um não é uma maneira prática de preencher o banco de dados. Vamos adicionar vários valores usando listas.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Para validar nossos resultados, execute a consulta select simples.
output = conn.execute(db.select([Student])).fetchall()
print(output)A tabela agora contém mais linhas.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]Em vez de usar objetos Python, também podemos executar consultas SQL usando String.
Basta adicionar o argumento como uma string à função `execute` e visualizar o resultado usando `fetchall`.
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Saída:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Você pode até mesmo passar consultas SQL mais complexas. Em nosso caso, estamos selecionando as colunas Name (Nome) e Major (Principal) nas quais os alunos foram aprovados no exame.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Saída:
[('Matthew', 'English'), ('Natasha', 'Math')]Nas seções anteriores, usamos API/Objetos simples do SQLAlchemy. Vamos nos aprofundar em consultas mais complexas e de várias etapas.
No exemplo abaixo, selecionaremos todas as colunas em que o curso do aluno é inglês.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Saída:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Vamos aplicar a lógica AND à consulta WHERE.
Em nosso caso, estamos procurando alunos que tenham se formado em inglês e tenham sido reprovados.
Observação: não é igual a '!=' Verdadeiro é Falso.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Apenas Ben foi reprovado no exame com especialização em inglês.
[(4, 'Ben', 'English', False)]Usando uma tabela semelhante, podemos executar todos os tipos de comandos, conforme mostrado na tabela abaixo.
Você pode copiar e colar esses comandos para testar os resultados por conta própria. Dê uma olhada no espaço de trabalho do DataCamp se você ficar preso em algum dos comandos fornecidos.
|
Comandos |
API |
|
em |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
e, ou, não |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
ordem por |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limite |
Student.select().limit(3) |
|
soma, média, contagem, mínimo, máximo |
db.select([db.func.sum(Student.columns.Id)]) |
|
grupo por |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinto |
db.select([Student.columns.Major.distinct()]) |
Para saber mais sobre outras funções e comandos, consulte a documentação oficial da API SQL Statements and Expressions.
Os cientistas e analistas de dados apreciam os dataframes do pandas e adorariam trabalhar com eles. Nesta parte, aprenderemos a converter um resultado de consulta do SQLAlchemy em um dataframe do pandas.
Primeiro, execute a consulta e salve os resultados.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()Em seguida, use a função DataFrame e forneça os resultados do SQL como argumento. Por fim, adicione os nomes das colunas usando o resultado da primeira linha `results[0]` e `.keys()`
Observação: você pode fornecer qualquer linha válida para extrair os nomes das colunas usando `keys()`
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
Nesta parte, conectaremos o banco de dados de futebol europeu, realizaremos consultas complexas e visualizaremos os resultados.
Como de costume, conectaremos o banco de dados usando as funções `create_engine` e `connect`.
No nosso caso, estaremos unindo duas tabelas, portanto, temos que criar dois objetos de tabela: divisão e correspondência.
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Você pode até mesmo criar consultas mais complexas adicionando módulos adicionais.
Observação: para unir automaticamente duas tabelas, você também pode usar: `db.select([division.columns.division,match.columns.Div])`
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data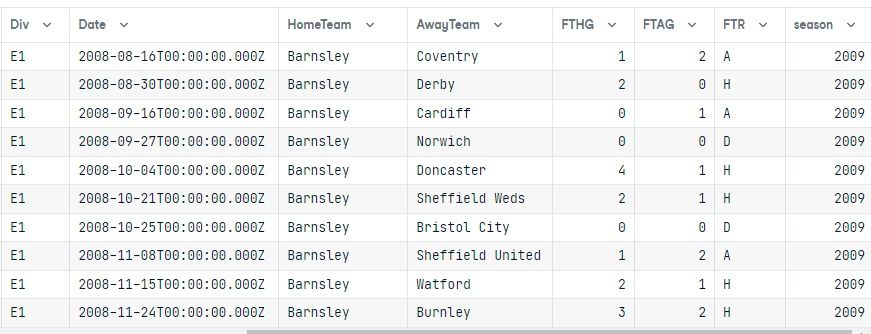
Após a execução da consulta, convertemos o resultado em um dataframe do pandas.
As duas tabelas são unidas, e os resultados mostram apenas a divisão E1 da temporada de 2009 ordenada pela coluna HomeTeam.
Agora que temos um dataframe, podemos visualizar os resultados na forma de um gráfico de barras usando o Seaborn.
Nós o faremos:
O principal objetivo desta parte é mostrar como você pode usar a saída da consulta SQL e criar uma visualização de dados incrível.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)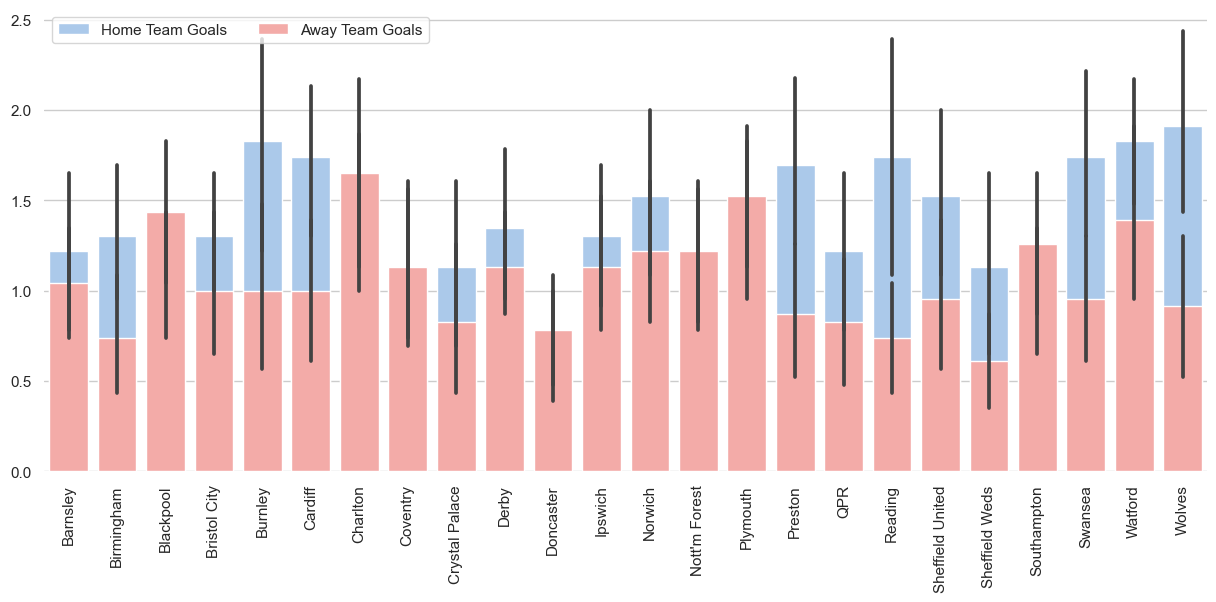
Depois de converter o resultado da consulta em um dataframe do pandas, você pode simplesmente usar a função '.to_csv' com o nome do arquivo.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Evite adicionar uma coluna chamada "Index" usando `index=False`.
data.to_csv("SQl_result.csv",index=False)Nesta parte, converteremos o arquivo CSV de dados da bolsa de valores em uma tabela SQL.
Primeiro, conecte-se ao banco de dados sqlite do datacamp.
engine = create_engine("sqlite:///datacamp.sqlite")Em seguida, importe o arquivo CSV usando a função read_csv. No final, use a função `to_sql` para salvar o dataframe do pandas como uma tabela SQL.
Principalmente, a função `to_sql` requer conexão e nome da tabela como argumento. Você também pode usar `if_exisits` para substituir uma tabela existente com o mesmo nome e `index` para eliminar a coluna de índice.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Para validar os resultados, precisamos conectar o banco de dados e criar um objeto de tabela.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)Em seguida, execute a consulta e exiba os resultados.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Como você pode ver, transferimos com êxito todos os valores do arquivo CSV para a tabela SQL.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)A atualização de valores é simples. Usaremos as funções update, values e where para atualizar o valor específico na tabela.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)Em nosso caso, alteramos o valor "Pass" de False (Falso ) para True (Verdadeiro ), onde o nome do aluno é "Nisha".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
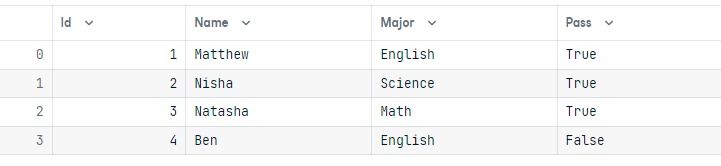
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Para validar os resultados, vamos executar uma consulta simples e exibir os resultados na forma de um dataframe do pandas.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataAlteramos com êxito o valor "Pass" para True para o nome da aluna "Nisha".
A exclusão das linhas é semelhante à atualização. Ele requer a função delete e where.
table.delete().where(table.columns.column_1 == 6)No nosso caso, estamos excluindo o registro do aluno chamado "Ben".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Para validar os resultados, executaremos uma consulta rápida e exibiremos os resultados na forma de um dataframe. Como você pode ver, excluímos a linha que contém o nome do aluno "Ben".
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Se você estiver usando o SQLite, a eliminação da tabela gerará um erro "banco de dados bloqueado". Por quê? Porque o SQLite é uma versão muito leve. Ele só pode executar uma função por vez. Atualmente, ele está executando uma consulta select. Precisamos encerrar toda a execução antes de excluir a tabela.
results.close()
exe.close()Depois disso, use a função drop_all dos metadados e selecione um objeto de tabela para eliminar a tabela única. Você também pode usar o comando `Student.drop(engine)` para eliminar uma única tabela.
metadata.drop_all(engine, [Student], checkfirst=True)Se você não especificar nenhuma tabela para a função drop_all. Isso eliminará todas as tabelas do banco de dados.
metadata.drop_all(engine)O tutorial do SQLAlchemy abrange várias funções do SQLAlchemy, desde a conexão do banco de dados até a modificação de tabelas e, se você estiver interessado em saber mais, tente concluir o curso interativo Introduction to Databases in Python. Você aprenderá sobre os conceitos básicos de bancos de dados relacionais, filtragem, ordenação e agrupamento. Além disso, você aprenderá sobre funções avançadas do SQLAlchemy para manipulação de dados.
Se tiver algum problema ao seguir o tutorial, você pode executar o código-fonte usando o espaço de trabalho e comparar seu código com ele. Você pode até mesmo duplicar o notebook Jupyter e executar o código clicando em apenas dois botões.
Cursos de Python e SQL
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Elena Kosourova
Tutorial
Javier Canales Luna
Tutorial
Javier Canales Luna
