Curso
Introdução ao Python
4 h
6.9M
A Structured Query Language (SQL) é a linguagem mais comum usada para executar várias tarefas de análise de dados. Ele também é usado para manter um banco de dados relacional, por exemplo: adicionar tabelas, remover valores e otimizar o banco de dados. Um banco de dados relacional simples consiste em várias tabelas interconectadas, e cada tabela é composta de linhas e colunas.
Em média, uma empresa de tecnologia gera milhões de pontos de dados todos os dias. É necessária uma solução de armazenamento que seja robusta e eficaz para que eles possam usar os dados para melhorar o sistema atual ou criar um novo produto. Um banco de dados relacional, como MySQL, PostgreSQL e SQLite, resolve esses problemas fornecendo gerenciamento de banco de dados robusto, segurança e alto desempenho.
Principais funcionalidades do SQL
O SQL é uma habilidade de alta demanda que o ajudará a conseguir qualquer emprego no setor de tecnologia. Empresas como Meta, Google e Netflix estão sempre em busca de profissionais de dados que possam extrair informações de bancos de dados SQL e apresentar soluções inovadoras. Você pode aprender os conceitos básicos de SQL fazendo o tutorial Introdução ao SQL no DataCamp.
O SQL pode nos ajudar a descobrir o desempenho da empresa, entender os comportamentos dos clientes e monitorar as métricas de sucesso das campanhas de marketing. A maioria dos analistas de dados pode realizar a maioria das tarefas de business intelligence executando consultas SQL, então por que precisamos de ferramentas como PoweBI, Python e R? Ao usar consultas SQL, você pode saber o que aconteceu no passado, mas não pode prever projeções futuras. Essas ferramentas nos ajudam a entender melhor o desempenho atual e o crescimento potencial.
Python e R são linguagens multiuso que permitem aos profissionais executar análises estatísticas avançadas, criar modelos de aprendizado de máquina, criar APIs de dados e, por fim, ajudar as empresas a pensar além dos KPIs. Neste tutorial, aprenderemos a conectar bancos de dados SQL, preencher bancos de dados e executar consultas SQL usando Python e R.
Observação: Se você é novo no SQL, faça o curso de habilidades em SQL para entender os fundamentos da criação de consultas SQL.
O tutorial em Python abordará os conceitos básicos de conexão com vários bancos de dados (MySQL e SQLite), criação de tabelas, adição de registros, execução de consultas e aprendizado sobre a função Pandas read_sql.
Podemos conectar o banco de dados usando o SQLAlchemy, mas, neste tutorial, usaremos o pacote embutido do Python, o SQLite3, para executar consultas no banco de dados. O SQLAlchemy oferece suporte a todos os tipos de bancos de dados por meio de uma API unificada. Se você estiver interessado em saber mais sobre o SQLAlchemy e como ele funciona com outros bancos de dados, confira o curso Introdução a bancos de dados em Python.
O MySQL é o mecanismo de banco de dados mais popular do mundo e é amplamente usado por empresas como Youtube, Paypal, LinkedIn e GitHub. Aqui aprenderemos como conectar o banco de dados. As demais etapas para usar o MySQL são semelhantes às do pacote SQLite3.
Primeiro, instale o pacote mysql usando '!pip install mysql' e, em seguida, crie um mecanismo de banco de dados local fornecendo seu nome de usuário, senha e nome do banco de dados.
import mysql.connector as sql
conn = sql.connect(
host="localhost",
user="abid",
password="12345",
database="datacamp_python"
)
Da mesma forma, podemos criar ou carregar um banco de dados SQLite usando a função sqlite3.connect. O SQLite é uma biblioteca que implementa um mecanismo de banco de dados autônomo, com configuração zero e sem servidor. Ele é compatível com o DataCamp Workspace, portanto, o usaremos em nosso projeto para evitar erros de host local.
import sqlite3
import pandas as pd
conn= sqlite3.connect("datacamp_python.db")
Nesta parte, aprenderemos a carregar o conjunto de dados do impacto da COVID-19 no tráfego do aeroporto, sob a licença CC BY-NC-SA 4.0, em nosso banco de dados SQLite. Também aprenderemos a criar tabelas do zero.

O conjunto de dados de tráfego do aeroporto consiste em uma porcentagem do volume de tráfego durante o período de linha de base de 1º de fevereiro de 2020 a 15 de março de 2020. Carregaremos um arquivo CSV usando a função do Pandas read_csv e, em seguida, usaremos a função to_sql para transferir o quadro de dados para a nossa tabela SQLite. A função to_sql requer um nome de tabela (String) e conexão com o mecanismo SQLite.
data = pd.read_csv("data/covid_impact_on_airport_traffic.csv")
data.to_sql(
'airport', # Name of the sql table
conn, # sqlite.Connection or sqlalchemy.engine.Engine
if_exists='replace'
)
Agora vamos testar se fomos bem-sucedidos executando uma consulta SQL rápida. Antes de executar uma consulta, precisamos criar um cursor que nos ajudará a executar as consultas, conforme mostrado no bloco de código abaixo. Você pode ter vários cursores no mesmo banco de dados em uma única conexão.
Em nosso caso, a consulta SQL retornou três colunas e cinco linhas da tabela de aeroportos. Para exibir a primeira linha, usaremos cursor.fetchone().
cursor = conn.cursor()
cursor.execute("""SELECT Date, AirportName, PercentOfBaseline
FROM airport
LIMIT 5""")
cursor.fetchone()
>>> ('2020-04-03', 'Kingsford Smith', 64)
Para exibir o restante dos registros, usaremos o site cursor.fetchall(). O conjunto de dados do aeroporto é carregado com sucesso no banco de dados com algumas linhas de código.
cursor.fetchall()
>>> [('2020-04-13', 'Kingsford Smith', 29),
('2020-07-10', 'Kingsford Smith', 54),
('2020-09-02', 'Kingsford Smith', 18),
('2020-10-31', 'Kingsford Smith', 22)]
Agora, vamos aprender a criar uma tabela do zero e preenchê-la adicionando valores de amostra. Criaremos uma tabela studentinfo com id (número inteiro, chave primária, incremento automático), nome (texto) e assunto (texto).
Observação: A sintaxe do SQLite é um pouco diferente. Recomenda-se dar uma olhada na folha de consulta do SQLite para entender as consultas SQL mencionadas neste tutorial.
cursor.execute("""
CREATE TABLE studentinfo
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
subject TEXT
)
""")
Vamos verificar quantas tabelas adicionamos ao banco de dados executando uma consulta SQLite simples.
cursor.execute("""
SELECT name
FROM sqlite_master
WHERE type='table'
""")
cursor.fetchall()
>>> [('airport',), ('studentinfo',)]
Nesta seção, adicionaremos valores à tabela studentinfo e executaremos consultas SQL simples. Usando INSERT INTO, podemos adicionar uma única linha à tabela studentinfo.
Para inserir valores, precisamos fornecer uma consulta e argumentos de valor para a função execute. A função preenche as entradas "?" com os valores que fornecemos.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
value = ("Marry", "Math")
cursor.execute(query,value)
Repita a consulta acima adicionando vários registros.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
values = [("Abid", "Stat"),
("Carry", "Math"),
("Ali","Data Science"),
("Nisha","Data Science"),
("Matthew","Math"),
("Henry","Data Science")]
cursor.executemany(query,values)
É hora de verificar o registro. Para fazer isso, executaremos uma consulta SQL simples que retornará as linhas em que o assunto é Data Science.
cursor.execute("""
SELECT *
FROM studentinfo
WHERE subject LIKE 'Data Science'
""")
cursor.fetchall()
>>> [(4, 'Ali', 'Data Science'),
(5, 'Nisha', 'Data Science'),
(7, 'Henry', 'Data Science')]
O comando DISTINCT subject é usado para exibir valores exclusivos presentes nas colunas de assunto. No nosso caso, é matemática, estatística e ciência de dados.
cursor.execute("SELECT DISTINCT subject from studentinfo")
cursor.fetchall()
>>> [('Math',), ('Stat',), ('Data Science',)]
Para salvar todas as alterações, usaremos a função commit(). Sem um commit, os dados serão perdidos após a reinicialização da máquina.
conn.commit()
Nesta parte, aprenderemos como extrair os dados do banco de dados SQLite e convertê-los em um dataframe do Pandas com uma linha de código. read_sql oferece mais do que apenas executar consultas SQL. Podemos usá-lo para definir colunas de índice, analisar data e hora, adicionar valores e filtrar nomes de colunas. Saiba mais sobre a importação de dados em Python fazendo um curso rápido do DataCamp.
read_sql requer dois argumentos: uma consulta SQL e uma conexão com o mecanismo SQLite. A saída contém as cinco principais linhas da tabela de aeroportos em que PercentOfBaseline é maior que 20.
data_sql_1 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
""",
conn)
print(data_sql_1.head())
Date City PercentOfBaseline
0 2020-12-02 Sydney 27
1 2020-12-02 Santiago 48
2 2020-12-02 Calgary 99
3 2020-12-02 Leduc County 100
4 2020-12-02 Richmond 86
A execução de análises de dados em bancos de dados relacionais ficou mais fácil com a integração do Pandas. Também podemos usar esses dados para prever os valores e executar análises estatísticas complexas.
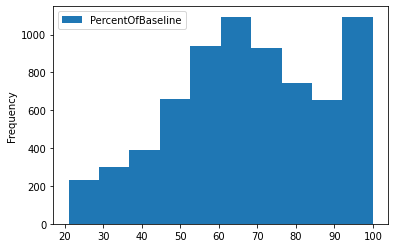
A função plot é usada para visualizar o histograma da coluna PercentOfBaseline.
data_sql_1.plot(y="PercentOfBaseline",kind="hist");
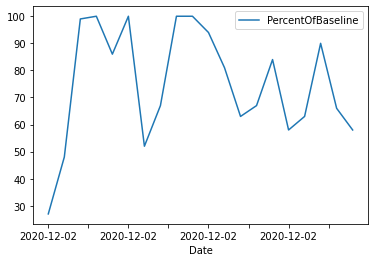
Da mesma forma, podemos limitar os valores aos 20 principais e exibir um gráfico de linha de série temporal.
data_sql_2 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
LIMIT 20
""",
conn)
data_sql_2.plot(x="Date",y="PercentOfBaseline",kind="line");
Por fim, fecharemos a conexão para liberar recursos. A maioria dos pacotes faz isso automaticamente, mas é preferível fechar as conexões depois de finalizar as alterações.
conn.close()
Vamos replicar todas as tarefas do tutorial em Python usando o R. O tutorial inclui a criação de conexões, a criação de tabelas, a inclusão de linhas, a execução de consultas e a análise de dados com o dplyr.
O pacote DBI é usado para conexão com os bancos de dados mais populares, como MariaDB, Postgres, Duckdb e SQLite. Por exemplo, instale o pacote RMySQL e crie um banco de dados fornecendo um nome de usuário, uma senha, um nome de banco de dados e um endereço de host.
install.packages("RMySQL")
library(RMySQL)
conn = dbConnect(
MySQL(),
user = 'abid',
password = '1234',
dbname = 'datacamp_R',
host = 'localhost'
)
Neste tutorial, vamos criar um banco de dados SQLite fornecendo um nome e a função SQLite.
library(RSQLite)
library(DBI)
library(tidyverse)
conn = dbConnect(SQLite(), dbname = 'datacamp_R.db')
Ao importar a biblioteca tidyverse, teremos acesso aos conjuntos de dados dplyr, ggplot e defaults.
dbWriteTable pega o data.frame e o adiciona à tabela SQL. Ele recebe três argumentos: conexão com o SQLite, nome da tabela e quadro de dados. Com dbReadTable, podemos visualizar a tabela inteira. Para visualizar as 6 primeiras linhas, usamos head.
dbWriteTable(conn, "cars", mtcars)
head(dbReadTable(conn, "cars"))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
dbExecute nos permite executar qualquer consulta SQLite, portanto, vamos usá-lo para criar uma tabela chamada idcard.
Para exibir os nomes das tabelas no banco de dados, usaremos dbListTables.
dbExecute(conn, 'CREATE TABLE idcard (id int, name text)')
dbListTables(conn)
>>> 'cars''idcard'
Vamos adicionar uma única linha à tabela idcard e usar o site dbGetQuery para exibir os resultados.
Observação: dbGetQuery executa uma consulta e retorna os registros, enquanto dbExecute executa uma consulta SQL, mas não retorna nenhum registro.
dbExecute(conn, "INSERT INTO idcard (id,name)\
VALUES(1,'love')")
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
Agora, adicionaremos mais duas linhas e exibiremos os resultados usando dbReadTable.
dbExecute(conn,"INSERT INTO idcard (id,name)\
VALUES(2,'Kill'),(3,'Game')
")
dbReadTable(conn,'idcard')
id name
1 love
2 Kill
3 Game
dbCreateTable nos permite criar uma mesa sem complicações. Ele requer três argumentos: conexão, nome da tabela e um vetor de caracteres ou um data.frame. O vetor de caracteres consiste em nomes (nomes de colunas) e valores (tipos). No nosso caso, forneceremos um data.frame de população padrão para criar a estrutura inicial.
dbCreateTable(conn,'population',population)
dbReadTable(conn,'population')
country year population
Em seguida, usaremos o site dbAppendTable para adicionar valores na tabela de população.
dbAppendTable(conn,'population',head(population))
dbReadTable(conn,'population')
country year population
Afghanistan 1995 17586073
Afghanistan 1996 18415307
Afghanistan 1997 19021226
Afghanistan 1998 19496836
Afghanistan 1999 19987071
Afghanistan 2000 20595360
Usaremos o site dbGetQuery para realizar todas as nossas tarefas de análise de dados. Vamos tentar executar uma consulta simples e depois aprender mais sobre outras funções.
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
2 Kill
3 Game
Você também pode executar uma consulta SQL complexa para filtrar a potência e exibir linhas e colunas limitadas.
dbGetQuery(conn, "SELECT mpg,hp,gear\
FROM cars\
WHERE hp > 50\
LIMIT 5")
mpg hp gear
21.0 110 4
21.0 110 4
22.8 93 4
21.4 110 3
18.7 175 3
Para remover tabelas, use dbRemoveTable. Como podemos ver agora, removemos com sucesso a tabela idcard.
dbRemoveTable(conn,'idcard')
dbListTables(conn)
>>> 'cars''population'
Para entender mais sobre tabelas, usaremos o site dbListFields, que exibirá os nomes das colunas em uma determinada tabela.
dbListFields(conn, "cars")
>>> 'mpg''cyl''disp''hp''drat''wt''qsec''vs''am''gear''carb'
Nesta seção, usaremos o dplyr para ler tabelas e, em seguida, executar consultas usando filter, select e collect. Se você não quiser aprender a sintaxe SQL e quiser executar todas as tarefas usando o R puro, esse método é para você. Extraímos a tabela de carros, filtramos por marchas e mpg e, em seguida, selecionamos três colunas, conforme mostrado abaixo.
cars_results <-
tbl(conn, "cars") %>%
filter(gear %in% c(4, 3),
mpg >= 14,
mpg <= 21) %>%
select(mpg, hp, gear) %>%
collect()
cars_results
mpg hp gear
21.0 110 4
21.0 110 4
18.7 175 3
18.1 105 3
14.3 245 3
... ... ...
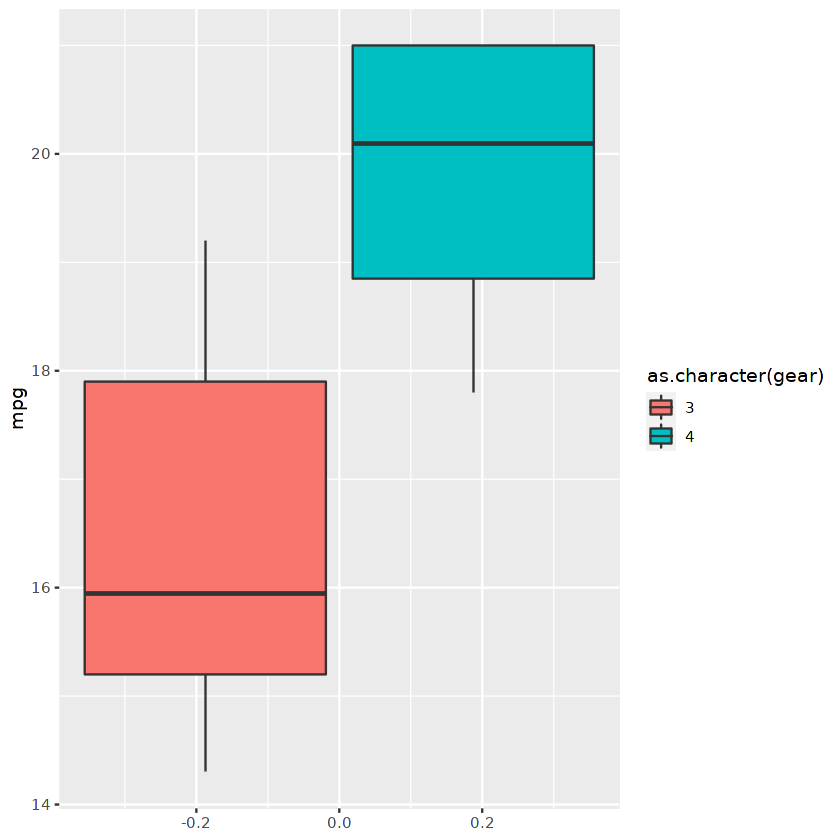
Podemos usar o quadro de dados filtrados para exibir um gráfico boxplot usando ggplot.
ggplot(cars_results,aes(fill=as.character(gear), y=mpg)) +
geom_boxplot()
Ou podemos exibir um gráfico de pontos de faceta dividido pelo número de engrenagens.
ggplot(cars_results,
aes(mpg, ..count.. ) ) +
geom_point(stat = "count", size = 4) +
coord_flip()+
facet_grid( as.character(gear) ~ . )
Neste tutorial, aprendemos a importância de executar consultas SQL com Python e R, criar bancos de dados, adicionar tabelas e realizar análises de dados usando consultas SQL. Também aprendemos como o Pandas e o dplyr nos ajudam a executar consultas com uma única linha de código.
O SQL é uma habilidade obrigatória para todos os trabalhos relacionados à tecnologia. Se você estiver iniciando sua carreira como analista de dados, recomendamos que conclua o curso de carreira de Analista de Dados com SQL Server em dois meses. Essa trilha de carreira lhe ensinará tudo sobre consultas SQL, servidores e gerenciamento de recursos.
Você pode executar todos os scripts usados neste tutorial gratuitamente clicando no botão verde Open In Workspace.
Cursos relacionados a Python e SQL
Curso
Curso
blog
Matt Crabtree
9 min
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma
Tutorial
Sejal Jaiswal
Tutorial
Elena Kosourova
Tutorial
Aditya Sharma
