
Kurs
Veritabanı Tasarımı
4 sa
126.2K
Veri modellemesiyle ilk karşılaştığımda, veritabanlarıyla çalışmanın bir başka teknik adımı gibi görünmüştü. Ancak derinleştikçe, verilerin iyi yapılandırılmış, kolay erişilebilir ve analize hazır olmasını sağlamada ne kadar kritik olduğunu fark ettim. Sağlam bir veri modeli olmadan, en güçlü veritabanları bile yönetimi zorlaşarak verimsizliklere ve tutarsızlıklara yol açabilir.
İster sıfırdan bir veritabanı tasarlıyor olun ister mevcut bir sistemi iyileştiriyor olun, veri modellemesini anlamak verileri sizin için çalışır hâle getirmenin anahtarıdır.
Bu yazıda, etkili modeller kurmanıza yardımcı olacak temel veri modelleme tekniklerini, en iyi uygulamaları ve gerçek dünya örneklerini inceleyeceğiz!
Veri modelleme, verilerin ve ilişkilerinin görsel bir temsilini oluşturmaya yönelik ayrıntılı bir süreçtir. veri yönetiminde tutarlılık ve açıklık sağlamak için verilerin nasıl yapılandırıldığı, saklandığı ve erişildiğine dair bir plan görevi görür.
Veri öğelerini ve aralarındaki ilişkileri tanımlamak, ekiplerin bilgileri verimli depolama, alma ve analiz için düzenlemesine yardımcı olur; bu da hem performansı hem de karar alma süreçlerini iyileştirir.
Üç ana veri modeli türü vardır. Bu bölümde bunları inceleyelim.
Kavramsal model, veriye üst düzey bir bakış sunar. Bu model, teknik ayrıntılara girmeden temel iş varlıklarını (ör. müşteriler, ürünler ve siparişler) ve bunların ilişkilerini tanımlar.
Mantıksal model, verinin nasıl yapılandırılacağını tanımlar. Bu model, belirli bir veritabanına veya teknolojiye bağlı kalmadan veri organizasyonuna odaklanır. Verinin öznitelikleri, ilişkileri ve kısıtlarına dair ayrıntılı bilgiler içerir; böylece iş gereksinimleri ile verinin fiziksel uygulaması arasında bir köprü sunar.
Fiziksel veri modeli, verinin bir veritabanında gerçekte nasıl saklandığını temsil eder. Bu model, performansı optimize etmek ve veri bütünlüğünü sağlamak için gerekli belirli tablo yapıları, indeksler ve depolama mekanizmalarını tanımlar. Mantıksal tasarımı, veritabanı sistemlerine uygun bir formata dönüştürür.
Veri modelleme tek tip bir süreç değildir. Verinin karmaşıklığına ve hedeflere bağlı olarak farklı teknikler kullanılır. Bu bölümde en popüler veri modelleme yaklaşımlarından bazılarını keşfedeceğiz.
ER modelleme, veriyi temsil etmek için kullanılan en yaygın tekniklerden biridir. Üç temel unsuru tanımlamaya odaklanır:
ER modeli, verinin nasıl yapılandırıldığını açık ve görsel biçimde sunarak farklı veri noktaları arasındaki bağlantıları haritalamaya yardımcı olur.
Bir çevrimiçi mağazayı düşünün. Şu varlıklara sahip olabilirsiniz:
Customer_ID, Name ve Email gibi özniteliklerle)Order_ID, Order_Date, Total_Amount ile)Product_ID, Product_Name, Price ile)İlişkiler şöyle olabilir:
ER şu şekilde görünür:
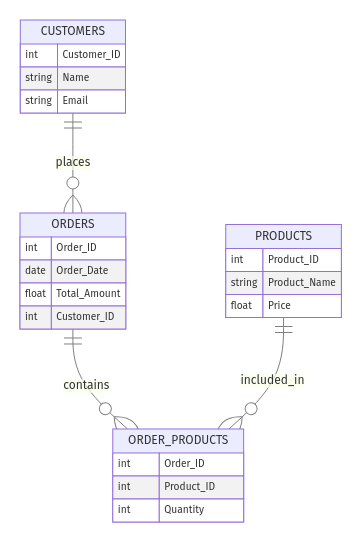
E-ticaret mağazası için örnek ER modeli. Görsel: Yazar
Boyutsal modelleme, verinin sıklıkla olgu ve boyutlar şeklinde temsil edildiği veri ambarı ve analitik alanında yaygın olarak kullanılır. Bu teknik, veriyi yıldız veya kartanesi şemasına organize ederek karmaşıklığı sadeleştirir; bu da sorgulama ve raporlamada verimlilik sağlar.
Satış verilerini analiz etmeniz gerektiğini hayal edin. Şu şekilde yapılandırırsınız:
Sales (işlemsel veriyi saklar; ör. Sales_ID, Revenue, Quantity_Sold)Time (ör. Date, Month, Year)Product (ör. Product_ID, Category, Brand)Customer (ör. Customer_ID, Location, Segment)Yıldız şemasında, Sales olgu tablosu doğrudan boyut tablolarına bağlanır; bu da analistlerin ay bazında toplam gelir veya kategoriye göre en çok satan ürünler gibi raporları verimli şekilde üretmesini sağlar. Şema şu şekilde görünür:
Satış raporlaması için örnek yıldız şeması. Görsel: Yazar
💡 Boyutsal veri modellemesine daha derinlemesine dalmak ister misiniz? Yıldız Şeması ve Kartanesi Şeması rehberimize göz atarak her birini ne zaman kullanmanız gerektiğini ve en iyi performansı nasıl elde edeceğinizi öğrenin.
Nesne yönelimli modelleme, verinin ve üzerinde çalışan işlevlerin nesneler olarak kapsüllendiği karmaşık sistemleri temsil etmek için kullanılır. Bu teknik, özellikle yazılım mühendisliği ve programlamada, karmaşık ve birbiriyle ilişkili veri ve davranışlara sahip uygulamaları modellemek için faydalıdır.
Bir kütüphane yönetim sistemi tasarladığınızı varsayalım. Şu nesneleri tanımlayabilirsiniz:
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Her nesne hem öznitelikleri (veri alanları) hem de metotları (işlevler) içerir. Örneğin, bir Book nesnesi, ödünç alındığında kitabın durumunu güncelleyen .check_out() metoduna sahip olabilir.
Bu yaklaşım, Java ve Python gibi nesne yönelimli programlama (OOP) dillerinde özellikle faydalıdır; çünkü veri modelleri doğrudan sınıflara ve nesnelere eşlenebilir.
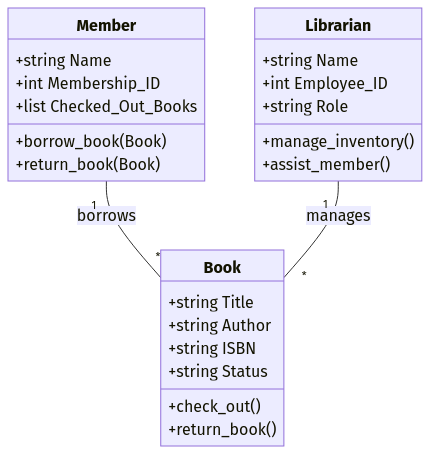
Nesne yönelimli veri modeline örnek. Görsel: Yazar
💡 Python’da nesne yönelimli programlamayı nasıl uygulayacağınızı öğrenmek ister misiniz? DataCamp’in Python’da Nesne Yönelimli Programlama kursuna göz atarak OOP kavramlarını gerçek projelerde ustalıkla uygulayın.
NoSQL ve belge tabanlı modelleme teknikleri, esnek, şemasız veritabanları için tasarlanmıştır.
Bu teknik, veri yapılarının daha az katı olduğu ya da zamanla evrildiği durumlarda sıklıkla kullanılır. Bu modeller, JSON belgeleri gibi önceden tanımlanmış şemalar olmadan yapılandırılmamış veya yarı yapılandırılmış verilerin saklanmasına ve yönetilmesine olanak tanır.
MongoDB gibi NoSQL veritabanlarında, belge tabanlı bir model verileri belge koleksiyonları hâlinde organize eder ve her belgenin benzersiz bir yapısı olabilir. Bu esneklik, özellikle büyük veri ortamlarında veya yüksek hızlı veri erişimi gerektiren uygulamalarda daha hızlı yineleme ve ölçeklenme sağlar.
İlişkisel bir veritabanında kullanıcı profilleri birden çok tabloya dağıtılabilir. Ancak MongoDB gibi belge tabanlı bir NoSQL modelinde bir kullanıcının verileri tek bir JSON benzeri belgede saklanabilir:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Her veri modelleme tekniği, üst düzey planlamadan fiziksel uygulamaya kadar veritabanı tasarımının farklı aşamalarıyla uyumludur. İşte makalenin başlarında gördüğümüz türlerle nasıl ilişkilendiklerine dair bir özet:
Bu kurslarla veri mühendisliği hakkında daha fazla bilgi edinin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
