
Kurs
Datenbankdesign
4 Std.
124.2K
Als ich das erste Mal mit der Datenmodellierung in Berührung kam, erschien sie mir wie ein weiterer technischer Schritt bei der Arbeit mit Datenbanken. Aber je mehr ich mich damit beschäftigte, desto mehr wurde mir klar, wie wichtig es ist, dass die Daten gut strukturiert, leicht zugänglich und für die Analyse bereit sind. Ohne ein solides Datenmodell können selbst die leistungsstärksten Datenbanken schwer zu verwalten sein, was zu Ineffizienzen und Inkonsistenzen führt.
Egal, ob du eine Datenbank von Grund auf neu entwirfst oder ein bestehendes System verfeinerst, das Verständnis der Datenmodellierung ist der Schlüssel dazu, dass Daten für dich arbeiten.
In diesem Beitrag werden wir uns mit grundlegenden Datenmodellierungstechniken, Best Practices und Beispielen aus der Praxis beschäftigen, die dir helfen, effektive Modelle zu erstellen!
Die Datenmodellierung ist ein detaillierter Prozess, bei dem eine visuelle Darstellung der Daten und ihrer Beziehungen erstellt wird. Sie dient als Blaupause dafür, wie Daten strukturiert, gespeichert und abgerufen werden, um Konsistenz und Klarheit im Datenmanagement zu gewährleisten.
Die Definition von Datenelementen und ihren Beziehungen hilft Teams, Informationen zu organisieren, um sie effizient zu speichern, abzurufen und zu analysieren - und damit sowohl die Leistung als auch die Entscheidungsfindung zu verbessern.
Es gibt drei Haupttypen von Datenmodellen. In diesem Abschnitt wollen wir sie erkunden.
Ein konzeptionelles Modell bietet eine Übersicht über die Daten. Dieses Modell definiert die wichtigsten Geschäftseinheiten (z. B. Kunden, Produkte und Aufträge) und ihre Beziehungen, ohne auf technische Details einzugehen.
Das logische Modell legt fest, wie die Daten strukturiert werden sollen. Dieses Modell konzentriert sich auf die Datenorganisation, ohne an eine bestimmte Datenbank oder Technologie gebunden zu sein. Sie enthält detaillierte Informationen über die Datenattribute, -beziehungen und -beschränkungen und bildet damit eine Brücke zwischen den Geschäftsanforderungen und der physischen Implementierung der Daten.
Ein physisches Datenmodell stellt dar, wie die Daten tatsächlich in einer Datenbank gespeichert werden. Dieses Modell definiert die spezifischen Tabellenstrukturen, Indizes und Speichermechanismen, die zur Optimierung der Leistung und zur Gewährleistung der Datenintegrität erforderlich sind. Sie übersetzt den logischen Entwurf in ein für Datenbanksysteme geeignetes Format.
Die Datenmodellierung ist kein Einheitsverfahren. Je nach Komplexität der Daten und den Zielen werden unterschiedliche Techniken eingesetzt. In diesem Abschnitt werden wir einige der beliebtesten Datenmodellierungsansätze kennenlernen.
Die ER-Modellierung ist eine der am häufigsten verwendeten Techniken zur Darstellung von Daten. Es geht darum, drei Schlüsselelemente zu definieren:
Das ER-Modell bietet eine klare, visuelle Darstellung der Datenstruktur, um die Verbindungen zwischen verschiedenen Datenpunkten zu verdeutlichen.
Ziehe einen Online-Shop in Betracht. Du könntest die folgenden Einheiten haben:
Customer_ID, Name, und Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)Die Beziehungen könnten sein:
So sieht die ERD aus:
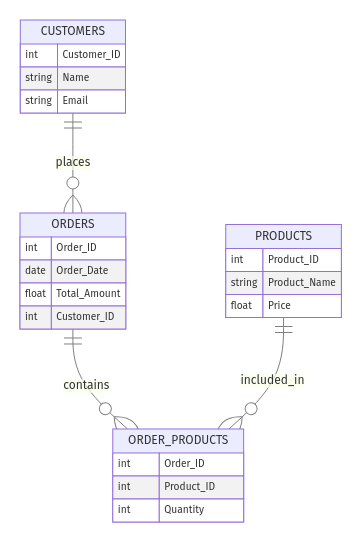
Beispiel für ein ER-Modell für einen E-Commerce-Shop. Bild vom Autor
Die dimensionale Modellierung wird häufig im Data Warehousing und in der Analytik eingesetzt, wo Daten oft in Form von Fakten und Dimensionendargestellt werden . Mit dieser Technik werden komplexe Daten vereinfacht, indem sie in einem Stern- oder Snowflake-Schema organisiert werden, das effiziente Abfragen und Berichte ermöglicht.
Stell dir vor, du musst deine Verkaufsdaten analysieren. Du würdest es wie folgt strukturieren:
Sales (speichert Transaktionsdaten, z.B. Sales_ID, Revenue, Quantity_Sold)Time (z.B. Date, Month, Year)Product (z. B. Produkt_ID, Kategorie, Marke)Customer (z.B. Customer_ID, Location, Segment)In einem Sternschema ist die Faktentabelle Sales direkt mit den Dimensionstabellen verknüpft, so dass Analysten effizient Berichte erstellen können, z. B. über den Gesamtumsatz pro Monat oder die meistverkauften Produkte nach Kategorie. So sieht das Schema aus:
Beispiel für ein Sternschema für Umsatzberichte. Bild vom Autor
💡 Möchtest du tiefer in die dimensionale Datenmodellierung eintauchen? Schau dir unsere Star Schema vs. Star Schema an. Snowflake Schema Leitfaden, um zu verstehen, wann du welches Schema für eine optimale Leistung verwenden solltest.
Die objektorientierte Modellierung wird verwendet, um komplexe Systeme darzustellen, bei denen Daten und die Funktionen, die auf ihnen arbeiten, als Objekte gekapselt sind. Diese Technik ist nützlich für die Modellierung von Anwendungen mit komplexen, miteinander verknüpften Daten und Verhaltensweisen - insbesondere in der Softwareentwicklung und Programmierung.
Angenommen, du entwirfst ein Bibliotheksverwaltungssystem. Du könntest Objekte definieren wie:
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Jedes Objekt enthält sowohl Attribute (Datenfelder) als auch Methoden (Funktionen). Ein Book Objekt könnte zum Beispiel eine Methode .check_out() haben, die den Status des Buches aktualisiert, wenn es ausgeliehen wurde.
Besonders vorteilhaft ist dieser Ansatz in objektorientierten Programmiersprachen (OOP) wie Java und Python, wo Datenmodelle direkt auf Klassen und Objekte abgebildet werden können.
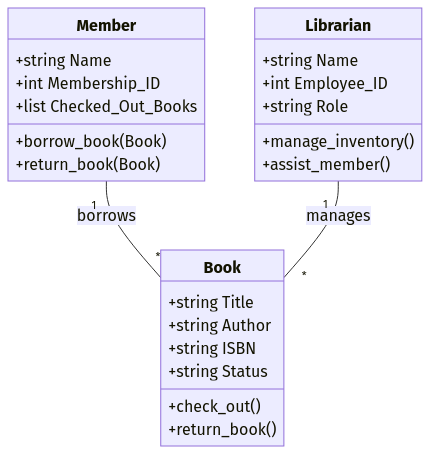
Beispiel für das objektorientierte Datenmodell. Bild vom Autor
💡 Willst du lernen, wie man objektorientierte Programmierung in Python umsetzt? Im DataCamp-Kurs "Objektorientierte Programmierung in Python " lernst du, OOP-Konzepte zu beherrschen und in realen Projekten anzuwenden.
NoSQL und dokumentenbasierte Modellierungstechniken sind für flexible, schemafreie Datenbanken konzipiert.
Diese Technik wird oft verwendet, wenn die Datenstrukturen weniger starr sind oder sich im Laufe der Zeit verändern. Diese Modelle ermöglichen die Speicherung und Verwaltung unstrukturierter oder halbstrukturierter Daten, wie z. B. JSON-Dokumente, ohne vordefinierte Schemata.
In NoSQL-Datenbanken wie MongoDB werden die Daten in einem dokumentenbasierten Modell in Sammlungen von Dokumenten organisiert, wobei jedes Dokument eine einzigartige Struktur haben kann. Diese Flexibilität ermöglicht eine schnellere Iteration und Skalierung, insbesondere in Big-Data-Umgebungen oder Anwendungen, die einen schnellen Datenzugriff erfordern.
In einer relationalen Datenbank können Benutzerprofile in mehreren Tabellen gespeichert sein. In einem dokumentenbasierten NoSQL-Modell wie MongoDB können die Daten eines Benutzers jedoch in einem einzigen JSON-ähnlichen Dokument gespeichert werden:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Jede Datenmodellierungstechnik passt zu verschiedenen Phasen des Datenbankdesigns, von der High-Level-Planung bis zur physischen Implementierung. Hier siehst du, wie sie mit den Typen zusammenhängen, die wir weiter oben im Artikel gesehen haben:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
Derrick Mwiti
Tutorial
Allan Ouko
Tutorial
Javier Canales Luna

