
Course
Database Design
4 hr
124.2K
When I first encountered data modeling, it seemed like another technical step in working with databases. But as I explored it more, I realized how essential it is for ensuring data is well-structured, easily accessible, and ready for analysis. Without a solid data model, even the most powerful databases can become difficult to manage, leading to inefficiencies and inconsistencies.
Whether you're designing a database from scratch or refining an existing system, understanding data modeling is key to making data work for you.
In this post, we’ll explore fundamental data modeling techniques, best practices, and real-world examples to help you build effective models!
Data modeling is a detailed process that involves creating a visual representation of data and its relationships. It serves as a blueprint for how data is structured, stored, and accessed to ensure consistency and clarity in data management.
Defining data elements and their relationships helps teams organize information to support efficient storage, retrieval, and analysis—improving both performance and decision-making.
There are three main types of data models. Let’s explore them in this section.
A conceptual model provides a high-level view of the data. This model defines key business entities (e.g., customers, products, and orders) and their relationships without getting into technical details.
The logical model defines how the data will be structured. This model focuses on data organization without being tied to any specific database or technology. It includes detailed information about the data's attributes, relationships, and constraints, thus offering a bridge between business requirements and the physical implementation of the data.
A physical data model represents how data is actually stored in a database. This model defines the specific table structures, indexes, and storage mechanisms required to optimize performance and ensure data integrity. It translates the logical design into a format suitable for database systems.
Data modeling is not a one-size-fits-all process. Different techniques are employed depending on the complexity of the data and the goals. In this section, we'll explore some of the most popular data modeling approaches.
ER modeling is one of the most common techniques used to represent data. It’s concerned with defining three key elements:
The ER model provides a clear, visual representation of how data is structured to help map the connections between different data points.
Consider an online store. You might have the following entities:
Customer_ID, Name, and Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)The relationships could be:
Here’s how the ER looks like:
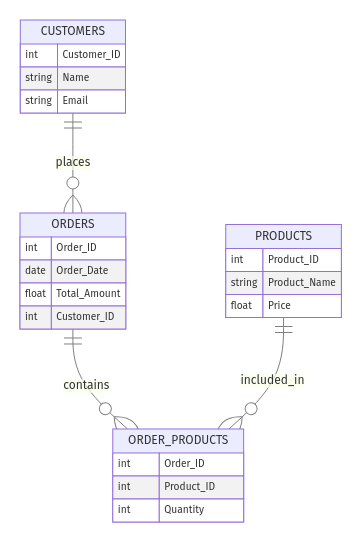
Example ER model for e-commerce store. Image by Author
Dimensional modeling is widely used in data warehousing and analytics, where data is often represented in terms of facts and dimensions. This technique simplifies complex data by organizing it into a star or snowflake schema, which helps in efficient querying and reporting.
Imagine you need to analyze sales data. You would structure it as follows:
Sales (stores transactional data, e.g., Sales_ID, Revenue, Quantity_Sold)Time (e.g., Date, Month, Year)Product (e.g., Product_ID, Category, Brand)Customer (e.g., Customer_ID, Location, Segment)In a star schema, the Sales fact table directly links to the dimension tables, allowing analysts to efficiently generate reports such as total revenue per month or top-selling products by category. Here’s how the schema looks like:
Example star schema for sales reporting. Image by Author
💡 Want to dive deeper into dimensional data modeling? Check out our Star Schema vs. Snowflake Schema guide to understand when to use each for optimal performance.
Object-oriented modeling is used to represent complex systems, where data and the functions that operate on it are encapsulated as objects. This technique is useful for modeling applications with complex, interrelated data and behaviors – especially in software engineering and programming.
Suppose you're designing a library management system. You might define objects like:
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Each object includes both attributes (data fields) and methods (functions). For example, a Book object might have a method .check_out() that updates the book’s status when borrowed.
This approach is particularly beneficial in object-oriented programming (OOP) languages like Java and Python, where data models can be directly mapped to classes and objects.
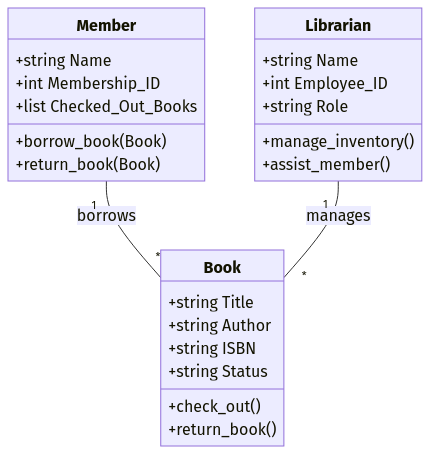
Example of the object-oriented data model. Image by Author
💡 Want to learn how to implement object-oriented programming in Python? Check out DataCamp’s Object-Oriented Programming in Python course to master and apply OOP concepts in real-world projects.
NoSQL and document-based modeling techniques are designed for flexible, schema-less databases.
This technique is often used when data structures are less rigid or evolve over time. These models allow storing and managing unstructured or semi-structured data, such as JSON documents, without predefined schemas.
In NoSQL databases like MongoDB, a document-based model organizes data into collections of documents, where each document can have a unique structure. This flexibility allows for faster iteration and scaling, particularly in big data environments or applications requiring high-speed data access.
In a relational database, user profiles might be stored across multiple tables. But in a NoSQL document-based model like MongoDB, a user's data can be stored in a single JSON-like document:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Each data modeling technique aligns with different stages of database design, from high-level planning to physical implementation. Here’s how they connect with the types we saw earlier in the article:
Learn more about data engineering with these courses!
Course
Course
Course
blog
Kurtis Pykes
13 min
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
14 min
Tutorial
Joleen Bothma
Tutorial
Austin Chia
code-along
Andy Alseth
