
Cours
Conception de bases de données
4 h
124.2K
Lorsque j'ai découvert la modélisation des données, j'ai eu l'impression qu'il s'agissait d'une étape technique supplémentaire dans le travail avec les bases de données. Mais en l'explorant davantage, j'ai réalisé à quel point il est essentiel pour s'assurer que les données sont bien structurées, facilement accessibles et prêtes à être analysées. Sans un modèle de données solide, même les bases de données les plus puissantes peuvent devenir difficiles à gérer, ce qui entraîne des inefficacités et des incohérences.
Que vous conceviez une base de données à partir de zéro ou que vous perfectionniez un système existant, la compréhension de la modélisation des données est essentielle pour faire travailler les données pour vous.
Dans ce billet, nous allons explorer les techniques fondamentales de modélisation des données, les meilleures pratiques et des exemples concrets pour vous aider à construire des modèles efficaces !
La modélisation des données est un processus détaillé qui consiste à créer une représentation visuelle des données et de leurs relations. Il sert de plan directeur pour la structuration, le stockage et l'accès aux données afin de garantir la cohérence et la clarté de la gestion des données.
La définition des éléments de données et de leurs relations aide les équipes à organiser l'information pour permettre un stockage, une recherche et une analyse efficaces, améliorant ainsi les performances et la prise de décision.
Il existe trois principaux types de modèles de données. Nous allons les explorer dans cette section.
Un modèle conceptuel fournit une vue de haut niveau des données. Ce modèle définit les principales entités commerciales (par exemple, les clients, les produits et les commandes) et leurs relations sans entrer dans les détails techniques.
Le modèle logique définit la manière dont les données seront structurées. Ce modèle se concentre sur l'organisation des données sans être lié à une base de données ou à une technologie spécifique. Il comprend des informations détaillées sur les attributs, les relations et les contraintes des données, offrant ainsi un pont entre les exigences de l'entreprise et la mise en œuvre physique des données.
Un modèle de données physique représente la manière dont les données sont réellement stockées dans une base de données. Ce modèle définit les structures spécifiques des tableaux, les index et les mécanismes de stockage nécessaires pour optimiser les performances et garantir l'intégrité des données. Il traduit la conception logique dans un format adapté aux systèmes de base de données.
La modélisation des données n'est pas un processus unique. Différentes techniques sont utilisées en fonction de la complexité des données et des objectifs. Dans cette section, nous allons explorer quelques-unes des approches de modélisation de données les plus populaires.
La modélisation ER est l'une des techniques les plus courantes utilisées pour représenter les données. Il s'agit de définir trois éléments clés :
Le modèle ER fournit une représentation claire et visuelle de la manière dont les données sont structurées afin d'aider à cartographier les connexions entre les différents points de données.
Pensez à une boutique en ligne. Vous pouvez avoir les entités suivantes :
Customer_ID, Name, et Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)Les relations pourraient être les suivantes :
Voici à quoi ressemble l'ERD :
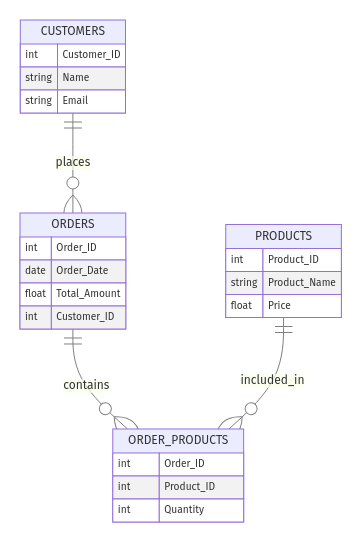
Exemple de modèle d'ER pour un magasin de commerce électronique. Image par l'auteur
La modélisation dimensionnelle est largement utilisée dans les entrepôts de données et les analyses, où les données sont souvent représentées en termes de faits et de dimensions. Cette technique simplifie les données complexes en les organisant selon un schéma en étoile ou Snowflake, ce qui permet d'effectuer des requêtes et de produire des rapports de manière efficace.
Imaginez que vous deviez analyser des données sur les ventes. Vous le structurerez comme suit :
Sales (stocke les données transactionnelles, par exemple Sales_ID, Revenue, Quantity_Sold)Time (e.g., Date, Month, Year)Product (par exemple, Product_ID, Category, Brand)Customer (e.g., Customer_ID, Location, Segment)Dans un schéma en étoile, le tableau de faits Sales est directement lié aux tableaux de dimensions, ce qui permet aux analystes de générer efficacement des rapports tels que le revenu total par mois ou les produits les plus vendus par catégorie. Voici à quoi ressemble le schéma :
Exemple de schéma en étoile pour la déclaration des ventes. Image par l'auteur
💡 Vous souhaitez plonger plus profondément dans la modélisation dimensionnelle des données ? Consultez notre site Star Schema vs. Guide du schéma Snowflake pour comprendre quand utiliser chacun d'entre eux pour une performance optimale.
La modélisation orientée objet est utilisée pour représenter des systèmes complexes, dans lesquels les données et les fonctions qui les exploitent sont encapsulées sous forme d'objets. Cette technique est utile pour modéliser des applications dont les données et les comportements sont complexes et interdépendants, en particulier dans le domaine du génie logiciel et de la programmation.
Supposons que vous conceviez un système de gestion de bibliothèque. Vous pouvez définir des objets tels que :
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Chaque objet comprend à la fois des attributs (champs de données) et des méthodes (fonctions). Par exemple, un objet Book peut avoir une méthode .check_out() qui met à jour le statut du livre lorsqu'il est emprunté.
Cette approche est particulièrement bénéfique dans les langages de programmation orientés objet (POO) comme Java et Python, où les modèles de données peuvent être directement mis en correspondance avec des classes et des objets.
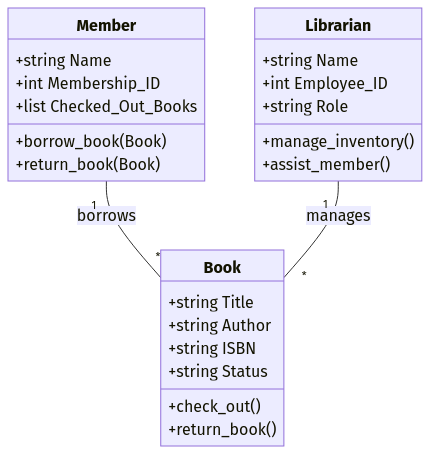
Exemple de modèle de données orienté objet. Image par l'auteur
💡 Vous souhaitez apprendre à mettre en œuvre la programmation orientée objet en Python ? Consultez le cours de programmation orientée objet en Python de DataCamp pour maîtriser et appliquer les concepts de la POO dans des projets réels.
Les techniques de modélisation NoSQL et basées sur des documents sont conçues pour des bases de données flexibles et sans schéma.
Cette technique est souvent utilisée lorsque les structures de données sont moins rigides ou évoluent dans le temps. Ces modèles permettent de stocker et de gérer des données non structurées ou semi-structurées, telles que des documents JSON, sans schémas prédéfinis.
Dans les bases de données NoSQL comme MongoDB, un modèle basé sur les documents organise les données en collections de documents, où chaque document peut avoir une structure unique. Cette flexibilité permet une itération et une mise à l'échelle plus rapides, en particulier dans les environnements big data ou les applications nécessitant un accès aux données à grande vitesse.
Dans une base de données relationnelle, les profils des utilisateurs peuvent être stockés dans plusieurs tableaux. Mais dans un modèle NoSQL basé sur des documents comme MongoDB, les données d'un utilisateur peuvent être stockées dans un seul document de type JSON :
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Chaque technique de modélisation des données correspond à différentes étapes de la conception d'une base de données, de la planification de haut niveau à la mise en œuvre physique. Voici comment ils s'articulent avec les types que nous avons vus plus haut dans l'article :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Tutoriel
Samuel Shaibu
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
DataCamp Team
