
Cursus
Databaseontwerp
4 Hr
126.2K
Toen ik voor het eerst met datamodellering in aanraking kwam, leek het gewoon weer een technische stap bij het werken met databases. Maar naarmate ik me er meer in verdiepte, besefte ik hoe essentieel het is om data goed te structureren, makkelijk toegankelijk te maken en klaar te zetten voor analyse. Zonder een solide datamodel kunnen zelfs de krachtigste databases lastig te beheren worden, met inefficiënties en inconsistenties tot gevolg.
Of je nu een database ontwerpt vanaf nul of een bestaand systeem verfijnt, inzicht in datamodellering is de sleutel om data voor je te laten werken.
In deze post bekijken we fundamentele technieken voor datamodellering, best practices en voorbeelden uit de praktijk om je te helpen effectieve modellen te bouwen!
Datamodellering is een gedetailleerd proces waarbij je een visuele weergave maakt van data en de onderlinge relaties. Het fungeert als een blauwdruk voor hoe data is gestructureerd, opgeslagen en benaderd om consistentie en helderheid te waarborgen in databeheer.
Door data-elementen en hun relaties te definiëren, kunnen teams informatie zo organiseren dat opslag, opvraging en analyse efficiënt verlopen—wat zowel prestaties als besluitvorming verbetert.
Er zijn drie hoofdtypen datamodellen. Laten we ze in deze sectie verkennen.
Een conceptueel model biedt een weergave op hoog niveau van de data. Dit model definieert belangrijke bedrijfsentiteiten (bijv. klanten, producten en bestellingen) en hun relaties, zonder in technische details te treden.
Het logische model definieert hoe de data wordt gestructureerd. Dit model richt zich op de organisatie van data zonder vast te zitten aan een specifieke database of technologie. Het bevat gedetailleerde informatie over attributen, relaties en beperkingen, en vormt zo een brug tussen zakelijke vereisten en de fysieke implementatie van de data.
Een fysiek datamodel geeft weer hoe data daadwerkelijk in een database wordt opgeslagen. Dit model definieert de specifieke tabelstructuren, indexen en opslagmechanismen die nodig zijn om prestaties te optimaliseren en dataintegriteit te waarborgen. Het vertaalt het logisch ontwerp naar een formaat dat geschikt is voor databasesystemen.
Datamodellering is geen one-size-fits-all-proces. Afhankelijk van de complexiteit van de data en de doelen worden verschillende technieken ingezet. In deze sectie bekijken we enkele van de meest populaire benaderingen van datamodellering.
ER-modellering is een van de meest gebruikte technieken om data te representeren. Het draait om het definiëren van drie kernelementen:
Het ER-model biedt een duidelijke, visuele weergave van hoe data is gestructureerd, zodat je de verbindingen tussen verschillende datapunten kunt in kaart brengen.
Neem een online winkel. Je zou de volgende entiteiten kunnen hebben:
Customer_ID, Name en Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)De relaties kunnen zijn:
Zo ziet het ER eruit:
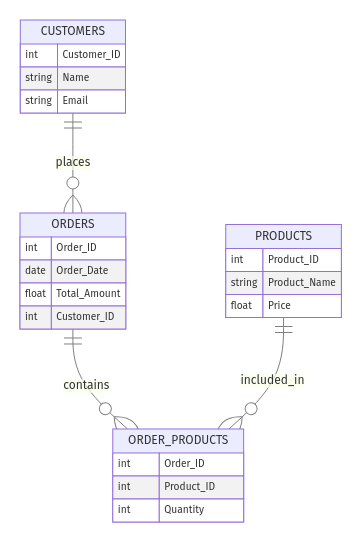
Voorbeeld van ER-model voor e-commercestore. Afbeelding door auteur
Dimensionale modellering wordt veel gebruikt in datawarehousing en analytics, waar data vaak wordt weergegeven in termen van feiten en dimensies. Deze techniek vereenvoudigt complexe data door deze te organiseren in een ster- of sneeuwvlokschema, wat helpt bij efficiënt bevragen en rapporteren.
Stel dat je verkoopdata moet analyseren. Je zou die als volgt structureren:
Sales (slaat transactionele data op, bijv. Sales_ID, Revenue, Quantity_Sold)Time (bijv. Date, Month, Year)Product (bijv. Product_ID, Category, Brand)Customer (bijv. Customer_ID, Location, Segment)In een sterschema is de Sales-feitentabel direct gekoppeld aan de dimensionstabellen, waardoor analisten efficiënt rapporten kunnen genereren, zoals totale omzet per maand of best verkopende producten per categorie. Zo ziet het schema eruit:
Voorbeeld van sterschema voor verkooprapportage. Afbeelding door auteur
💡 Wil je dieper duiken in dimensionale datamodellering? Bekijk onze gids Sterrenschema vs. Sneeuwvlokschema om te begrijpen wanneer je elk schema gebruikt voor optimale prestaties.
Objectgeoriënteerde modellering wordt gebruikt om complexe systemen te representeren, waarbij data en de functies die erop werken als objecten worden ingekapseld. Deze techniek is nuttig voor het modelleren van toepassingen met complexe, onderling verbonden data en gedragingen—vooral in software-engineering en programmeren.
Stel dat je een bibliotheekbeheersysteem ontwerpt. Je zou objecten kunnen definiëren zoals:
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Elk object bevat zowel attributen (datavelden) als methoden (functies). Zo kan een Book-object een methode .check_out() hebben die de status van het boek bijwerkt wanneer het wordt geleend.
Deze aanpak is vooral nuttig in objectgeoriënteerde programmeertalen zoals Java en Python, waar datamodellen direct kunnen worden gekoppeld aan klassen en objecten.
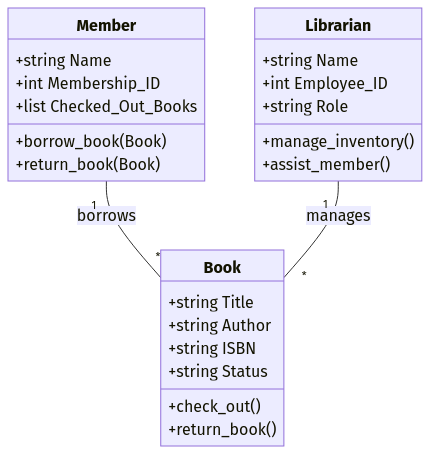
Voorbeeld van het objectgeoriënteerde datamodel. Afbeelding door auteur
💡 Wil je leren hoe je objectgeoriënteerd programmeren in Python toepast? Bekijk DataCamp’s Object-Oriented Programming in Python-cursus om OOP-concepten onder de knie te krijgen en toe te passen in projecten uit de echte wereld.
NoSQL en documentgebaseerde modelleringstechnieken zijn ontworpen voor flexibele databases zonder schema.
Deze techniek wordt vaak gebruikt wanneer datastructuren minder star zijn of in de loop van de tijd evolueren. Deze modellen maken het mogelijk ongestructureerde of semi-gestructureerde data op te slaan en te beheren, zoals JSON-documenten, zonder vooraf gedefinieerde schema’s.
In NoSQL-databases zoals MongoDB organiseert een documentgebaseerd model data in verzamelingen van documenten, waarbij elk document een unieke structuur kan hebben. Deze flexibiliteit maakt sneller itereren en schalen mogelijk, vooral in bigdata-omgevingen of toepassingen die hoge datasnelheid vereisen.
In een relationele database worden gebruikersprofielen mogelijk over meerdere tabellen verspreid opgeslagen. Maar in een NoSQL-documentmodel zoals MongoDB kan de data van een gebruiker in één JSON-achtig document worden opgeslagen:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Elke techniek voor datamodellering sluit aan op verschillende fasen van databaseontwerp, van plannen op hoofdlijnen tot fysieke implementatie. Zo sluiten ze aan op de typen die we eerder in het artikel zagen:
Leer meer over data engineering met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
